-
-
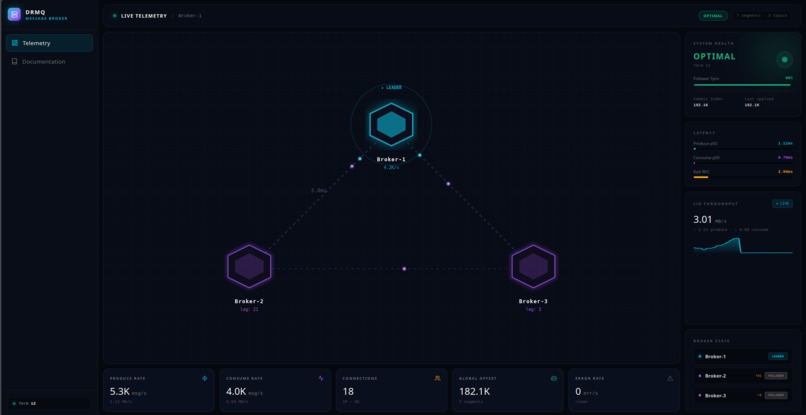
This is how the dashboard looks in cluster mode.
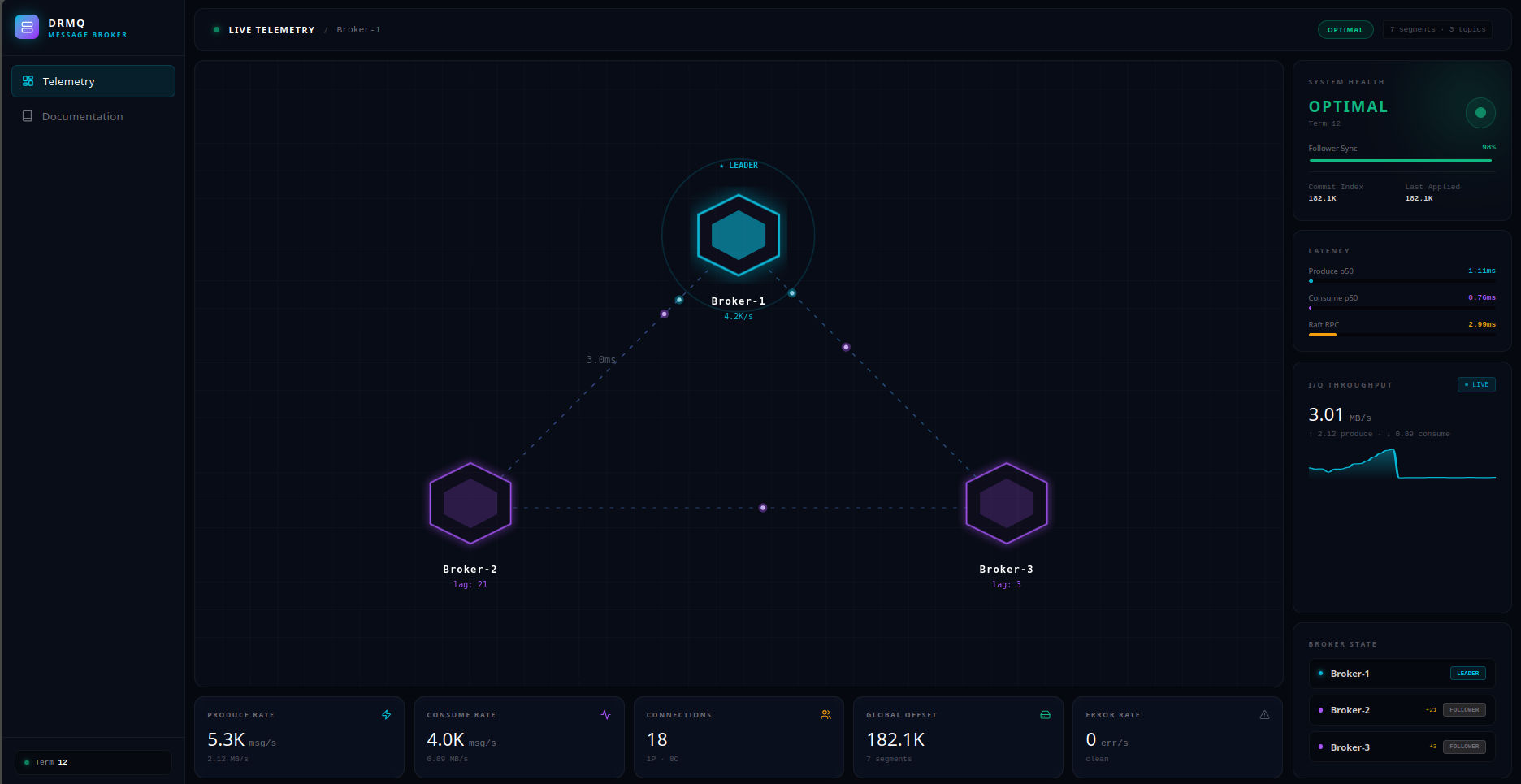
About the Project
DRMQ (Distributed Reliable Message Queue) is a high-performance, fault-tolerant distributed messaging infrastructure built entirely from scratch. It provides a highly available, replicated append-only message log capable of acting as the backbone for scalable microservices. By implementing the Raft consensus algorithm internally, it manages its own cluster topology, leader elections, and data replication without relying on external coordination services like ZooKeeper, making it ambitious and foundational piece of infrastructure.
Inspiration
Modern enterprise messaging queues provide immense value, but their underlying mechanics are often hidden behind layers of deep abstraction. I was inspired to demystify these black boxes by tackling the "hard problems" of distributed systems head-on. I wanted to build an impactful tool that didn't just route messages, but aggressively defended its own state against network partitions, node crashes, and disk exhaustion.
How I Built It
The broker infrastructure is meticulously engineered in Java 17, intentionally avoiding high-level web frameworks to maximize raw execution speed and control.
- Networking & Protocol: I utilized Netty to design a custom, low-latency binary RPC protocol over TCP. This robust transport layer elegantly handles both high-throughput client traffic and internal peer-to-peer synchronization.
- Consensus & Storage: The core is a custom Raft implementation governing leader elections and quorum-based log replication. The storage layer uses memory-mapped segment rolling and aggressive log compaction to bound disk usage, ensuring enterprise-grade data durability.
