-
-
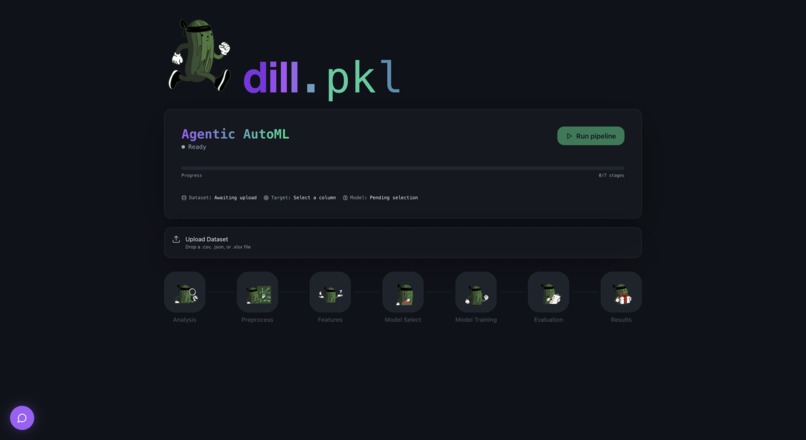
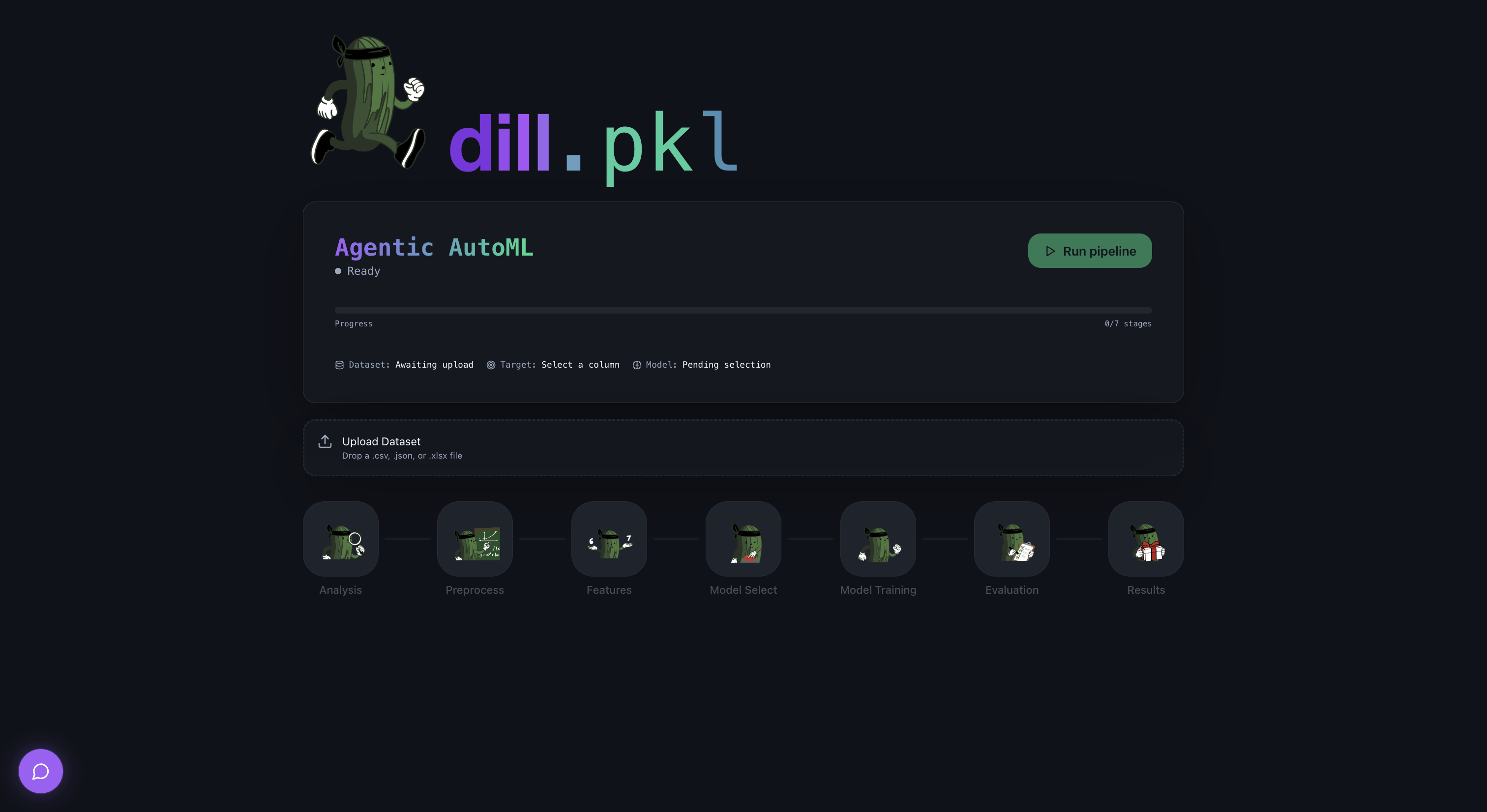
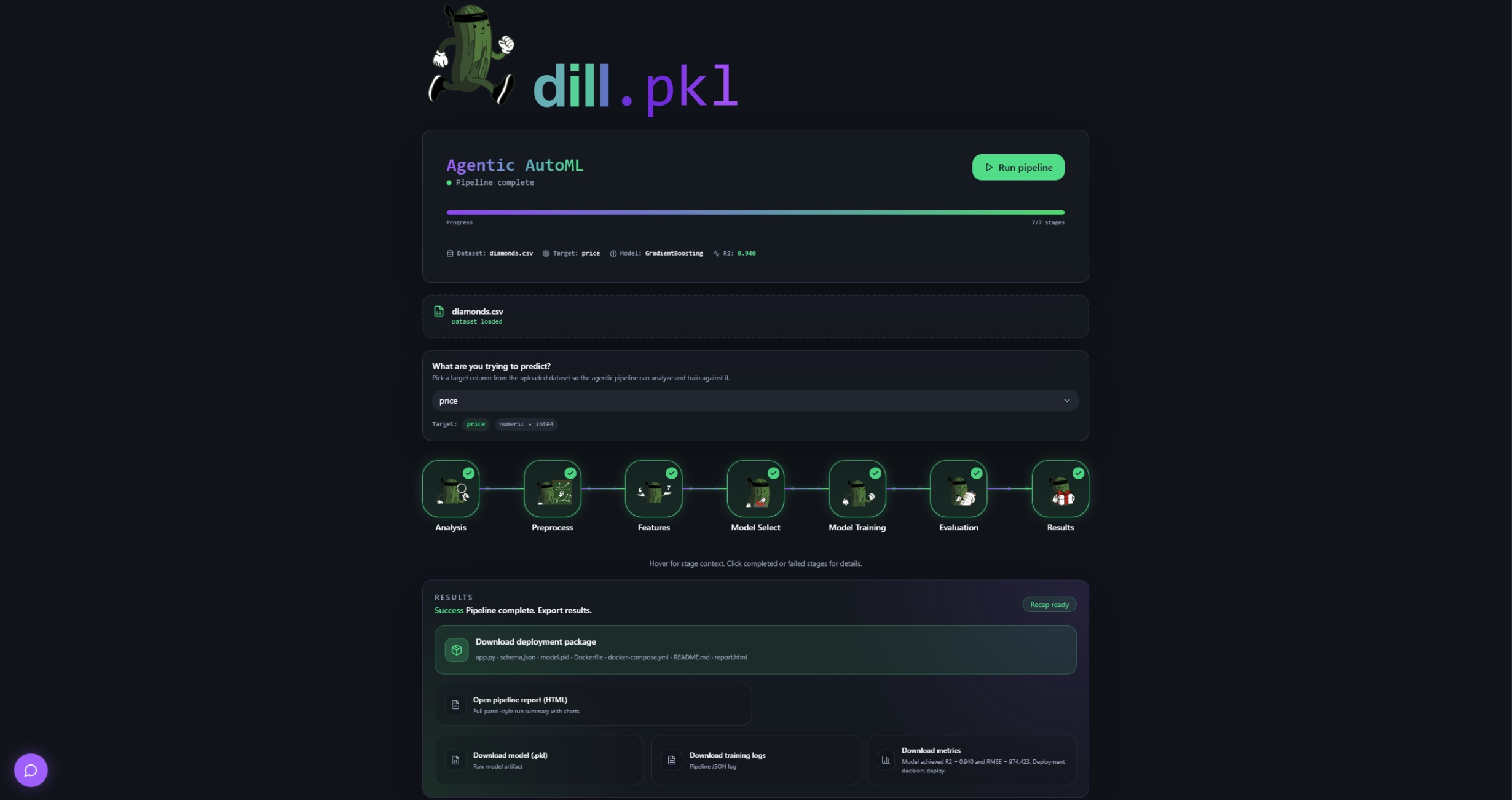
Main Dashboard
-
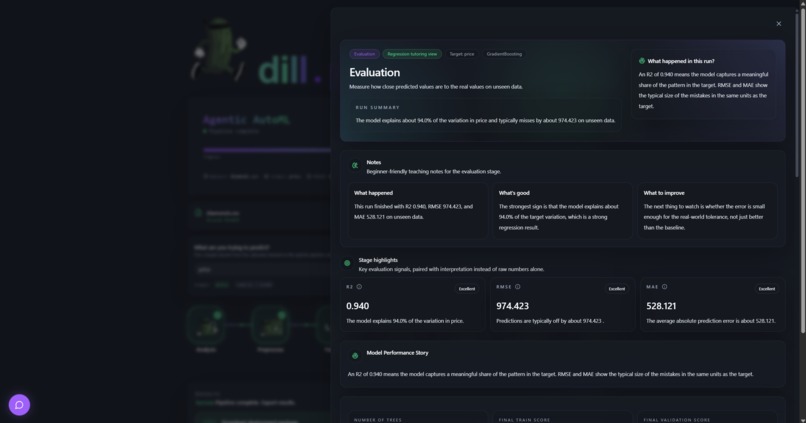
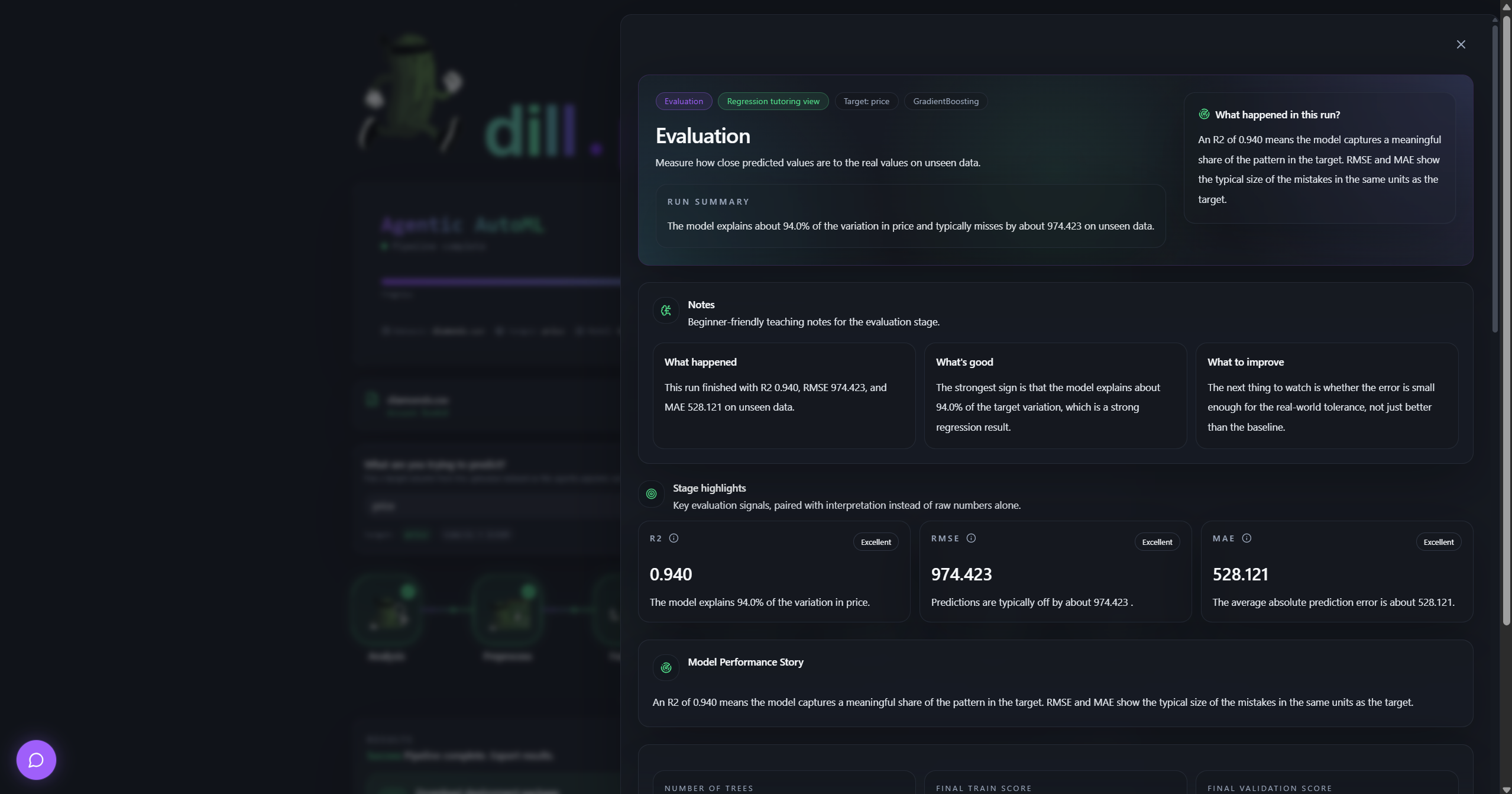
