-
-
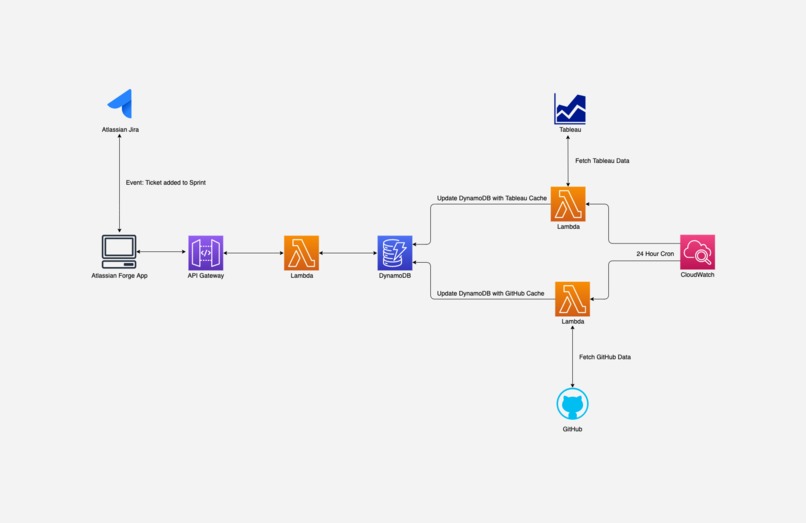
Project Architecture
-

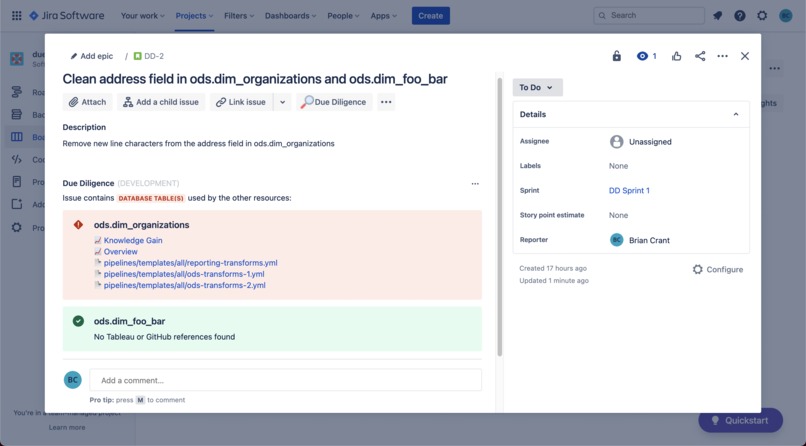
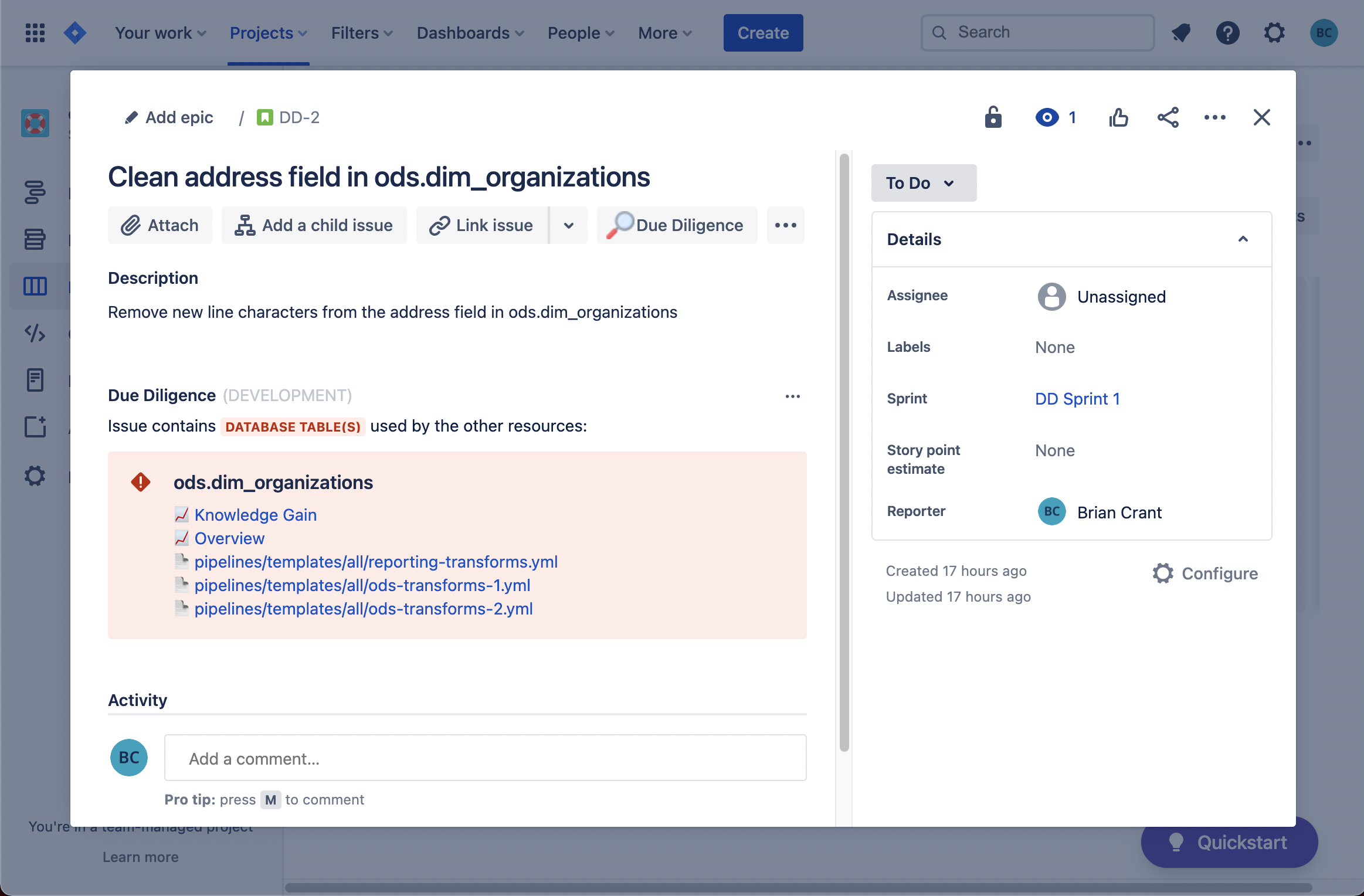
The information displayed by Diligence Doer can be seen directly in a Jira Issue underneath the description...
-
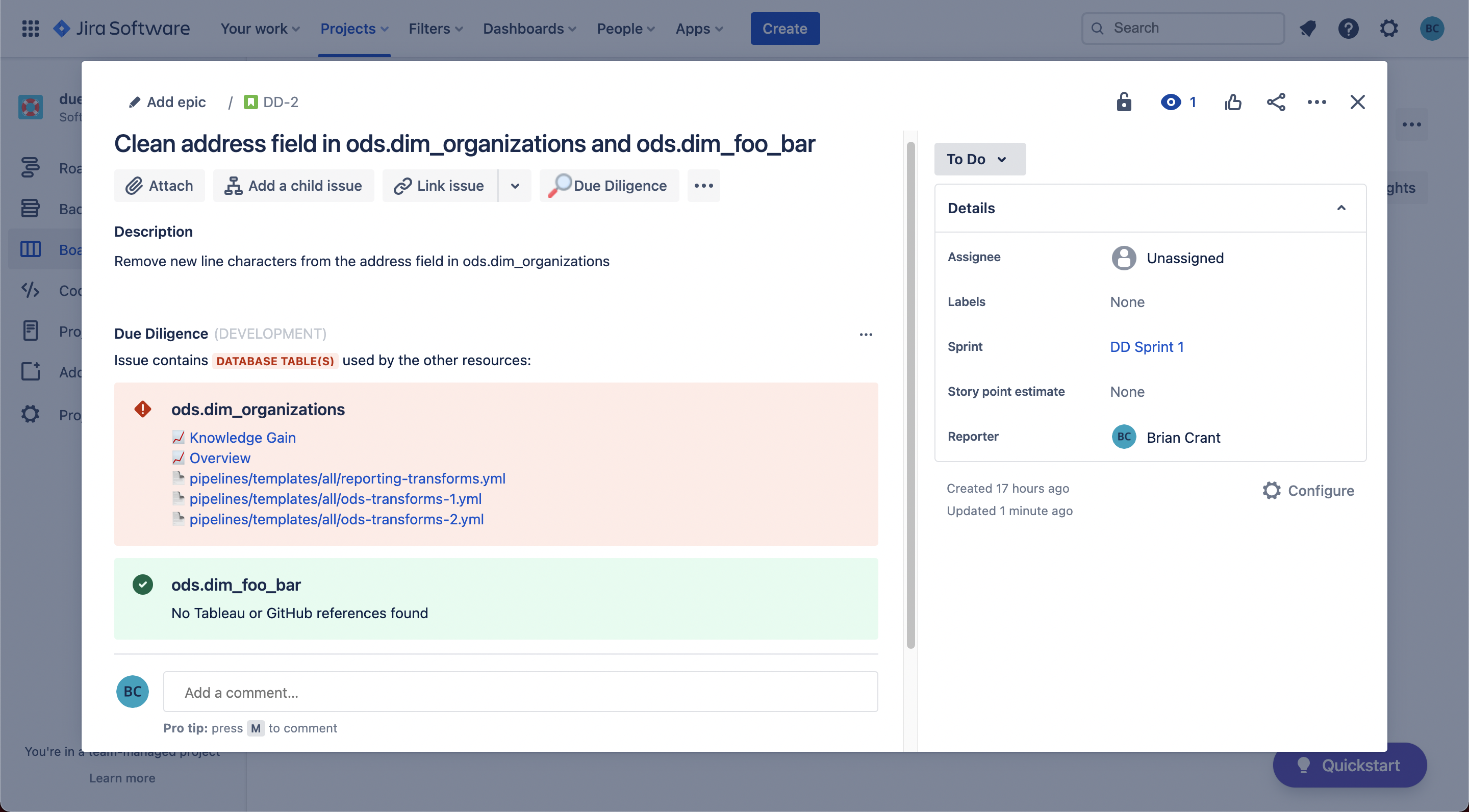
If the database table referenced in the ticket is not referenced in any other resources, Diligence Doer lets you know that, too!

Inspiration
Data is a highly coordinated team sport. Data teams work cross-functionally in an organization, and even within a data team there are many different roles:
Business Analysts, Data Analysts, Data Scientists... Analytics Engineers, Data Engineers, Pipeline Engineers, Data Visualization Engineers... Data Stewards, Data Governance Managers... Data Product Managers... The list goes on...
All of which must work in perfect harmony for an organization to have a successful data platform.
With so many moving pieces, it is inevitable that at some point the ball will get dropped. A field may be removed from a database table, a dashboard may have its datasource changed, even something as unremarkable as changing a field name can have disastrous impact to the resources that reference that field downstream.
Now, you might be thinking, 'Boo-hoo someones dashboard broke... so what? What's the big deal?'
Consider this real world example...
...in the case of the Mars Climate Orbiter. A NASA space probe, the Mars Climate Orbiter crashed as a result of a data entry error that produced outputs in non-SI units versus SI units, bringing it too close to the planet. Like spacecraft, analytic pipelines can be extremely vulnerable to the most innocent changes at any stage of the process. (Source)
What if every member of a data team had the ability to see where a database table is being referenced before they make a change to it?
This is the question that inspired us to build Diligence Doer.

What it does
Diligence Doer is an Atlassian Forge app for Jira. It works by parsing the summary of a Jira Issue for database tables or columns, then displays the other resources where those database tables or fields are being used.
