-
-
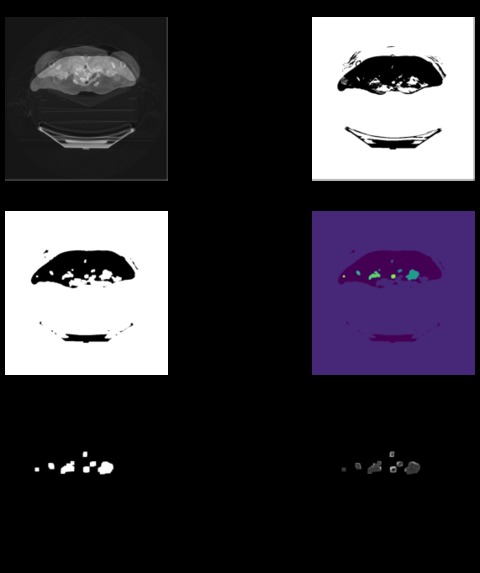
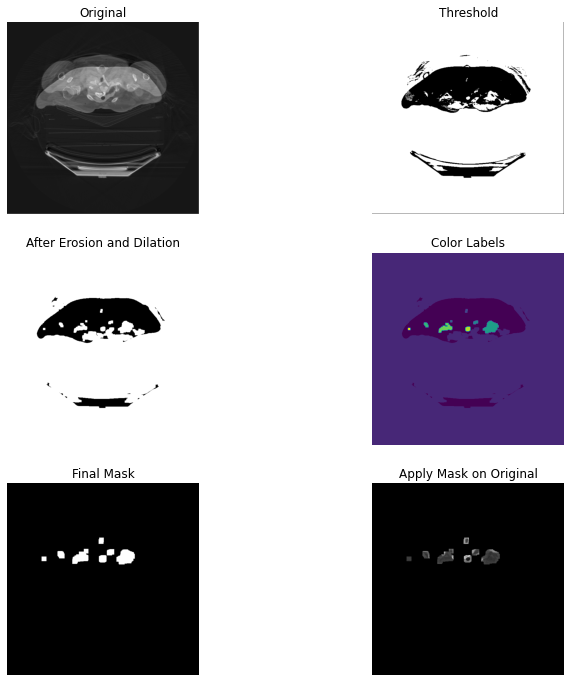
Segmentation of a PCR CT scan image
-
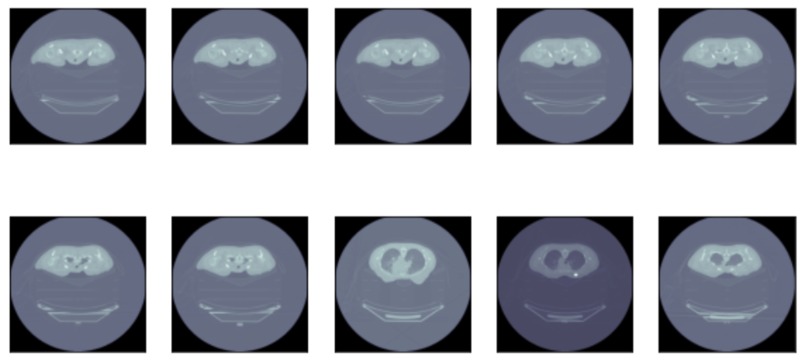
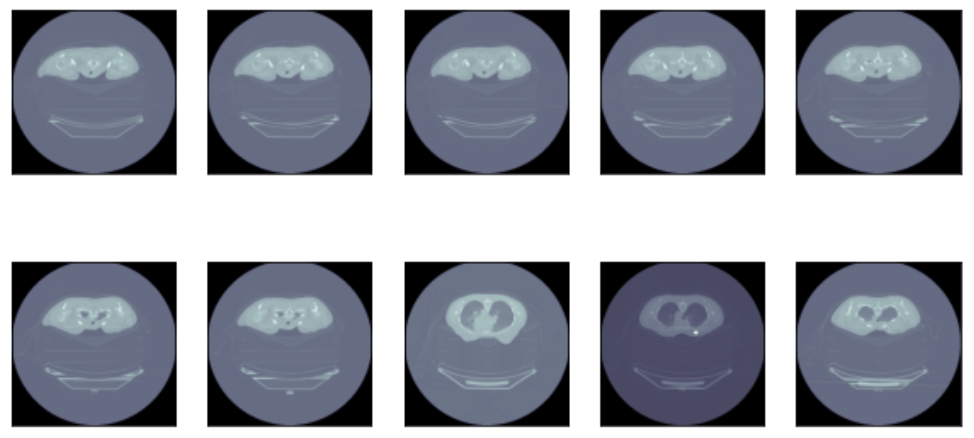
Sample of PCR CT Scan data
-
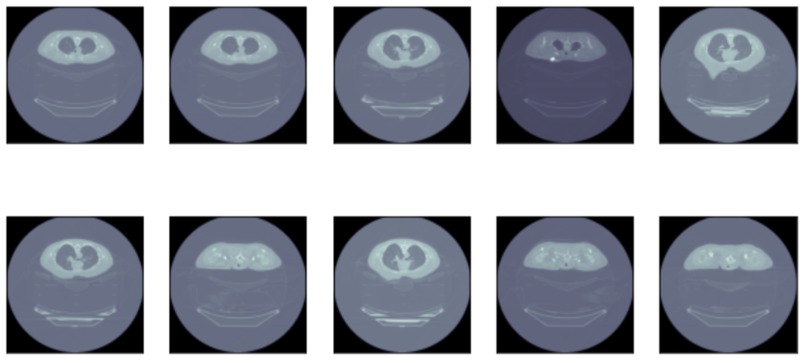
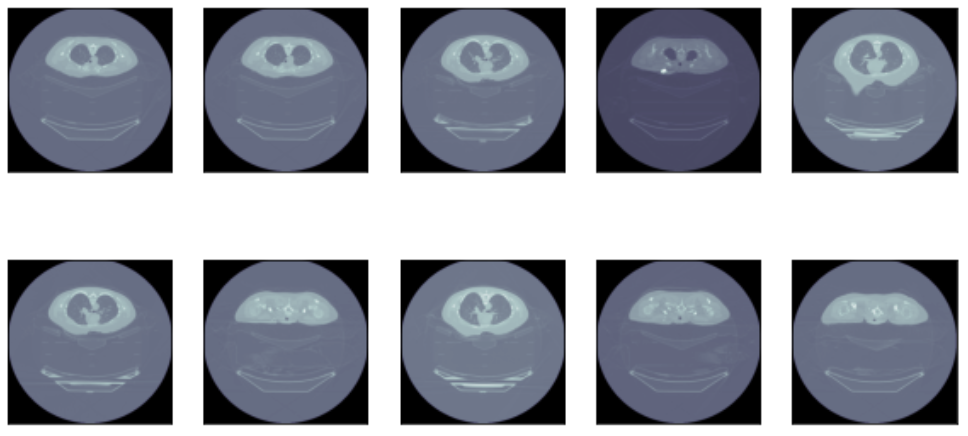
Sample of Non-PCR CT Scan data
-
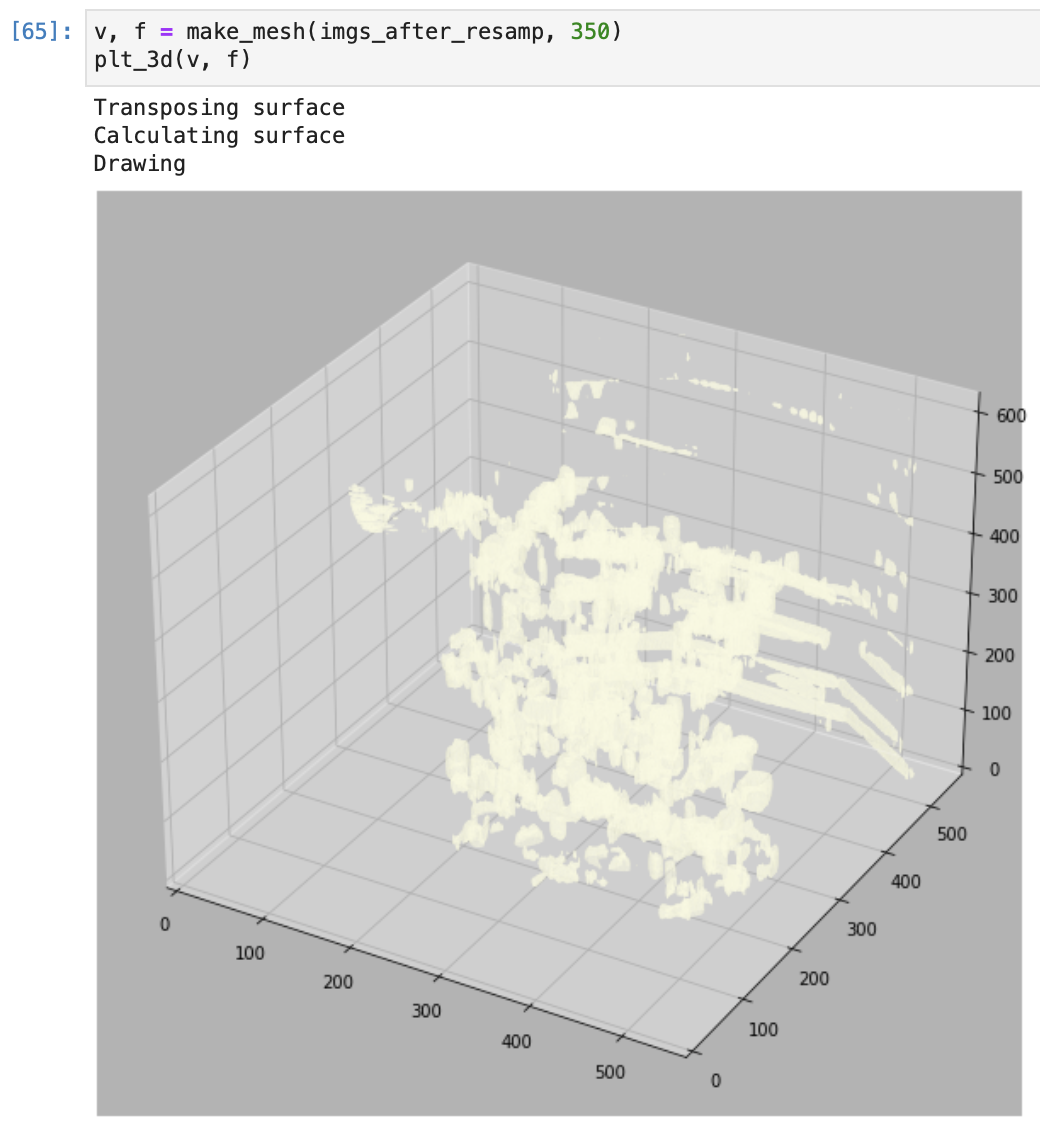
3-D Plot of a PCR CT scan image
-

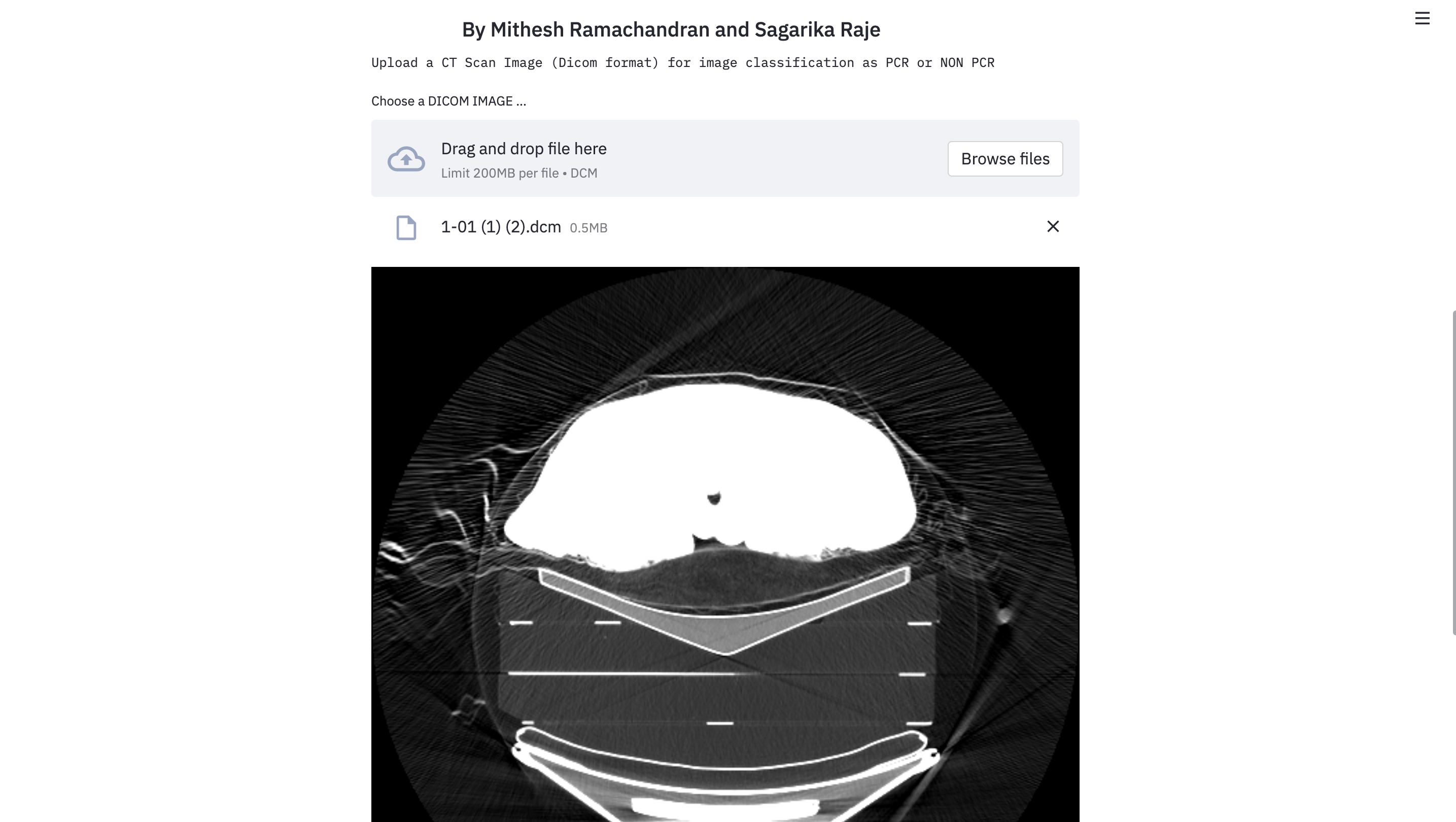
A peek from our app
-
A peek from our app (part 2)
-

A peek from our app (part 3)


Inspiration
No matter how much appreciation we shower on frontline workers for compromising their safety as the world grappled with a crisis unbeknownst to mankind, it will never be enough. Seeing our parents who are doctors by profession, spending days in the hospital for the care of COVID infected patients left us wondering how we can use leverage technological advancements like AI in aiding the healthcare sector too, for