-
-
TriageAlertAgent — registered, discoverable, and live on Agentverse, reachable through ASI:One
-
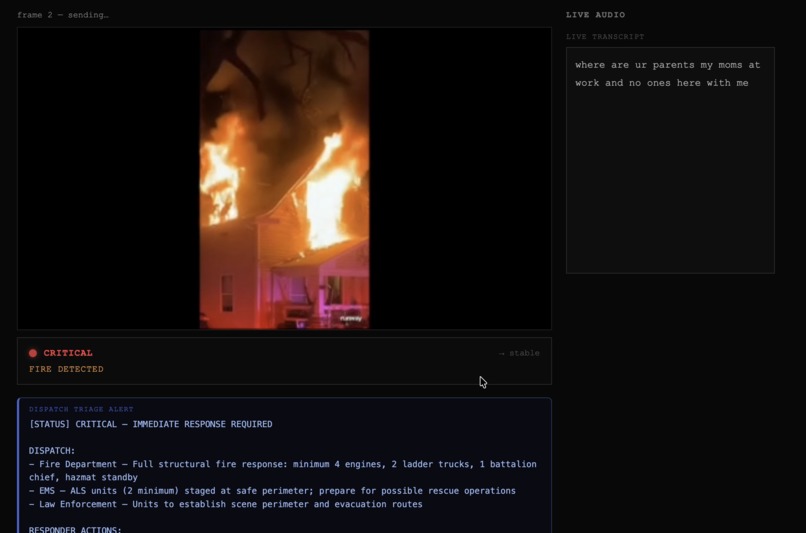
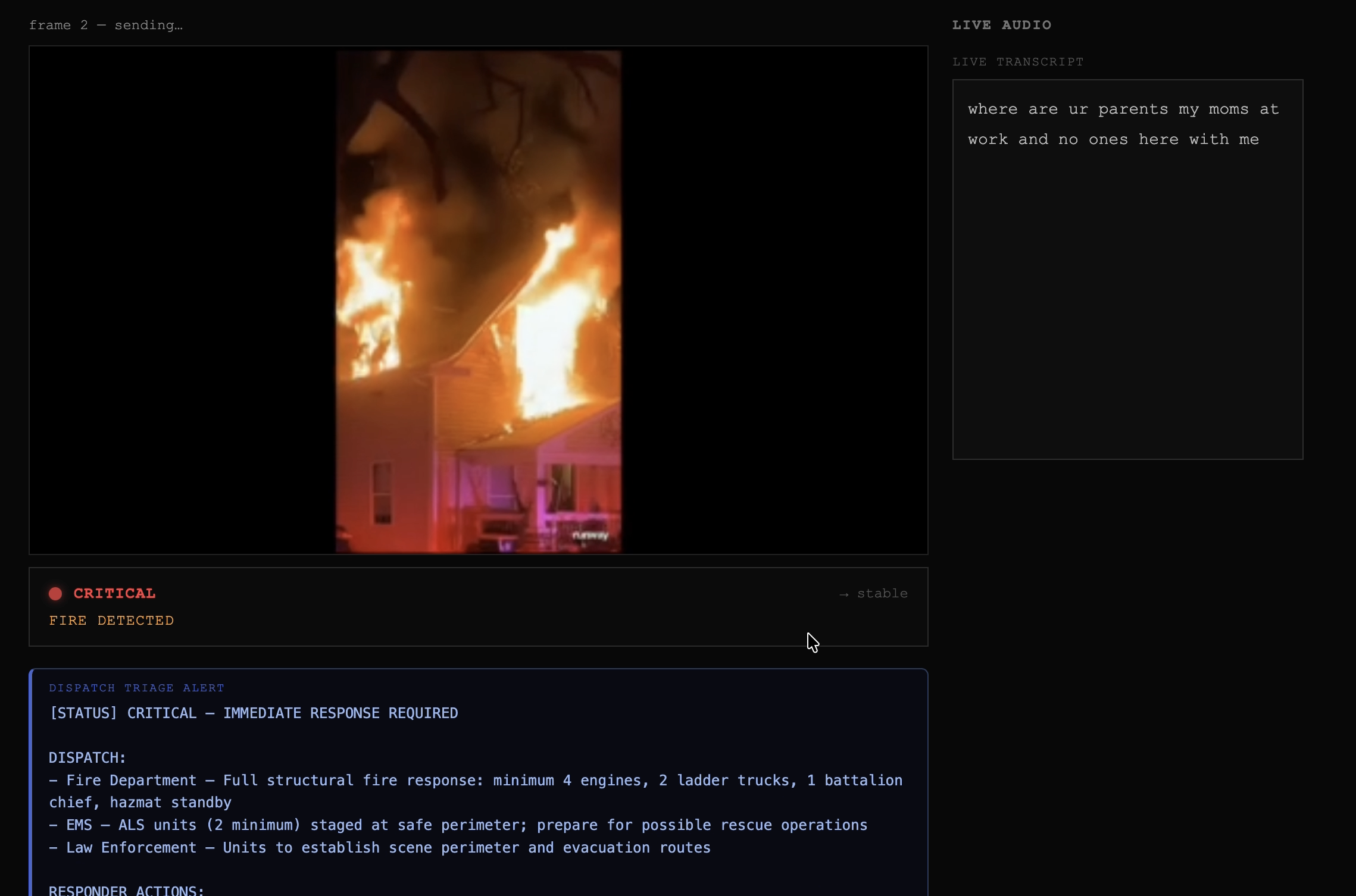
