-
-
What Harbor does
-
What's the agent training data?
-
How consistent are the agents?
-
Agent Consistency
-
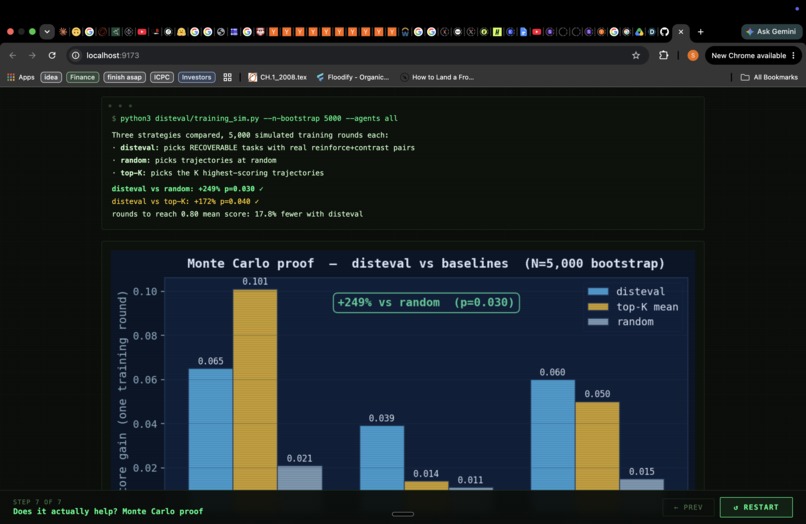
Monte-Carlo Simulation that proves improvements in code quality after dist-eval self-improvement framework is used
-
How consistent are the agents?
disteval: Distribution-First Evaluation and Self-Improvement for AI Agents
Inspiration
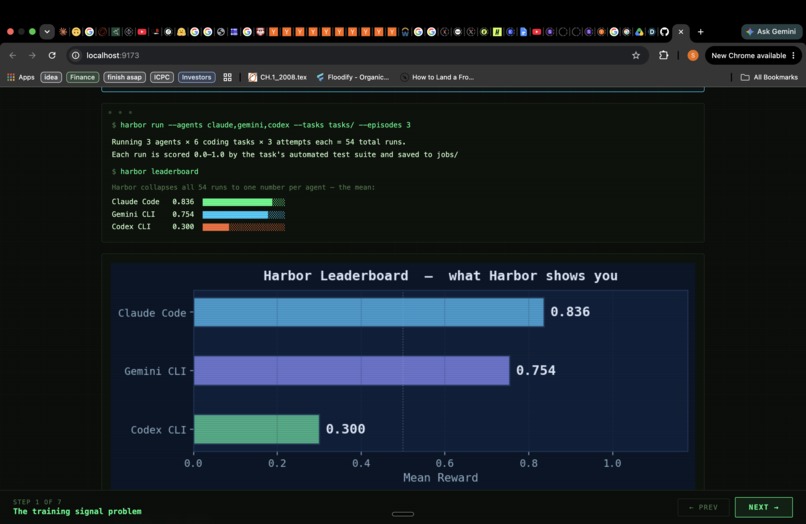
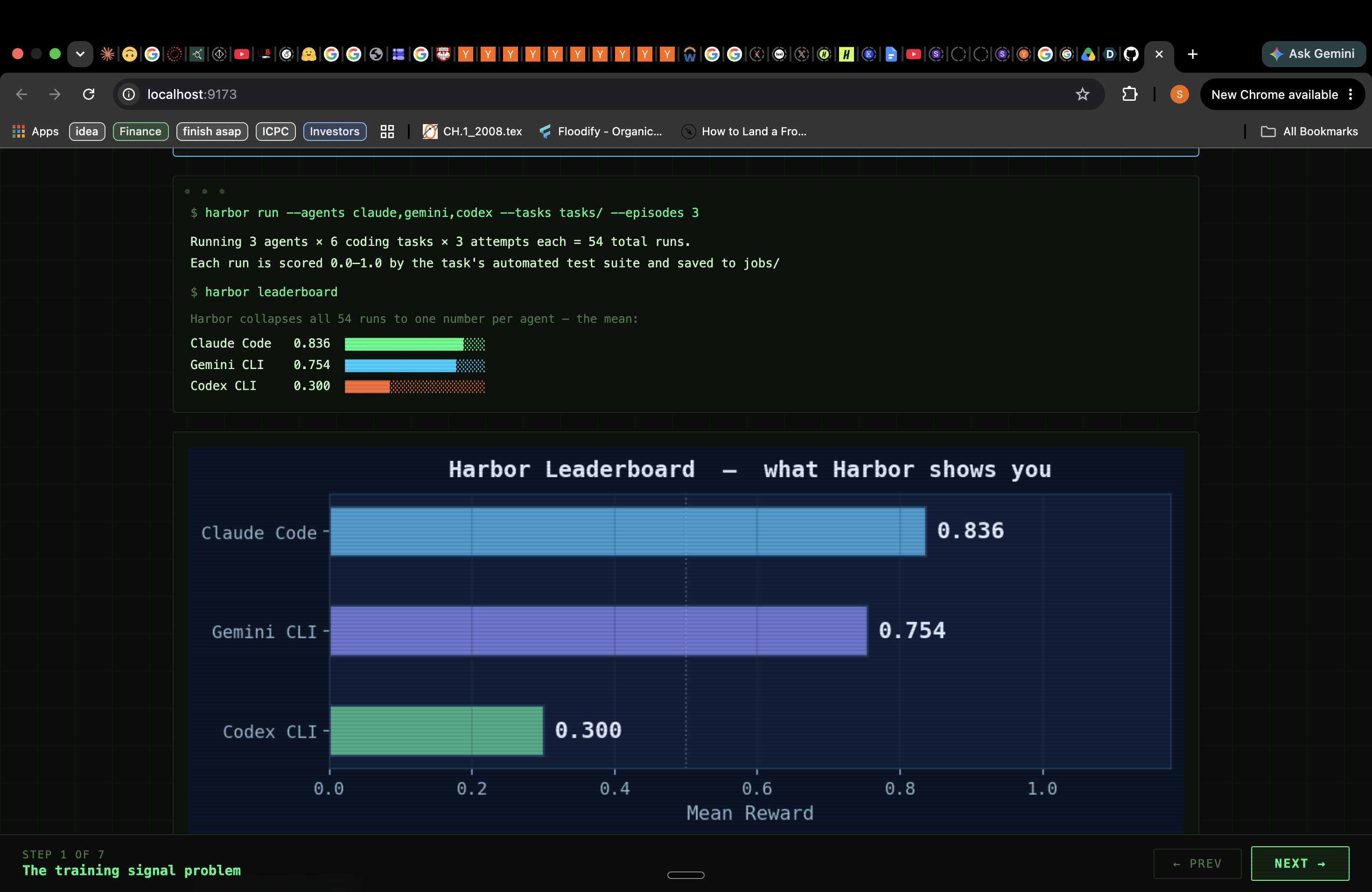
Every AI agent benchmark we looked at reported a single number: mean reward. You'd see a leaderboard like:
| Agent | Score |
|---|---|
| Claude Code | 0.836 |
| Gemini CLI | 0.754 |
| Codex CLI | 0.300 |
And that's it. That's supposed to tell you something useful.
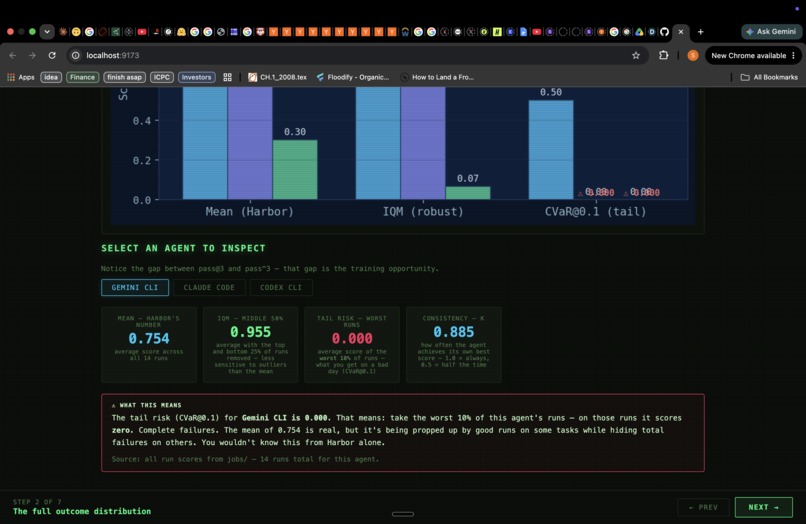
