-
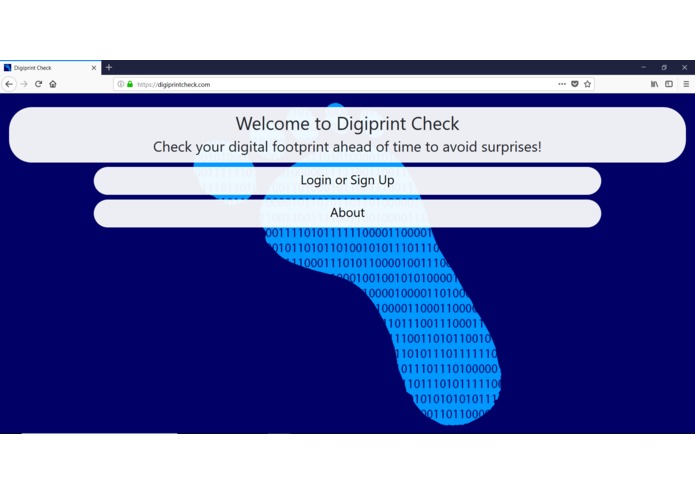
Home Page
-
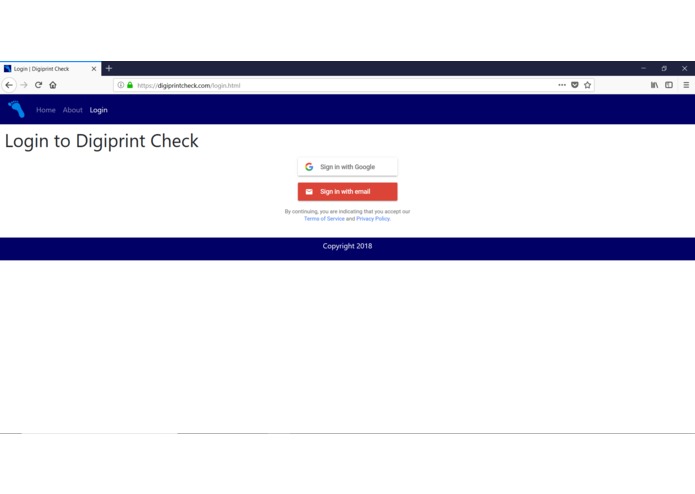
Login Page - Step 1
-
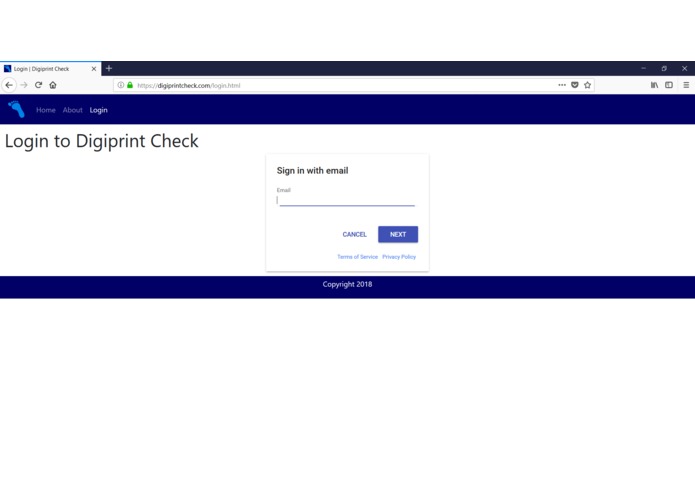
Login Page - Step 2
-
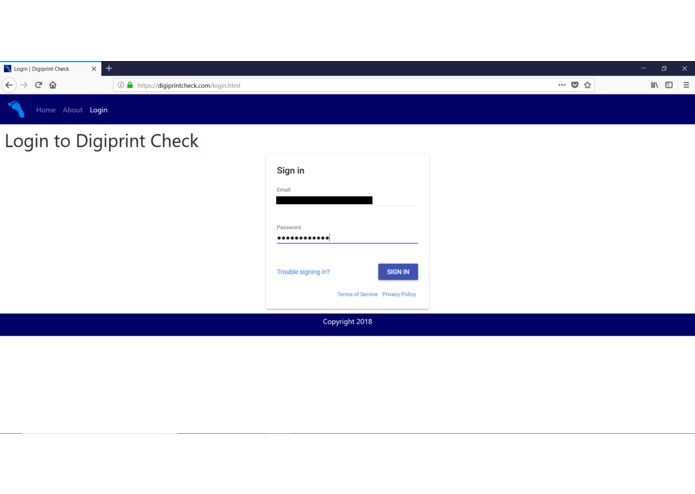
Login Page - Step 3
-
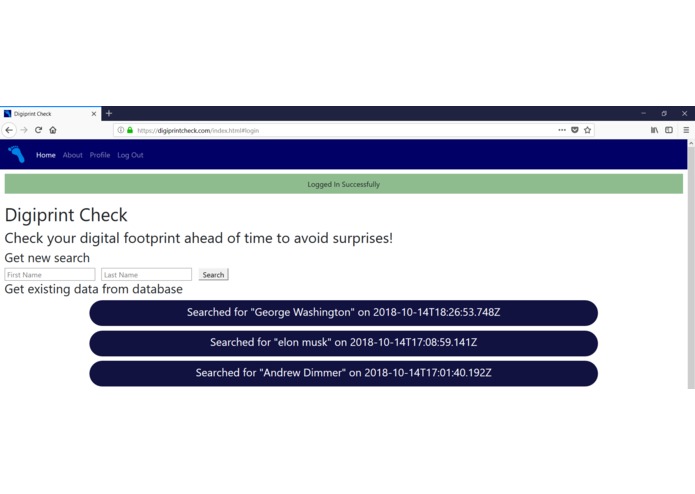
Dashboard Page
-
