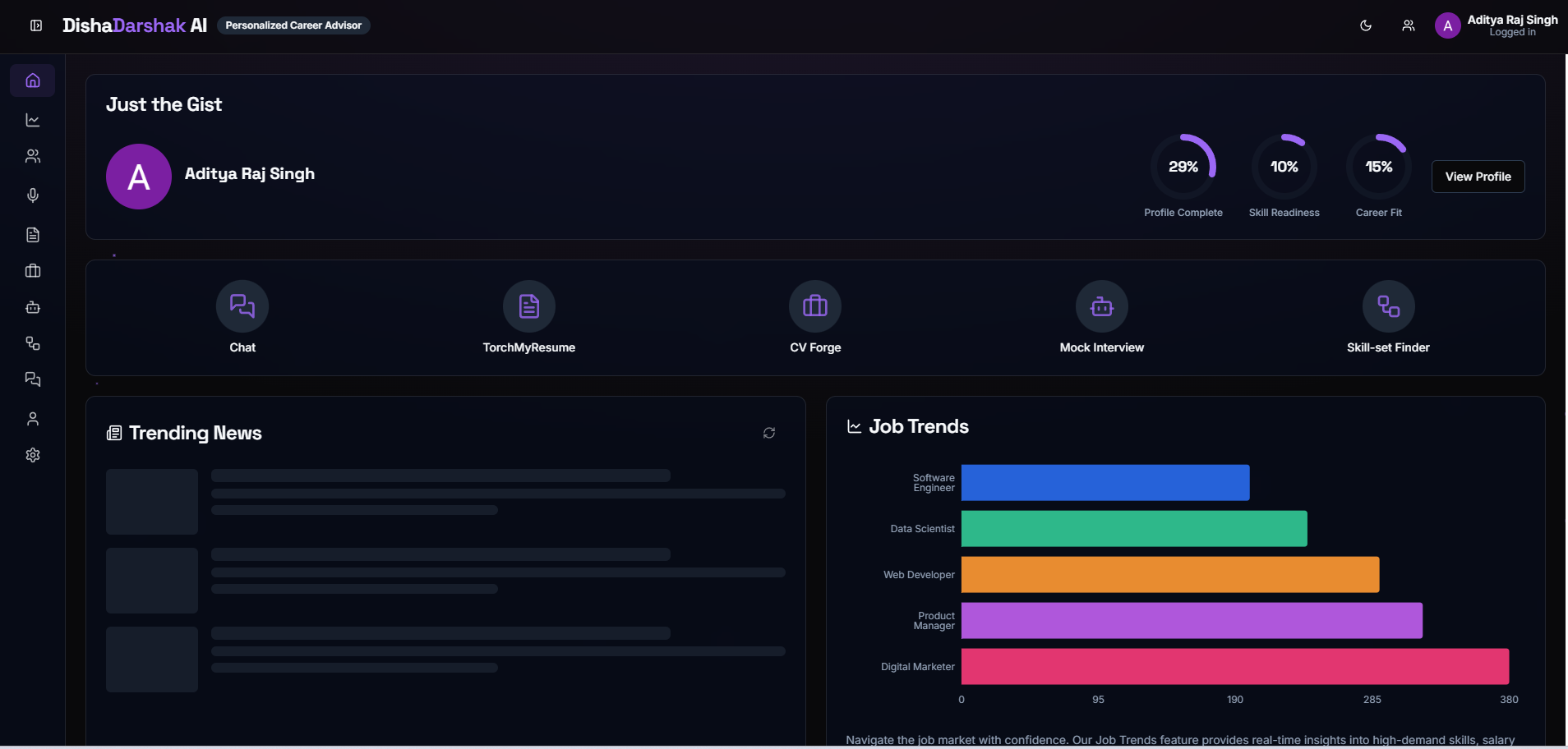
Disha Darshak AI: AI for Career & Placements, Help students become job-ready.
What Inspired Us
The inspiration for Disha Darshak (which translates to "Direction Guide" in Hindi) came from observing the overwhelming anxiety students and job seekers face in today's volatile job market. We noticed that while information is abundant, personalized guidance is scarce.
People from Tier-2 and Tier-3 cities often lack access to expensive career counselors. They struggle with three core problems:
- Lack of Self-Awareness: Not knowing what skills they actually possess.
- Resume Blindness: Applying with generic resumes that get rejected by ATS (Applicant Tracking Systems).