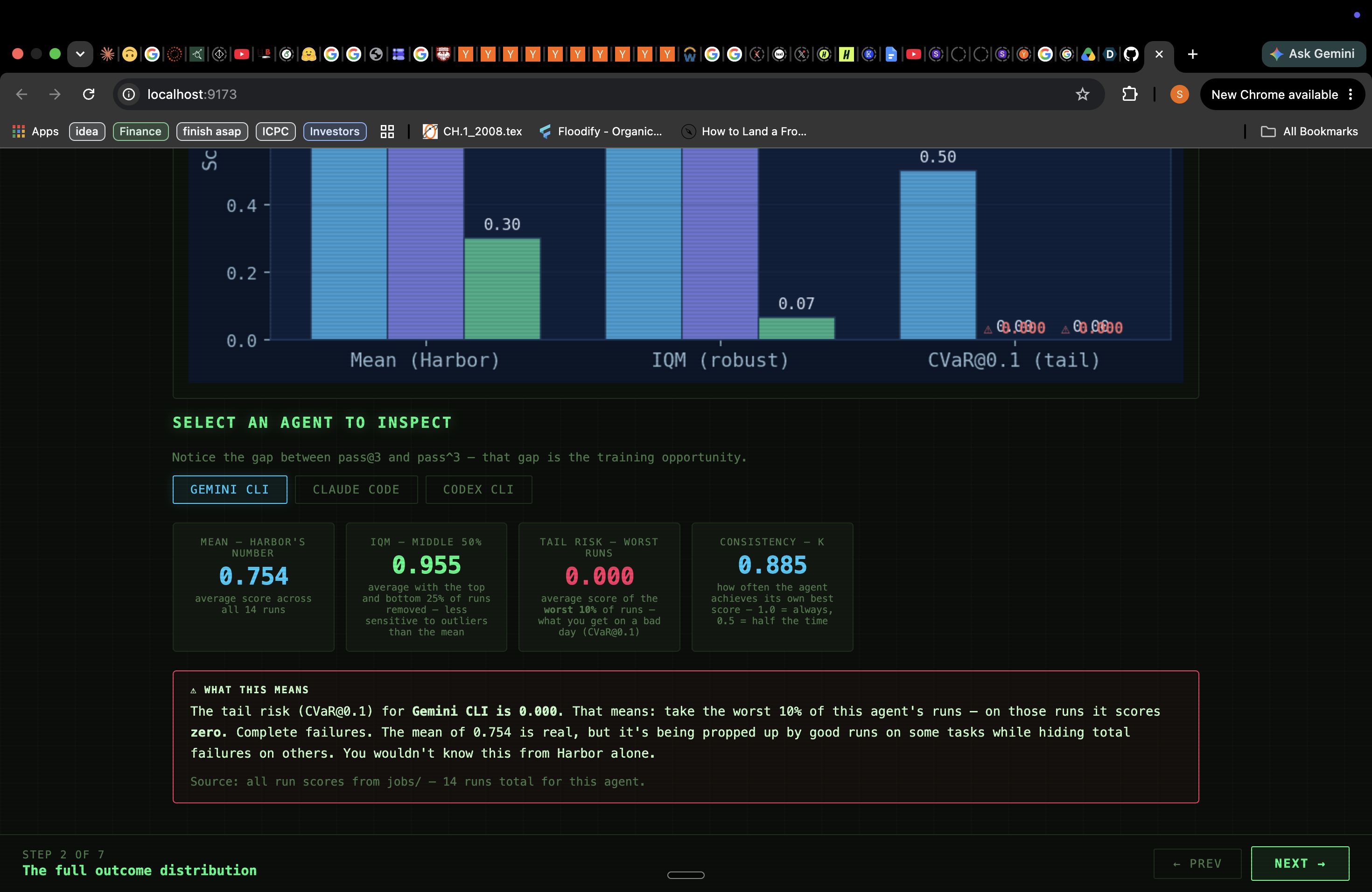
The problem hit us when we looked at the actual run data underneath one of those means. Gemini's 0.754 was hiding something: on easy tasks — the kind a junior developer handles in five minutes — Gemini's CVaR@0.1 was 0.000. Not low. Zero. In its worst 10% of runs on easy tasks, Gemini scored nothing. The mean had completely obscured a tail collapse that would be catastrophic in any real deployment.
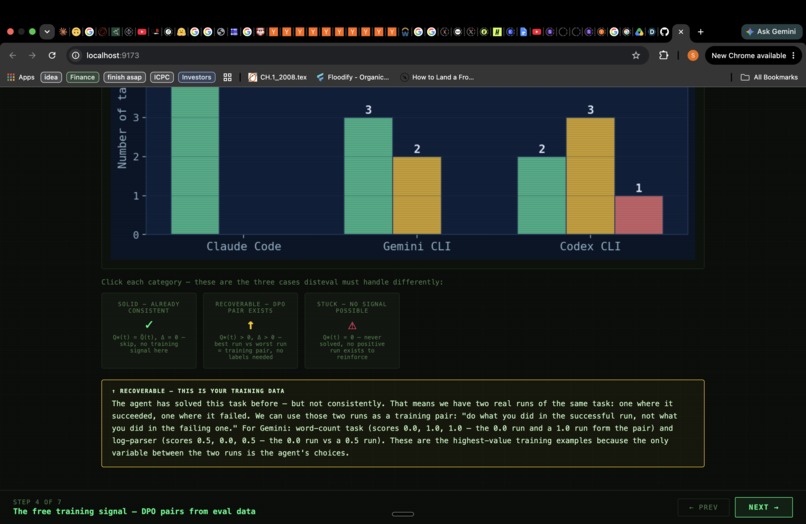
But the deeper insight came from looking at Codex. Its mean was 0.300 — looked like a weak agent. But when we ran the same tasks three times each, we found that Codex had solved medium-rest-client perfectly. Once. It also solved easy-fizzbuzz perfectly. Once. The agent demonstrably knew how to do these things. It just couldn't do them consistently.
That's a completely different problem from "the agent can't do this." And mean reward treats them identically. That's what disteval is about.
What it does
disteval takes your existing agent eval runs and does three things no standard benchmark does:
1. Measures the full outcome distribution. Five metrics instead of one:
| Metric | What it tells you |
|---|---|
| IQM | Outlier-resistant center — mean with top/bottom 25% stripped |
| CVaR@0.1 | Expected score in the worst 10% of runs — tail risk |
| pass@$k$ | $P(\geq 1$ success in $k$ tries) — peak capability |
| pass$^k$ | $P(\text{all } k$ tries succeed) — deployment consistency |
A large gap between pass@$k$ and pass$^k$ is the signature of inconsistency.
