-
-
Dishy
🎥 Video | 🕹️ Devpost Project | 💻 Live App | 🧵 Code
Introduce Dishy 🍽️
Dishy is a multimodal knowledge synthesis system that transforms fragmented, unstructured restaurant data into coherent dish-level intelligence. Using Gemini 3's reasoning capabilities, Dishy processes hundreds of scattered reviews and photos to construct a unified semantic and visual understanding of each menu item, capturing not just what a dish looks like, but how it's collectively perceived, described, and experienced across an entire customer base.

How Gemini 3 Is Central to the Project ✨
Our system utilizes Gemini 3 as a core reasoning engine with the application designed as an agentic, multi-stage pipeline focused on reasoning, verification, and synthesis.
Inputting hundreds of images alongside reviews isn't feasible for existing models, and baseline RAG methods fail when treating text and images independently; correct interpretation of reviews requires reasoning over the links between review text and images attached to them, which requires multimodal understanding rather than retrieval alone.
In this sense, Gemini 3 is central to our system in several ways:
- Multimodal image generation with contextual grounding, where nanobanana 3 creates a "mean image" by combining dish descriptions with multiple candidate images representing the dish’s perception.
- Long-context aggregation across large volume of reviews enabling comparison at scale, surfacing disagreements, and forming consensus-driven summaries.
- Reasoning and normalization to interpret noisy and inconsistent textual and visual signals from reviews, accounting for ambiguity, variation, and disagreement that cannot be addressed with heuristics or deterministic system alone.
- End-to-end autonomy, where Gemini 3 acts as the primary decision-making agent from review filtering to image selection and summary generation.
Inspiration 💡
When people search for restaurants, the problem is rarely a lack of information. Platforms like Google Maps already provide hundreds or thousands of reviews and photos for popular places. The real challenge is that this information is unstructured, fragmented, and difficult to reason about at the level people actually care about: individual menu items.
Understanding what a specific dish is what it looks like, how it’s prepared, what people commonly say about it, and where opinions diverge) often requires manually skimming dozens of reviews and photos. This becomes even harder for foreign cuisines, where menu items may have multiple spellings, translations, or informal names.
