-
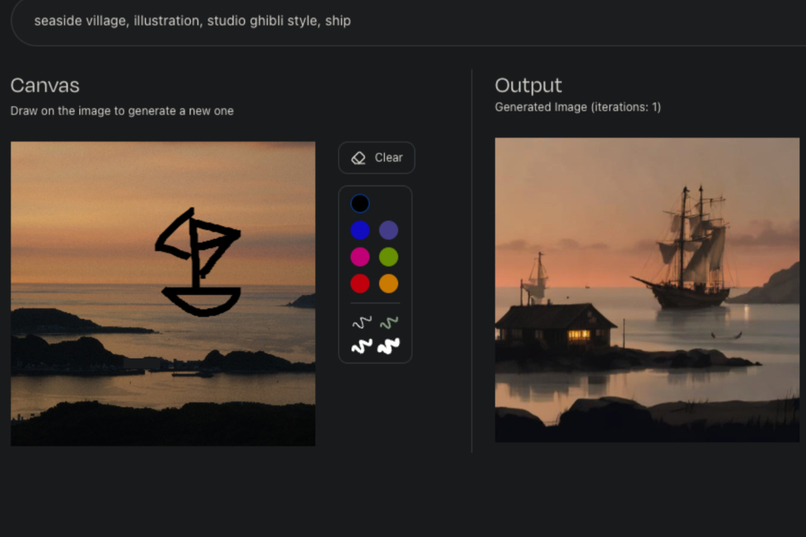
Demo
Inspiration
I sometimes have creative ideas, but I can't draw. In particular, prompting LLMs for images is tedious and extremely iterative (since images are not exactly how you want them)
What it does
This project allows you to draw on top of an existing image, and your own vision into a full, high quality image exactly how you want it.
How we built it
The backend is built using FastAPI and a SDXL Turbo diffusion model, powered by Modal GPU containers. We also incorporate image generation using Gemini's Nano Banana model. The frontend is built using Svelte, Typescript, and CSS.
Challenges we ran into
I ran into the challenge of how to use diffusion models from hugging face, as well as using Modal's API to spin up the containers.
Accomplishments that we're proud of
I'm proud of the whole project, I think that it is almost a complete product in and of itself. In particular, it is both useful and super fun to play around with.
What's next for Diffusion Art
Better support for drawing, including better drawing tools, ability to seperate parts of the image to keep and to iterate on. Also, a user gallery and the ability to save and share your art would be super cool!
Built With
- fastapi
- modal
- python
- sdxl
- svelte
- typescript


Log in or sign up for Devpost to join the conversation.