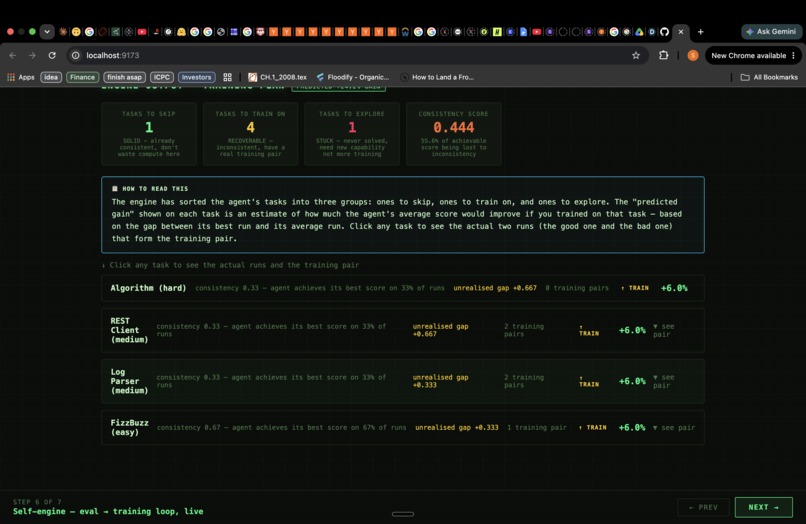
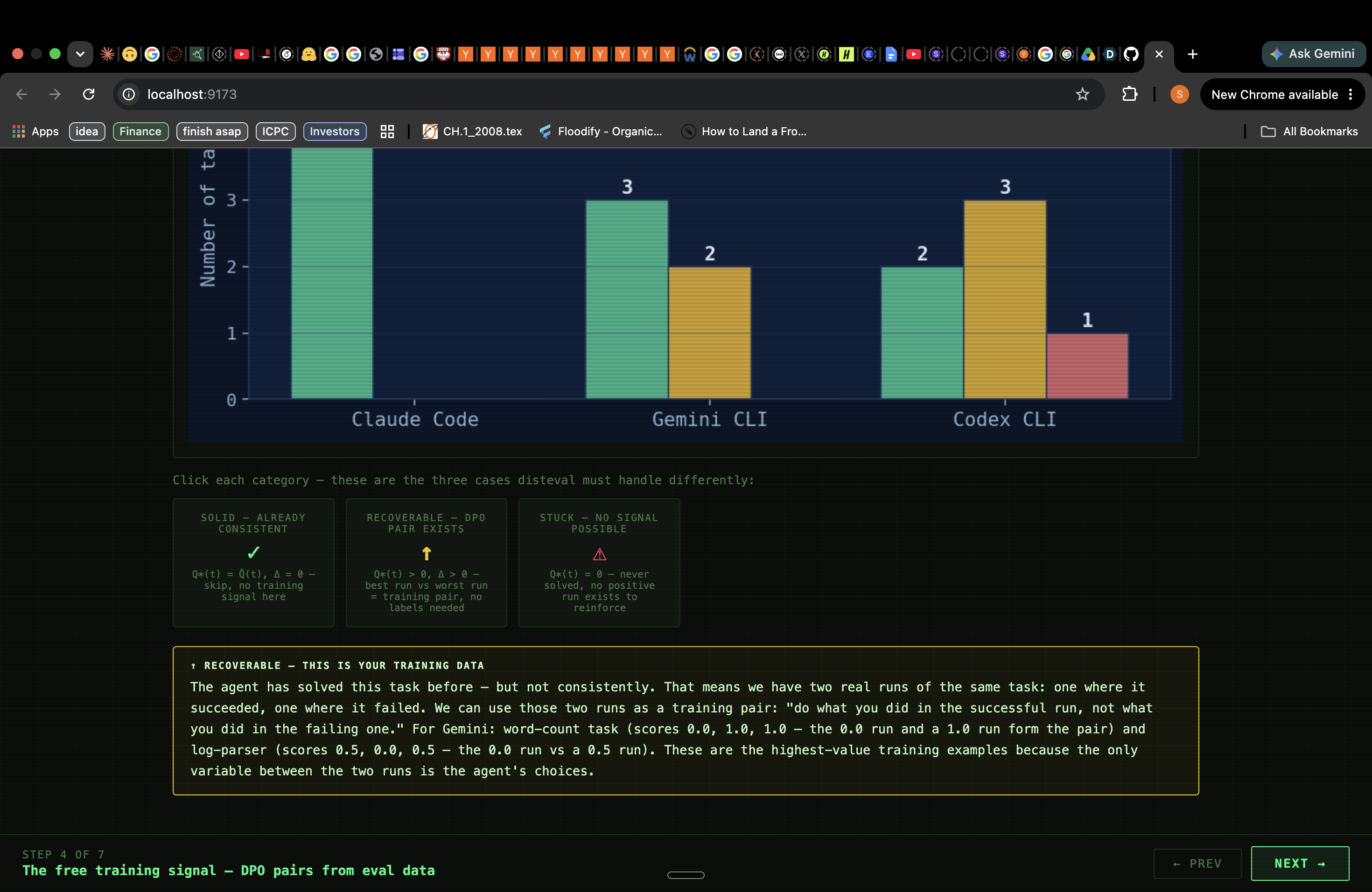
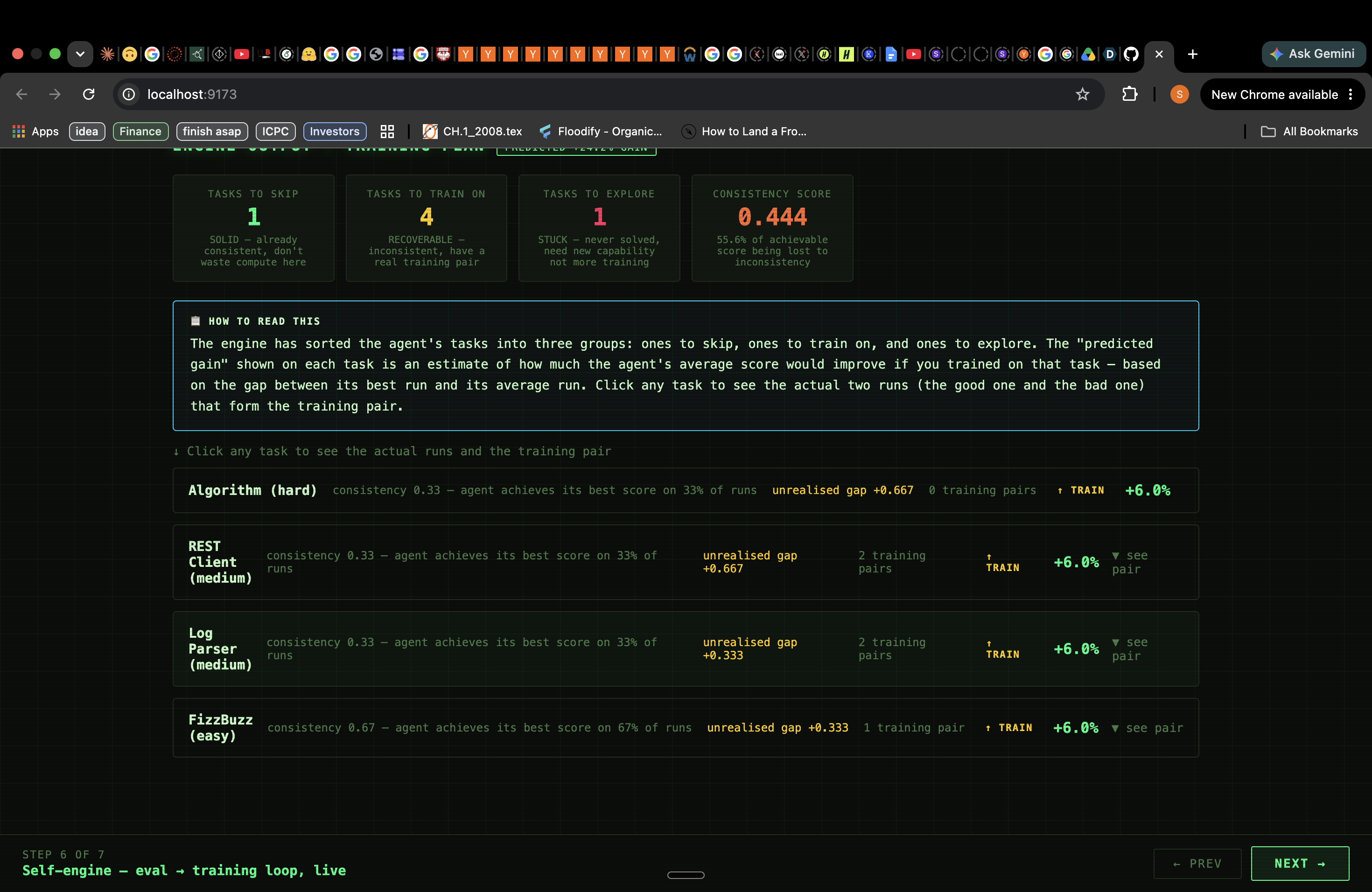
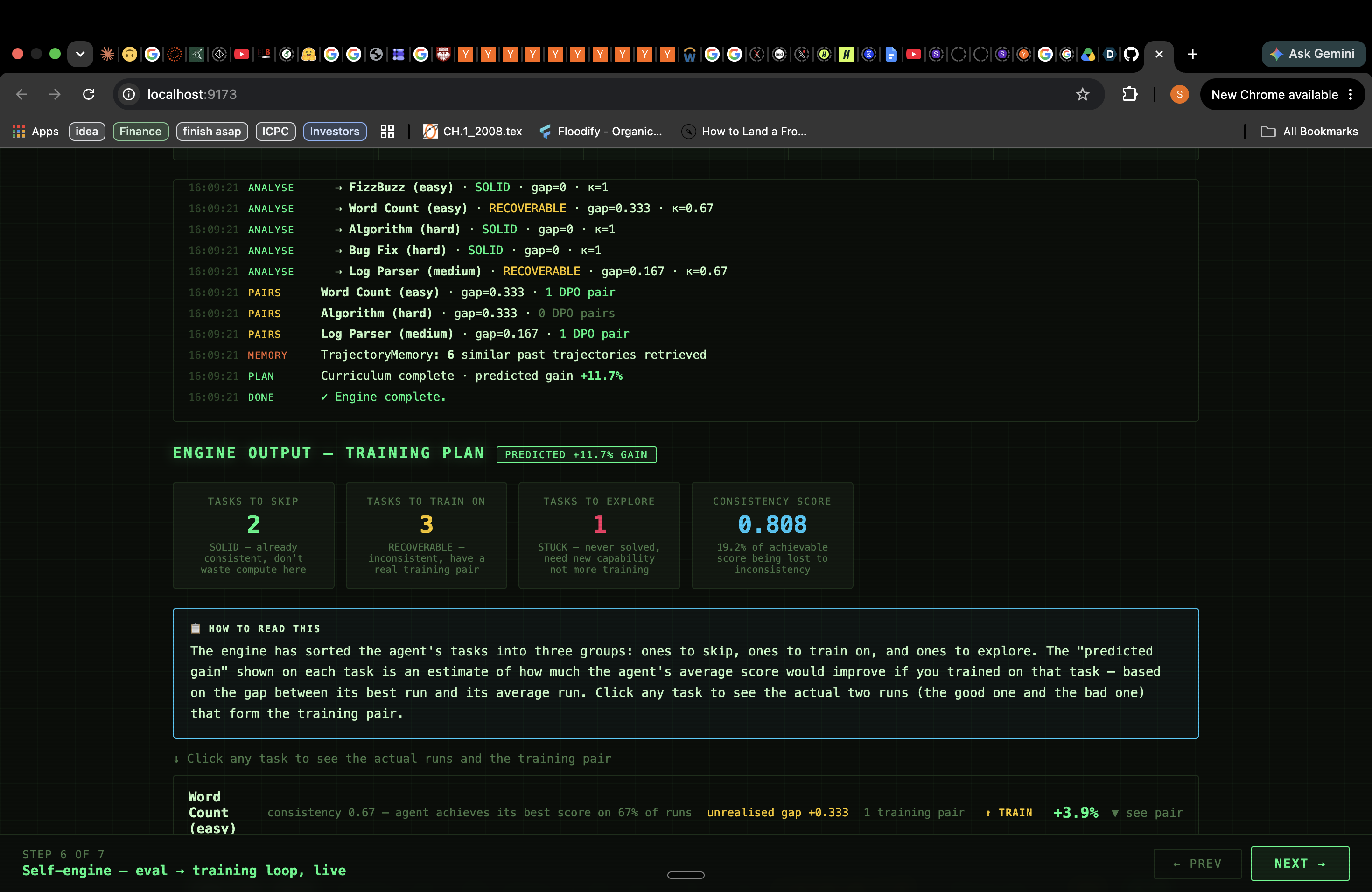
2. Classifies every task as SOLID, RECOVERABLE, or STUCK. For each (agent, task) cell, disteval computes:
$$Q^*(t) = \max_i\, q_i \qquad \text{(demonstrated peak capability)}$$
$$\Delta(t) = Q^*(t) - \bar{Q}(t) \qquad \text{(recoverable gap)}$$
$$\kappa(t) = \frac{\bar{Q}(t)}{Q^*(t)} \qquad \text{(consistency index, } \kappa \in [0,1]\text{)}$$
