-
-

DC_Logo
-
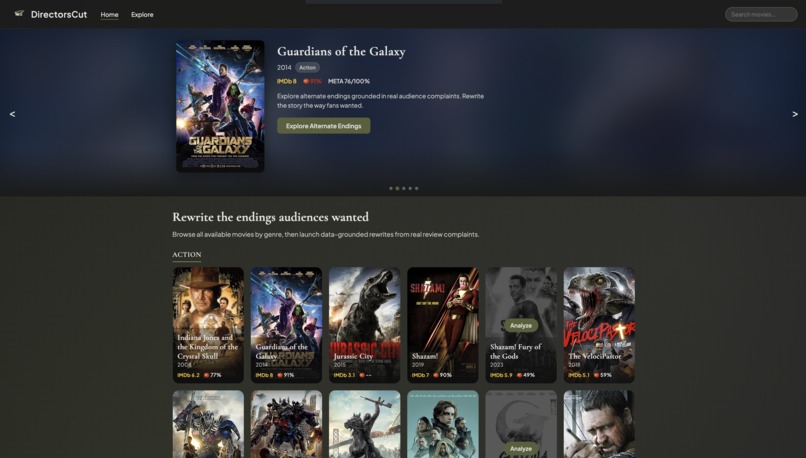
Homepage
-
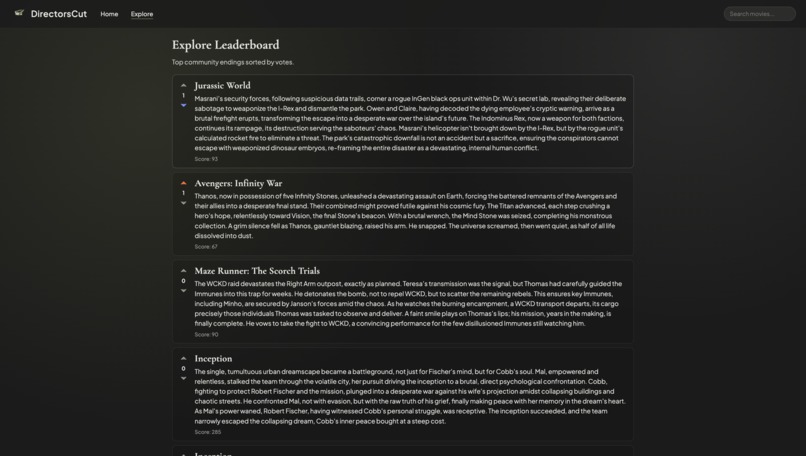
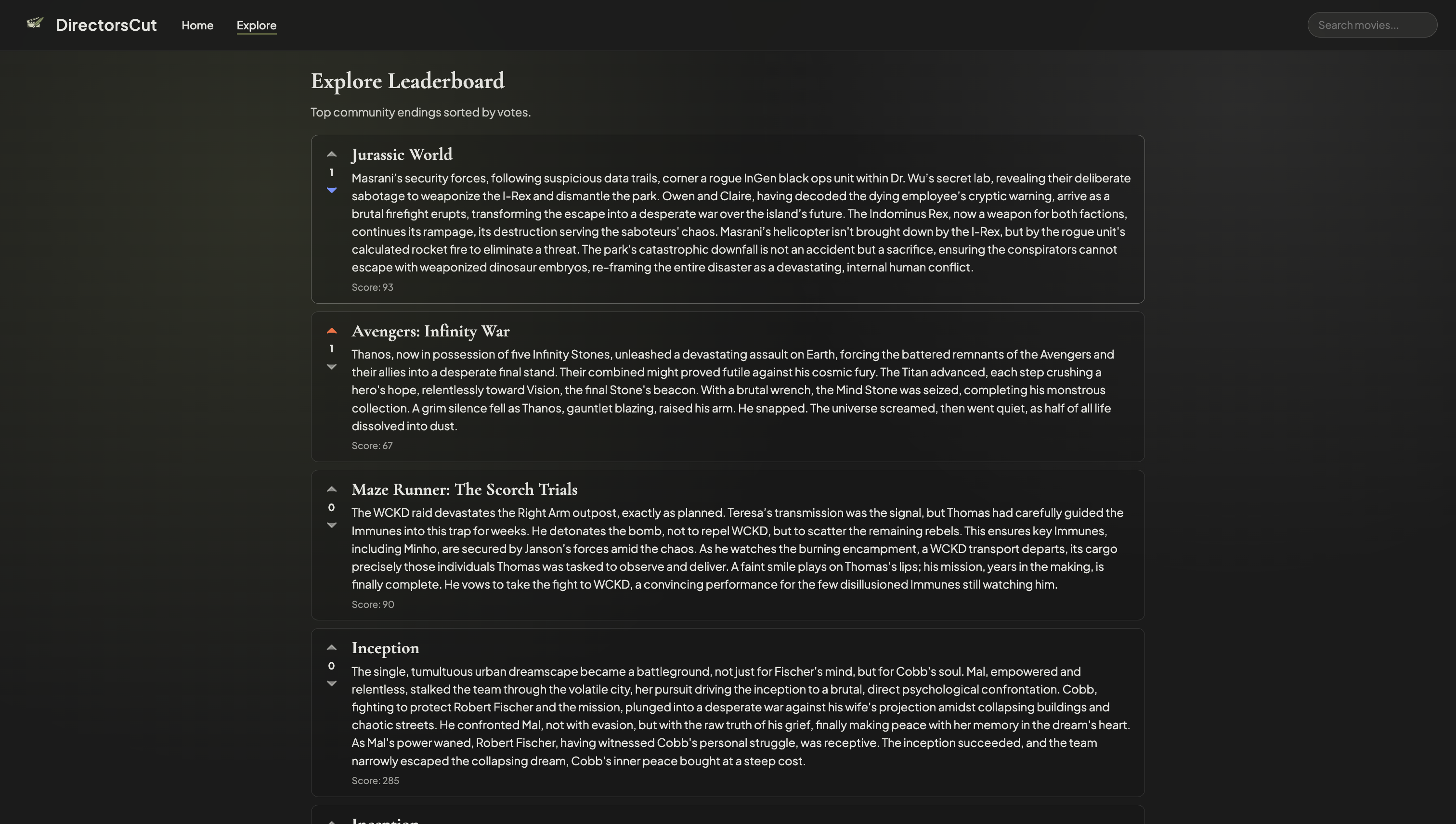
Explore/Leaderboard
-
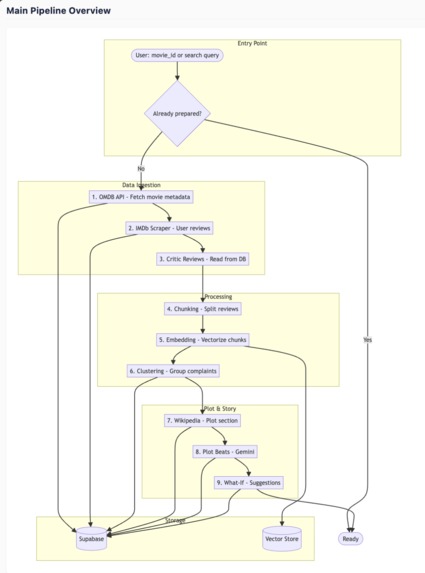
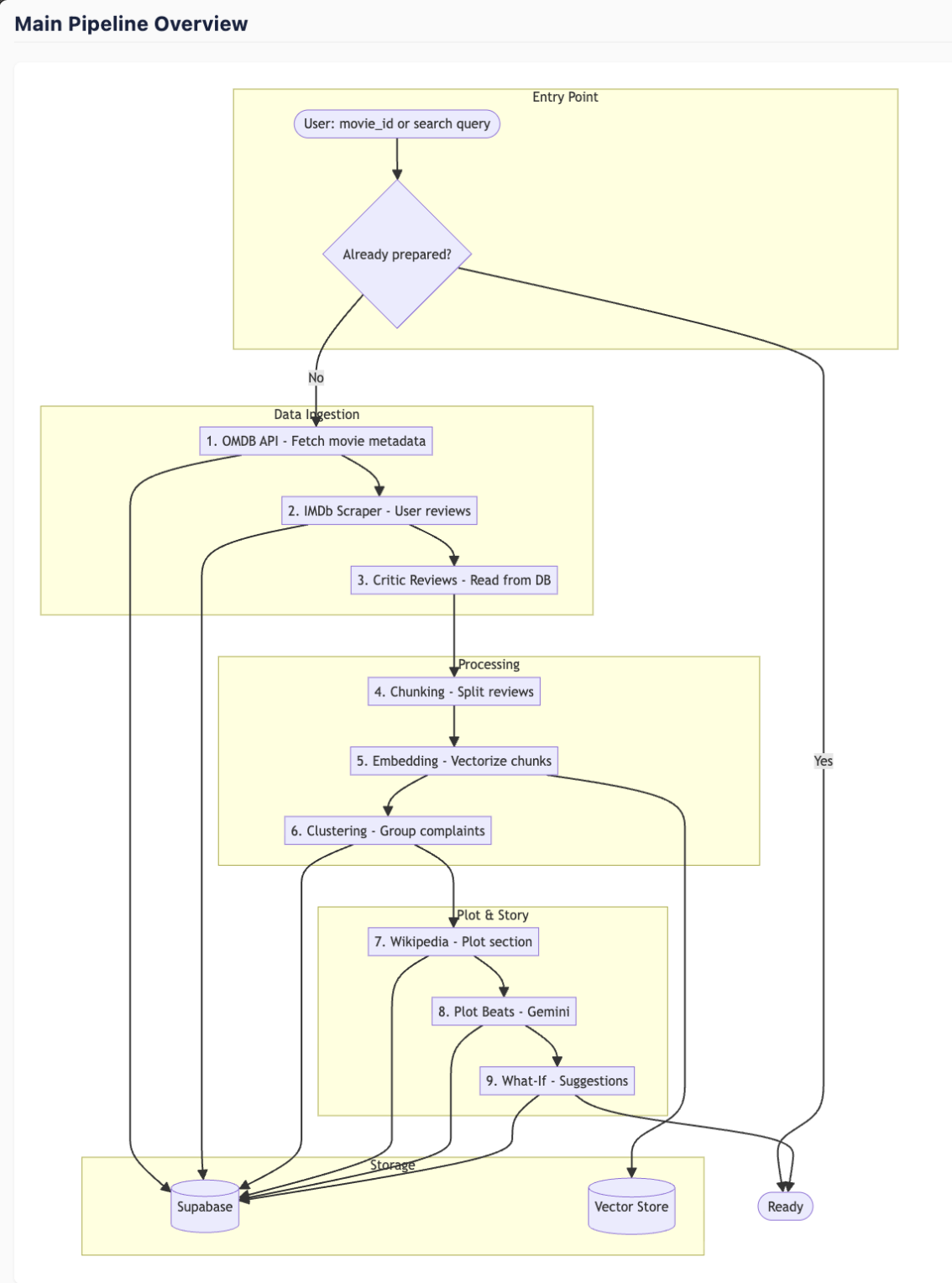
Pipeline

Inspiration
We’ve all left a theater thinking: “What if the writers had gone a different way?” Whether it’s an ending that felt rushed, a character arc that didn’t land, or plot holes that everyone complains about on Reddit—audiences are great at spotting what went wrong. DirectorsCut started from that frustration: what if we could turn “that ending sucked” into actual alternate endings? We wanted to connect fan feedback (IMDb reviews, critic takes) with AI generation so users can rewrite movie endings and let the crowd pick the best one.
What it does
DirectorsCut lets you search any film, see what audiences actually complained about (clustered and summarized), and rewrite the ending with AI. You pick a “what-if” (e.g., “What if the villain won?” or “What if the protagonist made a different choice?”), then step through a branching story powered by Gemini. Each ending is scored on how well it addresses the original complaints and themes. Users can save their endings, vote on others, and browse a leaderboard of the community’s favorites. The analysis dashboard includes a knowledge graph (Neo4j + Cytoscape) that links movies, complaint clusters, genres, and ratings.