Evaluation Panel
-
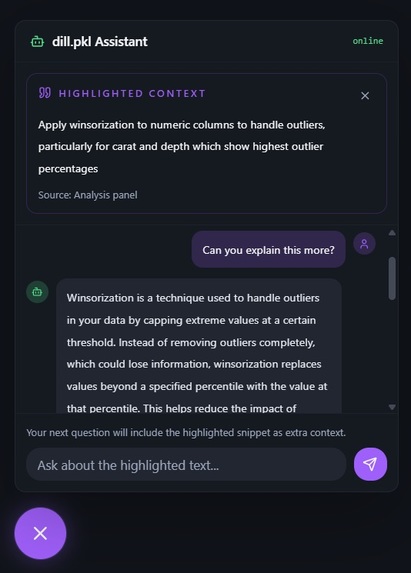
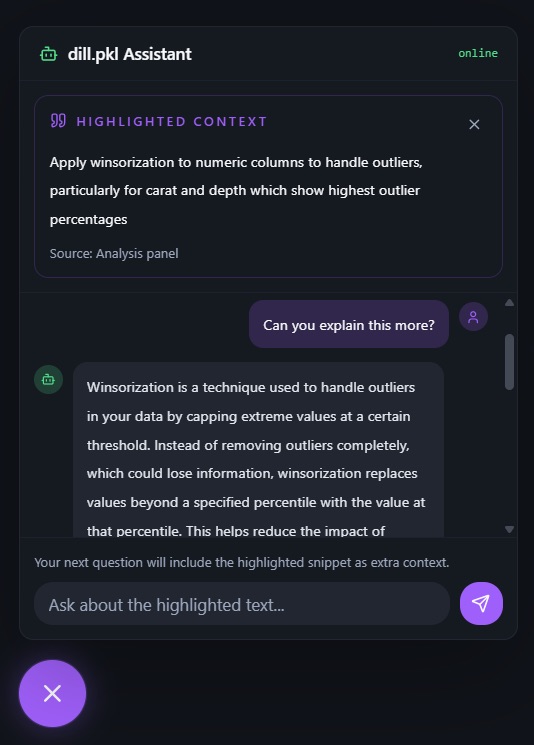
Chatbot Demo
-
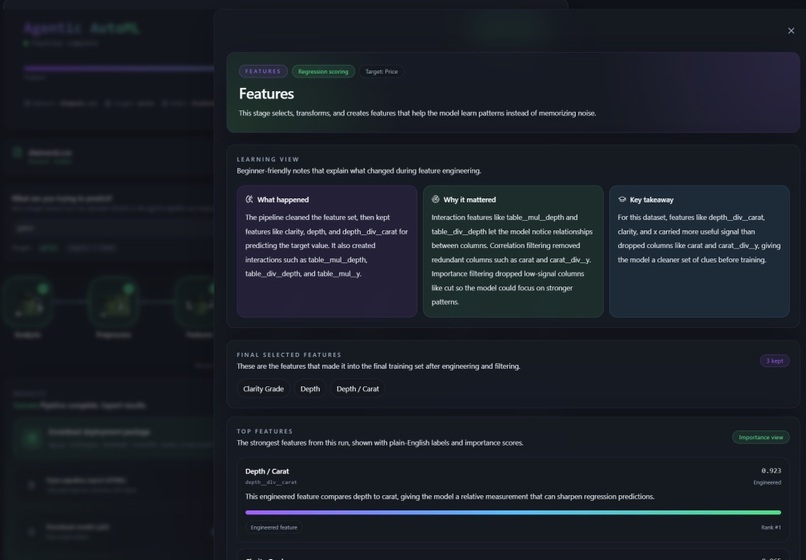
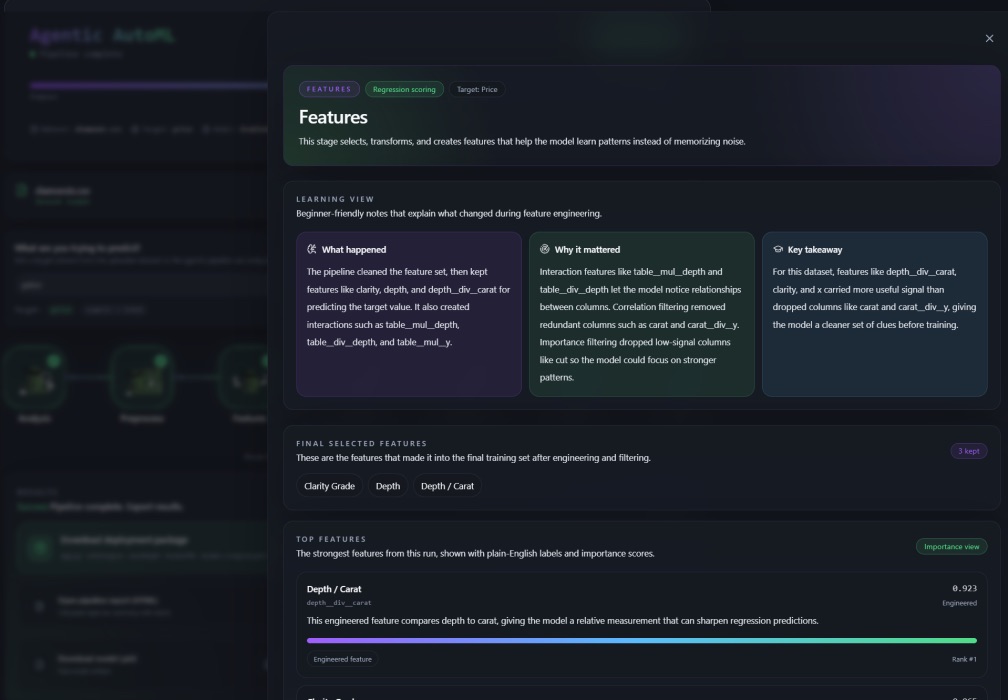
Feature panel after removing colour grade as a selected feature