| Class | Condition | Meaning |
|---|---|---|
| SOLID | $Q^* > 0,\ \Delta = 0$ | Consistently achieves best — nothing to recover |
| RECOVERABLE | $Q^* > 0,\ \Delta > 0$ | Can do it but doesn't always — DPO pair exists |
| STUCK | $Q^* = 0$ | Never solved — needs new capability, not consistency training |
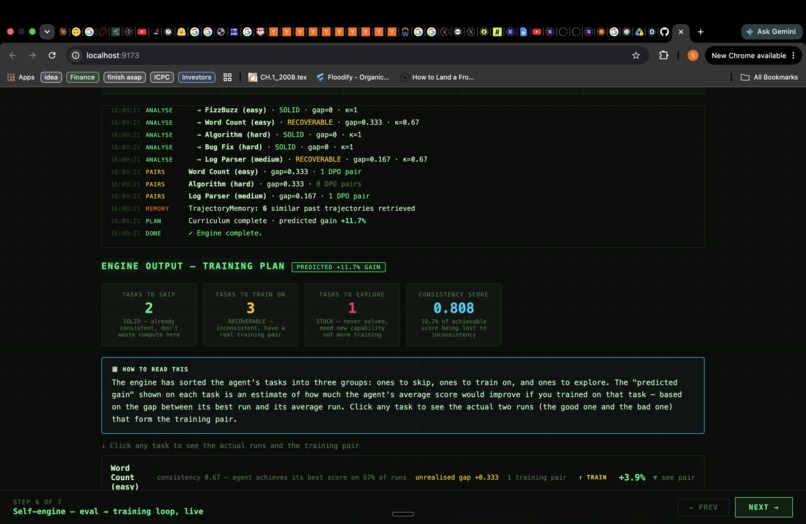
3. Generates a ranked training curriculum automatically. For every RECOVERABLE task, a passing run and a failing run already exist in your eval data. disteval extracts those trajectory files, identifies the structural divergence step (where the two runs first made a different tool-call choice), ranks tasks by $\Delta(t) \times (1 - \kappa(t))$, and outputs a JSON curriculum ready to feed into any DPO trainer. No human labels. No synthetic data.
disteval engine jobs/run_1/ --agent my-agent --output plan.json
The loop: eval → distribution → taxonomy → training pairs → retrain → eval again. $\kappa$ rises each cycle.