Currently, those resources can come from two places: Github and Tableau.
Github
- Given a Github Repository and authentication token, Diligence Doer will return the name and link to the file(s) that contain the database table(s) in the summary of the Jira Issue.
- In the app, these files are marked with the :page_facing_up: emoji.
Tableau
- Given a Tableau Server and authentication token, Diligence Doer will return the name and link to the dashboard(s) whose datasources contain the database table(s) or field(s) in the summary of the Jira Issue.
- In the app, these dashboards are marked with the :chart_with_upwards_trend: emoji.
Usage
The information displayed by Diligence Doer can be seen directly in a Jira Issue underneath the description...
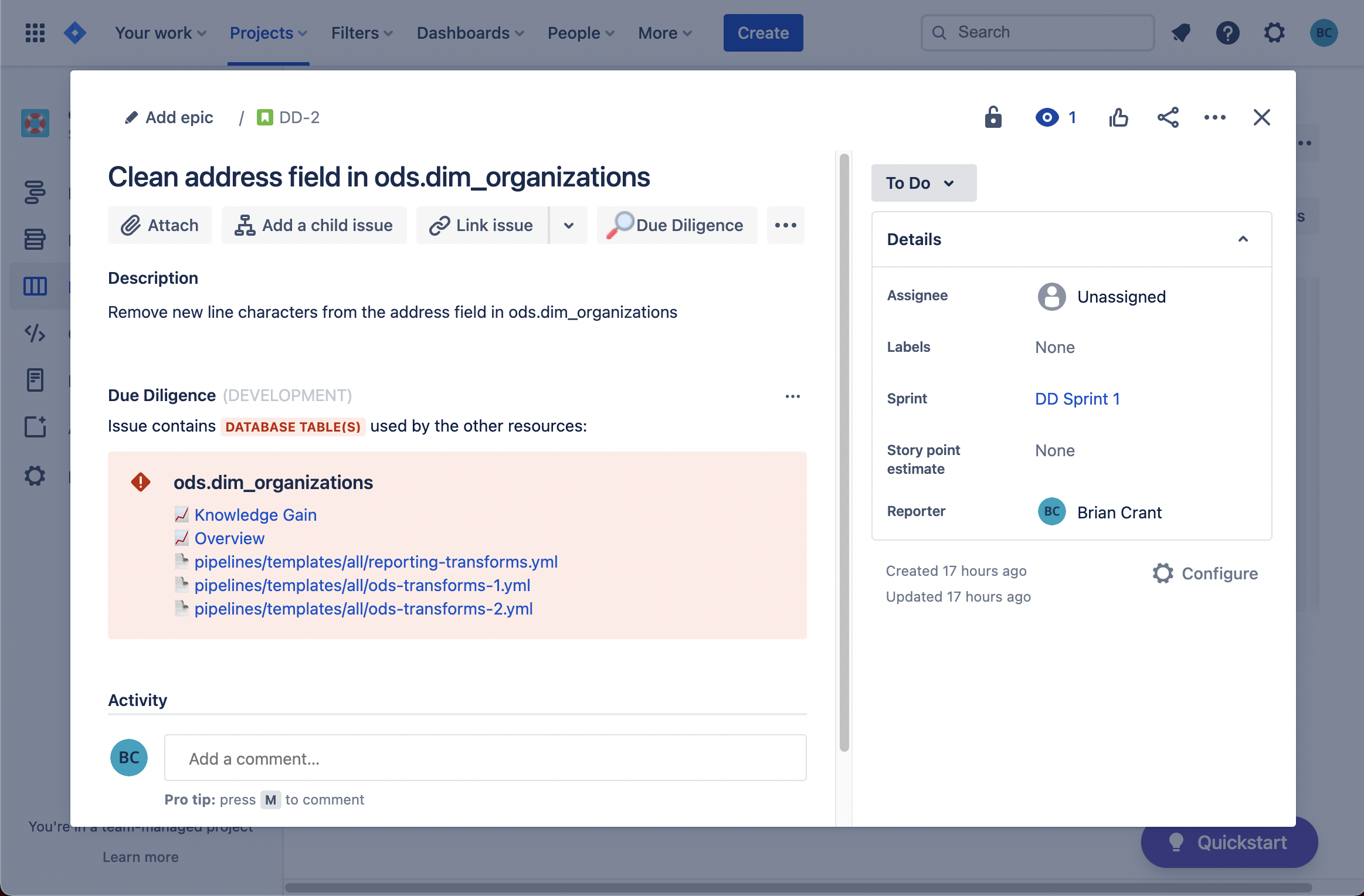
and in other places an Issue may exist, like the Backlog...
