

Inspiration
Technology today is a lot about convenience. Self-driving cars, mobile phones, the internet - they all make life more convenient, efficient, and easy. Our goal is to create an app that integrates into life seamlessly and introduces you to features you never thought you needed so that we can make your life more convenient.
What it does
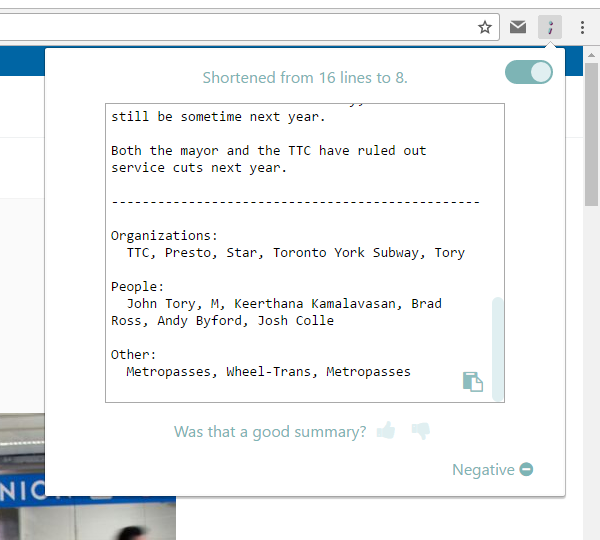
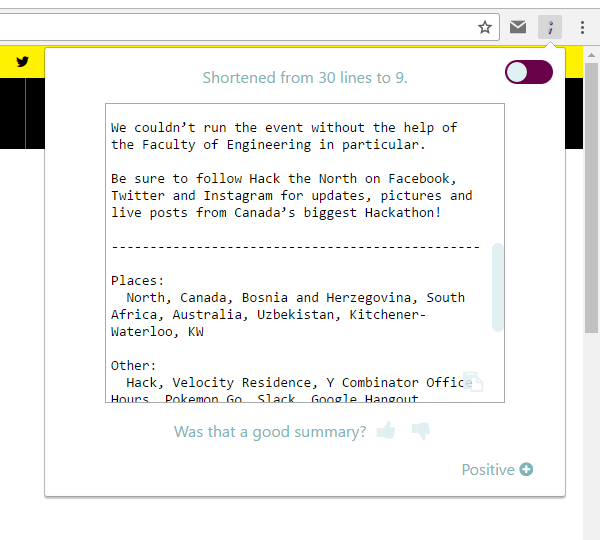
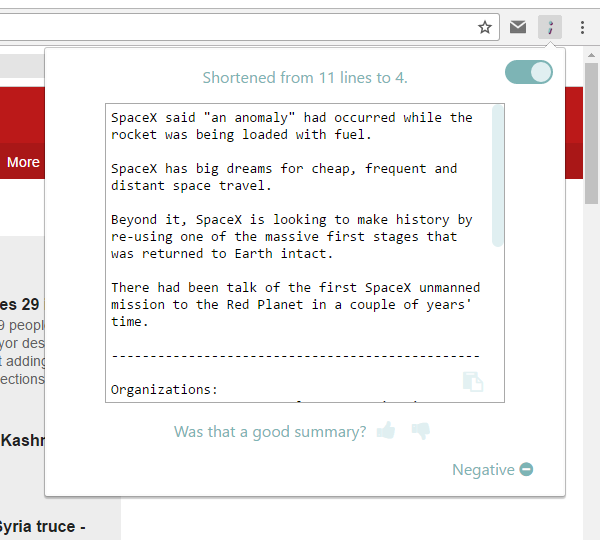
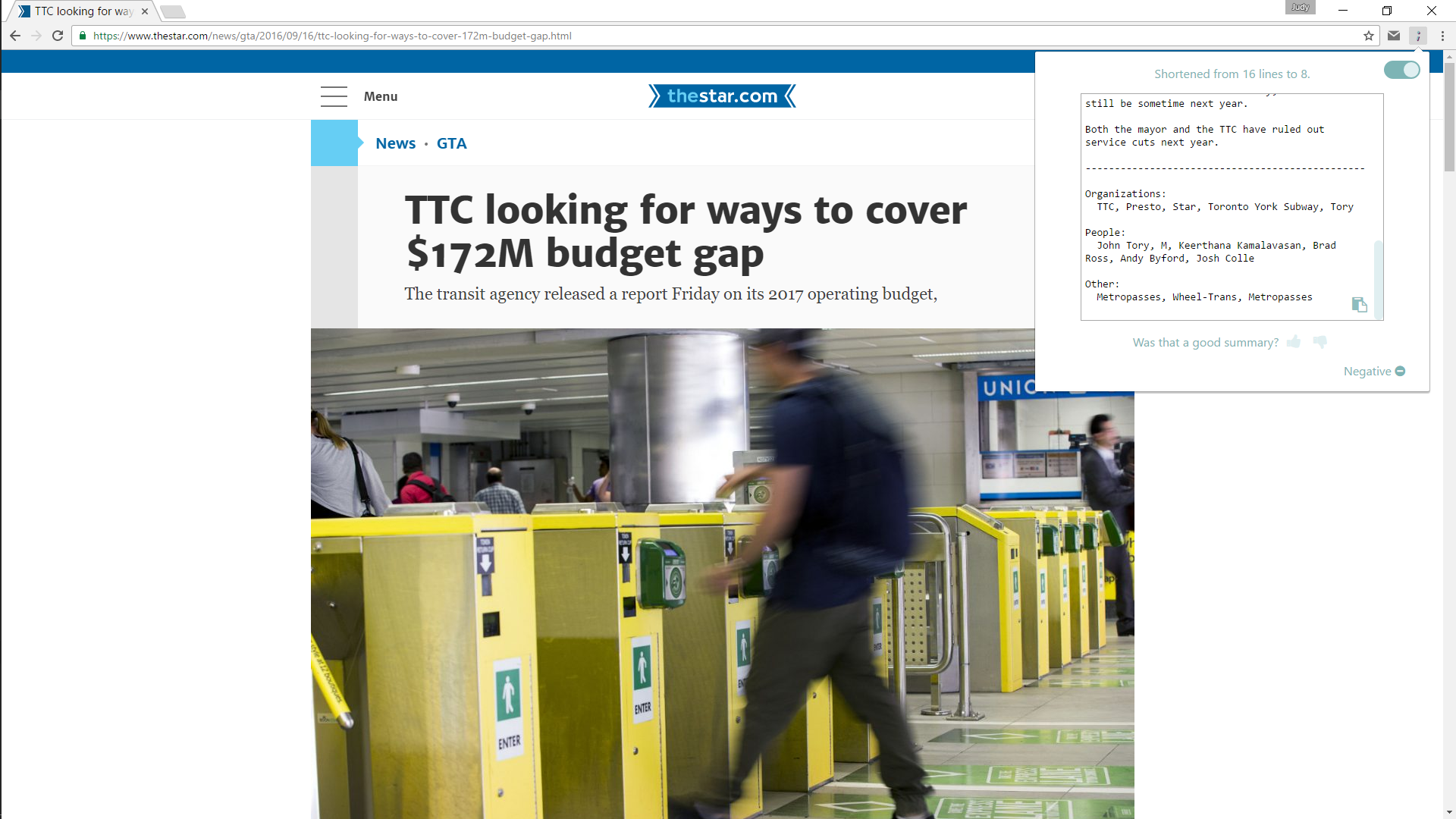
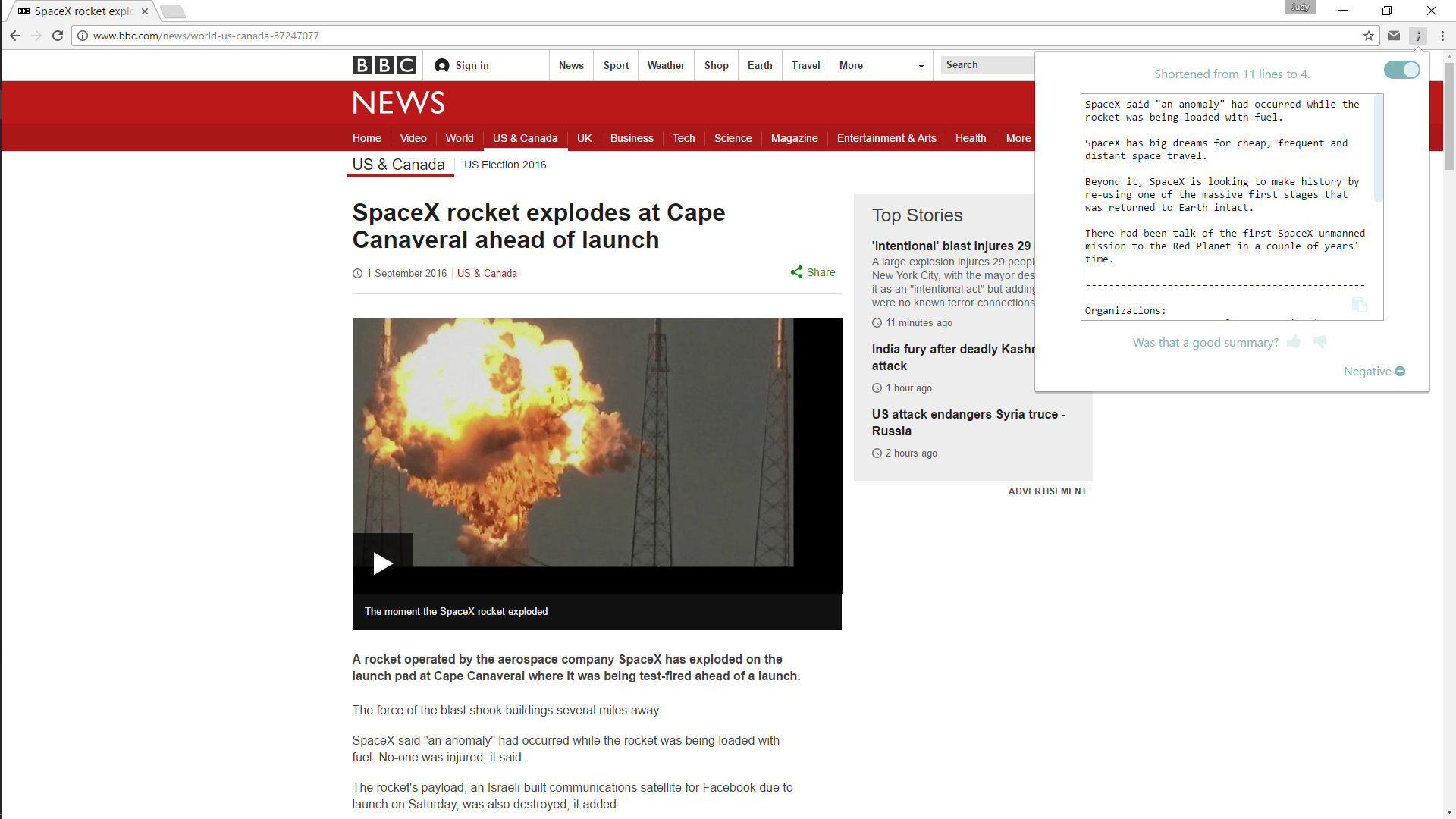
distl provides the client with a “distilled” version of articles as they browse the web. The client has to do very little - distl automatically extracts relevant text from a webpage and gives back a summarized version with sentiment analysis and keyword extraction.
How we built it