How we built it
The architecture has four layers:
Records layer — EpisodeRecord and RecordStore. The first principle was never collapse early. Every adapter preserves per-episode scores so IQM, CVaR, and pass$^k$ can be computed on demand. Most eval frameworks aggregate before you can stop them; disteval lifts the raw scores back out.
Metrics layer — metrics.py, bootstrap.py, compare.py. Stratified bootstrap CIs resample within difficulty strata to preserve task heterogeneity. Wasserstein distance, KS test, and stochastic dominance for head-to-head agent comparison. A rliable bridge converts to {algo: ndarray[n_runs, n_tasks]} format for compatibility with existing tooling.
Right-tail layer — right_tail.py. The core $Q^*$, $\bar{Q}$, $\Delta$, $\kappa$ computation. The SOLID/RECOVERABLE/STUCK classification. Priority ranking by $\Delta \times (1 - \kappa)$. The trajectory featurizer extracts tool-call sequences and finds the structural divergence step between passing and failing runs.
Self-engine — self_engine.py. Assembles everything in one call: loads trajectories from Harbor job directories, runs right-tail analysis, finds divergence steps, queries trajectory memory for similar past successes, and writes the ranked JSON curriculum.
We also built a real-time trajectory monitor — the structural signature of an agent's tool-call sequence predicts final outcome with 89% leave-one-out accuracy before the run finishes. An agent doing web_search × 8 at step 3 already has $p(\text{success}) = 0.07$, before it has written a single line of code.
We validated against three real agents (Claude Code, Gemini CLI, Codex CLI) running six Harbor tasks across three attempts each — 54 episodes total, all real data, no synthetic inflation.
Challenges we ran into
The "failing run" problem. Our first instinct for the demo was to show a live replay of a passing run vs. a failing run side by side. We spent a lot of time looking for a case where the agent had written wrong code — not just crashed or hit a network error, but produced a plausible-but-incorrect solution. In our dataset, most failing runs never produced code at all; the failures were infrastructure errors or the agent getting stuck in search loops. The cases where both a wrong-code failure and a correct-code success existed for the same task were rare. We eventually removed the replay panel — the data didn't support the story we wanted to tell with it.
Mean reward's stickiness. The hardest conceptual challenge was explaining why the right-tail signal is strictly better, not just "more information." The key is the taxonomy: mean reward cannot distinguish RECOVERABLE from STUCK, and the intervention for each is completely different. RECOVERABLE tasks have a solution sitting in your jobs/ directory right now. STUCK tasks need new capability. Mean reward forces you to treat them identically, which points the gradient in the wrong direction for both.
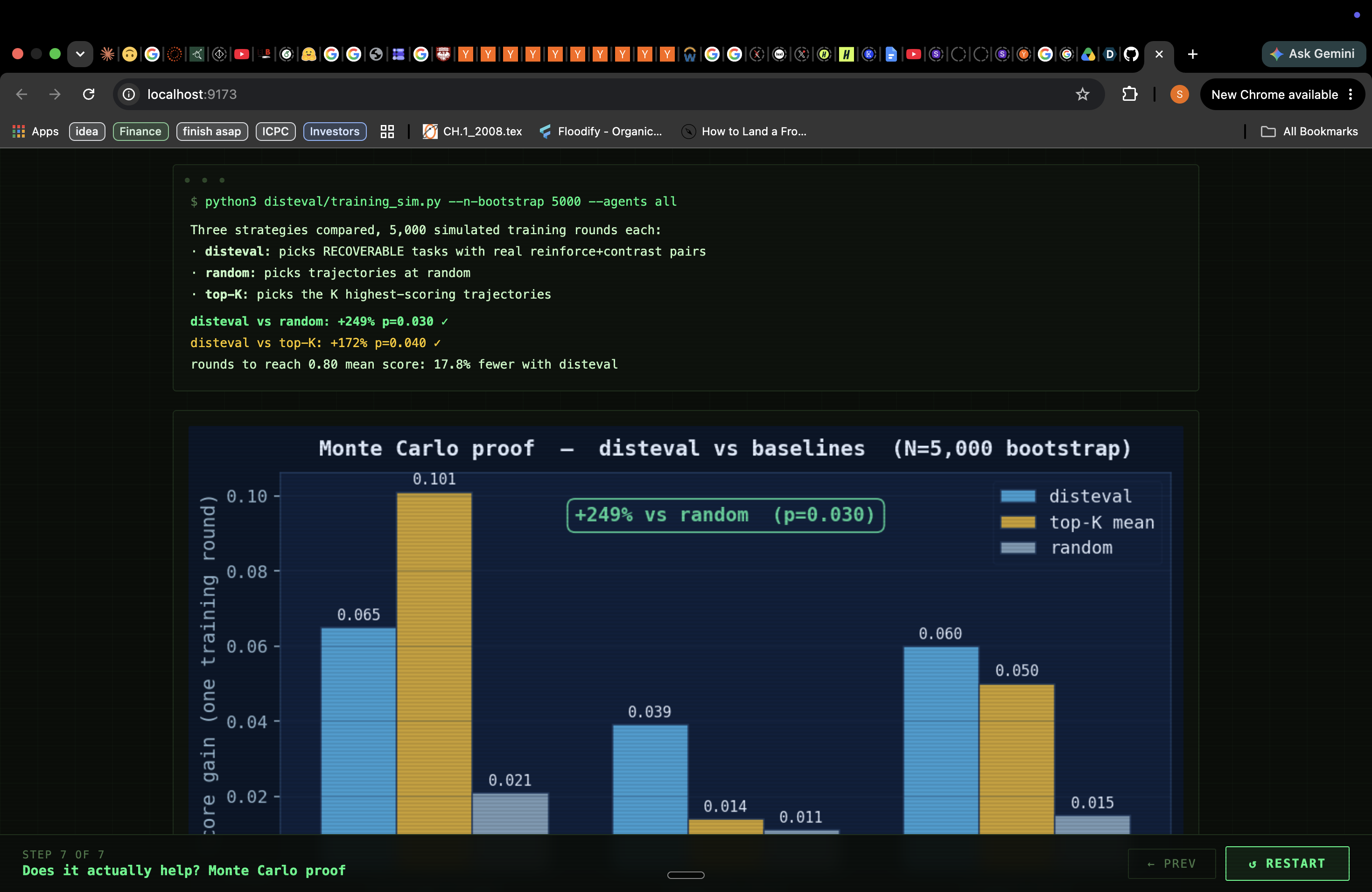
Closing the loop without a live training run. We can generate the DPO pairs and rank them by leverage. What we can't yet show is $\kappa$ going from 0.63 to 0.85 after a training round, because we haven't run the full fine-tuning experiment end-to-end. The Monte Carlo simulation (showing +249% improvement in score gain vs. random trajectory selection) is the current evidence, but it's a bootstrap simulation over existing score distributions, not a live training result.
Accomplishments that we're proud of
