Inspiration
I've been watching the same thing happen over and over on X and YouTube — a story breaks, and within an hour there are dozens of accounts all posting the same talking points, word for word. New accounts, no history, all pushing one narrative. It's not organic. It's coordinated.
The thing is, trying to fact-check individual posts is a losing game. There's too many of them and the damage is done before anyone catches up. But the coordination itself leaves fingerprints — clusters of accounts created at the same time, identical phrasing, velocity spikes that real conversations just don't produce. That's a graph problem. So I built a system to detect it.
What it does
Disinfo Detector is a multi-agent pipeline that finds coordinated inauthentic behavior across X, YouTube, and the web. Not "is this post true or false" — that's a trap. Instead it asks: "are these accounts behaving like a coordinated campaign?"
It works in two layers.
Layer 1 sources real content from the live web. Tavily runs dozens of targeted searches (site:x.com, news queries) to pull in real posts. Yutori deploys browsing agents that actually navigate X.com and YouTube, scrolling through pages and pulling text, handles, timestamps, and media URLs straight from the DOM. The two cross-verify each other — Tavily's metadata is often wrong (reported 958 followers for an account that actually has 18,800), so Yutori browses the real profile to get ground truth.
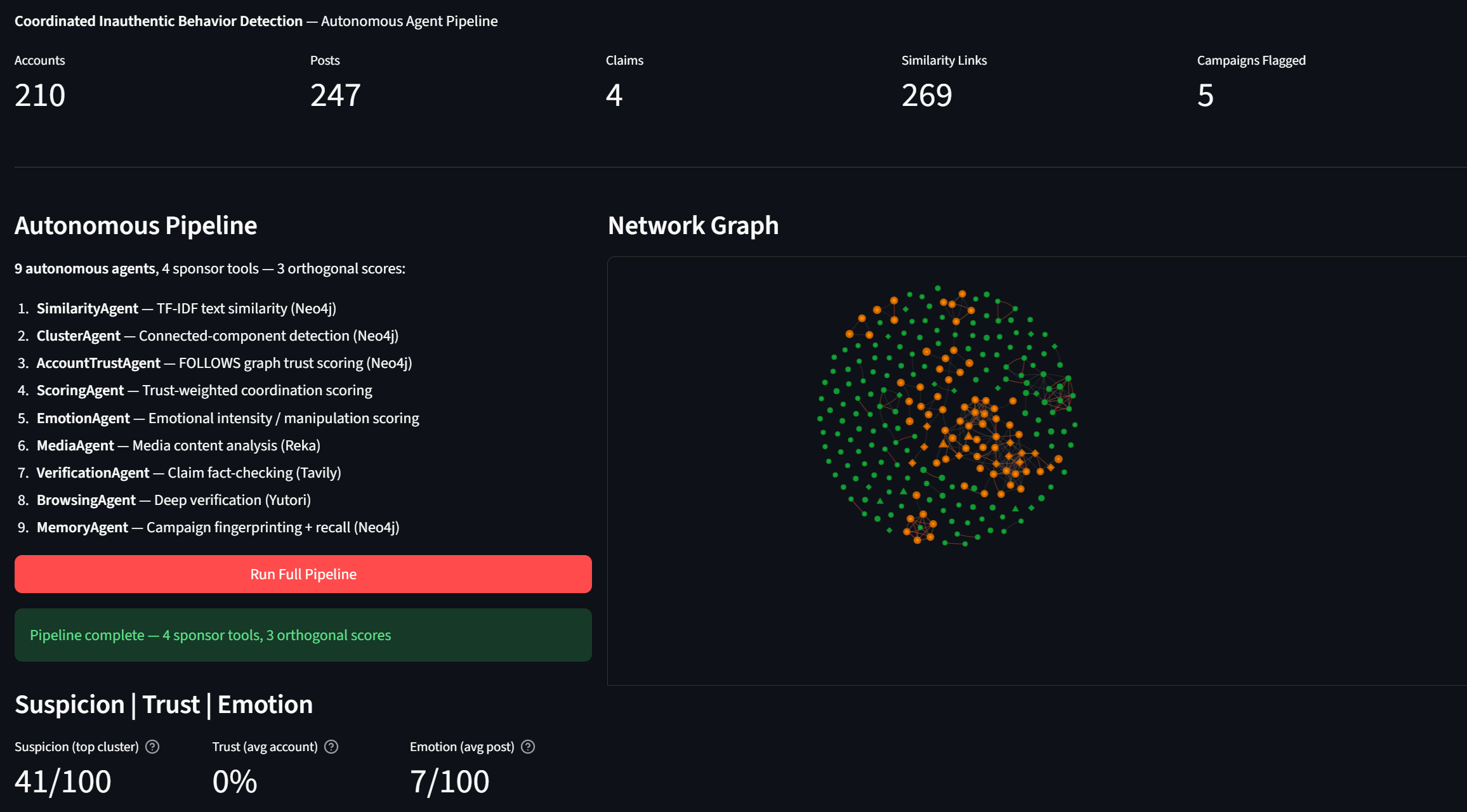
Layer 2 is 9 autonomous agents:
- SimilarityAgent computes TF-IDF cosine similarity across all posts, writes SIMILAR_TO edges into Neo4j
- ClusterAgent runs BFS to find connected components
- AccountTrustAgent scores credibility using graph topology — in-degree, follower counts, account age, and a reciprocity penalty for bot cliques
- ScoringAgent evaluates clusters on 9 signals and outputs a 0-100 suspicion score
- EmotionAgent scores posts on emotional manipulation (loaded vocabulary, urgency phrases, caps ratio, absolutism)
- MediaAgent sends video posts to Reka for manipulation and sensationalism analysis
- VerificationAgent fact-checks claims via Tavily, classifies as debunked/confirmed/unverified
- BrowsingAgent dispatches a Yutori agent to Snopes for deep verification
- MemoryAgent builds campaign fingerprints and stores them in Neo4j — next time similar content shows up, it recognizes it
Output is three scores: Suspicion (behavioral coordination), Trust (account credibility), Emotion (manipulation intensity). No "fake/real" verdict. Just scores.
