Inspiration
DigitalGradient-AI was inspired by the need for a single system that could do more than answer questions: it needed to understand a document corpus, retrieve relevant knowledge, route requests to the right specialist behavior, and generate grounded responses. The attached document shows a design that combines a fine-tuned transformer backbone, semantic search, vector indexing, re-ranking, and a multi-agent customer support layer, mirroring a full-stack AI platform rather than a single model workflow. A second source of inspiration was practical deployment. The pipeline was clearly designed around memory-aware operation, Hugging Face loading without local model downloads, LoRA-based fine-tuning, and fallback strategies for retrieval and generation when resources are constrained.
What it does
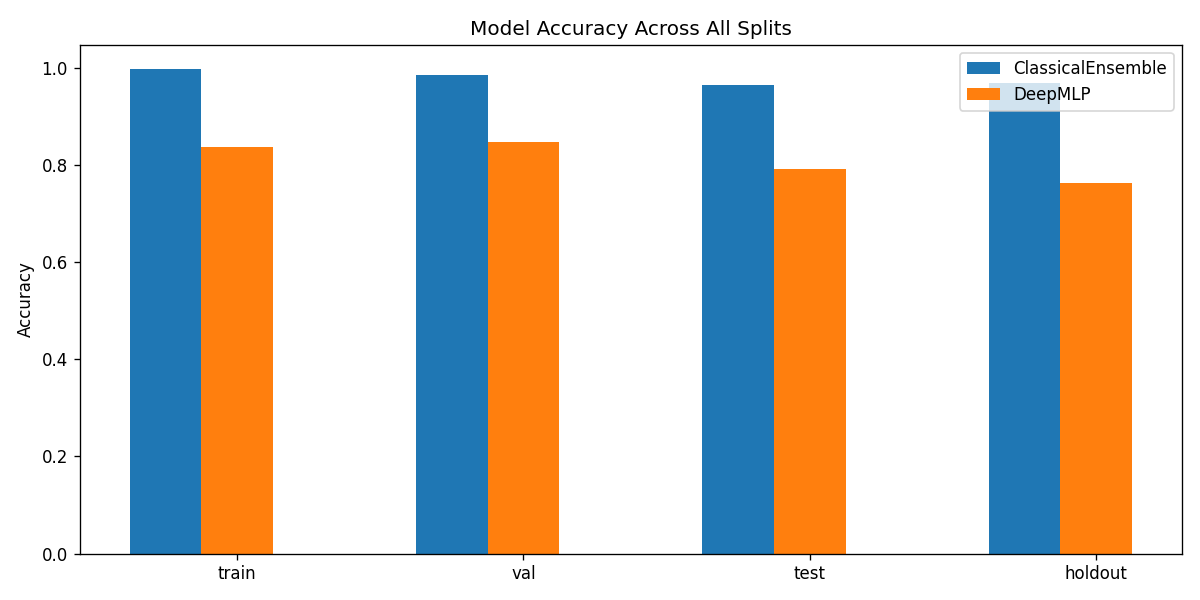
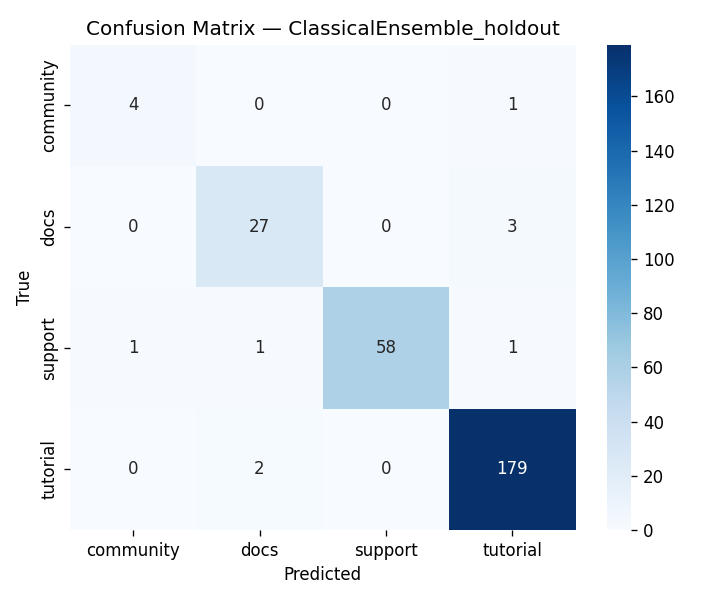
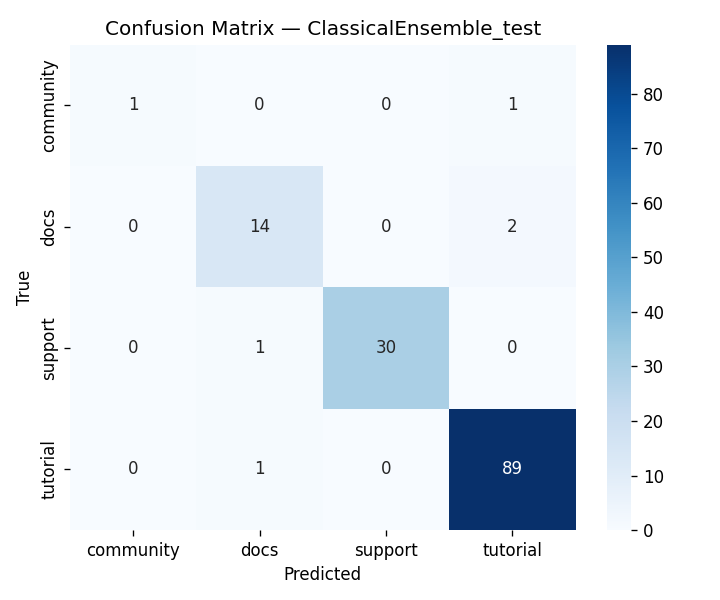