Live video scene and live analysis. Our system injests the feed in real time and flags "critical" the moment fire appears.
-

Scooter accident near Pauley Pavilion. The agent doesn't just describe it: spinal precautions, traffic hazard, EMS unit and ETA in one brief
-
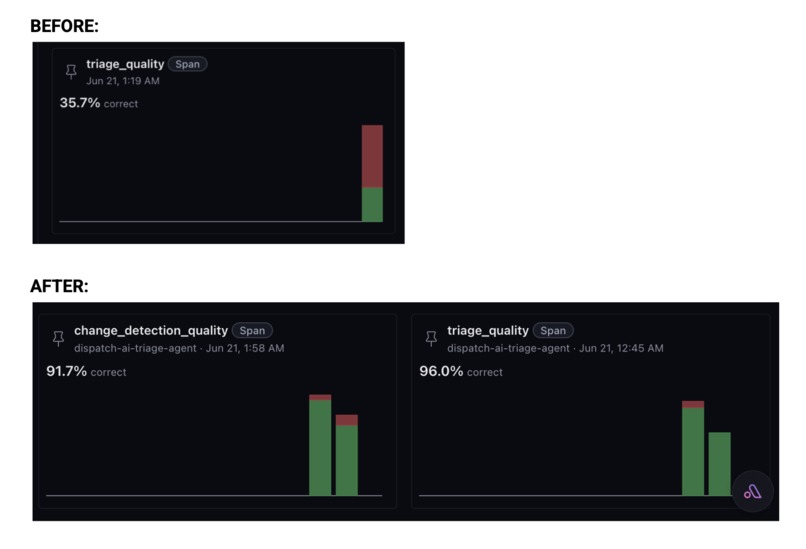
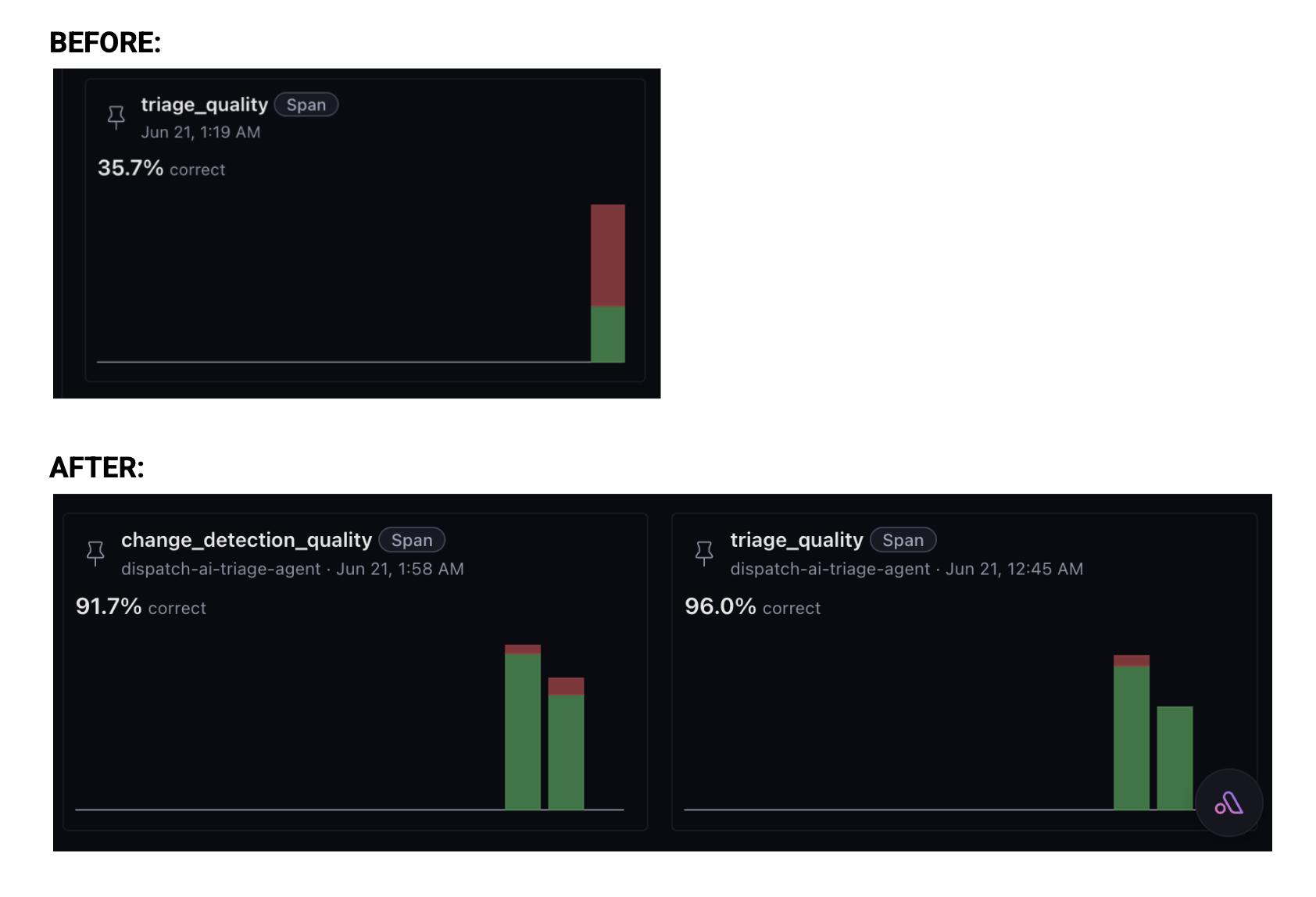
