-
-
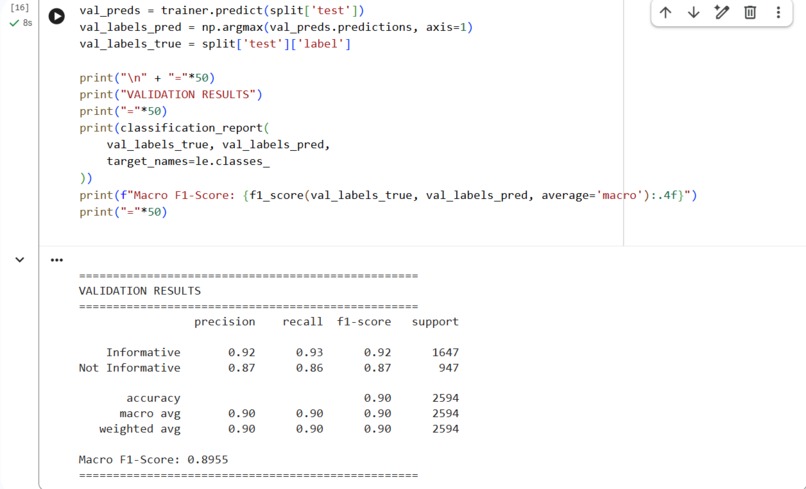
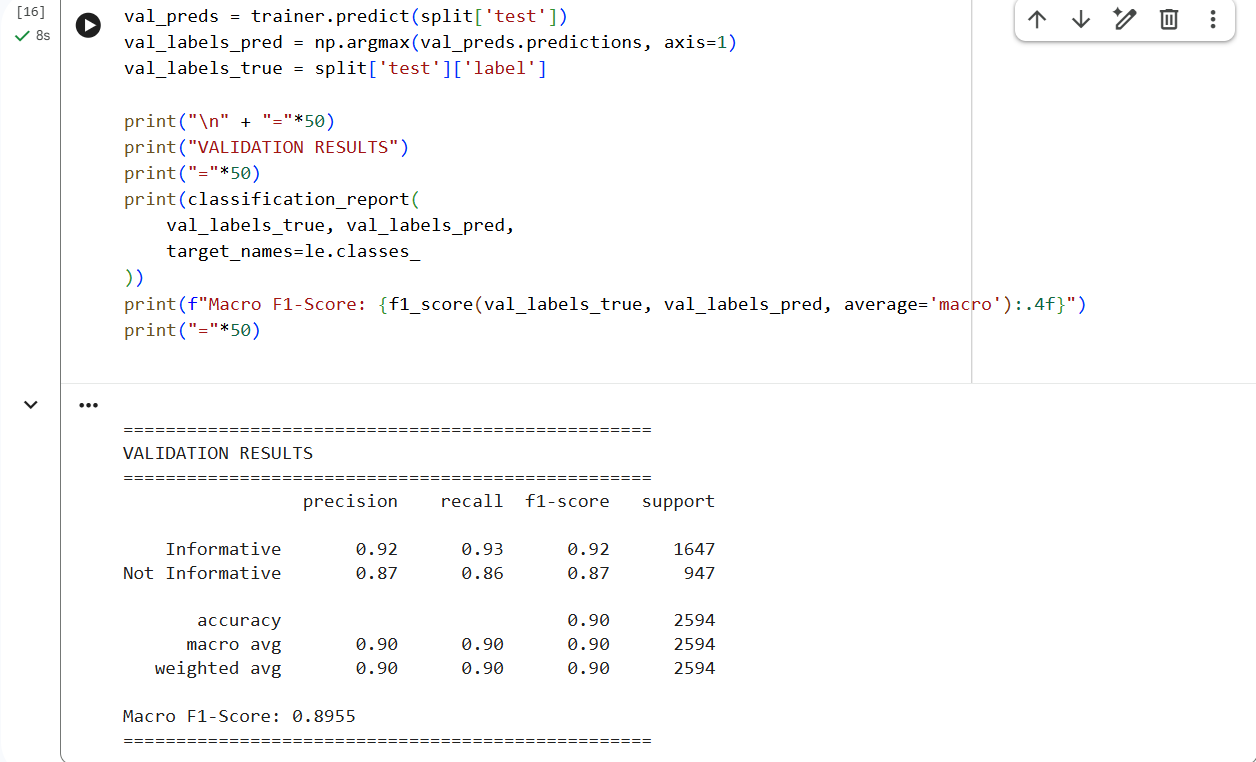
This is the screenshot of the validation for the model which achieved an F1 score of = 0.8955
Inspiration
Real disasters generate thousands of social media posts per minute. First responders need automated tools to filter actionable information from noise. This motivated building a high-accuracy disaster tweet classifier.
What I Built
A binary text classifier using BERTweet (vinai/bertweet-base) — pretrained on 850 million tweets — fine-tuned to classify disaster tweets as Informative or Not Informative.
How I Built It
- Combined Tweet Text + Information Source + Information Type as input features
- Fine-tuned BERTweet for 3 epochs on 25,933 labeled tweets
- 90/10 train-validation split with seed=42 for reproducibility
- Platform: Google Colab T4 GPU
Results
Informative → Precision: 0.92 | Recall: 0.93 | F1: 0.92
Not Informative → Precision: 0.87 | Recall: 0.86 | F1: 0.87
✅ Macro F1-Score: 0.8955
Challenges Faced
- Choosing domain-specific BERTweet over generic BERT for better tweet understanding
- Combining multiple text columns for richer feature signal
What I Learned
Domain-specific pretraining significantly outperforms generic models for social media text classification.
Built With
- bertweet
- google-colab
- huggingface-transformers
- numpy
- pandas
- python
- pytorch
- scikit-learn
- t4-gpu

Log in or sign up for Devpost to join the conversation.