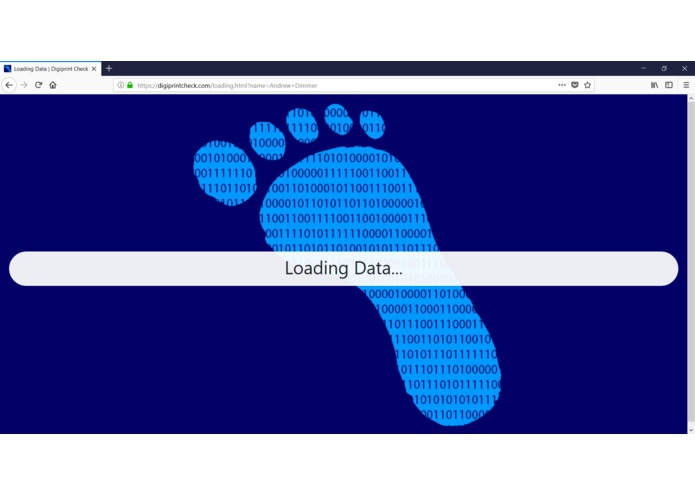
Load New Data from Search
-
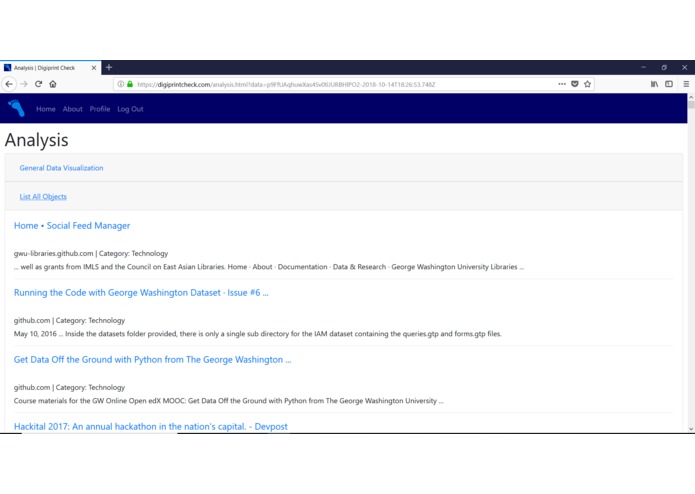
View Analysis Page
-
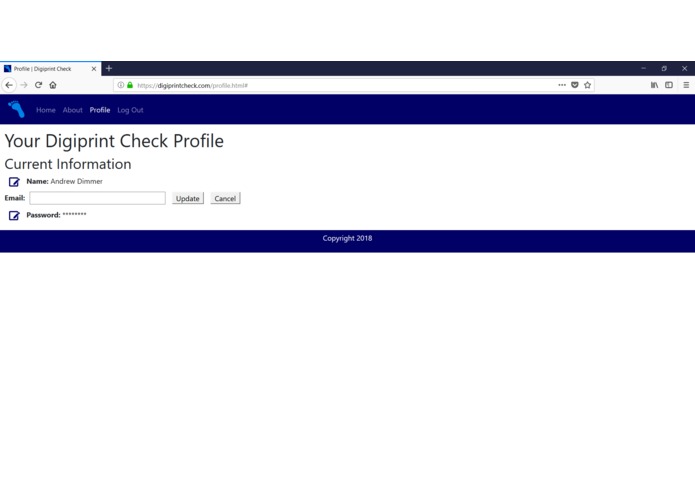
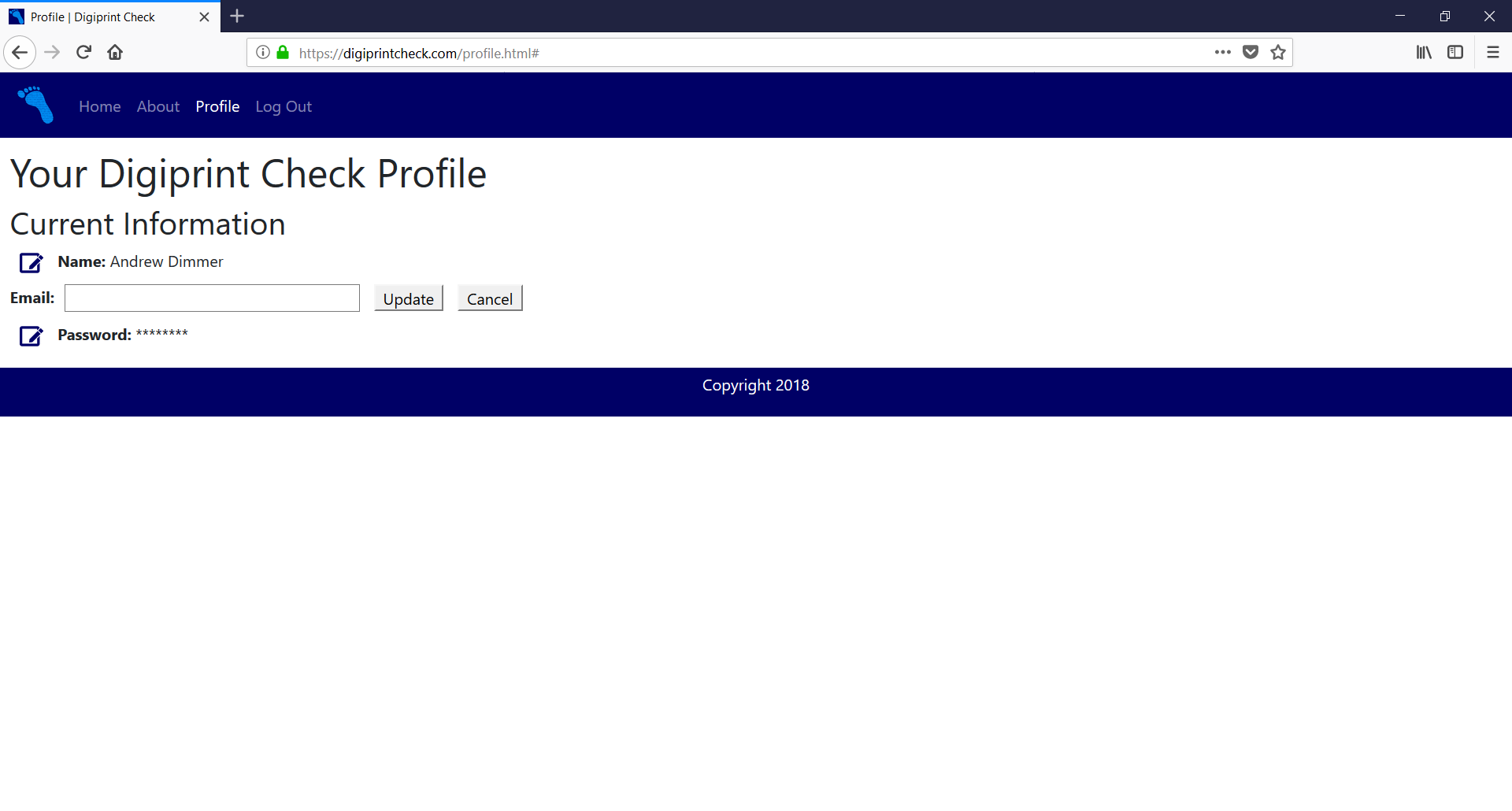
Profile Page - Editing Email
-
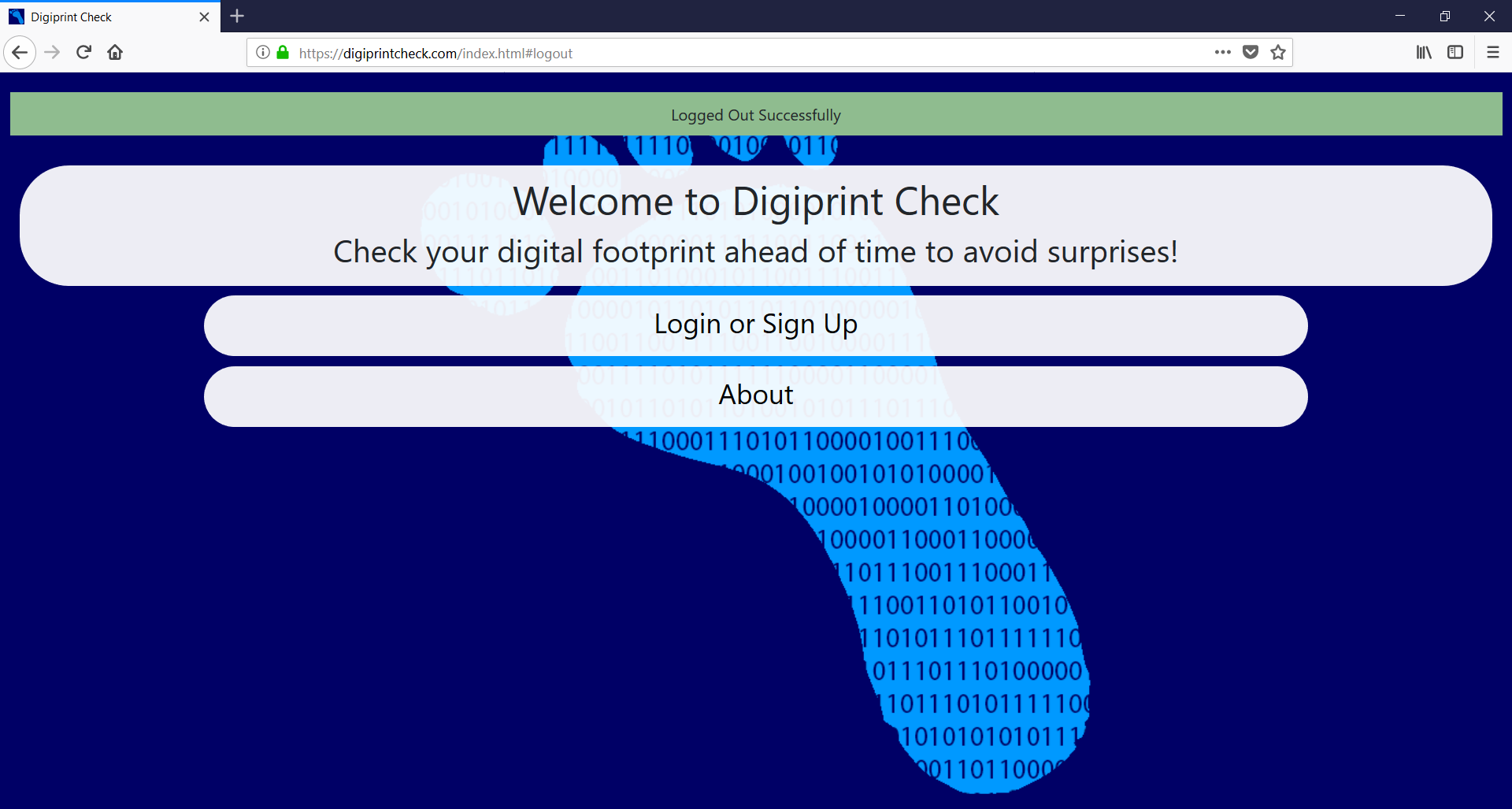
Logged Out
Inspiration
We first came up with the idea for Digiprint Check when we were discussing different methods of data visualization from a live source, and stumbled across the Twitter API. As we were looking at it for potential project ideas, we all found old tweets that we had forgotten we had made. It occurred to us that everyone has a digital footprint (which we have since called a digiprint), and even if we have forgotten about it, potential employees will find it if they run a quick background check. Thus, we decided to make a website that would allow users to start checking their own digital foot to analyze it and hopefully clean it up before applying for jobs.