example, improve diagnostic accuracy, prevent pandemics and epidemics, and reduce the risk of harmful diseases. When we received an email to this hackathon, we realised this was exactly what we were looking for, and decided to grab this opportunity!
Earlier in the year, our college hosted a webinar regarding Breast Cancer and the perils it brings to the patients’ lives. Being the most common type of cancer in women, breast cancer accounts for 14% of cancers in Indian women. It is reported that every four minutes, an Indian woman is diagnosed with breast cancer. Breast cancer is on the rise, both in rural and urban India. As you know, surviving cancer becomes more difficult in higher stages of its growth, and more than 50% of Indian women suffer from stages 3 and 4 of breast cancer. Post cancer survival for women with breast cancer was reported 60% for Indian women, as compared to 80% in the U.S. So for this competition, we decided to take on the challenge to curate a breast cancer detection program, which determines whether a CT scan is malignant, or benign, using our knowledge of Deep Learning and Image Processing.
What it does
Pathological Complete Response (PCR) is defined as the disappearance of all invasive cancer in the breast after completion of neoadjuvant chemotherapy, although some authors require clearance of residual disease in axillary nodes. Achievement of PCR has been confirmed to increase both overall survival and disease-free survival with the greatest benefits seen in triple-negative and ER-/HER2+ patients.
Non-Responder or progressive disease (Non-PCR) happens to high-risk patients who do not achieve a pathologic complete response after neoadjuvant chemotherapy in triple-negative breast cancer. There is now sufficient evidence that if neoadjuvant chemotherapy leads to complete pathologic response, the patient will enjoy a better outcome. Therefore, assessment of the degree of response to neoadjuvant chemotherapy has a major impact on patient selection and the follow-up management of each patient defines the patients’ outcome.
Our project aims to identify and predict PCR or non-PCR response by conducting a comparative study of various Machine Learning and Deep Learning Algorithms using DICOM (Digital Imaging and Communications in Medicine) format.
How we built it
The Dataset information obtained from The Cancer Imaging Archive (TCIA) Public Access is summarised in the below table:
| Responder | Count |
|---|---|
| Non-PCR/With Cancer | 39 |
| PCR/Without Cancer | 20 |
| Total Samples | 59 |
"Responder" represents:
- PCR: Pathological Complete Responder
- NON-PCR: Non -Responder or Progressive Disease "Count" represents the number of folders. Here, for example, ‘Non-PCR’ has 39 folders which represent 39 different patients & has many sub-folders whose name gives us the date & time at which the CT scan was taken. Each sub-folder has 83 images of these CT scans taken from different angles.