The taxonomy is tight. SOLID / RECOVERABLE / STUCK cleanly partitions every (agent, task) cell, and the partition directly implies the right action for each class. We haven't seen this framing anywhere else — most eval work stops at "here's a better metric" without connecting the metric to a concrete training intervention.
The data confirmed the theory. On real benchmark data, Codex's consistency index $\kappa = 0.63$ — meaning 37% of its theoretically achievable score is recoverable without teaching it any new skills. That number came out of 54 real runs, not a simulation.
The pipeline closes end-to-end. disteval engine goes from raw Harbor job directories to a JSON curriculum with actual file paths in one command. The output is immediately consumable by a DPO trainer — no intermediate steps, no manual annotation.
89% trajectory prediction accuracy with no ML infrastructure. The outcome predictor is logistic regression in pure numpy — no model training server, no embeddings, no vector database. It runs in under a second on 37 training trajectories.
What we learned
The distribution is the signal. Mean reward isn't a lossy compression of performance — it's a lossy compression that specifically loses the information you need most. The gap between pass@$k$ and pass$^k$ tells you more about an agent's deployment readiness than any single aggregate. And the trajectories that sit in your eval data, discarded after the leaderboard updates, contain the training pairs that could close that gap.
The right-tail framework connects three things usually treated as separate problems: evaluation (how good is this agent?), diagnosis (where is it inconsistent?), and training (what data fixes it?). The insight is that they're not separate — the eval data, analyzed at the right level of granularity, directly answers all three.
We also learned that framing matters as much as the math. Calling it a "better leaderboard" undersells it completely. The pitch is: your eval runs are already generating training data. You just haven't been reading them correctly.
What's next for DistEvaL
Close the loop with a real training run. The most important next step is running disteval's curriculum through an actual DPO fine-tuning round on a real agent, re-evaluating, and measuring whether $\kappa$ rises as predicted. The theory and simulation are solid — the missing piece is the empirical validation.
Larger benchmark. Six tasks across three agents is enough to demonstrate the framework; it's not enough to publish a result. We want to run disteval on a 50+ task benchmark across 5+ agents to get statistically robust estimates of how much recoverable score exists in practice across different task domains.
Integrate with training pipelines. The curriculum JSON format is already specified in CURRICULUM_FORMAT.md. The next step is building first-class integrations with TRL (DPO trainer), Axolotl, and OpenRLHF so the disteval engine output can be consumed without any glue code.
Extend to multi-turn and tool-use agents. The current trajectory format handles single-episode tool-call sequences well. Long-horizon tasks with sub-tasks, handoffs, and multi-agent coordination need a richer trajectory schema and a divergence-step algorithm that works at the sub-task level.
Publish the consistency index as a standard eval metric. $\kappa$ is computable from any benchmark that runs $k > 1$ attempts per task. We want to propose it as a standard alongside IQM and CVaR in the rliable / eval reliability literature — a single number that captures the fraction of demonstrated capability an agent actually deploys consistently.


Log in or sign up for Devpost to join the conversation.