Inspiration
The Recovers web app (https://recovers.org/) is one of the ideas inspired our project. Recovers is a request/planning app that manages the requests of needs and supplies in a disaster relief stage. In a need-request form, a user may tag his/her request by selecting labels manually. However, for different disasters, the app provides users with the same set of labels. It would be better, in the case that Recovers app could suggest the labels to users based on the needs requested in the similar disasters that had occurred before.
With this observation, we intuit that a tool which associates different disasters may help disaster management software (e.g., those built with Sahana API) to configure an initial state for a specific case. The initial configuration is built from the knowledge and lessons learned from those similar disasters that had occurred before. It may help first responders planning their operations before arriving to the site, or a disaster management organization managing the operations or activities in an emergency relief stage.
This project is the first step to realizing the tool described above.
What it does
In this project, we developed a web app that provides concept-relationship-based search on disasters.
A search procedure starts right after a user submits a request. The request contains a description of a disaster. A disaster description presents the information of a disaster in plain English. It should include the country, geological objects (e.g, river, mountain), and types (e.g, flooding) of a disaster. The headline of a news (e.g., those in CNN natural disaster), or of a report (e.g., those in ReliefWeb/report) works well in this case. For example, the content in the disaster page: http://reliefweb.int/disaster/fl-2015-000146-dza, could be used as a description.
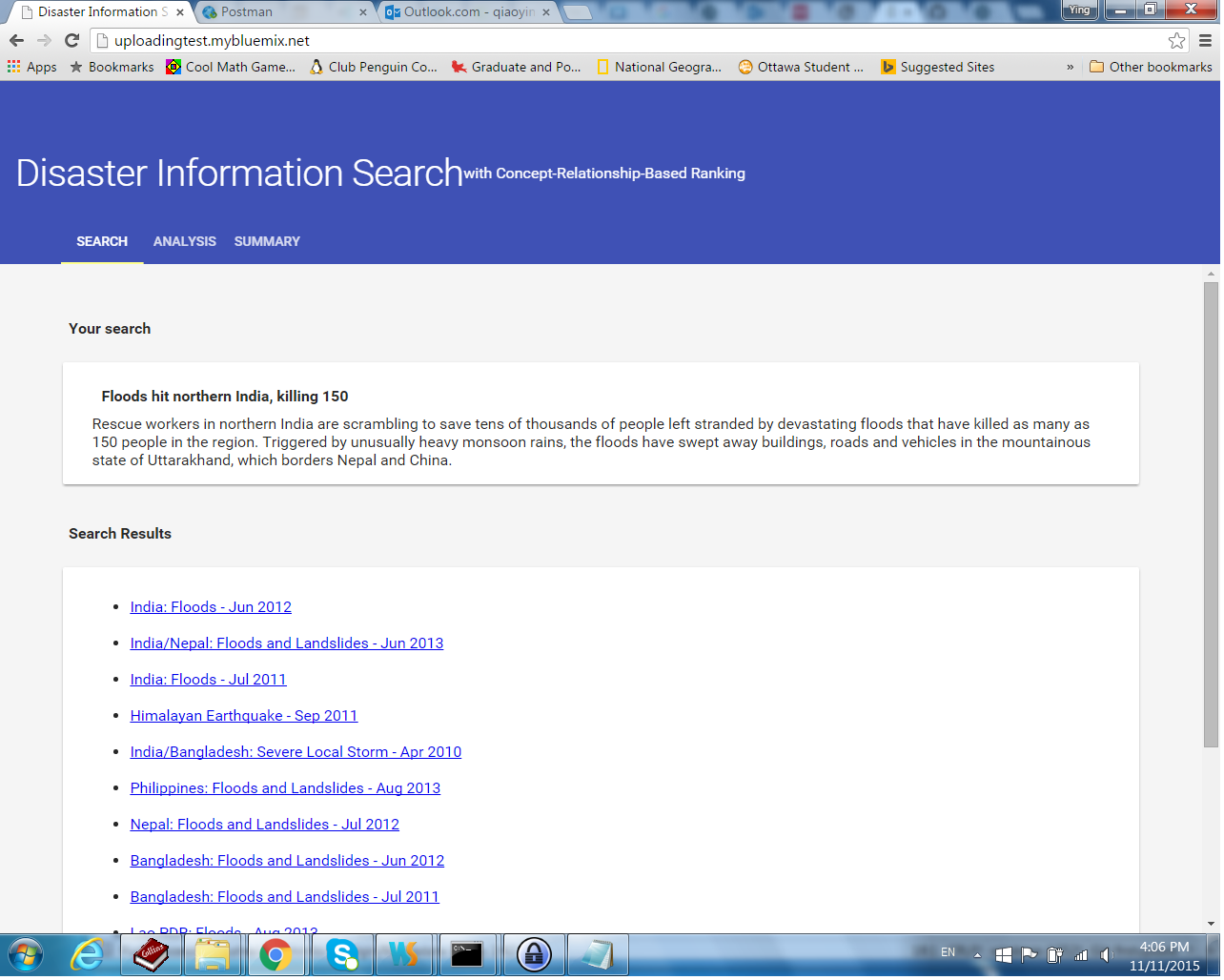
Our app searches a corpus for the disasters related to the description in a search request. The descriptions of those disasters occurred in history are stored in the corpus as documents. While handling a search request, our app retrieves the concepts contained in the description first. Then, it queries the corpus using these concepts as input parameters. The corpus returns a number of entities. Each entity contains the information of a document, including