-
-

Diversify homepage
-
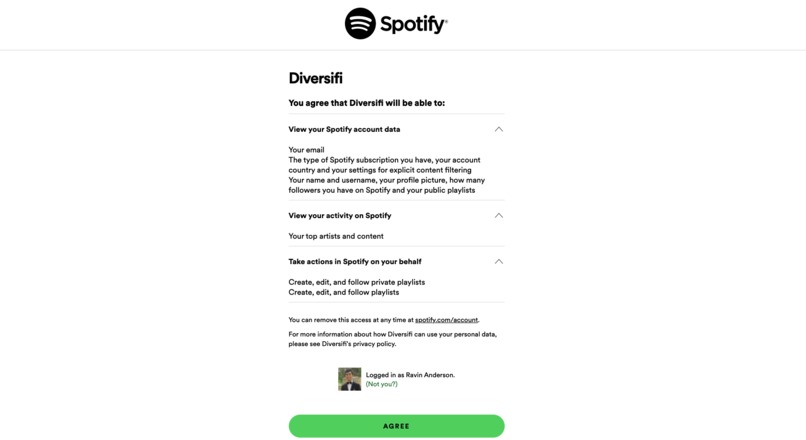
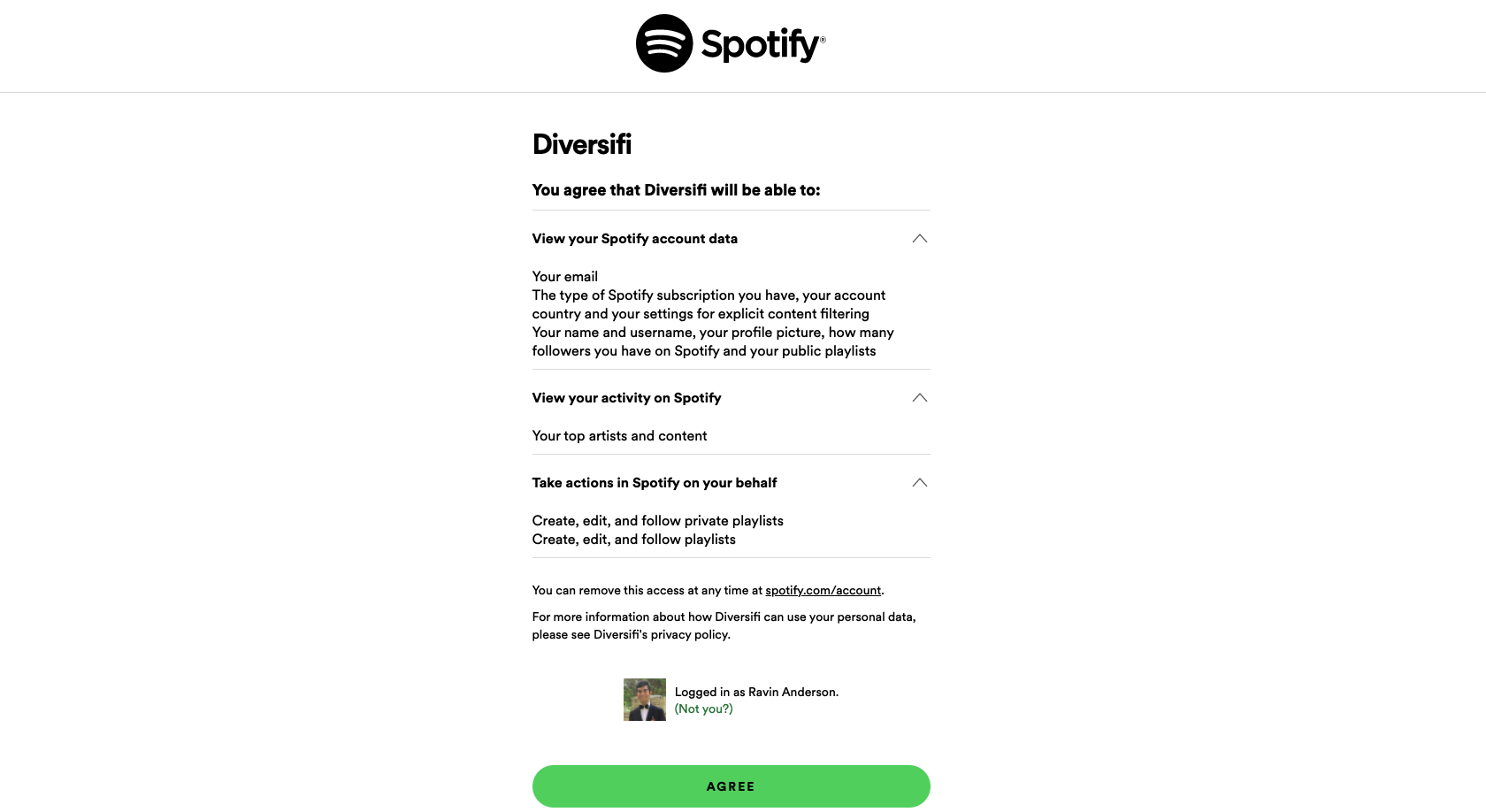
User authenticated through Spotify
-