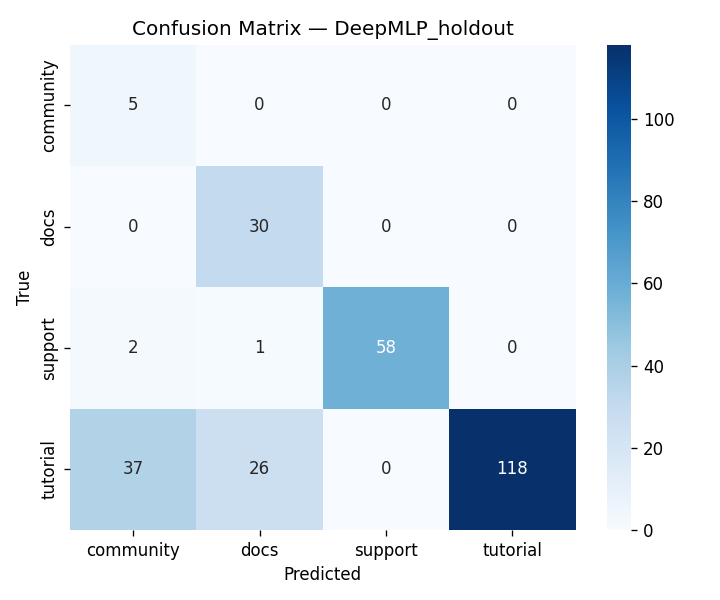
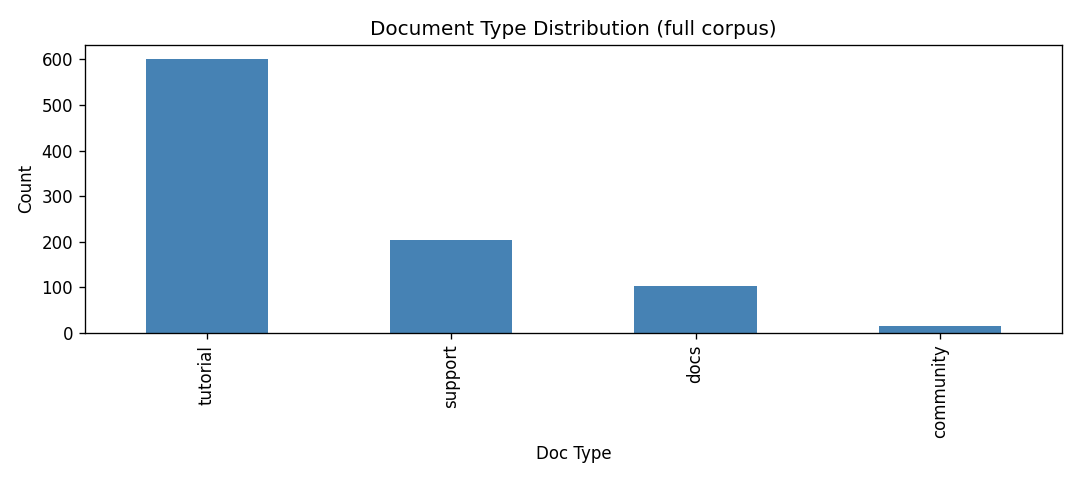
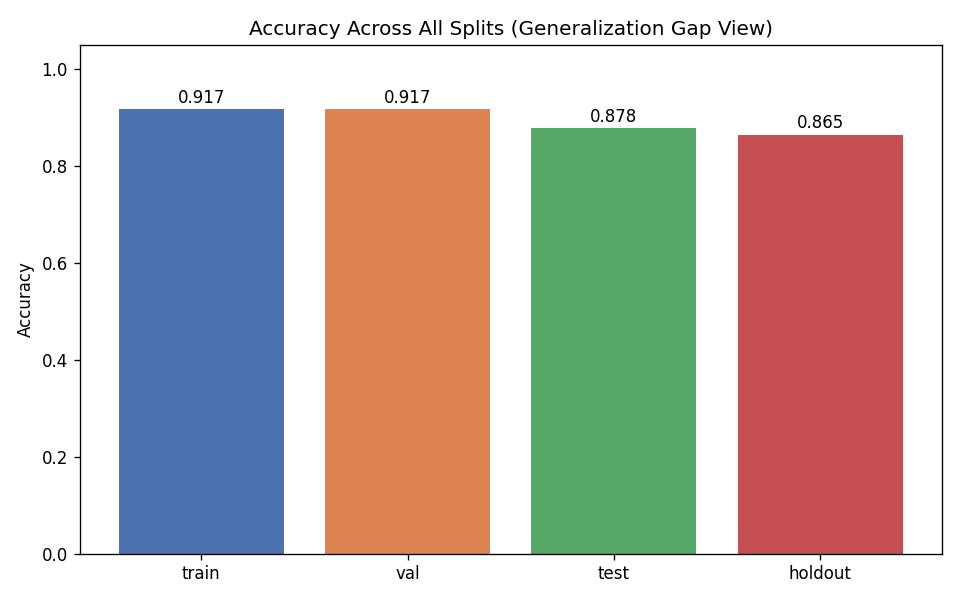
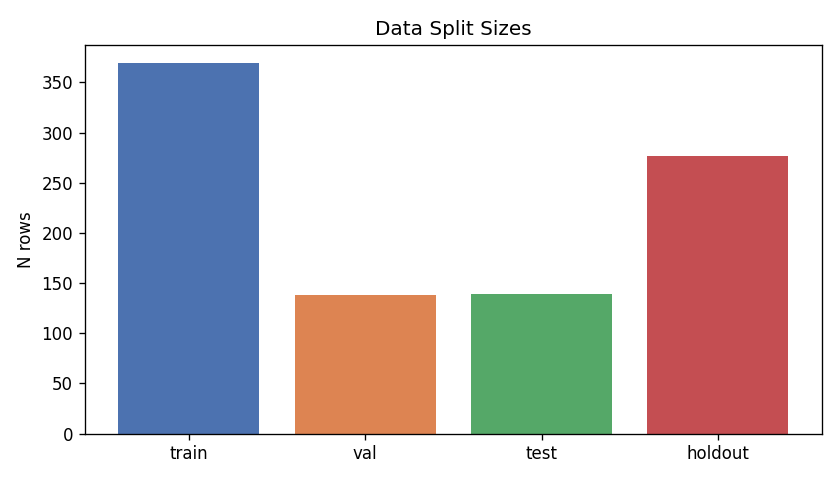
DigitalGradient-AI turns a document collection into an end-to-end intelligent system. It begins by crawling and parsing HTML documents, cleaning them, and labeling document types for downstream learning tasks. It then performs stratified splitting into train, validation, test, and holdout sets using a 40/15/15/30 structure, which supports disciplined evaluation and leakage control. The system builds two major model families. First, it trains classical machine learning models and a PyTorch MLP classifier on engineered features derived from TF-IDF, SVD, and handcrafted metadata features. Second, it loads a large Hugging Face transformer backbone for embeddings and generation, applies LoRA adapters when available, and uses that model to power semantic search and RAG-style responses.