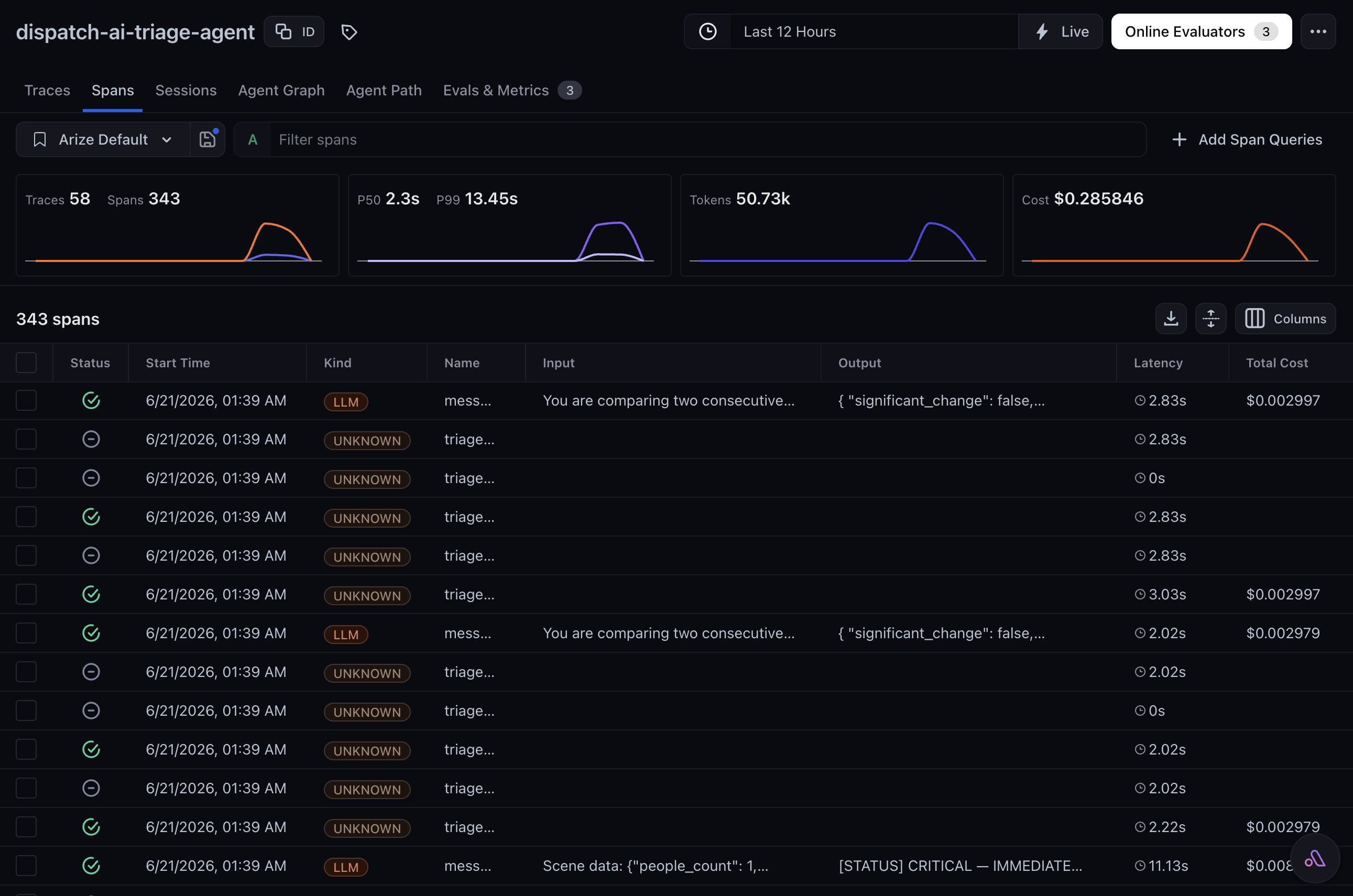
Traced every call, built an evaluator to judge quality, used the feedback to make the agent better, implementing a full Arize loop.