There were a lot of components to our project. To extract text from a webpage in a non-disruptive and natural way, we created a beautifully designed chrome extension that quickly and efficiently extracts the relevant text (i.e. no ads!) from a webpage using the Boilerpipe API as well as HTML parsing and filtering techniques that we created. We then sent the relevant text to a node.js server hosted on Google App Engine, where we used text summarization techniques, sentiment analysis, and keyword extraction to condense and compress the content as much as possible. This information is relayed back to the client, where he/she can choose to “upvote/downvote” the result. The upvote/downvote is sent back to our servers so that we can log the original text, resultant text, etc. for data processing later on. A CRON Job is scheduled on a VM hosted by Google Compute Engine to run Spark jobs on a Hadoop cluster to process and analyze log data for trends (i.e. average article size) so that we can improve our NLP algorithms.
Challenges we ran into
It was very difficult learning how to use the Google Cloud Platform tools as well as the APIs.
Accomplishments that we're proud of
We tackled a lot of different, new technologies in just a few days. We learned about NLP, ML, big data, hadoop, cloud computing, and chrome extensions. In addition, Google Cloud Platform was a very complex but powerful service. It was difficult to understand the various components (i.e. Google storage, dataproc, app engine, compute engine, ML API's) and their use cases in the short period of time we had.
What we learned
First and foremost, we learned about a lot of technologies. However, we realized that the difficulty and scope of the project should be better taken into consideration next time. We took on too much and were VERY tired by the end of it all.
What's next for distl
distl's backend is very loosely coupled with the frontend. We will consider launching different versions to other platforms (i.e. mobile) in the future.




Log in or sign up for Devpost to join the conversation.