- Interview Anxiety: Having no safe space to practice technical and behavioral questions.
🛠️ How We Built It
We architected the application as a full-stack solution using Next.js 14 (App Router) for the framework and Firebase for persistence and real-time features. The core intelligence is powered by Google Vertex AI, leveraging the cutting-edge Gemini 3 models.
1. The AI Architecture (Vertex AI & Gemini 3)
We moved away from abstraction layers to integrate directly with Vertex AI for maximum control and performance.
- Gemini 3 Flash (High Throughput): We utilized the
gemini-3-flash-previewmodel for latency-sensitive tasks like the Resume Roaster and Skill Extraction. Its speed allows for real-time parsing of complex PDF structures. - Gemini 3 Pro (Deep Reasoning): For the Mock Interview Loop, We deployed
gemini-3-pro-preview. This model manages the conversation state machine, maintaining the persona of a strict interviewer while generating highly specific, context-aware follow-up questions based on the candidate's previous answers. - Multimodal Capabilities: We used Gemini 3's native multimodal abilities to process PDF resumes directly as binary buffers, extracting structured JSON data (Skills, Experience, Education) without needing brittle third-party text parsers.
2. The Algorithm: Skill-Set Finder
For the career path recommendation engine, We grounded the AI's creativity in a mathematical scoring system based on Likert scales.
When a user takes the psychometric test, we normalize their responses into vector dimensions: Analytical ($A$), Creative ($C$), Independence ($I$), and Stability ($S$).
If $R_i$ is the response value $(1 \dots 5)$ for question $i$, the dimension scores are calculated as:
$$ S_{analytical} = \frac{\sum_{i \in \text{LogicQuestions}} R_i}{N_{logic}} $$
$$ S_{creative} = 6 - S_{analytical} \quad (\text{Inverted correlation}) $$
These scores are passed as a structured payload to Gemini 3, which calculates the "Vector Distance" between the user's profile and potential career clusters to generate a personalized roadmap.
3. Real-Time Community & Tech Stack
- Frontend: Built with Tailwind CSS and Framer Motion for a "glassmorphism" aesthetic.
- Backend: Next.js Server Actions handle the heavy lifting of AI processing to keep API keys secure.
- Database: Firebase Realtime Database handles the instant messaging (DMs) and the community feed, allowing for live updates without page reloads.
🧠 What We Learned
- Model Selection Matters: upgrading to Gemini 3 significantly improved the nuanced understanding of resumes. Where previous models might miss context in a "Project Description," Gemini 3 accurately inferred implied soft skills.
- Prompt Engineering is Logic, not Magic: Writing the
roast-resumeandrank-resumeprompts required strict output schema enforcement (Zod) to ensure the UI didn't break when Vertex AI returned data. - The Importance of Latency Masking: Even with the speed of Gemini 3 Flash, complex flows take time. We learned to implement engaging UI states—like the typewriter effect in the chat and the "Thinking Orb" animation in the voice interview—to keep users engaged during server processing.
🚧 Challenges We Faced
The "Context Injection" Problem
The biggest hurdle was connecting isolated features. Initially, the Mock Interview and the Chatbot were separate. Users would finish an interview and ask the chatbot, "How did We do?", but the bot had no idea.
- Solution: We implemented a session storage mechanism that serializes the
EvaluationResultJSON. When navigating to the chat, this JSON is injected into the system prompt invisibly. $$ P_{final} = P_{system} + \text{Context}{\text{evaluation}} + H{history} + Q_{user} $$
Audio Synchronization
Implementing the Voice Interview was tricky. Browser-based SpeechRecognition is often flaky.
- Solution: We wrapped the Web Speech API in a custom React hook and paired it with Google Cloud's Text-to-Speech (Wavenet voices) on the server. Handling the asynchronous gap between "User stops speaking" $\rightarrow$ "Vertex AI processes text" $\rightarrow$ "Audio generates" $\rightarrow$ "Audio plays" required careful boolean flag management to prevent the bot from interrupting itself.
Variable Data Structures
AI models occasionally return Markdown inside JSON fields, breaking JSON.parse().
- Solution: We wrote a robust cleaning utility function that strips markdown code blocks using Regex before parsing, ensuring the frontend always receives valid objects.
Disha Darshak AI evolved from a simple chatbot idea into a comprehensive ecosystem that not only tells you what to do but provides the tools to actually do it.

Log in or sign up for Devpost to join the conversation.