-
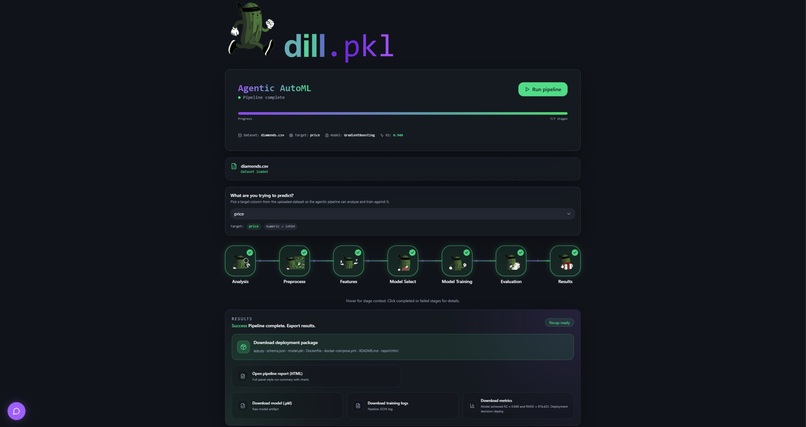
Pipeline Complete
-
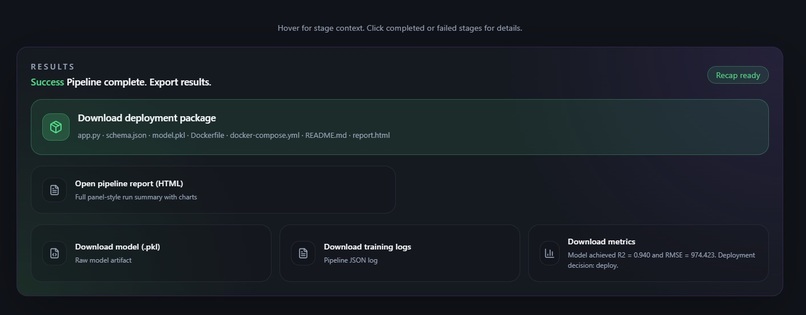
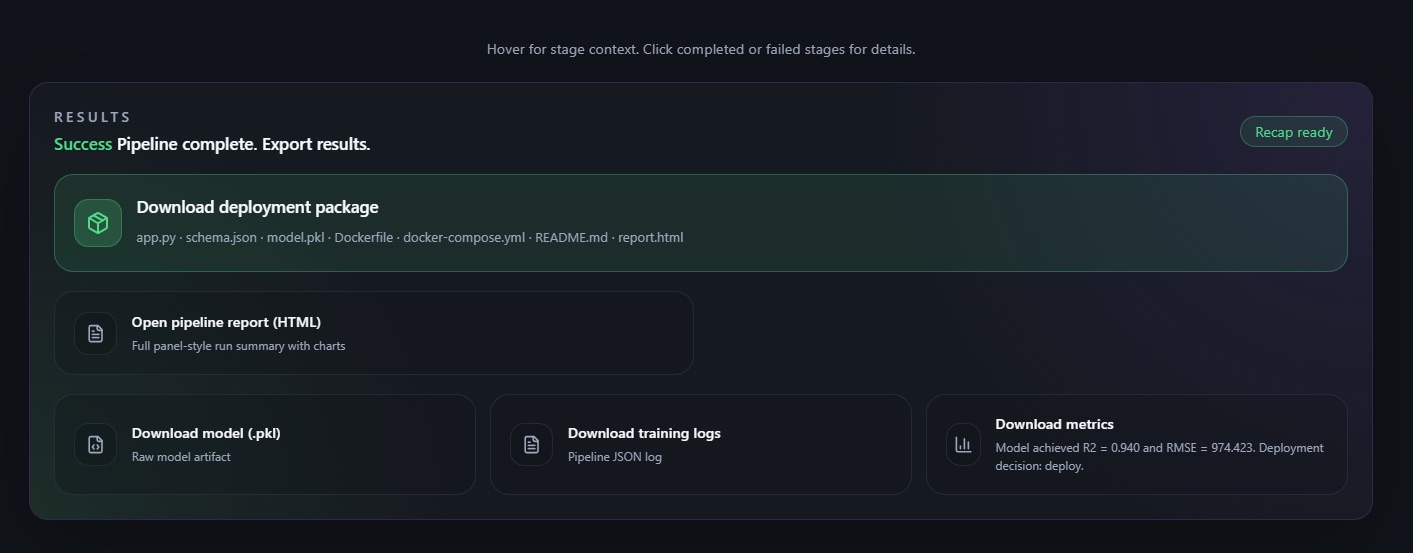
Deployment Package Ready
-
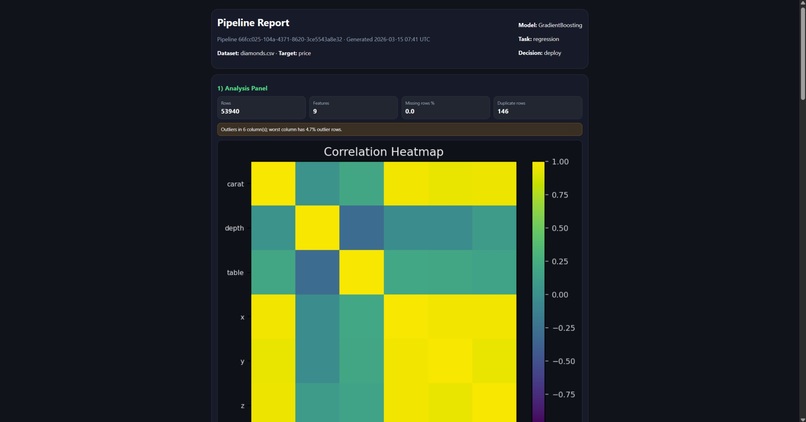