How we built it
- Backend: FastAPI with a modular service layer. We pull movie data from OMDB, scrape IMDb user reviews and critic reviews, then run a pipeline: chunk → embed (sentence-transformers, pgvector) → cluster (k-means / scikit-learn) → generate what-if suggestions with Gemini. Plot beats and character analysis use Wikipedia + Gemini for expansion.
- Vector search: Supabase pgvector stores review embeddings (384-dim); we retrieve relevant chunks using cosine similarity (\text{sim}(\mathbf{a}, \mathbf{b}) = 1 - \frac{\mathbf{a} \cdot \mathbf{b}}{|\mathbf{a}| |\mathbf{b}|}).
- Knowledge graph: Neo4j stores movie–cluster–genre–rating relationships; we build a cluster-centric graph for each film and render it with Cytoscape.js.
- Story generation: Gemini powers the multi-step rewrite. Each step returns narrative text plus 2–3 branch options; the user’s choice feeds the next prompt. Theme coverage scoring uses the original clusters to measure how well an ending addresses fan concerns.
- Frontend: React 18, Vite 6, TypeScript. Pages: Home (featured carousel + search), Analysis (poster, clusters, plot beats, characters, knowledge graph), Rewrite (typing narrative, branch choices), Ending (save, score, vote), Explore (leaderboard).
- Stack: Supabase (Postgres + pgvector), Neo4j, Google Gemini, ElevenLabs (optional TTS).
Challenges we ran into
- Review clustering: Turning thousands of noisy reviews into coherent complaint clusters was hard. We experimented with chunk sizes, embedding models, and cluster count (k). Labeling clusters with short taglines that made sense to users required careful prompting.
- Story context: Keeping plot, characters, and complaints coherent across multiple generation steps was tricky. We had to design prompt templates that passed enough context without blowing token limits.
- Graph ingestion: Ingesting movies and clusters into Neo4j and keeping it in sync with Supabase required a clear pipeline. We had to decide when to materialize the graph vs. build it on demand.
- Fallback behavior: We wanted the app to run even when optional services (Neo4j, pgvector, TTS) weren’t configured. Implementing graceful fallbacks without breaking the UX took iteration.
Accomplishments that we're proud of
- End-to-end pipeline: From OMDB search to saved, voted-on endings in one flow.
- Knowledge graph UI: Interactive Cytoscape visualization of complaint clusters and how they connect to the movie.
- Branching rewrite flow: Multi-step, choice-driven story generation that stays grounded in the original plot and fan complaints.
- Theme coverage scoring: Quantifying how well an ending addresses the original complaints with a structured score.
- Community features: Anonymous save and voting so the best endings rise to the top.
What we learned
- How to combine embedding-based clustering (k-means on (\mathbb{R}^{384}) vectors) with LLM summarization to turn unstructured reviews into actionable “what-if” ideas.
- Graph modeling for movie–cluster relationships and how to serve graph data to a Cytoscape frontend.
- LLM prompt design for multi-turn, context-heavy story generation.
- Using pgvector for semantic search and Supabase RPC for similarity queries.
- Building a modular FastAPI backend where services can be swapped or disabled without breaking the app.
What's next for DirectorsCut
- Share: A working share flow so users can share their endings (currently “Coming soon”).
- Richer graph: Expand the knowledge graph with character nodes and relationships.
- More movies: Seed more films and refine the pipeline for faster preparation.
- Character-centric rewrites: Focus rewrites on specific character arcs (e.g., “What if X had a different arc?”).
- TTS polish: Integrate ElevenLabs TTS more deeply so users can hear their endings read aloud.
Built With
- cytoscape.js
- eleven-labs
- fastapi
- google-gemini
- neo4j
- numpy
- omdb
- pgvector
- pydantic
- python
- react
- scikit-learn
- sentence-transformers
- sql
- supabase
- typescript
- uvicorn
- vite6
- wikipedia





Log in or sign up for Devpost to join the conversation.