the title of the description, related concepts as well as scores. A score or relevance indicates the closeness of relationships between the disaster description and the concepts in query. Our app orders the entities by their scores and creates a list with their titles. It returns the ordered list to the user at the end of the search.
At current stage of our app, each entity in the returned list includes a link in addition to a title of a disaster. By clicking that link, a user is directed to the report page of that disaster in ReliefWeb.
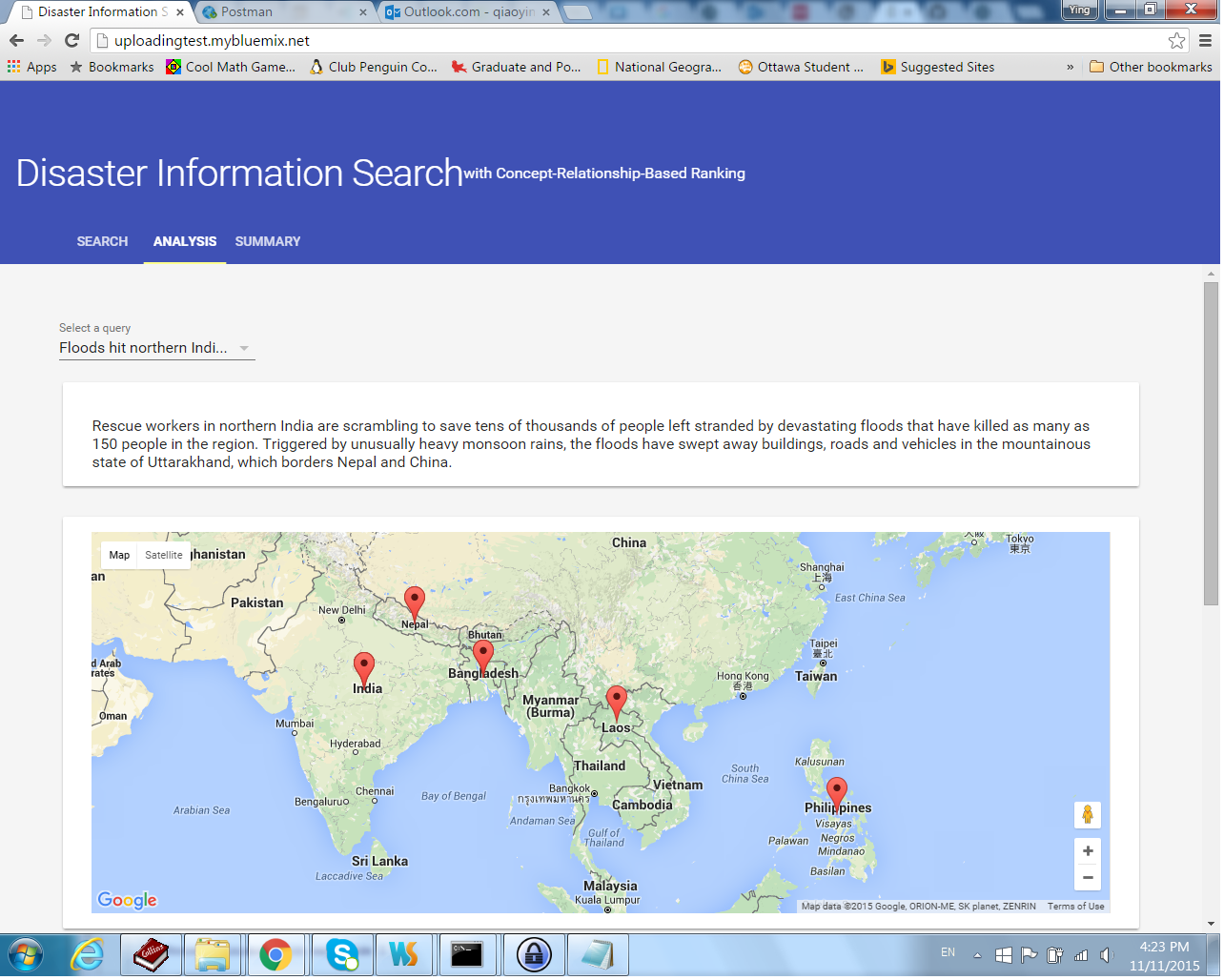
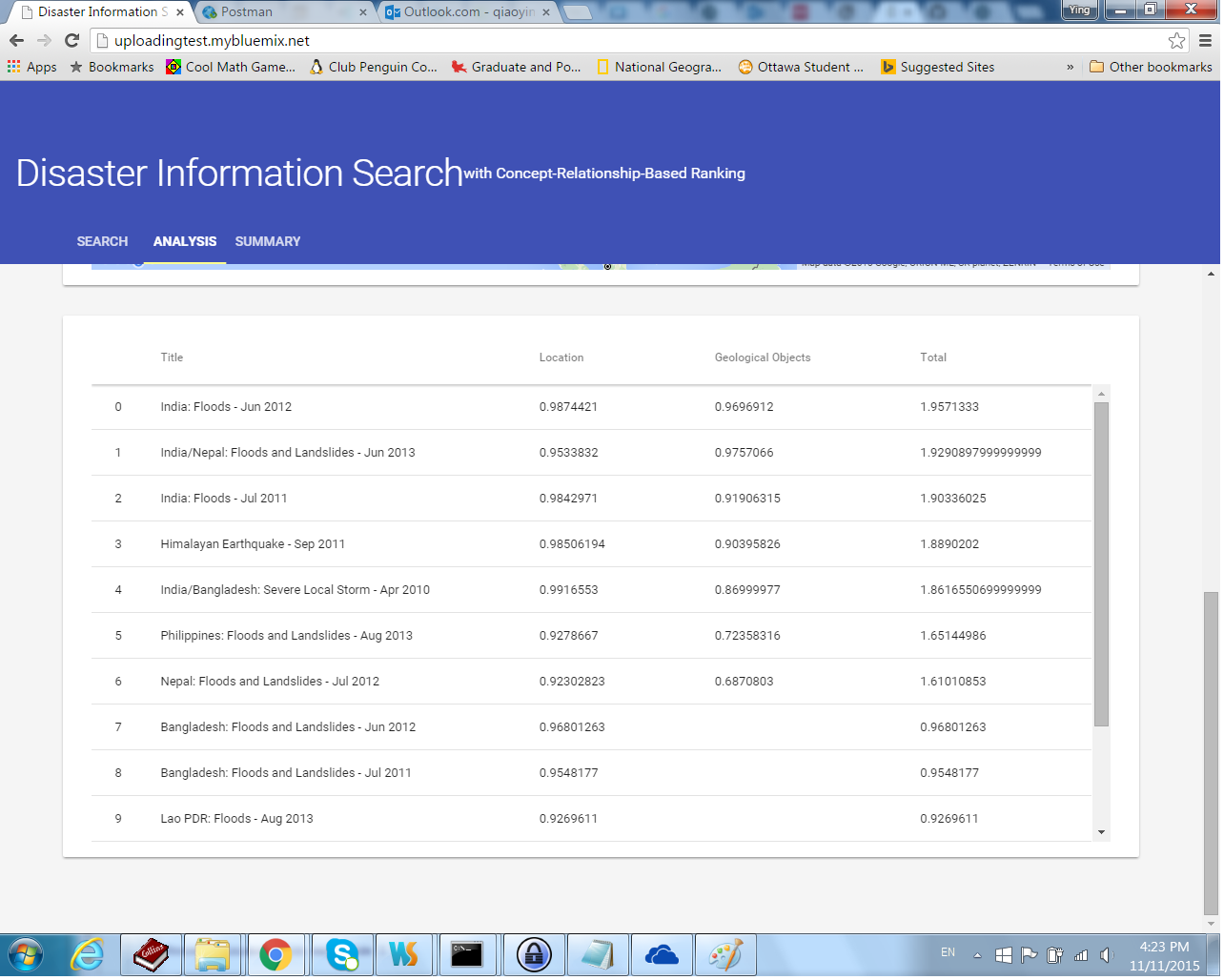
Our app also has a page called Analysis. It is a tool for verifying the results of search requests. A selector lists all of the requests that had been processed by the app. A user may select a request using this selector first. Then, the Analysis page retrieves the result of the request from the server and display the result there. A map with markers displays the locations of related disasters. Furthermore, a table lists these related disasters with their titles, and their scores on two different concept categories, in parallel.