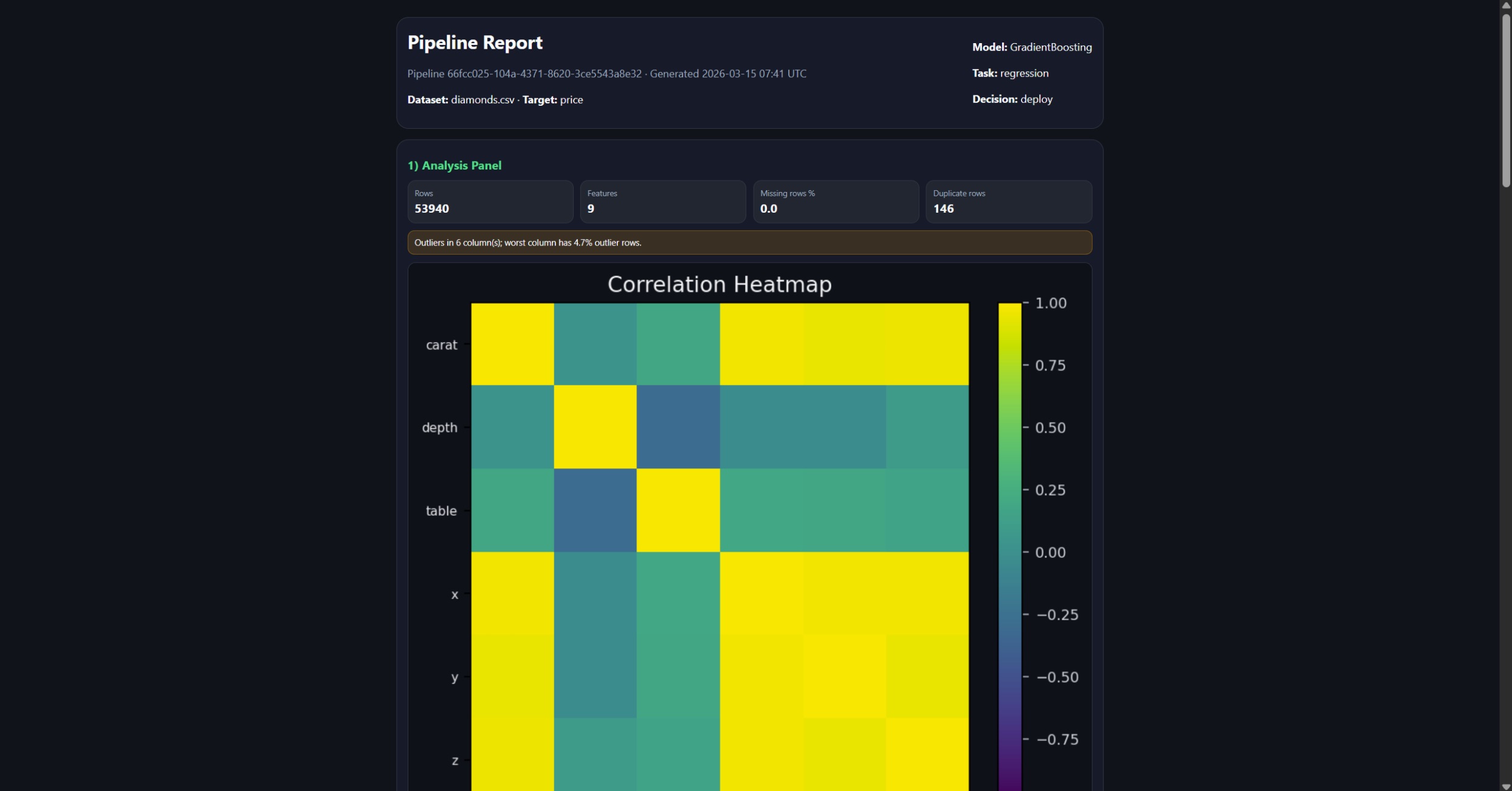
Pipeline Report
-
67
Inspiration
Every software team has data worth predicting from. Most never act on it. Not because the idea isn't there, but because building a reliable ML pipeline is a project in itself. Understanding the dataset, deciding how to preprocess features, selecting the right algorithm, tuning hyperparameters, validating results, debugging failures, then somehow turning a trained model into something that actually runs in production. Each of those steps demands expertise that most dev teams don't have sitting around. So the ML feature gets deprioritized, the CSV sits in a folder, and the insight never happens.