On top of that, it creates a FAISS-backed vector index for nearest-neighbor retrieval and uses a cross-encoder re-ranker to improve the quality of the returned documents. The final layer is a multi-agent customer support system that routes questions into billing, technical, or general handling paths, applies PII guardrails, and escalates unresolved cases through a ticketing mechanism.
How we built it
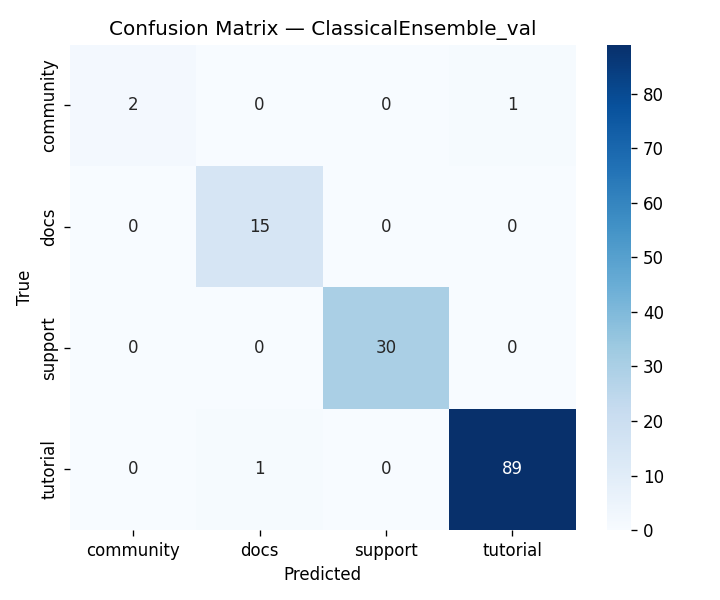
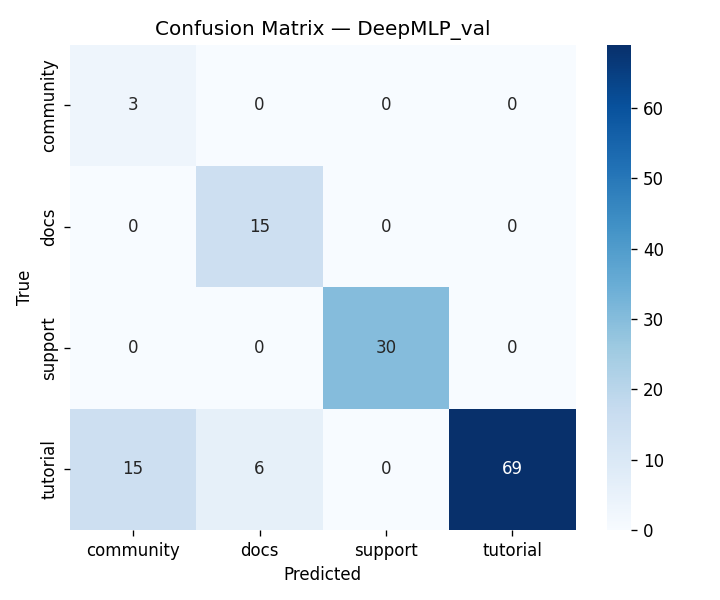
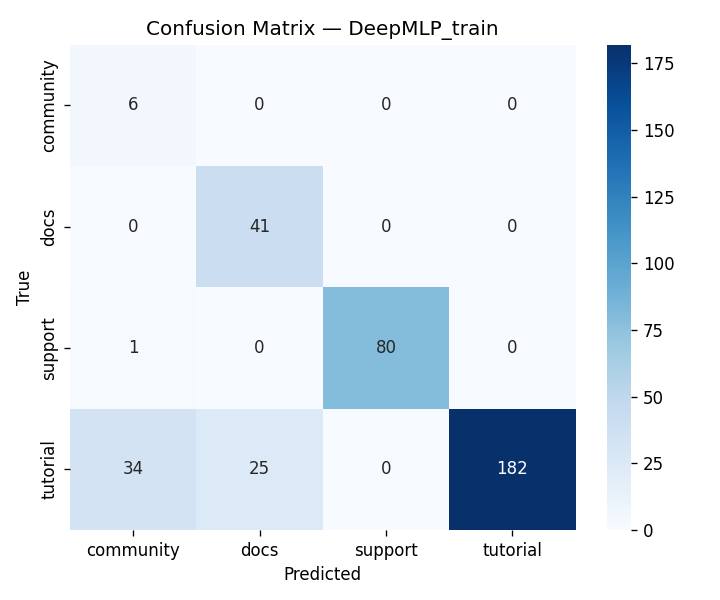
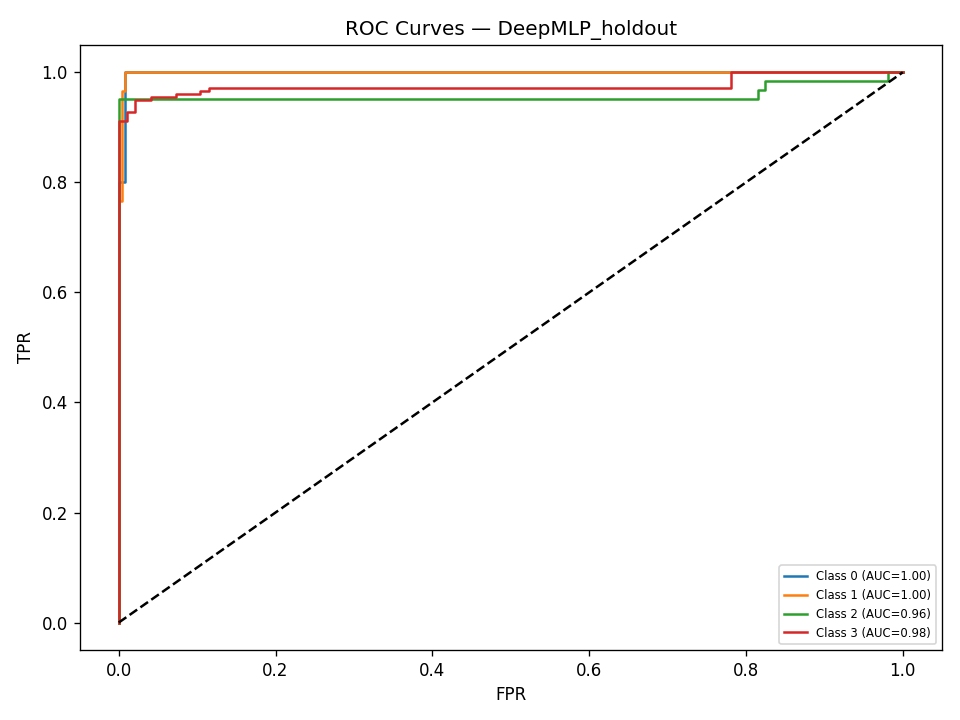
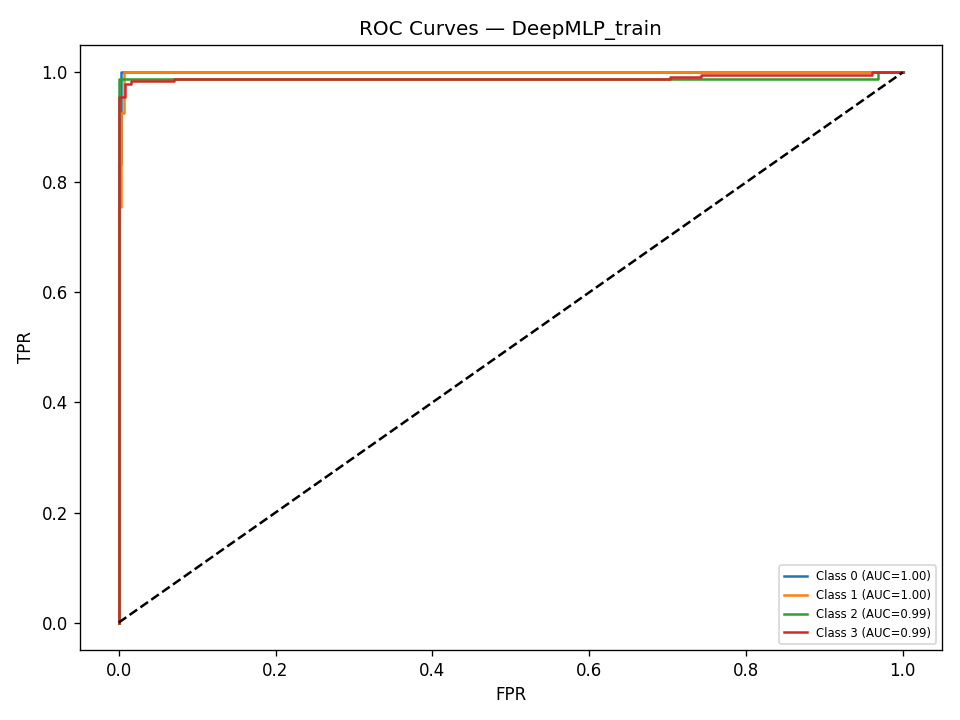
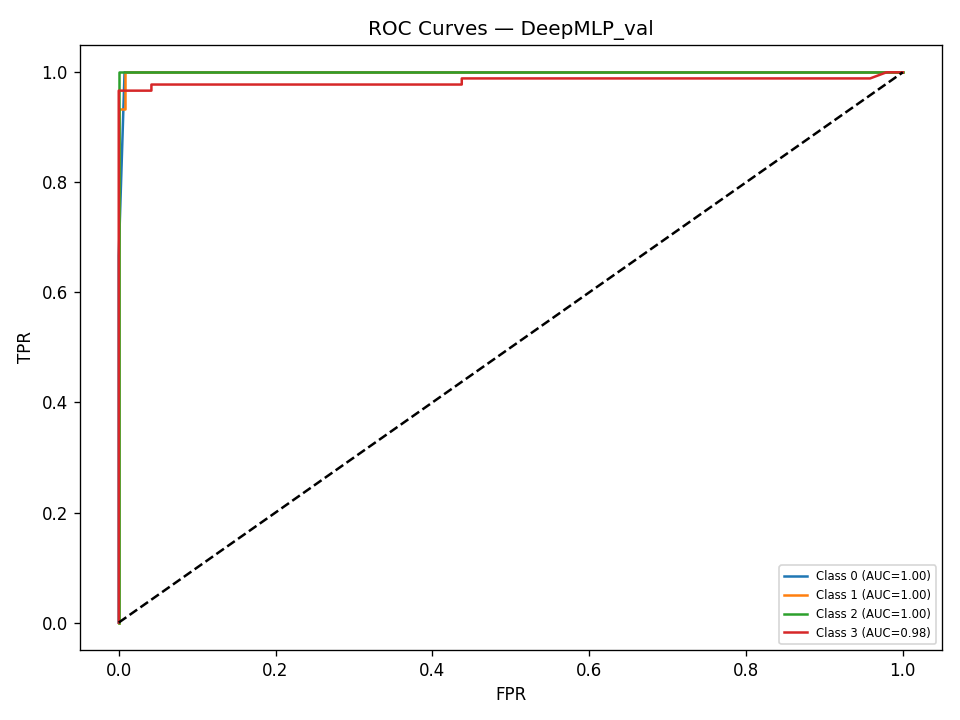
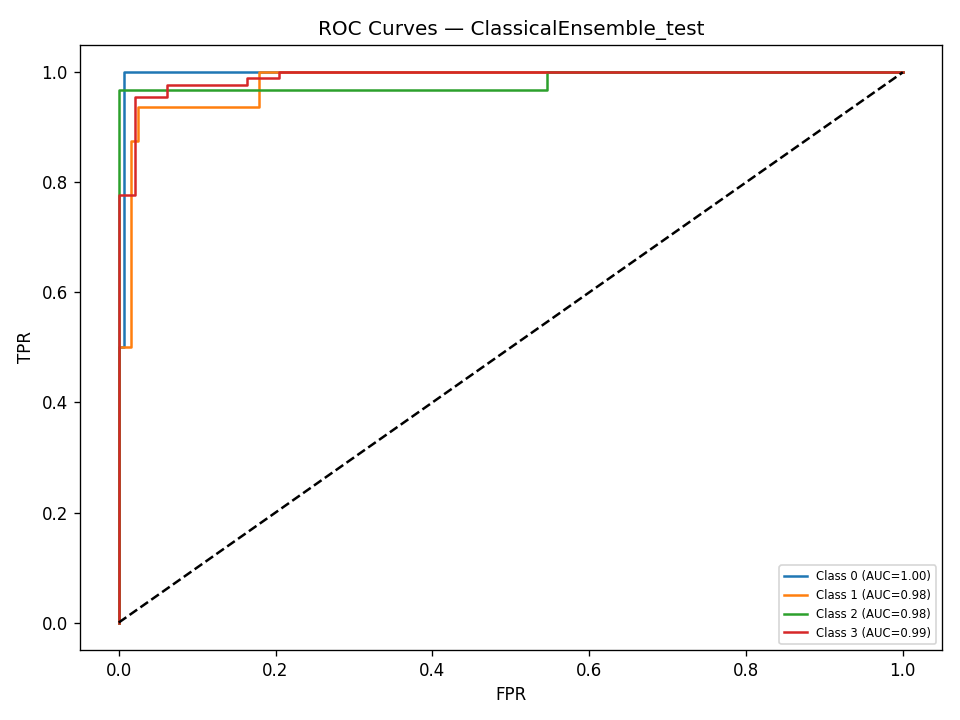
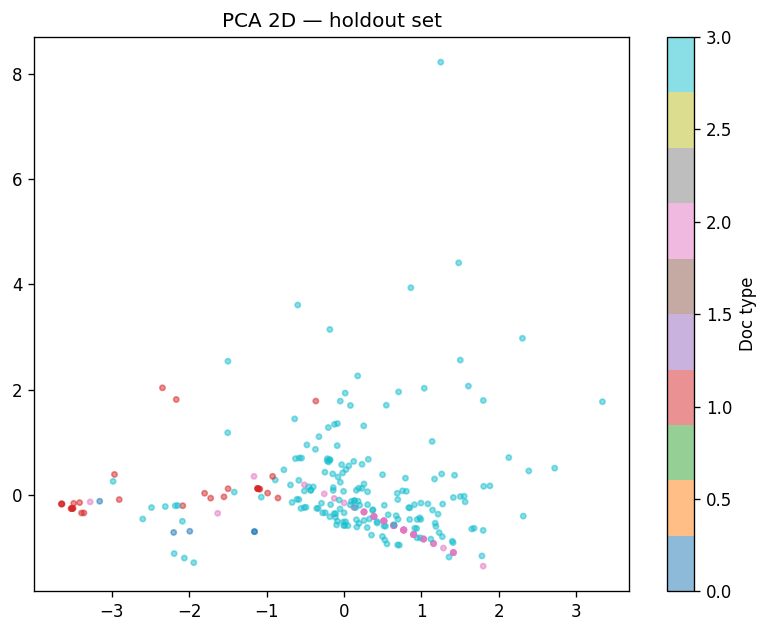
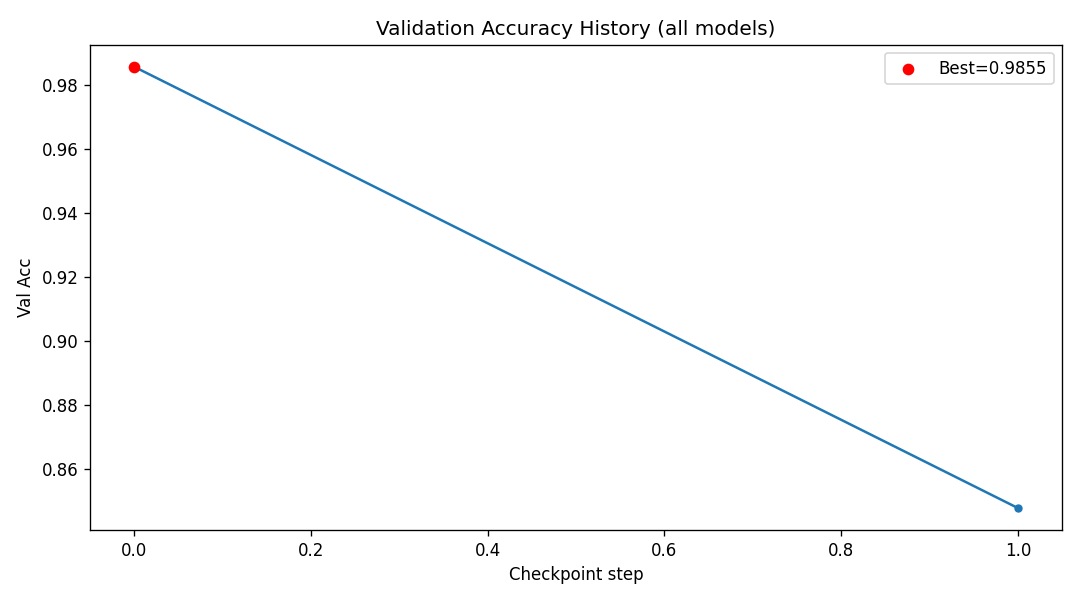
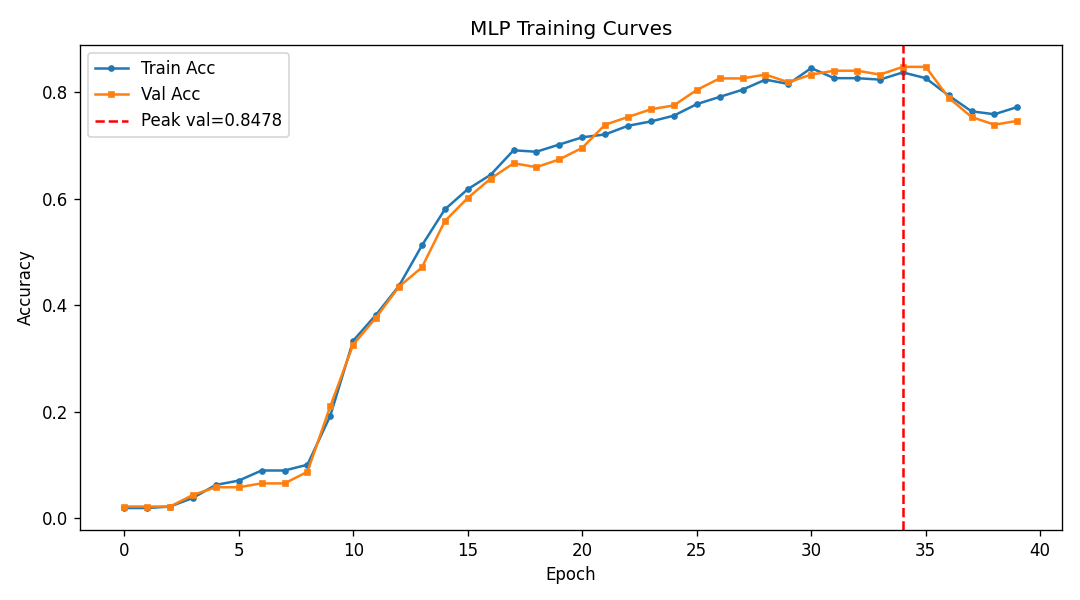
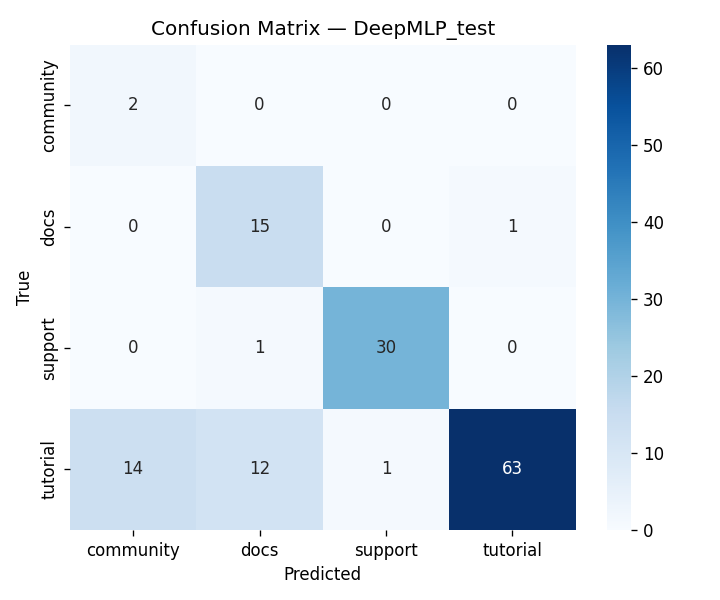
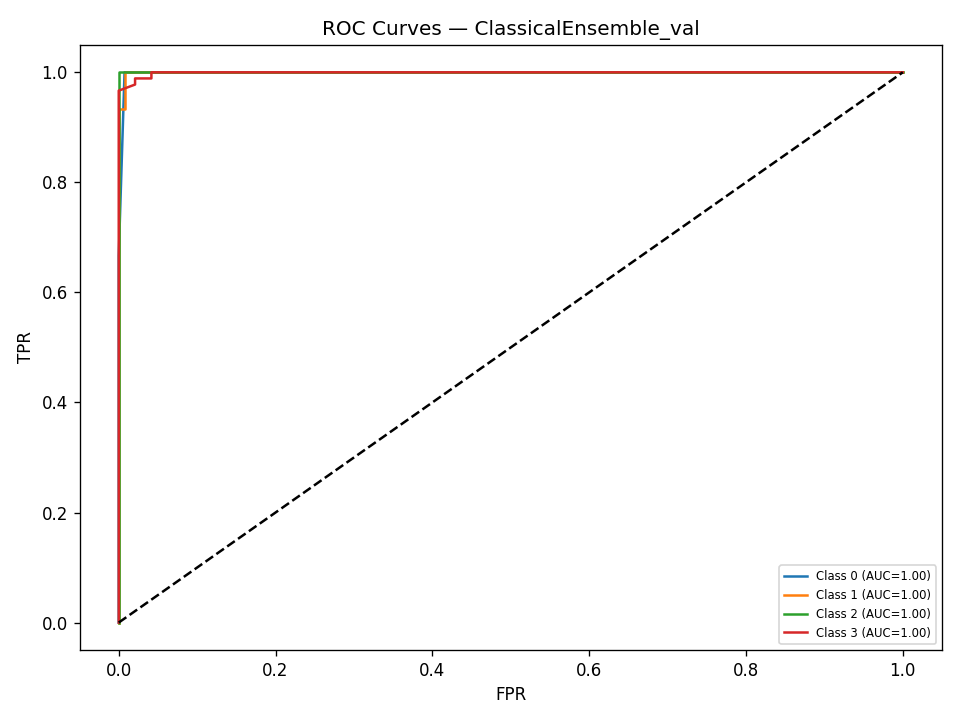
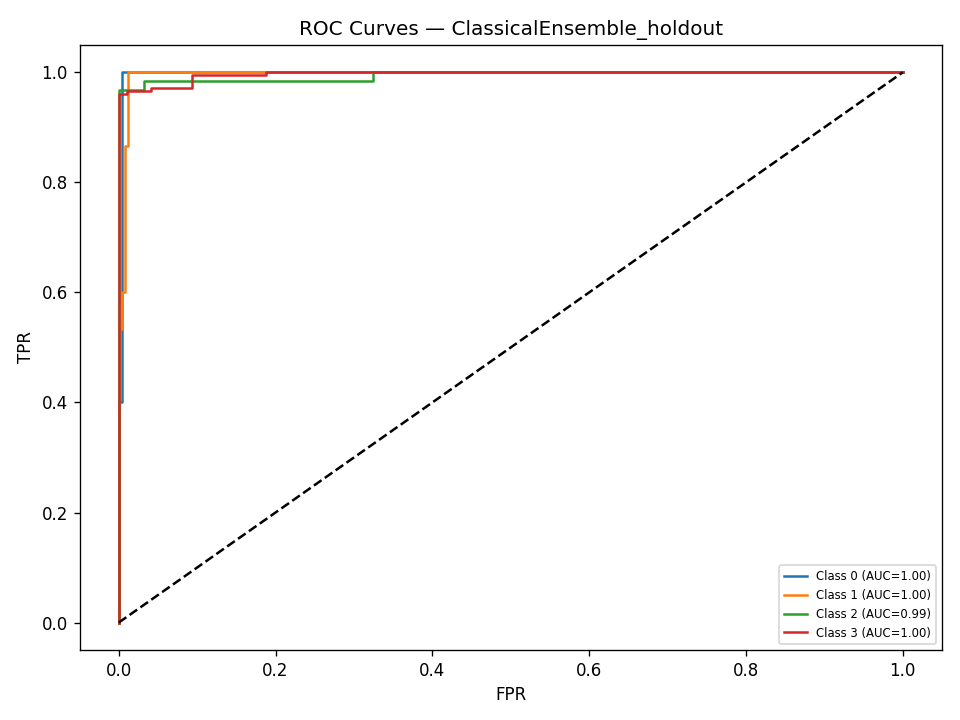
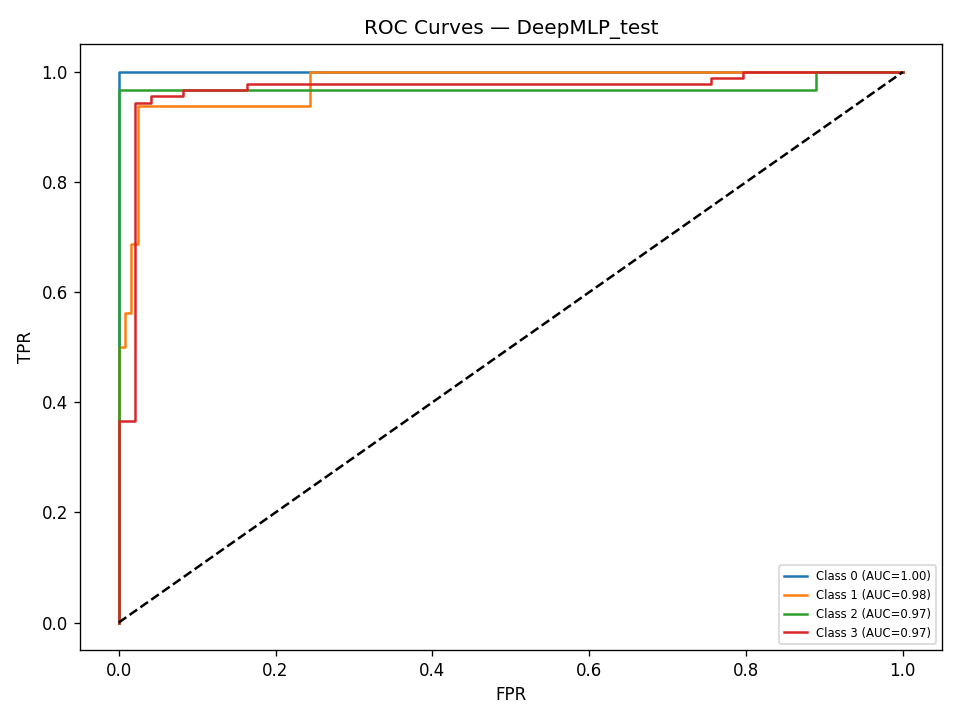