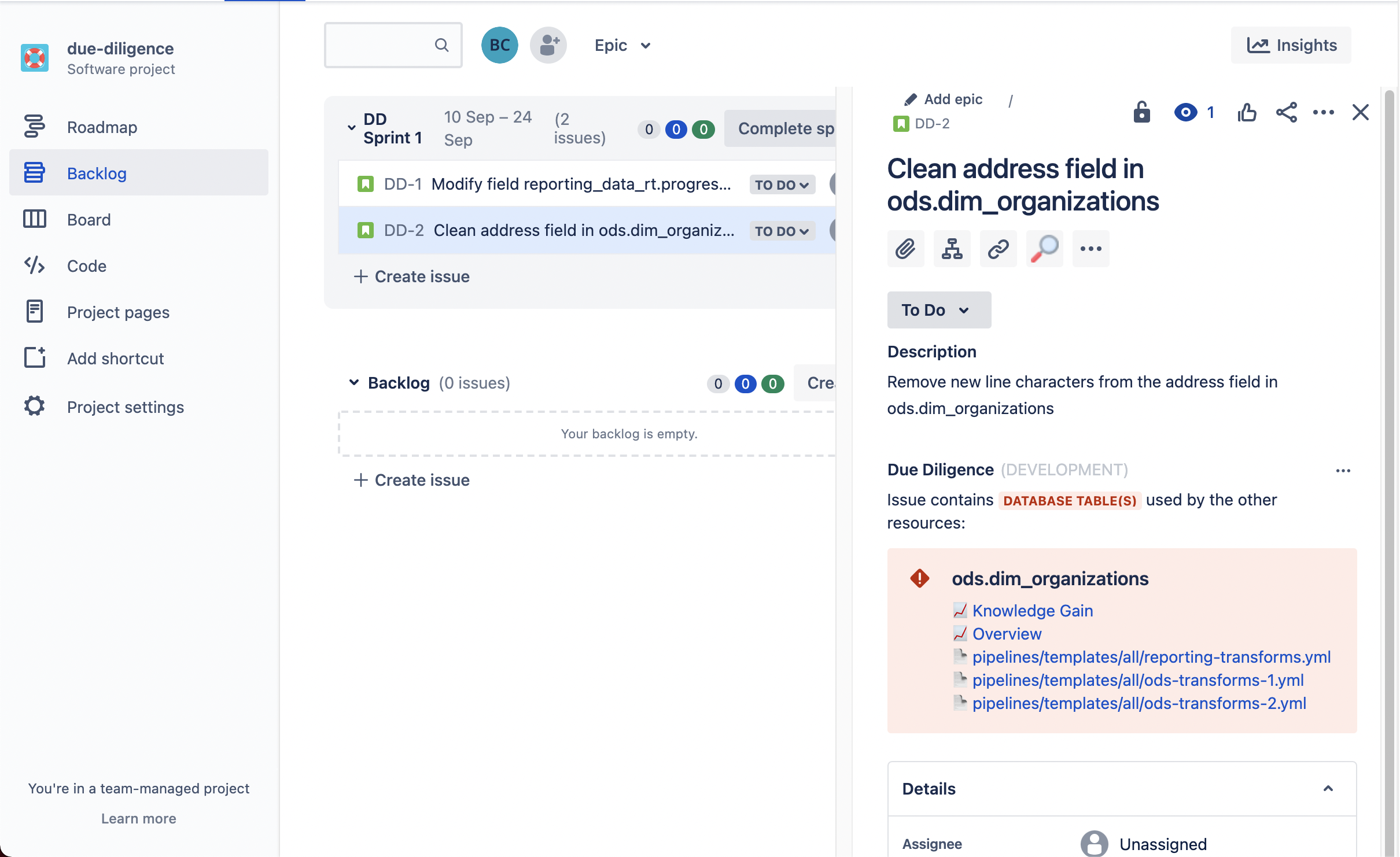
If the database table referenced in the ticket is not referenced in any other resources, Diligence Doer lets you know that, too!