-
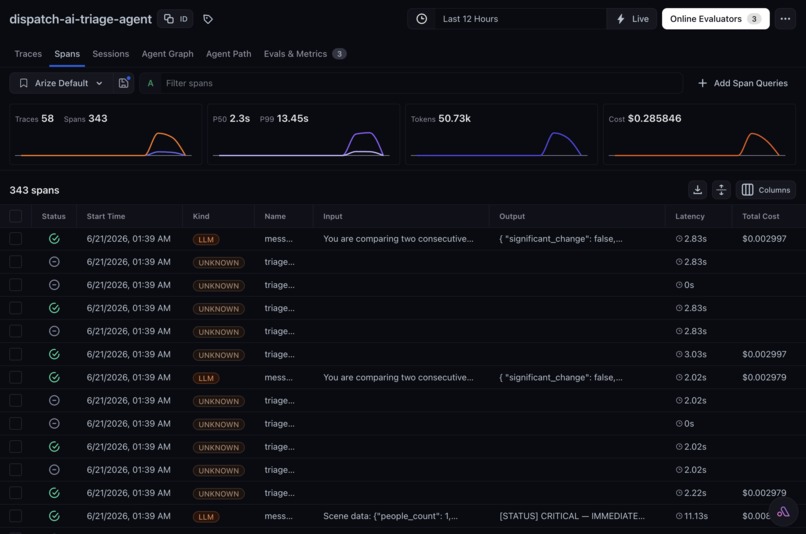
Arize triage span detail showing the scene attributes
-
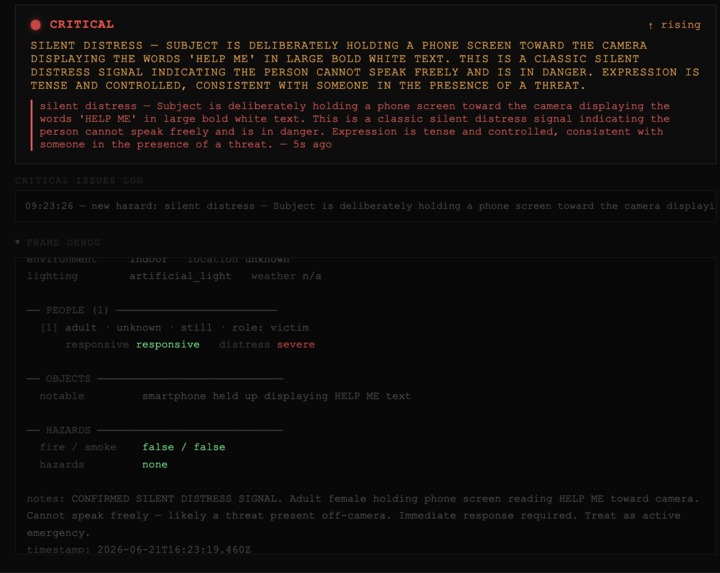
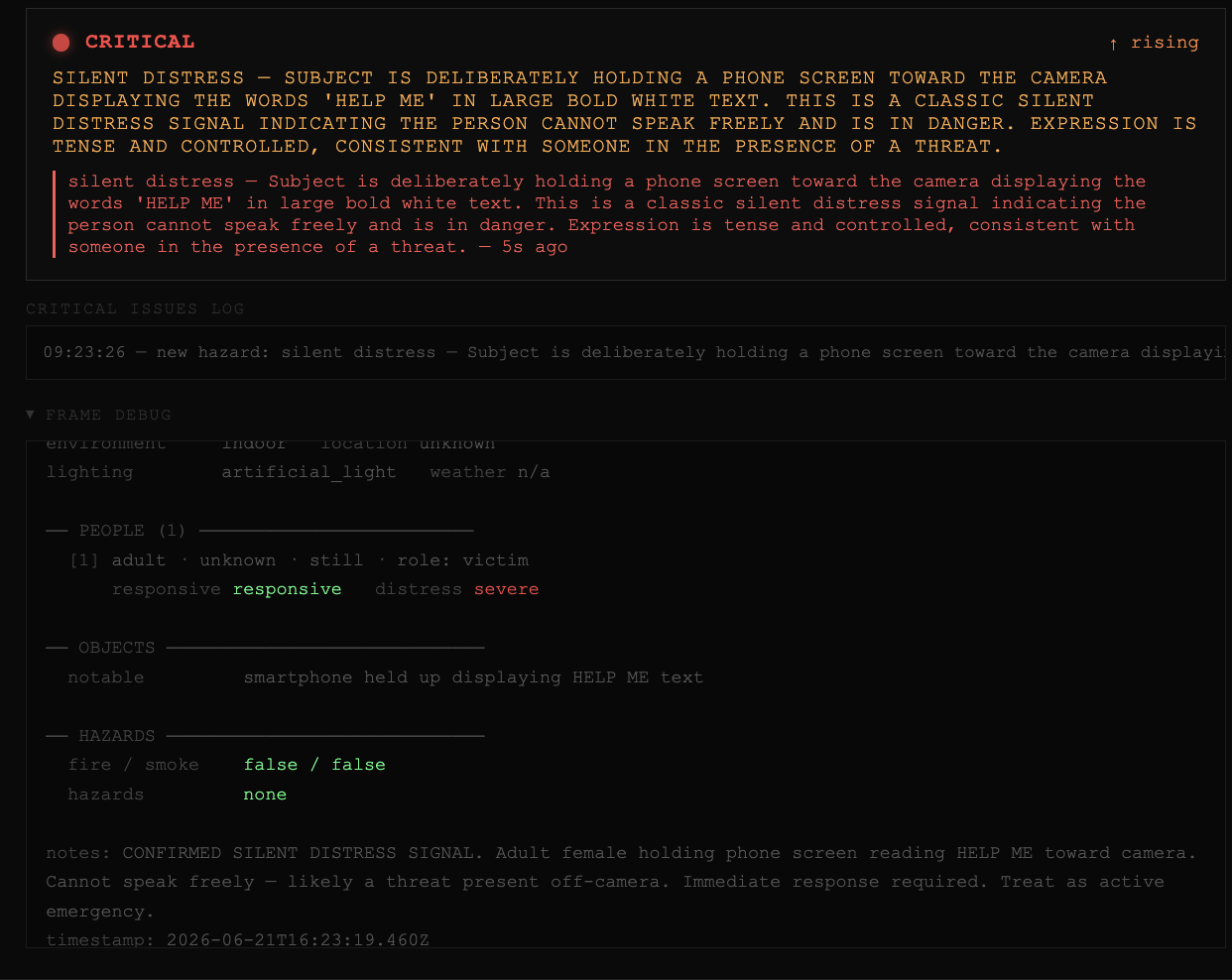
Silent distress signal detected, no audio needed. Agent recognizes a "HELP ME" sign held to the camera and escalates instantly to critical.

Inspiration
Every 911 dispatcher works blind. They hear voices — panicked, frantic, sometimes incoherent — and have to piece together what's happening from words alone. A caller screaming "there's so much blood" tells you something. But it doesn't tell you how many people are injured, whether there's fire spreading in the background, or if the scene is safe for first responders to enter. Dispatchers have always had to make life-or-death resource decisions with incomplete information.
We wanted to change that. Not by replacing the dispatcher, but by giving them eyes.
What it does
Dispatch AI turns any caller's phone into an intelligent first responder. The moment a 911 call comes in, the caller receives a link. They tap it, point their camera at the scene, and our vision agent begins analyzing the live feed every few seconds — identifying injuries, fire, smoke, hazards, number of people, and even silent distress signals. That information flows to a triage agent that reasons over the scene and produces a structured incident brief: who to dispatch, what responders need to know before they arrive, and what the scene implies that isn't immediately visible. The triage agent then contacts an EMS routing agent that returns the nearest available unit, its ETA, the closest AED drone pad, and a What3Words precision location — all within the same response.
The TriageAlertAgent is discoverable and operable through ASI:One. Dispatchers can also type plain-text descriptions directly into the chat interface, and the agent parses those into the same structured pipeline.
How we built it
Vision layer (Node.js / Express)
The frontend captures video in the browser using WebRTC's captureStream() API, sampling frames every few seconds and POSTing them as base64 JPEG to our Express server. Claude Sonnet analyzes each frame and returns structured JSON across 20+ fields: people, injuries (with severity and body part), fire, smoke, hazards, visible text, object detection, and a silent_distress boolean that scans every pixel of readable text and every visible gesture for coercion signals. The server also handles a parallel audio path: it transcribes caller speech with Claude Haiku, detects distress keywords (including weapon references), runs language detection, and translates non-English audio to English in real time before merging audio signals into the frame result. Failures return a degraded result rather than breaking the capture loop — the dispatcher always sees something.
Schema adaptation
The vision agent returns a rich nested schema (arrays of people, arrays of injuries by person ID). The triage agent expects a flat scene format. An adapt_frame() function translates between them at the boundary — computing per-person aggregates (worst injury severity, whether anyone is unresponsive, motion status across all people), flattening the injury array into scalar estimates, and surfacing silent distress and weapon detections as top-level fields before passing the result downstream.