We were inspired by the idea that while individual reviews are noisy, the collective signal across many reviews is surprisingly consistent when aggregated correctly. This project started from a simple question:
What if restaurant reviews could organize themselves into a clear, dish-level understanding?
That idea became the foundation for this project.
What it does 💬
We built a multimodal reasoning system powered by Gemini 3 that transforms noisy restaurant reviews and user-uploaded photos into a unified, per-dish knowledge layer.
Instead of presenting another list of reviews, the system produces, for each menu item:
- a structured textual summary grounded in multiple reviews,
- normalized metadata such as dietary claims and common variations,
- and a visual representation of the dish.
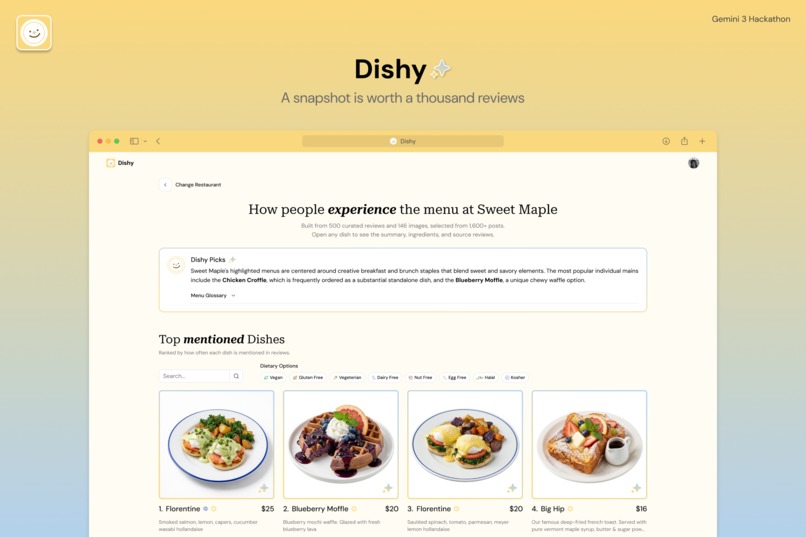
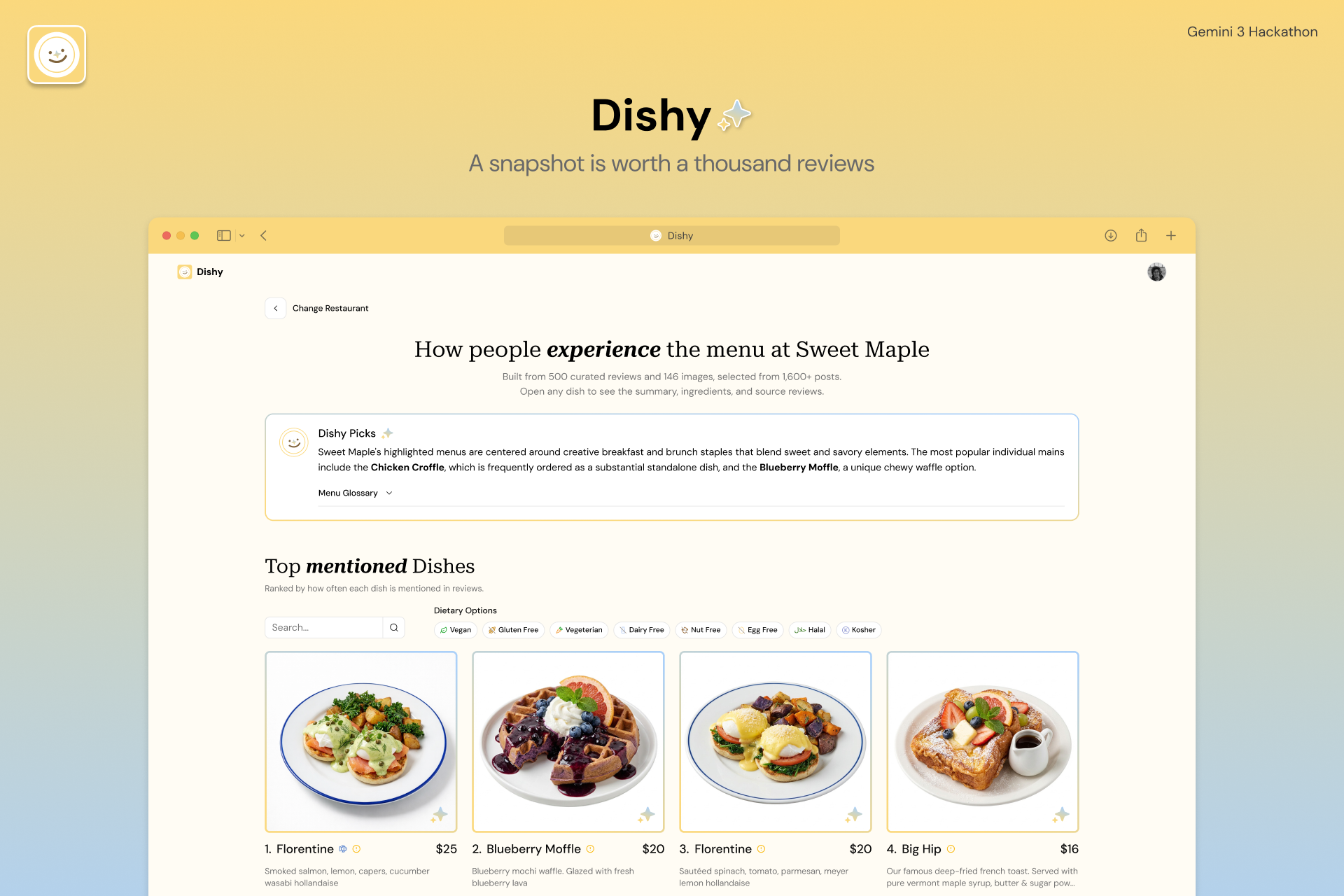
The result is a gallery-style snapshot that reflects how a dish is most commonly perceived, not how it appears in an individual review or a single idealized promotional photograph.
This approach reframes restaurant discovery as a dish-level understanding problem, rather than a review-ranking problem.
How we built it 🛠️
The system is designed as an agentic, multi-stage pipeline that emphasizes reasoning, verification, and synthesis— something that cannot be solved with a single prompt or baseline RAG. Even with long-context vision–language models(including state-of-the-art models such as Gemini) providing hundreds of images is not feasible in practice. Likewise, baseline RAG methods are insufficient because adequately embedding and reasoning over the links between textual reviews and their associated images is non-trivial. This linkage, which avoids treating the images and reviews as independent fields, is essential for the correct interpretation of the reviews.
1. Review and Image Collection
We collect raw public reviews consisting of paired text and user-uploaded images, forming a large, noisy multimodal dataset with no predefined structure. We intentionally avoid restaurant-level metadata such as official menus or cuisine labels, relying solely on reviewer-generated content.
Despite this minimal structure, the sheer volume of reviews allows meaningful patterns to emerge.
2. Obtain list of menus
To establish a ground truth set of menu items, the system identifies menu board images by comparing multimodal embeddings against a textual description(A photo of a full textual menu showing all items and prices). High-similarity images are clustered to remove duplicates and handle multiple pages or angles.