How I built it
This app is built with Watson services and Cloudant NoSQL DB service of Bluemix. It has Node.js/Express.js working as its web framework.
We use two Watson services: Concept Insights and Relationship Extraction. We use Relationship Extraction service to retrieve entities or mentions from the description in a search. We store the descriptions of the disasters in history in the corpus of Concept Insights. We further uses Concept Insights to search the corpus for related disasters. Those disasters have their descriptions related to the concepts of the entities retrieved from a search request.
We also collect the information of disasters from ReliefWeb/disaster through their API in our project. The information includes the descriptions of disasters, the links to disaster reports, and some other general information (e.g., location, type, and country). We store the descriptions in the corpus and the other information in a database.
The Cloundant NoSQL DB is used to store the information of disasters and the data of users' requests. For a search request from a user, the data includes its description and the list returned from its search procedure. These data are used by the Analysis tool.
Challenges I ran into
The challenge we met is to select right Watson services and use them properly.
For instance, Concept Insights has a document search API which searches a corpus for documents related to a group of concepts. Meanwhile, it has a concept extraction API which extracts concepts from a document. Upon a search request, one approach our app could use is to call the concept extraction API with the description as input first. With the extracted concepts, our app calls the document search API next. However, this approach does not work sometime. Normally, for a description, the concept extraction API returns 10 or more concepts. In the case that all of the extracted concepts are used as an input, the document search API can not find any document.
In order to solve this problem, we use Relationship Extraction service here. For a search request, our app calls Relationship Extraction service to retrieve entities from the description first. The retrieved entities are further organized into two different categories: location and geological object. Both of the categories contain the event type of the disaster. Then, our app calls Concept Insights' label search API to map these entities to the concepts there. It further calls document search API with the concepts in two categories, one call for each category. In this way, our app obtains the information of the descriptions related to a search successfully.
Accomplishments that I'm proud of
I am proud that we use Watson service to realize a concept-relationship-based search method. Unlike those keyword search methods, this search can find conceptually related documents. In our case, a disaster can be conceptually related to some others even though it does not share the same entities with them. The two Watson services are imperative.
What I learned
I learnt to build an app with Bluemix Watson services.
What's next for Disaster Information Search with Concept-Based Ranking
Our app could be improved. The returned result could be more accurate. First improvement could be to calculate the score of a related description in different ways. Currently, the score is the sum of the relevance that the description has on two categories. In a different way, the score could be calculated with the relevance on individual concepts in these categories. Second improvement could be to have more concept categories. Currently, the search is mainly based on the concepts extracted from the descriptions of disasters. There are more ways to retrieve concepts. For instance, knowing the locations of disasters, the app can obtain the geographical features (e.g, island, mountain, or river) from OSM (i.e. OpenStreetMap) through Overpass API. Or, with the knowledge of the occurrence dates and the locations, the app can obtain the weather of disasters through a weather service. With these extra concepts, the app could return more accurate results.
One extension of this project is to connect the app with a tool that could generate a description from a report or from a piece of news. Currently, our app downloaded the headlines of disaster reports in ReliefWeb and stored them in corpus as the documents for search. These descriptions are formatted already. Differently, with such a tool mentioned above, any news or reports could be used in this app.
Our app could be combined with a recommendation system. For example, for a case in Recovers, the recommendation system may suggest labels to users according to the needs requested in those related disasters. Or, it may estimate the requests of needs without users' request so that these needs could be prepared earlier.
Built With
- bluemix
- cloudant
- concept-insights
- javascript
- node.js
- polymer
- relationship-extraction



Log in or sign up for Devpost to join the conversation.