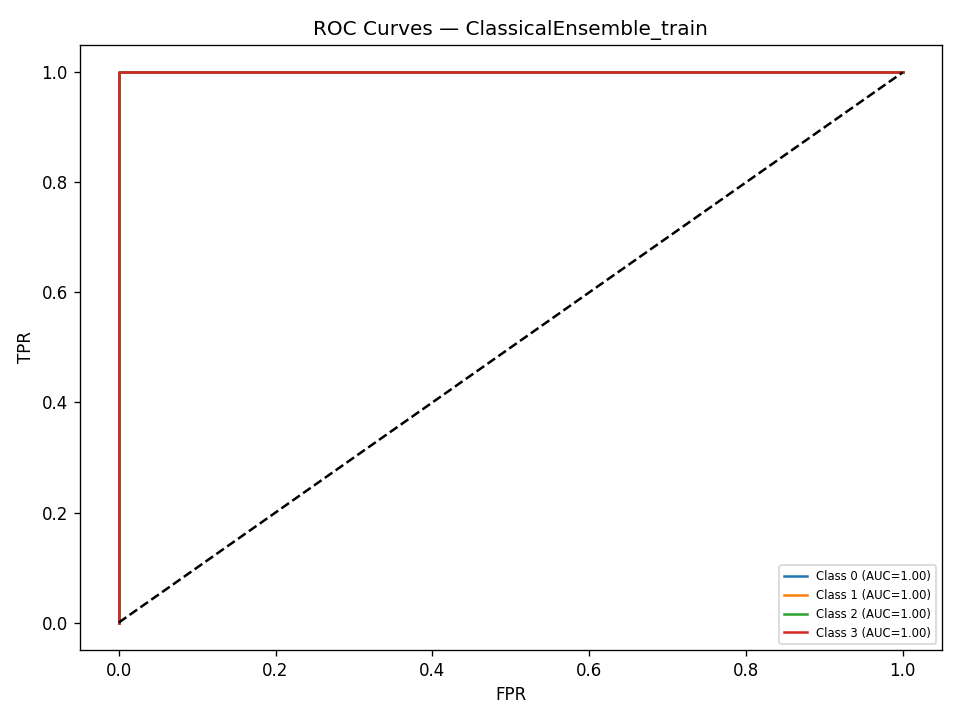
We built DigitalGradient-AI as a modular pipeline with clearly separated stages. The document shows sections for utility functions, HTML crawling, preprocessing, splitting, feature engineering, EDA, classical ensemble training, deep learning, embedding model loading, vector indexing, re-ranking, semantic search, knowledge base retrieval, customer support orchestration, evaluation, and checkpointing . For the retrieval side, the pipeline uses transformer-based embeddings, normalizes them, and stores them in FAISS when available; otherwise, it falls back to a numpy cosine-similarity index. For generation, it attempts to load NVIDIA Nemotron as a causal language model with quantization and remote Hugging Face access, then attaches LoRA adapters for parameter-efficient fine-tuning . If that path fails, it falls back to a smaller embedding model so the system still remains functional. For classification, the code combines Gradient Boosting, Random Forest, and