Gemini 3 then performs OCR and structured extraction of menu names, prices, and descriptions. This menu list becomes the backbone for all downstream reasoning, effectively establishing the ground-truth set of menu items, around which all subsequent processes are built.
3. Review Association and Per-Dish Synthesis
Each menu item is linked to reviews mentioning it using text embeddings. Our system calculates the similarity between reviews and menu items, dynamically setting a threshold that ensures relevance without causing false negatives. Minimizing false negatives is key, as we’ll refine the data with Gemini 3 later. This initial filtering offloads Gemini 3's input, providing a more manageable context length. From these candidates, Gemini 3 performs long-context reasoning to identify which reviews genuinely discuss the dish and synthesizes a structured, source-of-truth representation capturing:
- Taste and ingredient descriptions,
- Physical appearance cues,
- Dietary properties and modifiability,
- Variations from what the menu indicates (e.g., hidden cost, availability, secret menus)
This step relies heavily on long-context aggregation and reasoning under uncertainty, rather than surface-level summarization.
Unlike vanilla RAG, which assumes the answer resides within a small set of highly similar (top-k) chunks, our task requires aggregating ALL potentially relevant review signals across many reviews. Because global trends and cross-entity relationships often span far beyond any fixed K boundary, a recall-oriented retrieval strategy is necessary for accurate per-dish synthesis, where sparse but important mentions could otherwise be missed by RAG.
4. Image Classification and Canonical Visuals
For each dish, we gather only images attached to the classified(as mentioning the dish) reviews. Using 'physical appearance' descriptions from the previous stage, the system retrieves and ranks food images via multimodal embeddings(reusing from the first stage), selecting the most representative examples.
These curated images are passed to NanoBanana, which generates synthetic menu images acting as a mean image. This mean image reflects how reviewers collectively represent the dish, offering a more generalized view rather than a cherry-picked example.
5. Presentation Layer
The final output is a clean, gallery-style interface where users can explore restaurant by dish. Thanks to our pipeline, which organizes data into structured fields like 'dietary restrictions,' 'order options' (size, topping, protein, etc.), and 'ingredients,' the interface offers efficient filtering functionality.
We also provide a restaurant overview, distinct from typical platform summaries that rely on simple LLM text review outputs. Our overview explains based on the typical ordering patterns of the top 3 most mentioned dishes. To assist with foreign terms, we include a brief glossary defining key terms that clarify multiple menu items.
Challenges we ran into 🎯
One of the biggest challenges was avoiding false confidence. Reviews frequently contradict each other, images may be misleading, and menus can be outdated. Designing a system that detects disagreement instead of smoothing it away required careful prompting, schema design, and verification logic.
Another challenge was deciding when to use reasoning-heavy Gemini calls versus lightweight vector retrieval. Overusing reasoning increased latency and cost, while underusing it led to brittle outputs. Striking the right balance was key to making the system both robust and scalable.
Finally, representing a “typical” dish visually without drifting into unrealistic or overly stylized imagery required tight constraints and careful curation before generation.
Accomplishments that we're proud of 🏆
We’re proud of building a system that goes beyond surface-level summarization and treats restaurant discovery as a true multimodal reasoning problem. Instead of relying on a single prompt or generic RAG, we designed an agentic pipeline that extracts menus from images, associates reviews at the dish level, verifies claims across text and visuals, and produces consensus-driven representations. A key accomplishment was carefully balancing vector embedding retrieval with targeted Gemini 3 reasoning calls, invoking the LLM only when deeper understanding or verification is required, rather than dumping all data into a single prompt. This allowed us to significantly reduce unnecessary compute while improving robustness, explainability, and scalability.
What we learned ✍️
This project reinforced that multimodal AI becomes most powerful when it is orchestrated, not when it is asked to do everything at once.
We learned that:
- structure emerges naturally when multimodal signals are aggregated correctly,
- reasoning is most effective when applied selectively,
Most importantly, we learned that
- many real-world problems are not about generating new information, but about organizing what already exists into something people can actually use.
--
What’s next for Dishy 🚀
What’s powerful here is not just the interface, but the structured restaurant database underneath. By transforming reviews into structured signals, Dishy enables new forms of discovery for customers, such as searching for places where people consistently mention spicy dishes or strong vegetarian options. For restaurant owners, the same structure can power auto-generated restaurant websites, per-menu insight into what customers are actually saying without running surveys, and reusable assets that adapt easily to delivery apps and listing platforms. Beyond restaurants, this approach naturally generalizes to any Google Place — libraries, cafés, gyms, museums, and more — anywhere multimodal reviews exist and collective understanding can be synthesized.
Built With
- gemini-3-api
- google-cloud
- google-maps
- python
- react
- vertexai




Log in or sign up for Devpost to join the conversation.