Existing AutoML tools don't fully solve this. They automate the training step but leave everything else: the reasoning, the debugging, the deployment, the explanation as an exercise for the reader. You get a model file and a confusion matrix. You don't get answers to the questions that matter: why was this model chosen over the others? Why was that feature dropped? What do I do when the pipeline breaks at 2am?
And once the run finishes, you're stuck with it. There's no way to say "make it less prone to overfitting" and have the system actually respond.
dill.pkl was built around a different premise: a machine learning tool should produce not just a model, but a complete, auditable, shippable result, while being able to explain every decision it made along the way and change course when you ask it to.
What it does
dill.pkl is an AutoML web application where a team of eight AI agents runs your entire machine learning pipeline, from raw CSV to deployed, documented model, while logging every decision in plain English.
You upload a dataset, pick the column you want to predict, and hit run. The pipeline executes sequentially through eight stages, each vizualised in real time in the browser. Click any stage node to open a detail panel showing what the agent found, what it decided, and why. If that's not enough, you can keep talking to it to answer questions and change model workflows. When the pipeline completes, you download a deployment package and walk away with something you can actually ship.
The eight pipeline agents handle:
Dataset analysis: column profiling, missing value detection, outlier flagging, correlation mapping Preprocessing: imputation, categorical encoding, numeric scaling, train/test splitting Feature engineering: polynomial and interaction feature creation, redundancy pruning via feature importance Model selection: LLM selects up to three candidate algorithms, each with fixed parameters and a tuning search space, with written reasoning for every choice Training: all candidates trained in parallel, Optuna hyperparameter optimization per candidate, comparison by cross-validated score Evaluation: accuracy, F1, AUC, RMSE and more; overfitting detection; deploy or reject decision Deployment: model artifact saved with full metadata, deployment package generated Explanation: SHAP-style feature importance and plain-English interpretation of results
Conversational pipeline agent
A chat interface gives you full control over the pipeline through natural language. This isn't a Q&A wrapper. Rather, it's an orchestration agent that can modify, rerun, and audit the pipeline safely.
Ask it to include a feature it dropped and it updates feature engineering and reruns every downstream stage. Ask why a column was selected and it surfaces the stored reasoning from the explanation stage. Tell it to undo the last change and it restores the previous configuration and reruns. Every revision is stored as a named diff, metrics before and after, features added or removed, config changes. So no experiment is ever lost and every result is reproducible.
Deployment Package
The deployment package is a complete, ready-to-run zip: a schema-validated FastAPI serving endpoint, pinned requirements.txt, Dockerfile, docker-compose.yml, and a README.md covering what the model does, what inputs it expects, what the output means, and known caveats from the evaluation stage. Run docker-compose up and your model is serving. The generated README.md transfers knowledge automatically, removing human dependency.
How we built it
Backend
The backend is a FastAPI application with a central orchestrator that runs all eight agents in sequence, passing a shared stage_results dictionary between them so each agent has full context of everything that came before.
Each agent is an independent Python class that builds a structured prompt from prior stage results, calls an LLM via OpenRouter, and parses the response into a typed output contract. We built a multi-stage JSON recovery system for the LLM responses (BOM stripping, fence stripping, balanced-brace scanning, and common repair heuristics) because real-world LLM output is messier than the happy path.
Model training is handled by a ModelComparator that accepts the candidate specs output by the ModelSelectionAgent, including per-candidate fixed_params and search_space, and trains each one independently. Hyperparameter optimization uses Optuna, with each candidate's search space passed directly from the model selection output so the HPO is always aligned with what the LLM intended. The best candidate by CV score becomes the selected model.
The conversational agent is built as a separate orchestration layer on top of the pipeline. A RevisionPlanner converts natural language requests into structured revision plans: identifying intent, affected stages, and exact config changes. A ControlledActionRegistry enforces that only safe, deterministic modifications are allowed; the LLM interprets the request but never directly controls execution. A DependencyAwareRerunEngine restarts the pipeline from the earliest affected stage, leaving prior stages untouched. Every revision is logged by a RevisionHistoryManager that supports undo, cross-run comparison, and full auditability.