Logistic Regression in a soft-voting ensemble, then separately trains a deep MLP with batch normalization, dropout, mixup, class weights, gradient clipping, and early stopping. The pipeline also produces EDA plots, PCA projections, confusion matrices, ROC curves, and model comparison charts to make performance visible and auditable.
Challenges ran into
One major challenge was memory and compute constraints. The document explicitly uses memory guards, cleanup routines, conservative sampling, and fallback loading strategies because the intended transformer backbone is too large to treat casually in constrained environments. The pipeline repeatedly checks memory usage, empties CUDA cache, and limits corpus encoding to a capped number of documents for safety. A second challenge was making the system robust even when ideal dependencies are missing. The code anticipates missing PEFT, missing FAISS, or model-loading failures and switches to alternate implementations rather than stopping execution entirely. A third challenge was coordinating multiple subsystems without losing traceability. The architecture has classification, retrieval, re-ranking, generation, routing, guardrails, ticket creation, and evaluation all living in one ecosystem, so preserving clean data flow and avoiding leakage required explicit split verification and careful orchestration.
Accomplishments that we're proud of
We are most proud of turning a single document corpus into a full AI platform rather than an isolated model. The system does not stop at classification; it supports semantic retrieval, answer generation, domain routing, and escalation workflows in one pipeline. We are also proud of the engineering discipline in the design: early stopping, best-model checkpointing, evaluation on multiple splits, and rich visualization all help ensure the results are not just functional but measurable.
