-
-
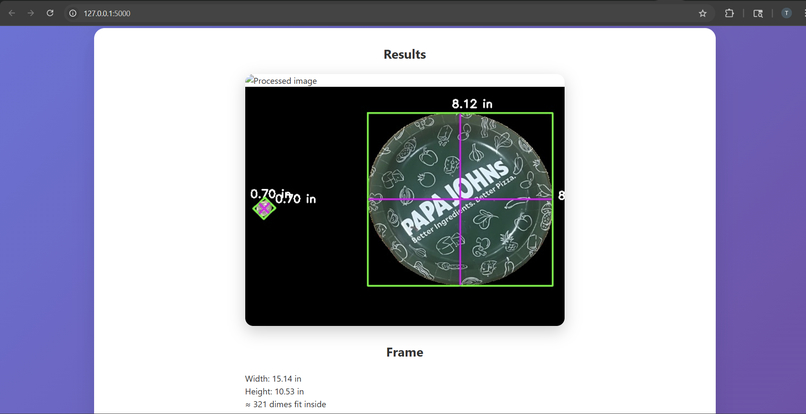
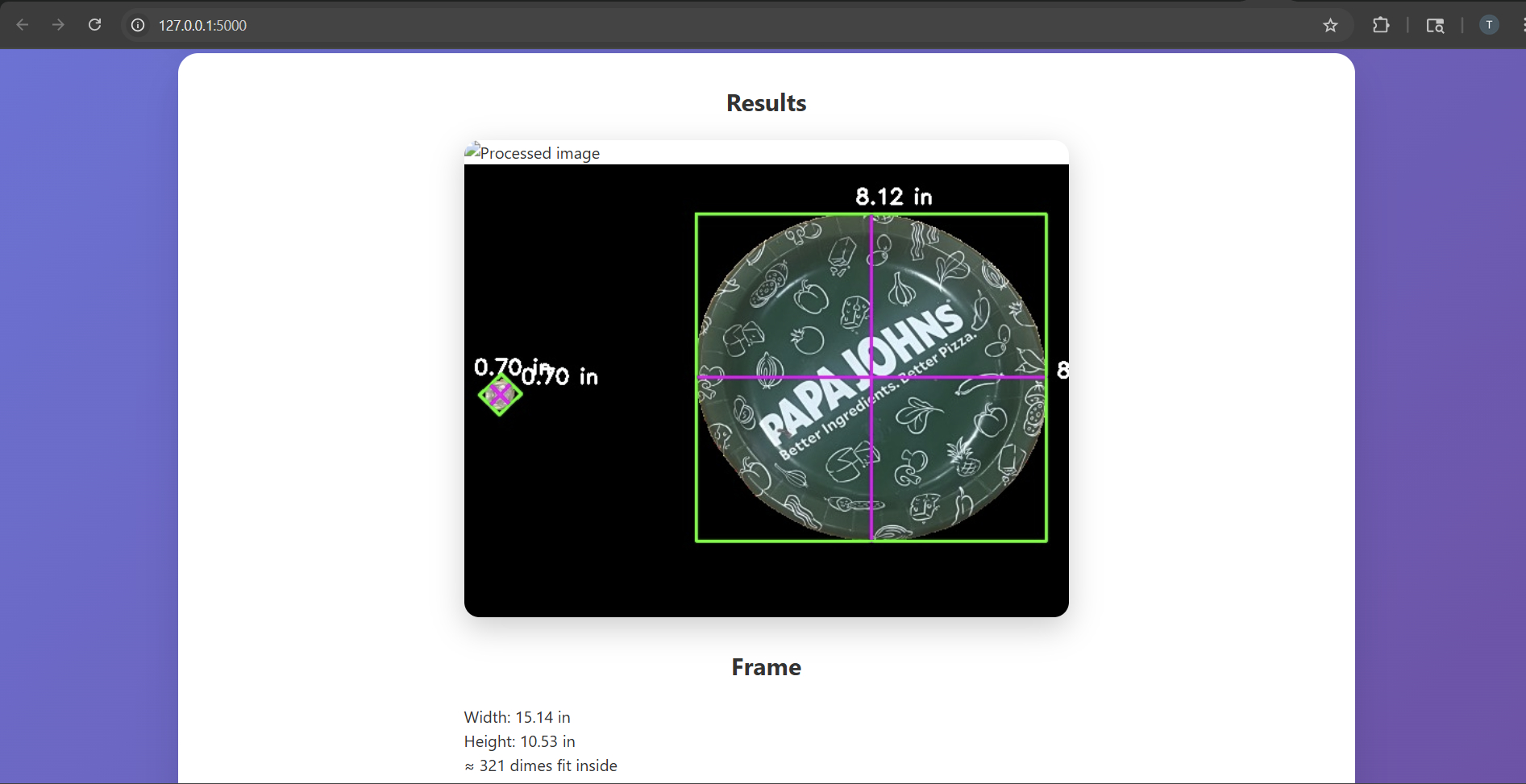
an example of its application
Inspiration
All of us have a passion for making lives easier through software. One thing that we were all wondering is when we want to quickly find sizes of different everyday objects, how could we do that without needing to use a ruler and by simply just taking a picture. We came to the conclusion that a viable idea would be to use a reference object that works with a ML model that could use the reference object to determine dimensions of other objects in the image.
What it does
DimEnvision is a web app that takes in an input image that should have a reference object in the image. Along with the reference object, there should be other objects in the image that the user wants to find the dimensions of. The input image is processed by an OpenCV and UNet model that removes image background and processes the reference object to find the dimensions of the other objects in the image. The web app then outputs information like the dimensions of other objects in the image, how many of the reference object can fit into other objects, and the size of the frame of the image.
How we built it
We used OpenCV and UNet for our machine learning models. We used Python as the backend and used Flask to connect the backend with the frontend. The frontend was made up of HTML, CSS, and JavaScript. There are two backend Python classes, one that actually runs the CV modeling and one that integrates Flask and Cloudflare to connect backend and frontend and make it easy for the user to run the web app on other devices, like a phone.
Challenges we ran into
One challenge was being able to accurately differentiate between foreground and background. Sometimes the model would classify the reference object as part of the background. The web app had issues in terms of actually running the CV model. Additionally, users that were trying to use the camera on mobile or running on Wi-Fi (as opposed to localhosting) were not able to at first. Integrating Flask was a challenge because connecting the data that the model was returning was a complex process.
Accomplishments that we're proud of
Firstly, we are proud of making a working product that is easy for users to use. Additionally, we faced an immense amount of challenges through each step of building this, which we were able to overcome. For instance, the CV model accurately being able to identify dimensions of objects from different angles was a huge win.
What we learned
We learned a lot about using OpenCV models, camera interfaces, frontend (HTML/CSS/JS), integrating Flask and Cloudflare, and working with JSON files.
What's next for DimEnvision'
Being able to auto-identify reference objects without presets using the AI model Able to recognize objects being different distances from the camera and still scale it correctly Being able to work with bigger objects Being able to work under more dynamic circumstances, like different backgrounds and angles


Log in or sign up for Devpost to join the conversation.