Configuration is managed via Pydantic settings read from a .env file, with feature flags for multi-model training, HPO, and ensemble methods.
Frontend
The frontend is React 18 with TypeScript and Vite. Pipeline state is polled via React Query, which drives the node graph animation — each stage node transitions through waiting → running → completed/failed with a live log stream below. Stage detail panels render visualisations appropriate to the stage type: correlation heatmaps for analysis, bar charts for feature importance, loss curves and confusion matrices for training and evaluation, model selection cards with candidate comparisons. The conversational agent surfaces as a floating chat panel that streams responses and displays revision diffs inline alongside the pipeline graph.
Challenges we ran into
Making the pipeline feel real-time without overcomplicating the backend. We kept pipeline state in-memory on the FastAPI side for simplicity, with the frontend polling for updates. This works well for the local/single-user case and let us move fast, but it's the first thing that needs to change before this runs as a shared service.
Making pipeline modifications safe and deterministic. The conversational agent needed to feel flexible without being unpredictable. The solution was to keep the LLM out of the execution path entirely. It plans, but a deterministic action registry executes. This means a user can say "try something different" and trust that the system won't do something unexpected to their pipeline config.
Accomplishments that we're proud of
The thing we're most proud of is that dill.pkl produces results you can actually interrogate. Every model selection decision has written reasoning. Every feature that gets dropped has an explanation. The evaluation stage produces plain-English insights, not just numbers. And when something doesn't seem right, you can say so in plain English and the system responds, replans, and shows you the diff. We've seen AutoML tools that treat the pipeline as a black box you submit a dataset to and wait. dill.pkl treats it as a process you should be able to follow, question, and learn from.
We're also proud of the multi-model HPO architecture. The fact that model selection outputs a typed search space per candidate, and that search space flows directly into Optuna without any translation layer, means the LLM's intent and the actual optimization are always in sync.
And the revision system. The idea that every conversational change is a named, diffable, undoable revision (not a destructive overwrite) means the pipeline has a proper history, not just a current state.
What we learned
We learned how to keep agent context coherent across multiple stages. Each of our 8 agents need enough context from prior stages to make good decisions, but sending the entire accumulated state to every LLM call is expensive and noisy. This taught us that finding the right balance (what to pass, what to summarize, and what to discard) requires careful design of the stage results contract.
Building the conversational agent taught us that the right role for an LLM in an agentic system is interpretation, not execution. Once we put a controlled action registry between intent and execution, the system went from unpredictable to trustworthy. Designing the dependency-aware rerun engine forced us to model our own architecture explicitly, helping us understand which stages depend on which in a way that simply building the pipeline never required.
What's next for dill.pkl
Persistent pipeline versioning
Store and diff runs across sessions to compare two pipeline runs side by side, see which parameter changes moved the metrics, understand what the model looked like before the last preprocessing change. Currently, the audit trail exists per-run; we would like to make it cross-run.
Deploying dill.pkl as a hosted service
We would like to deploy dill.pkl as a product anyone can use without touching a terminal. The core architectural change is moving pipeline state out of memory and into a persistent store. This would require Postgres for metadata and revision history and S3 for artifacts, which unlocks multi-user support, saved pipelines, cross-session revision history, and shareable run links. Alongside the hosted version, a self-hosted path matters equally: a single docker-compose.yml that spins up the entire stack locally, combined with support for local LLM backends like Ollama or vLLM, gives teams handling sensitive data a fully air-gapped deployment where nothing leaves their machine.
Deep learning and LLM fine tuning support
Deep learning support would expand the types of models available in the system, adding neural architectures such as MLPs, TabNet, and 1D CNNs. These models can perform better than classical methods on datasets with many features, complex nonlinear relationships, or high-cardinality categorical variables.
LLM fine-tuning enables a different use case: helping teams adapt language models to their own text data. Instead of manually preparing datasets, selecting base models, and running training scripts, the system would automate the process using LoRA fine-tuning through Hugging Face PEFT, with agents handling dataset preparation, training, and packaging. The final deployment would ship lightweight adapter weights rather than a full model.pkl.
Both features depend on GPU hardware. While neural networks can technically run on CPUs, training becomes extremely slow. Tasks that take minutes on a GPU can take hours on a CPU. In addition, LoRA fine-tuning even a 7B parameter model typically requires at least a 24GB GPU.
For the hosted version of dill.pkl, this means GPU-backed compute instances. For self-hosted users, a CUDA-capable GPU is required, as these features are designed to run on GPU hardware.
Built With
- docker
- fastapi
- lightgbm
- numpy
- openrouter
- optuna
- pandas
- pytest
- python
- radix
- react
- recharts
- scikit-learn
- shap
- tailwind
- typescript
- uvicorn
- vite
- xgboost

Log in or sign up for Devpost to join the conversation.