Another achievement is the hybridization strategy. The code combines classical ML, deep learning, dense retrieval, and LLM-based generation in a way that is practical and layered, allowing each subsystem to do what it is best at.
What we learned
We learned that high-quality AI systems are rarely “just a model.” They need data cleaning, feature engineering, retraining logic, evaluation, retrieval infrastructure, fallback behavior, and operational guardrails to be useful in the real world. We also learned that parameter-efficient fine-tuning and remote model loading are essential when dealing with large foundation models under resource limits. The document’s Nemotron + LoRA design makes it clear that modern systems often need to trade full fine-tuning for efficient adaptation. Finally, the project shows the importance of task routing and safety filters in agentic AI. Even a strong retrieval system benefits from routing user intent into specialist prompts and redacting sensitive content before responses are returned.
What’s next for DigitalGradient-AI
The next step is to make the system more scalable, more modular, and more production-ready. A natural extension would be to split the pipeline into deployable services: one for ingestion, one for embeddings and vector search, one for generation, and one for support routing. That would improve maintainability and make the architecture easier to deploy in cloud environments. Another next step is to improve the retrieval stack with stronger rerankers, better chunking strategies, and possibly hybrid sparse+dense retrieval so the semantic search layer becomes even more accurate and robust.
We would also extend the agent layer with stronger policy control, richer escalation logic, and evaluation metrics focused not only on accuracy but on response faithfulness, retrieval precision, and support resolution quality. The current design already has the scaffolding for this through its knowledge base, ticketing, routing, and guardrail components.

Log in or sign up for Devpost to join the conversation.