-
-
Simulation Replay of Direct Address Loading for Convolution Operations
-
Inspiration and What it does
Stable diffusion on GPUs can be slow because a lot of time gets wasted moving data around before the actual compute even starts. My project is based on the paper SD-Acc: Accelerating Stable Diffusion through Phase-aware Sampling and Hardware Co-Optimizations, which proposes a cleaner hardware approach for this bottleneck.
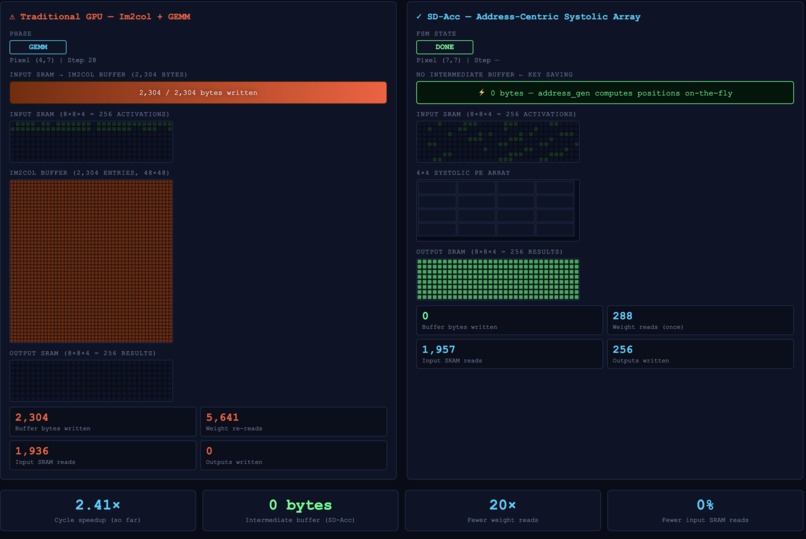
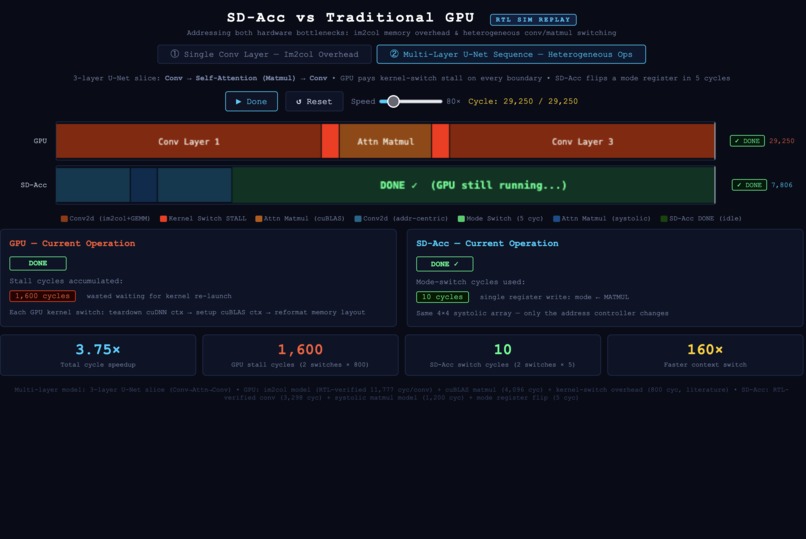
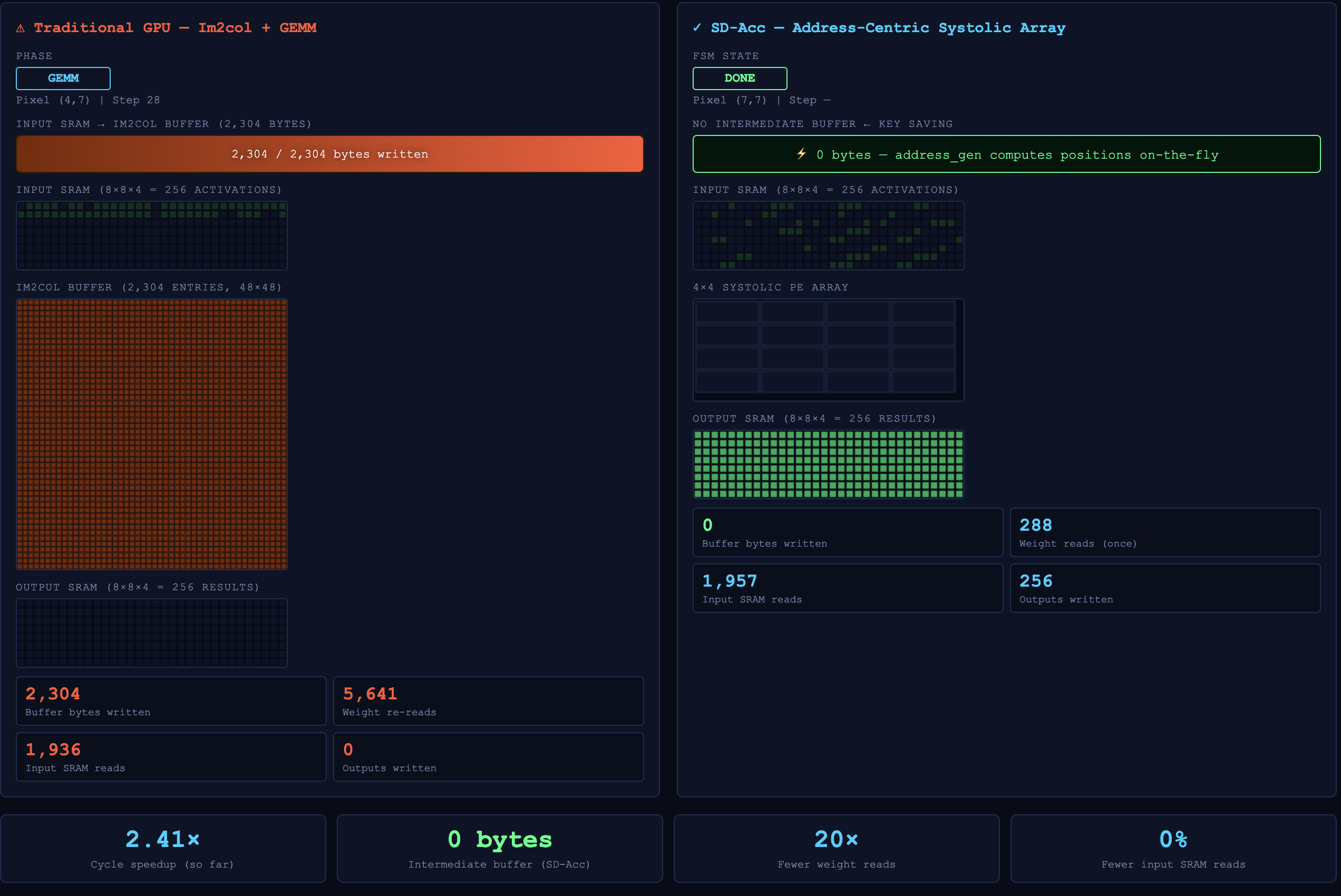
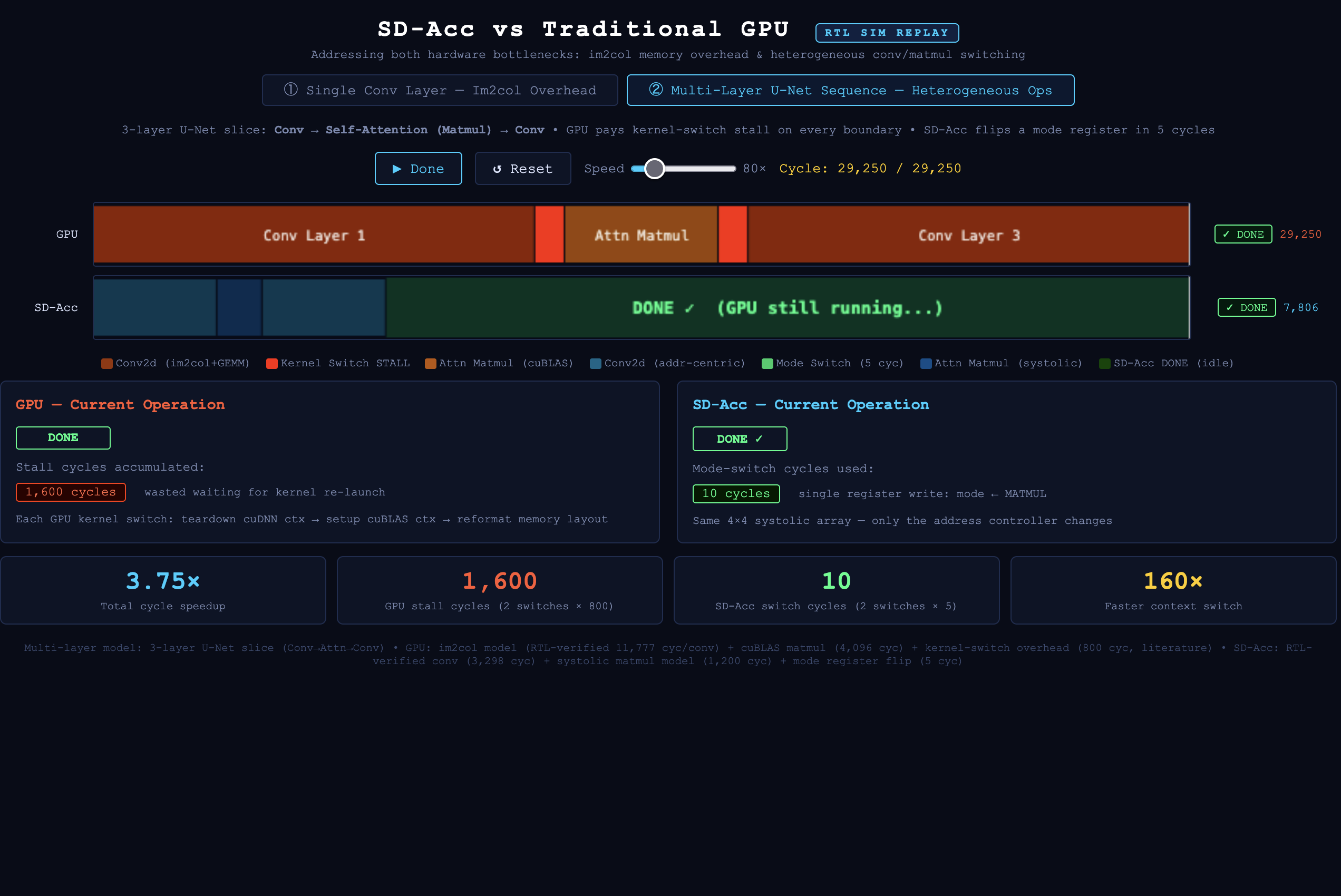
I built a RTL prototype of that idea: instead of filling a huge im2col buffer for convolution, I generate SRAM addresses on the fly and feed the data straight into a shared systolic array. The goal is less buffer copying, less switching overhead between conv and attention layers, and way fewer wasted cycles.
How I built it