TriageAlertAgent (Python / uAgents / Fetch.ai)
The TriageAlertAgent is built on Fetch.ai's uAgents framework using the chat protocol spec, registered on testnet, and operable through ASI:One. It receives structured JSON frame-by-frame over the chat protocol and maintains an in-memory scene store (last_scene_store) that persists context across messages for the lifetime of the process.
Each incoming frame goes through a two-layer change detection pipeline before any Claude call is made:
Fast heuristics (no LLM): Eleven specific conditions are checked with direct comparisons — fire appearing for the first time, victim becoming unresponsive, victim stopping movement, silent distress newly detected, audio distress keywords detected, new hazards added, bleeding or injury severity increasing, people count rising, camera obstruction (confidence < 0.2), and scene resuming after obstruction. If any fast flag fires, the agent skips the LLM and returns immediately with the reason.
Claude fallback: If no fast flag fires, Claude compares the previous and current scene JSON and decides whether the change is significant enough to alert the dispatcher. This handles ambiguous cases like a change in recommended units or an urgency shift that doesn't map neatly to a single field.
When a scene change warrants an alert, Claude Sonnet generates the dispatcher brief: a status line (CRITICAL through LOW PRIORITY), dispatch recommendations, ordered responder actions, and a brief scene summary. The prompt is engineered to lead with action — what to do and what the scene implies — not to restate what the camera detected. All outputs use "recommend dispatching" language; the agent never implies a dispatch has been executed.
If the computed urgency is 3 or higher, the agent simultaneously fires an EmsRequest (typed uAgents Model) to a companion EMS & AED Drone agent containing the emergency ID, address, chief complaint derived from the scene fields, and GPS coordinates. The EMS agent returns a typed EmsResult with the nearest available unit, its ETA in seconds, the closest AED drone pad, and a What3Words precision location. The EMS routing block is appended to the triage brief before it's sent back to the dispatcher.
Observability
The production agent is fully instrumented with Arize Phoenix OpenTelemetry tracing. Every Claude call, every fast-check evaluation, and every change detection decision is captured as a named span with scene metadata attributes, so the full decision trace is visible and evaluable in the Arize dashboard.
SMS / QR delivery
The system is designed to send the video link automatically via Twilio the moment a 911 call comes in. Due to carrier A2P 10DLC registration timelines, SMS approval was not completed within the hackathon window. For the demo, the link is delivered via a QR code on the dispatcher dashboard — the caller scans it and the experience is identical from that point forward. The SMS infrastructure (sms_trigger.py) is fully built and ready to activate once the number clears.
Claude
Claude does three different jobs in this system, not one. It reads each video frame and turns it into structured scene data: people, injuries, hazards, fire, confidence. It decides whether a change between two frames is actually significant, but only when hard-coded checks can't already tell (fire appearing or a victim going unresponsive get caught instantly, no model call needed, Claude only steps in for the ambiguous cases). And it writes the dispatcher-facing brief itself, which we spent a lot of time getting right.
The triage agent also calls a second agent on Agentverse for EMS and drone routing, so Claude's output it triggers a real action and folds the result back into the response.
We kept every Claude call narrow. The vision call only sees one frame at a time. The change-detection call only sees the previous and current scene, nothing else. The brief-generation call sees the current scene and why it was flagged. No call carries a growing conversation history, temporal reasoning comes from the last_scene_store dictionary holding state between messages, not from accumulating context inside the model. That separation is part of why the pipeline stays fast even with multiple model calls in the loop: each call gets exactly the data it needs, and memory lives in our code, not in the prompt.
We built it this way because 911 dispatch is a real, painful, time-critical problem, and most of what's hard about it isn't model capability, it's making sure the model says the right thing at the right instance.
We also used Claude Code to develop our project, with the four of us working on different pieces (vision, triage logic, the EMS integration, the dashboard) at the same time, in the same codebase. Once we established the JSON contract between the vision and triage agents, Claude Code wrote adapt_frame() to bridge them, implemented our two-layer change-detection logic from a plain-English spec, and helped iterate on the system prompts until "action-first" output actually meant something concrete. It also wired up the EMS agent integration, and when one of us hit a ctx.storage persistence bug, it diagnosed the issue and replaced it with the module-level dictionary that fixed it. Working directly against the running codebase, instead of writing in isolation and reconciling later, is a big part of why four people could move this fast in a day.