What it does
There are a few major parts of the project. Primarily, the website allows the user to call a number of Google Custom Search Engines with the intent of finding different parts of his/her digiprint. These results are then brought into two different analysis engines: an RStudio Markdown file that complies visual representations of the various attributes of the digiprint as a whole, as well as an Algolia search engine to find specific components of said digiprint. In addition, because cleaning and maintaining and a positive digital footprint takes both time and monitoring, Digiprint Check allows users to create a profile and track their results over time.
How we built it
Ultimately, we broke this project down into 4 main components: the web design and user authentication, the data retrieval from Google and its subsequent storage in a database, the Algolia analysis of the data, and the RStudio data visualization. None of us initially knew how to do any of these above, and we each took one component to specialize on and integrate with everyone else's component's when completed. We started by conducing individual research in each of our respective areas, being sure to check in with one another so we had a common frame of reference with respect to how we were processing the data. We also built sequentially, focusing each of the 4 components consecutively so that we could minimize ambiguity that naturally came with literally not knowing how each component of the multiple external APIs would talk to each other, and what data would be accessible for export and required for import.
With respect to the construction itself, the website was built in mostly plain HTML and CSS, and augmented with BootStrap to increase mobile responsiveness for things like the menu. From there, JavaScript was employed to connect with the Firebase for authentication and profile management. After JavaScript and JQuery were used to connect with the Custom Search Engine API, and then were used again to store that data in the Firestore database. JavaScript was also used to connect to the Algolia API for searches. However, because creating dynamic visuals like charts is difficult to do in any of the above languages and frameworks, RStudio was used to create the data visualization, and was imported as an RMarkdown file. Finally to make the website accessible to the public, we used a Domain.com domain name and Firebase Hosting.
Challenges we ran into
Aside from none of us having used any of the 3 main APIs we used, we also had a 4th team member who had to leave suddenly after only half of a day, and we needed to re-allocate workload to still get everything done. In addition, we had service outages for Algolia and an expired API key for Firebase, so we had difficulties determining what errors were our code, and what errors came from service interruptions. Not knowing exactly what data we would be able to get for our search results until late in the project was also a challenge, because if forced us to think of multiple contingencies in case we didn't, in fact, get the data we had planned for. The asynchronous nature of JavaScript also threw us for a loop for a little bit; as in the time it took for our APIs to initialize other functions had already called the data that was assumed to be already be initialized, which in turn lead to erratic behavior until we could track down the issue.
Accomplishments that we're proud of
Quite frankly, we're all proud that for the minimal existing experience we had going into this that we accomplished pretty much all that we had set out to do. All of our primary objectives were met and with minimal reworks as other people's components changed, which is impressive in and of itself as none of us knew each other before MHacks.
What we learned
"For data analysis, I decided to write my code in R using R Studio. This was the first time I did statistical analysis, so learning everything from appropriate statistical measures to how to create data visualizations was entirely new for me. Along the way, I learned how to integrate features to control aesthetics in my data visualizations. I also learned about a markdown file, how to write one, and how to convert it to an HTML so anyone can access it." - Arsha Ali
"It's a thrilling experience for me to go into the depths of web development. I worked with Algolia and it is something I heard of after joining the team through discussion. Searching through internet and and getting to play with Google and learning and getting help from the employees was the very exciting part for me. This being my first real Hackathon, I have taken away a lot from my teammates to mentors to the people from the professional world. This experience has given me the energy and the inspiration to continue building myself and keep taking the advantage of such great opportunities." - Amrish Nayak
"I was heavily involved in Firebase and Google Cloud, handling authentication and data collection and storage. This whole thing was one big learning expereince for me, where it seemed like every line of code brought new challenges (asynchronous threads) and triumphs (creating my first functional database). Overall, it was a great experience, and it made me appreciate just how much goes into everything, even if it seems simple at first." - Andrew Dimmer
What's next for DigiprintCheck
Ultimately, we would like to expand both the number of results that we can get from the Google Data, as well as implement additional filters to better identify which results for the user, and which belong to someone else with the same name. We would also like to connect it to additional data sources, social media sites like Facebook, Twitter, Pinterest, and LinkedIn in particular, so we can get a more in-depth analysis of both how the user's digital profile looks on those platforms with respect to reputation, but also for finding personally identifiable information that is publicly available so that users who were not previously aware of the vulnerability could remediate it. Speaking of reputation, we would also like to add a feature to the program that will be able to analysis both text and images to help the user sift through the various components of their digiprint, and prioritize which data is best for their reputation to keep highlighting and sharing, and which to focus on remediating first.




Log in or sign up for Devpost to join the conversation.