- Intuitive UX & Observability: Distributed systems are notoriously hard to manage, so I prioritized developer experience by building a beautiful React and TypeScript dashboard. The brokers stream live JSON telemetry over WebSockets, allowing users to intuitively visualize real-time graphs of cluster throughput, active consumer leases, and dynamic leader topologies at a single glance.
Challenges We Faced
Building resilient infrastructure is a continuous battle against complex edge cases. Our most significant technical hurdles included:
- Zero-Downtime State Transfers: When a follower node crashes and falls severely behind, replaying millions of messages is inefficient. I engineered a robust snapshotting mechanism where the leader atomically zips its persistent state and streams it over the network in 2MB chunks to safely bypass Netty frame limits. The follower then securely hot-swaps its storage directories without requiring a JVM restart.
- Thread-Pool Starvation: During extreme high-throughput load testing, a lagging follower starved the leader's Raft RPC thread pool. This blocked heartbeats to healthy nodes, triggering a cascading infinite election loop. I architected a strict concurrent task isolation model, mathematically guaranteeing that slow network I/O to one peer could never destabilize the rest of the cluster.
What We Learned
This project fundamentally elevated my approach to system architecture. I gained a profound, hands-on understanding of the Raft consensus protocol, resolving split-brain network partitions, and the critical importance of atomic disk operations. It reinforced the reality that in distributed environments, hardware failures are guaranteed. By prioritizing comprehensive testing, clear documentation, and highly resilient component design, I learned how to engineer software that survives true chaos.

Log in or sign up for Devpost to join the conversation.