-
-
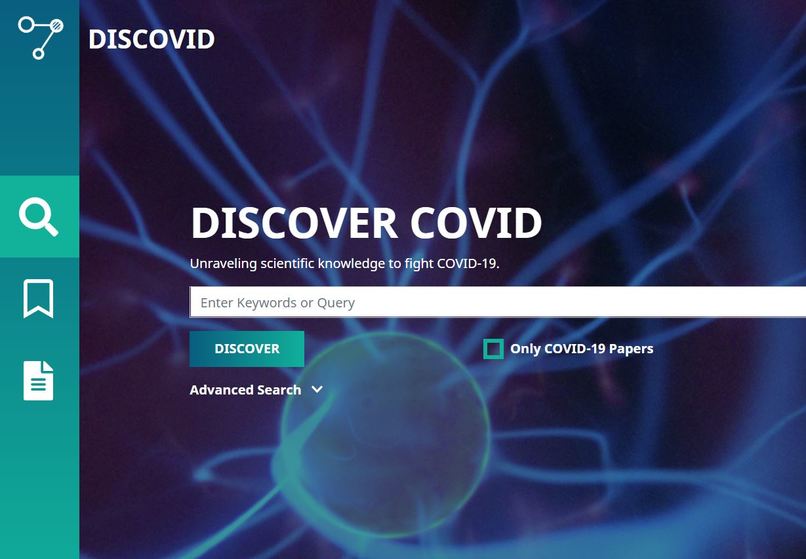
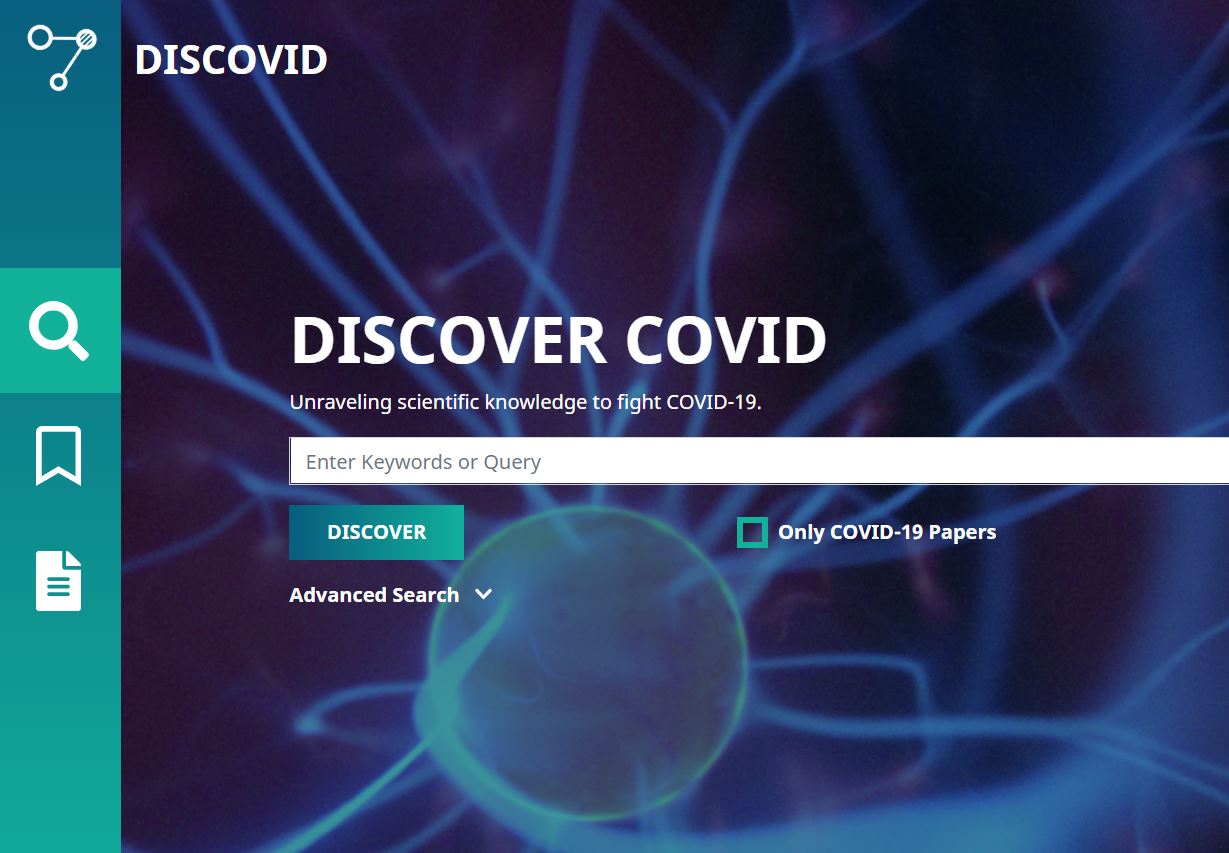
discovid.ai - search interface
The Challenge
Since the beginning of the current pandemic, there has been a rapid increase in scientific literature around COVID-19, which is hard to keep up with. Additionally, the limitations of scientific conferences make it even harder to collaborate and stay up to date. But it is crucial for scientists to be aware of ongoing research to find relevant publications and to identify gaps in the current literature to set their new goals. That's why we have developed DISCOVID.AI.
The Solution
DISCOVID.AI is a search engine specialized on the CORD-19 corpus - a collection of over 52,000 scholarly articles about COVID-19 and related viruses.
Our website evolved from the COVID-19 Open Research Dataset Challenge on kaggle.com where we've received a lot of positive feedback on our topic model. It's a machine learning approach that essentially learns topics in the corpus and thus helps to uncover hidden semantic relationships. We can then see each article as a mixture of these topics (which themelves are distributions over words). By mapping each article into the topic space (a simplex with a topic in each corner), we can then find related articles.
For this, we analyze the full text of each paper and not only use metadata or the abstract like most search engines.
This approach lies at the heart of our search engine and enables users to iteratively click their way through related research to discover new insights. It is also used for personalized reading suggestions based on the user's bookmarks.
For the initial search we use whoosh, which enables you to either search for simple keywords or use more complex boolean queries (AND, OR, NOT, etc.) and phrase queries to help you find exactly what you are looking for. We also provide the option to search in specific fields (title, abstract, authors, doi and methods) or use phrase queries with double quotes. Try for example:
- journal:(The Lancet)
