


Inspiration
Want to cut hours of research? Tired of having 30 tabs of article information open? (And you don't want to bookmark them?) Sound familiar? We thought so. Here at techTomodachi, we listen to the cries of frustrated students working late hours searching for information for their research paper; or researchers just scouring the inter web trying to gather knowledge. We feel your pain (from experience), and we are here to help: introducing, DI, a search engine that goes beyond search engines.
How it works
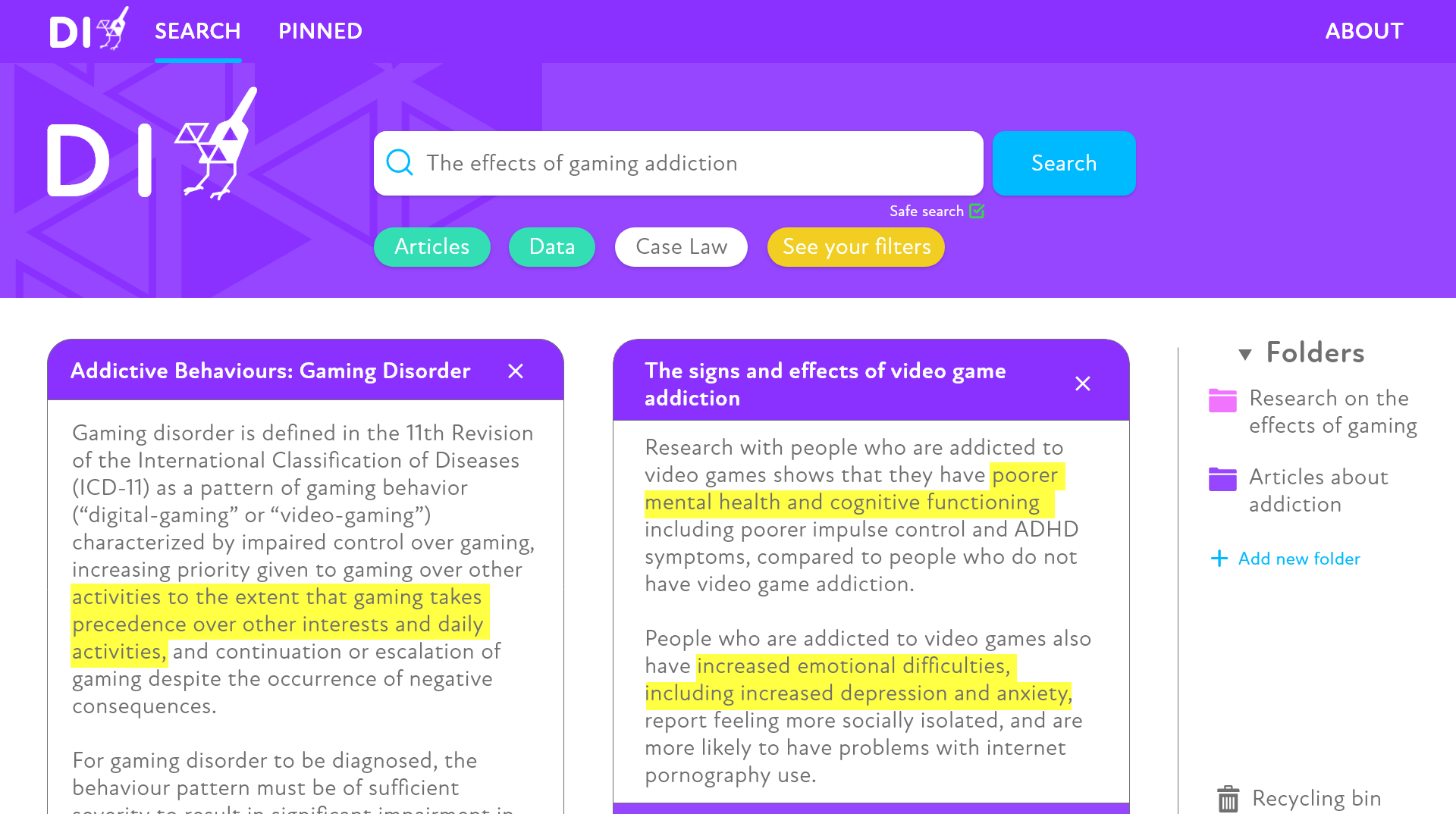
So how does it work? How does it save you time and not make you want to cry? Well, just like every other search engine, you put in the terms and/or phrases that you want to search in our super clean and savvy interface. Ridiculously easy right? It's literally that easy. Our search engine aggregates from reputable sources such as Google Scholar, Microsoft Academic and more to bring you all the necessary information that you need to finish your research. Given more time and technology advances it will use natural language processing to identify specific paragraphs in articles or data in convenient cards that will aid you and save you time from having to access the webpage and scroll and find the information that you need. But it doesn't stop there. You may asking, what separates DI from the rest of our competitors? Why not just use Google Scholar? And you know what, that's a good question. And I have an amazing answer. First of all, doesn't our search engine look really cool? It doesn't just look cool but it's extremely user friendly and provides users with a pleasant searching experience, built on from research into other search engine precedents and interviews. It utilises the main colour of purple to contrast buttons and text, making it accessible to many. And secondly, it has useful features such as, a save and import search settings function for collaborative research among peers, ensuring you are all on the correct page (literally). Another phenomenal feature are folders on the side as you search. These folders are of course customisable but more importantly, keep hold of any articles, data or information that you wish to revisit or keep. When searching with DI, you can also tailor your results by 'crossing out' too vague results.
How we built it
As a team, we ideated and designed the initial look of the website in Adobe XD. We also prototyped in Adobe XD and started coding the front-end using React.js and Material UI.
Challenges we ran into
Our first biggest challenge as a team was personally settling on an idea. We were ambitious in wanting to hack something that helped everyone and could be widely used. We went from, trip making to COVID, to fitness, to university apps until we finally settled on an idea. While pondering the impact we could make for our peers and classmates, we wondered: "What makes research papers so arduous to complete?" We considered taking the path of creating an entirely new search engine. It then became obvious that we had a lot cut out for us to be competing against large web browsers with years of R&D and data collections. In order for us to have an edge against the competing browsers, we made the decision to develop an overlaying search function with innovative features that will splice researching time. Other challenges we ran into are that we did not have enough time and manpower.
Accomplishments that we're proud of
We are personally proud of how it all turned out given the 48 hour time limit. The branding of DIScraper looks sleek and professional.
What we learned
We learnt how to effectively collaborate within a team and set goals. We also learnt tech stacks we haven't heard before such as Microsoft Azure and ElasticSearch which we will look into and learn further moving forward.
What's next for DIScraper
Developing a fully functional overlaying search function. As of now we have a prototype for how the application will look and work, as well as it’s basic functions and features. We will need to look into how to properly integrate Google Scholar and other article and library databases.
Log in or sign up for Devpost to join the conversation.