User is connected to Diversify via Spotify authentication
-

User can select any of the 116 countries Diversifi indexes
-

Diversifi Globe view, User selected India
-

Custom Generated playlist available in Diversifi web client
-

Diversifi Auto Generated Playlist available in user's Spotify Account
-
 GIF
GIF
World 3D Model Gif







Inspiration
We live in a world of 7 billion people, 7100 languages, and 195 nations. The world is full of rich and diverse cultures, but we seldom break out of our local bubbles to experience something truly new. The advent of streaming services has made international and indie music more accessible than ever, but is at the same time driven by algorithms that reinforce our local biases, not expose us to things that might change them. In a world so full of rich and dynamic cultures, it would be a shame to allow technology to keep us from experiencing the best of it. Diversifi flips this narrative and leverages technology to put you in touch with the best songs you haven't heard yet from cultures you otherwise would not have witnessed. We hope that our project will contribute to cultural revitalization though sparking interest in diverse musical traditions.
What it does
Diversifi scans your Spotify library and makes note of the prominent features across your favorite music. With knowledge of the type of music you're likely to enjoy, Diversifi allows you to select any one of 116 countries and returns trending songs in that country that match most closely to your music tastes. If you like danceable beats and choose Nigeria, expect a playlist of groovy afrobeats to show up in your Spotify account. Diversifi tears down the locality barrier and puts you in touch with music you'll love, no matter how far.
How we built it
The development of Diversifi can be split into 3 stages:
- Data Collection:
We used the Google Cloud Compute Engine to scrape more than 1300 Spotify Playlists from everynoise.com (organized by gender, age, and nationality) to generate lists of the top 100 songs among 116 nations.
Data Transformation
To get meaningful insights from these scraped songs, we used the Spotify API to analyze every song in our database across 6 dimensions (Acousticness, Danceability, Energy, Instrumentalness, Speechiness, and Valence). Then, we cast each song from each country into 6 dimensional vector spaces according to its value on each of the 6 dimensions. We store these song vectors in 100+ k-d trees (one for each country) to facilitate fast lookup of these songs later.
Deployment and User Processing
Our team created a ReactJS Frontend and ExpressJS Backend hosted on DigitalOcean to present our application while our k-d tree data was stored on MongoDB Atlas.
After a user authenticates, the user selects a country whose music they are interested in listening to. We use Spotify's API to analyze the user's 50 most liked songs across the same 6 dimensions and average them to create a vector representing the overall taste of the user.
Finally, we compare the 6-dimensional location of the user with the 6-dimensional location of the 100 songs scraped from the country the user selected. We use the k-nearest-neighbors algorithm to implemented using our pre-computed k-d trees to create a playlist of the 20 songs closest to the user's vector. We add this playlist to the user's Spotify account.
Challenges we ran into
Learning to use Spotify's API was challenging for our team. Spotify uses the OAuth authentication technique that was new to our team, and trying to execute thousands of API requests without surpassing rate limits or breaching authentication presented a novel and difficult challenge. Using Google Cloud Compute Engine allowed our team to easily keep tabs on the status of our scrapers, and make sure we were sending the correct data to our database.
Our team found the prospect of hosting and deploying an accessible webpage a difficult task. Luckily, with Digital Ocean's suite of hosting and deployment tools, we were able to successfully stand up our app for the world to see.
Accomplishments that we're proud of
Julian learned how to use the 3D rendering library ThreeJS for rendering a dynamic globe model that pans to each country the user selects. He layered 8k textures sourced from NASA satellite photography and a transparent cloud-cover on top of a spherical model. He then individually mapped the over 100 real-life locations of each country in our database against their coordinates on the spherical model. The result was a really cool visual centerpiece of our frontend! He also designed our logo and deployed our project!
Alphonso created the scraper which collected the numerous Spotify playlists that were the source for our dataset of each country's songs. Using Google Cloud Compute Engine, this process was made automatic to work overnight to scrape more than 1300 Spotify Playlists in total.
Working together to wrangle OAuth for Spotify API authentication, Andrew and Alphonso built a worker, also housed on Google Cloud, to collect ~10000 Spotify songs categorized by country
Building off of the 1300+ Spotify playlists scraped by Alphonso, Andrew built out the k-nearest neighbor model through an efficient implementation using numerous k-d trees for super fast lookup, enabling our service to match users to international music fitting their fibe and produce a playlist for them in less than 5 seconds
Ravin was responsible for designing and developing the frontend of our app, linking together Julian's 3D model, Andrew and Alphonso's backend infrastructure, the user interface, and the Spotify playlist display. Linking everything together on the frontend as well as displaying all the complicated components in an appealing and responsive view ended up being one of the most difficult portions of our project.
... but we are most proud of our impeccable teamwork through our entire project that allowed us to pursue individual portions of the project, come together on challenges, and have fun along the way!
What we learned
Everyone on our team learned an incredible amount throughout the process of creating Diversifi. We learned to deploy an application, project manage, delegate tasks, create a fullstack app, numerous libraries, work with vector spaces and k-d tress, use databases, and use virtual machines for scraping and data collection / transformation.
What's next for Diversifi?
We plan to make our application more comprehensive and powerful in the future. This could mean collecting more features on each song, adding more granular locales to our dataset (cities or administrative regions as opposed to nations) and simply collecting a larger volume of data in general.






Log in or sign up for Devpost to join the conversation.