I wrote the whole thing in SystemVerilog from scratch. The core is a 4x4 INT8 systolic array, plus an address-centric datapath that decides which SRAM locations to read depending on whether its running convolution or matrix multiplication.
For conv layers, the address generator replaces the im2col buffer by calculating the sliding-window reads directly. For matmul/attention layers, the same systolic array is reused with a different control path. So the hardware doesnt need seperate compute blocks for each layer type.
I verified the design with Verilator and compared all 256 output values against a golden model. Then I built a visualizer that replays the simulation trace cycle by cycle, so the speedup comes from the actual RTL behavior, not just a estimate.
Challenges I ran into
The systolic array timing was annoying. I had a off-by-one bug in the drain phase that made the outputs look almost right, but not fully correct. Comparing every output against the golden model was what finally caught it.
Cognichip also helped a lot with debugging from the testbench results. When the waveform was hard to read, it helped me narrow down where the RTL behavior stopped matching the expected output, which made the debugging way faster.
Accomplishments that I'm proud of
The RTL actually works. I got 256/256 outputs correct against the C++ model, verified through Verilator.
What's next for Diffusion Accelerator
Right now the prototype runs on a 8x8 feature map, which proves the idea but is still small. The next step is adding tiling so bigger Stable Diffusion layers can fit through the SRAM and systolic array.
I also want to scale the array to 16x16 or 32x32 and implement the phase-aware sampling part from SD-Acc, where redundant diffusion steps can be skipped. That would stack with the hardware speedup.
Built With
- cognichip
- python
- systemverilog



Log in or sign up for Devpost to join the conversation.