Challenges we ran into
A2P 10DLC registration. US carriers require programmatic SMS senders to complete a multi-day registration process. We pivoted to a QR code flow that preserved the demo experience.
State management across uAgents messages. The uAgents framework's built-in ctx.storage does not persist reliably between separate incoming messages when running locally, causing the agent to treat every frame as an initial assessment and alert on every input. We replaced it with a module-level last_scene_store dictionary that holds the last scene and last triage result for the lifetime of the running process, restoring correct change detection across the full frame sequence.
Schema contract between agents. The vision agent and triage agent had to agree on field names and types. That contract broke multiple times during integration. We learned to define the shared schema first and build to it, rather than reconciling mismatches after the fact. The adapt_frame() function now serves as the formal boundary between the two schemas.
Prompt engineering for dispatcher output. The natural tendency of a language model is to summarize what it sees. Dispatchers already have the raw feed. Getting the agent to consistently lead with what the scene implies — what risks aren't visible yet, what could change in the next 60 seconds — required many iterations of the system prompt and testing against realistic frame sequences.
Real-time performance. Frame analysis had to feel fast enough to be useful. We tuned frame intervals, compressed JPEG quality, structured the fast-check layer to bypass Claude entirely for the most time-critical signals, and built the server to return degraded results rather than fail silently when a frame can't be analyzed.
Accomplishments we're proud of
We built a working end-to-end pipeline in a single hackathon day: phone camera → Claude vision → schema adapter → uAgents triage → EMS routing → dispatcher brief. The system requires zero buy-in from dispatch centers, zero app downloads from callers, and zero enterprise contracts. Anyone with a phone and a browser can be the data source.
The two-layer change detection is the technical piece we're most proud of. The most dangerous changes — fire, unresponsiveness, silent distress, weapon keywords — are caught in microseconds through direct field comparisons with no model call. Claude only gets involved when the situation is genuinely ambiguous. A stable scene stays quiet. A deteriorating scene escalates immediately.
Silent distress detection is one of our strongest features. The vision agent scans visible text in frame — phone screens and handwritten notes — and watches for coercion gestures like a raised hand with extended fingers or exaggerated eye movements. If a caller is being coerced or can't speak freely, the system can detect it even when they say nothing.
The real-time audio path — transcription, language detection, translation, keyword extraction — means non-English speaking callers are not invisible to the system. Language barriers cost lives in emergency response; we built to eliminate that gap.
What we learned
The infrastructure barrier in emergency response is real. Existing solutions require dispatch centers to sign enterprise contracts. By pushing the intelligence to the civilian side — making the caller the data source — you bypass that barrier entirely. Any center can read a plain-text incident brief. No contract required.
We also learned that the bottleneck in emergency dispatch isn't data availability. It's dispatcher cognitive load. More information isn't always better. A well-reasoned summary that leads with action beats a raw feed every time.
And we found that how you write instructions to an agent matters as much as the code around it. The difference between an agent that describes a scene and one that gives a dispatcher something actionable is entirely in the system prompt. We went through many iterations before it felt right.
What's next for Dispatch AI
- SMS approval and automated delivery once A2P 10DLC registration clears
- Expanded audio coverage: full caller transcript analysis, not just keyword spotting
- Integration with real CAD systems for direct alert routing
- Confidence scoring on dispatch recommendations so dispatchers know when to trust the AI and when to dig deeper
- Multi-camera support for scenes with multiple callers reporting the same incident
- International emergency number support (112, 999, etc.)
- Live Arize evaluations running against real frame sequences to continuously measure triage accuracy
Agentverse Agent Links
Existing Agent We Used https://agentverse.ai/agents/details/agent1qw3239g4tahjmw93fwqqp24hyhelljh70ee6wh59euqgrts0kdqfv8gtdll/profile


Log in or sign up for Devpost to join the conversation.