- authors:Drosten
- doi:10.1101/2020.01.31.929042
- title:hydroxychloroquine AND methods:(randomized controlled trial)
- title:("randomized controlled trial")
We've also performed extensive data preparation and cleaning to ensure a high quality output of our topic model. For example, for lemmatization, we used scispacy, which is useful for processing biomedical, scientific or clinical texts. Additionally, we've used language detection to remove non-English articles to reduce noise.
To ensure a pleasant user experience, we've designed a clean and intuitive interface. The website is realized as a react app and we used bootstrap to provide a responsive design.
Our Progress During the Hackathon
We've collected feedback from medical researchers and implemented new highly desired features, namely bookmarks, personalized suggestions based on the bookmarks and we've also added links to clinical trials registered in the WHO ICTRP whenever they are referenced in a paper. (For this, we extracted all trial ids with manually crafted regular expressions). We've also released several minor improvements to the user interface.
Impact
We hope our discovery engine helps researchers around the world to navigate the current flood of publications and find what is relevant to their work. It could also prevent duplication of research efforts and help to identify current evidence gaps in literature.
Future Work
Our work can easily be expanded to other text files, that's why we plan to incorporate other data sources soon. Another important issue that we plan to work on is the quality assessment of current publications - for example, by automatically classifying the study design or extracting the sample size.
In the near future, we’d like to start closer collaborations, so we can implement further features that are useful to the research community and assist their workflow.
So, if you are interested, please get in touch via hello@discovid.ai.







Log in or sign up for Devpost to join the conversation.