How we built it
Neo4j is the backbone. Every agent reads from and writes to the graph — posts, accounts, similarity edges, cluster assignments, trust scores, fingerprints. Agents don't call each other. They communicate through graph state. If one agent breaks, the others keep running.
The scoring math is mostly hand-tuned heuristics:
- Text similarity threshold at 0.30 (too high and you only catch copy-paste, too low and everything clusters together)
- Account age uses a sigmoid centered at 1 year
- Following-count penalty is basically a ReLU at 5000 — no penalty below, linear increase above. Targets bot farms that mass-follow
- Connectivity discount subtracts up to 15 points for well-connected accounts (real people have real graph edges)
MediaAgent and VerificationAgent run in parallel via asyncio.gather(). BrowsingAgent fires async and doesn't block. The rest runs sequentially because each stage depends on the previous one's graph state.
For the dataset — zero synthetic data. 265 real posts from 244 real accounts, all sourced from live platforms via Tavily and Yutori. We tracked real coverage of a breaking news story (Pentagon/Scouting America, Feb 27 2026) pulling from X, YouTube, and 32+ news outlets.
Dashboard is Streamlit. API is FastAPI. Everything is Python.
Challenges we ran into
Modulate had no REST API. I planned around their deepfake voice detection — perfect fit for catching AI audio in disinfo videos. At the event I found out there's no way to call it programmatically. Dropped by 11:30 AM. Replaced that signal slot with the EmotionAgent, which turned out to catch a different but equally useful dimension (emotional manipulation vs media fakery).
Fastino's docs were MCP-only. Their personalization endpoint returned 404. I pivoted to using their GLiNER-2 model for entity extraction and text classification instead. Better fit anyway — NER feeds directly into scoring and fingerprinting.
Tavily's account metadata was wrong. Follower and following counts from search results were off by 10-20x in some cases. Since the scoring agent uses a following-count ReLU and connectivity discount, bad data = bad scores. Built a cross-verification loop: Yutori browses real X profiles, reads the actual DOM, patches the dataset with ground truth.
Similarity threshold tuning. Spent a while on this. 0.7+ only catches exact duplicates. 0.1 clusters everything together. 0.30 was the sweet spot for catching paraphrased coordination without drowning in noise.
Accomplishments that we're proud of
100% real data. Every post in the system came from a live platform. No fake accounts, no synthetic text. The pipeline analyzes real discourse and finds real patterns.
5 sponsor tools, nothing shoehorned. Neo4j is the graph (because coordination IS a graph problem). Reka analyzes media. Tavily searches and fact-checks. Yutori browses and verifies. Pioneer extracts entities. Three of the five serve dual roles — sourcing data AND analyzing it.
Campaign memory works. Run the pipeline once, it fingerprints the campaign. Run it again on new content, it matches against stored fingerprints using keyword overlap OR account overlap. The system builds institutional memory.
Top cluster scores 75/100. The scoring agent caught patterns I didn't even explicitly design for — the combination of signals surfaced coordination that any single signal would've missed.
What we learned
Graph structure is the real signal. What posts say matters less than how the accounts behind them are connected. Creation timing, follower topology, cross-platform synchronization — these are way harder to fake than post content. Neo4j made these queries natural.
No single data source is reliable. Tavily's fast but its metadata is wrong. Yutori's accurate but slow. Using them together — fast search for discovery, deep browsing for verification — gave me a dataset I could actually trust.
Heuristics beat classifiers here. I didn't train any ML models. The 9-signal scoring system with hand-tuned thresholds works because coordination leaves structural fingerprints that are easy to quantify. A classifier would need labeled training data I didn't have.
Build for graceful degradation. Two sponsor tools failed on me. Because agents communicate through Neo4j instead of calling each other, dropping an agent didn't break anything. The pipeline kept running.
What's next for Disinfo Detector
- Real-time monitoring — replace batch pipeline with streaming. Yutori Scouts continuously watch X search pages, trigger detection when velocity spikes hit
- Temporal analysis — track how narratives evolve over hours/days, detect when campaigns shift talking points after fact-checks
- Cross-campaign linking — use fingerprints to build a graph of related campaigns, find persistent threat actors running multiple operations
- Audio deepfake detection — fill the gap Modulate was supposed to cover
- Adversarial testing — throw synonym substitution, posting schedule randomization, and account aging at the scoring signals and see what breaks
Built With
- neo4j
- pioneer
- reka
- tivily
- yutori

Log in or sign up for Devpost to join the conversation.