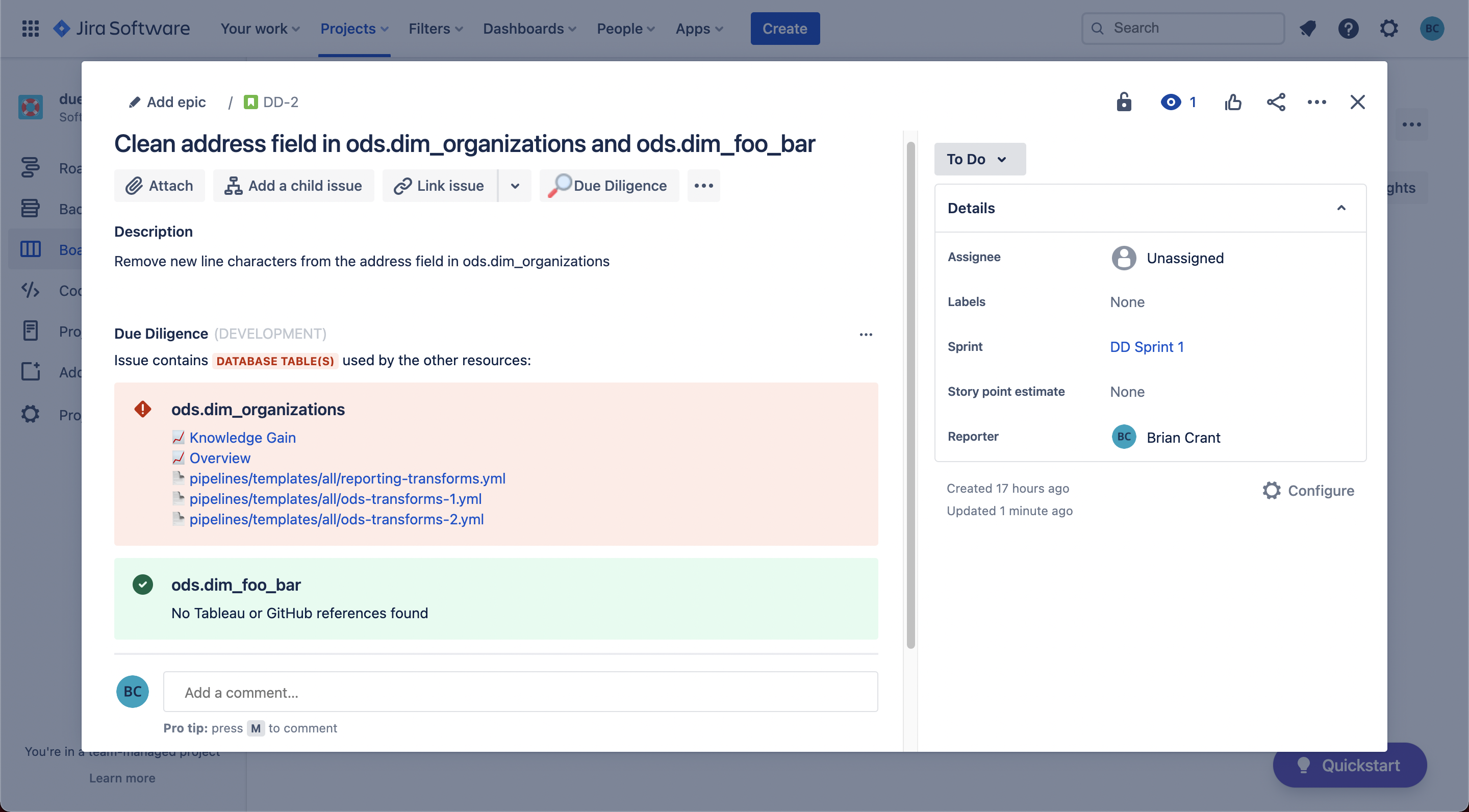
How we built it
The infrastructure is deployed on Amazon Web Services using the Cloud Development Kit. This allows us to quickly provision and manage permissions for all of the cloud components of this project.