Detailed Description of Dataset
| Collection Statistics | Description |
|---|---|
| Number of Studies | 214 |
| Number of Series | 530 |
| Total Samples | 59 |
| Number of Images | 100,835 |
| Number of Series | 530 |
| Modalities | MR, PET, CT |
| Total Size in GB | 11.286 |
We randomly selected 1826 images from the dataset and divided them into training and testing subsets. These images then underwent preprocessing where we converted them all to arrays and normalised the values. After a simple visualisation, we built a classification model and performed segmentation on the new dataset.
CLASSIFICATION
Approach: Convolutional Neural Networks To train the Dicom images we decided to use a CNN. The first layer of the neural network had a conv2D layer with 64 filters with a (3,3) kernel for which we used the relu activation function. We then added the pooling layer, where we used MaxPooling. The pooling kernel used here was a (2,2) kernel.
This was followed by another set of convolution-relu-pooling layers. The conv2D layer had 32 folders with a (3,3) kernel and the pooling kernel used here was (2,2).
2D convolutions were used for each slice present in the 3D image.
After a lot of trial and error, we realised that increasing the number of layers, decreased our accuracy. Hence, we stuck to using only two conv-relu-pool layers. We then flattened the layers and added Dropout regularisation of 0.2.
Finally, we added a dense layer of 50 neurons with a relu activation function. Then we had our output layer with 2 neurons. We used the sigmoid activation function for the final layer.
For this network, we used binary cross-entropy as it is a binary classification problem. We further did parameter optimization and chose Adam optimizer for our model compilation, and accuracy metric for our results.
SEGMENTATION
For this, we followed a simple semantic segmentation approach to generate masks, using intensity values and K means clustering and techniques like image normalisation and thresholding. We then separated the foreground and the background with K means clustering. We created 1 cluster each (fg, bg) totalling two clusters. We then thresholded the images with the mean of cluster centres and further applied morphological transformations like erosion, to remove the unwanted smaller elements from our ROI. We used dilation to avoid clipping the tissues. The final step of the mask was filling out the rest of the image. So we used a larger dilation with a 10,10 kernel to obtain our mask.
Challenges we ran into
One of the main challenges we faced was working with the dataset with limited RAM storage. Since the images used in this project were in DICOM format, the accuracy and precision of the images reduced when used in python, especially for something as precise as the difference between PCR or a Non-PCR responder to Neoadjuvant Chemotherapy. Also, since Google Colab provides only 12.72 GB free RAM, despite our very rich and extensive database, we were constrained to use only part of it & this resulted in the deformation of data images. We believe with better RAM accessibility and more precise reading of DICOM images in python these models can give better results. Lastly, despite trying our best, due to limited resources and time, we couldn't complete the training of our fine-tuned U-Net model for segmentation.
Accomplishments that we're proud of
We’re proud to take on this challenge as a stepping stone towards a better, more technologically advanced healthcare sector. From helping us brush up on our image preprocessing skills to helping us learn 3 Dimensional plotting, building this project indeed is an achievement for us on its own. Writing an efficient code that cleaned over 2GB of data, debugging, running it through various classification and segmentation algorithms and most importantly, patiently waiting for it to run in under 48 hours wasn’t easy at all, but we thoroughly enjoyed every minute of it. We are also grateful for the opportunity we were presented with, in this hackathon, to meet and interact with people all over the world and discuss our approaches to the problem statement. It made us realise that it is not about coming up with the correct solution, it is about coming up with the most unique one.
What we learned
This hackathon helped us put all the theoretical concepts we’ve learnt so far in our graduate studies to use. Since it was our first virtual hackathon we realised the importance of good communication skills to present and pitch your ideas to others and even to your own teammates. We learnt about concepts like Focal loss which helped us with our segmentation and also about the AlphaTau dataset, which dealt with the detection of seeds injected in patients tumours, using CT scan images, thanks to Mr Ilay Kamai.
What's next for DIME - Disease Identification Made Easy
Our main focus for the future of DIME is to get accessibility to enough RAM to process the data. Furthermore, we would work on making the image more specific to the area of change to help have a more precise analysis. We would also like to consider different parameters of breast cancer and include them in our analysis, along with which we would also like to explore the other shortcomings of specific medical image analysis.
Built With
- ai
- deep-learning
- google-colab
- keras
- pydicom
- python












Log in or sign up for Devpost to join the conversation.