-
-
Homepage
-
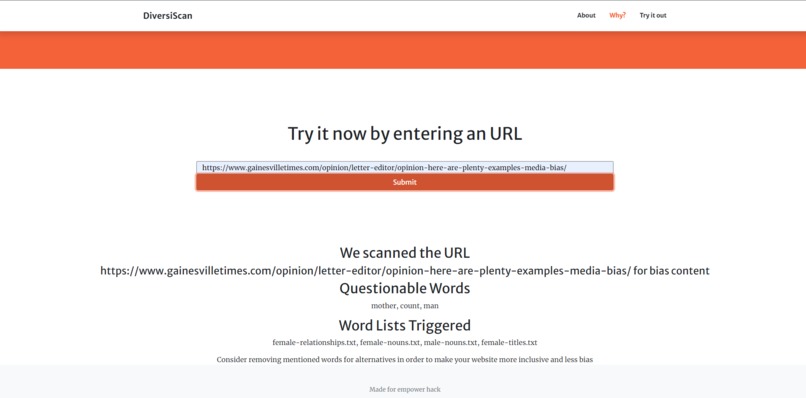
Example of entering a url


Inspiration
The inspiration for this project was products like lighthouse that look at performance and accessibility features with scanning, but they don't look at inherent biases in language of developers. My project, DiversiScan intends to solve this issue.
What it does
The project allows users to enter a url and get an assessment of bias language in their website such as pronoun usage and other assumptions made by the author.
How we built it
The project is comprised of a light frontend wrapper for a backend api that stores bias language datasets and compares elements of the website individually with the datasets, and keeps track of the websites biases. The backend is built using hibernate, spring boot, and Jsoup. The frontend is build using Jquery and Apache.
Challenges we ran into
I ran into issues building the frontend, as I am a backend focused developer. Finding datasets was an issue, and sanitizing them also took much of the project development cycle.
Accomplishments that we're proud of
I like how my frontend turned out and the backend's accuracy.
What we learned
I learned a lot about how much inherent bias we have in our everyday lives. I also learned a lot about javascript and frontend development.
What's next for DiversiScan
Possibly a cli for developers, and ide and github integrations, so biases never reach production.


Log in or sign up for Devpost to join the conversation.