Behind the scenes, a daily AWS Lambda batch job parses the database table(s) and field(s) from the resources we currently support, Github and Tableau, and stores the output in an AWS DynamoDB Table.
For Github, an AWS Lambda function queries the Github Repository using the Github REST API and parses all database table and column references from SQL and YAML files.
For Tableau, an AWS Lambda function queries all of the dashboards on the given Tableau Server using the Tableau Metadata API and parses all database table and column references from the datasources of every dashboard.
That was the hard part.
Then we used Atlassian Forge and all of our problems melted into gummy bears and palm trees!
Just kidding! We did however enjoy the CI/CD automation that Forge has to offer and both of us were impressed with how robust the Forge CLI is.
Here is a diagram illustrating the project architecture [link to full size image]:

Challenges we ran into
Once the backend application was functional, when we started to "make it pretty" we initially felt limited in our style choices. For instance, the inability to apply common styles like background or border colors. In another case, we were frustrated by having access to some (via UI Kit components) but not all of the Markdown features that are available in Jira, for example using inline code blocks like this. Only the full line, numbered code blocks are available via the Code component .
After some tinkering and several iterations, we were able to piece together several of the UI Kit Components and create an interface that suits our use case well.
One final note or piece of feedback: it would be nice to have admin collaboration for apps where you could invite another Atlassian Developer account to share admin responsibilities. I forget the specifics, but there were a couple of times where it ended up being easier just to have John log in as me in his Forge CLI.
Accomplishments that we're proud of
We were able to put out a product that solves a real problem that data teams everywhere struggle with. The idea did not fall out of thin air, this is something I personally have struggled with and experienced -- to the extent that I decided to spend the last three weekends and weeknights building a solution! Now, my team, and countless others just like it, will be able to immediately gain value from Diligence Doer thanks to the wonders of infrastructure as code (AWS CDK) and automated deployments (Atlassian Forge). -Brian
What we learned
The biggest takeaway for me is the ease of integrating with the Atlassian product suite using the Forge app development platform. I was pleasantly surprised with how you could seamlessly inject custom apps into their products. -John
What's next for Diligence Doer
- [ ] Add support for parsing Spark SQL and DataFrames
- [ ] Add support for other code repository hosts (BitBucket, Gitlab) and BI Tools (Looker, Power BI)
- [ ] Add support for matching individual fields
- [x] Ingest and parse fields from Github and Tableau
- [ ] Determine best way to shape the data for this use case
- [ ] Determine best way to identify a field name separate from database table in a Jira Issue Summary
- For instance, consider the issue summary:
"Combine address1 and address2 fields in ods.customers" - If we add databases as a source (Snowflake, Redshift, BigQuery), we could then check each word in the summary against the actual schema for the database table:
"ods.customers.Combine" "ods.customers.address1" "ods.customers.and" "ods.customers.address2" "ods.customers.fields" "ods.customers.in"
Built With
- amazon-dynamodb
- amazon-lambda
- amazon-web-services
- github
- github-rest-api
- javascript
- python
- tableau
- tableau-metadata-api
- typescript










Log in or sign up for Devpost to join the conversation.