-
-

A world cloud creating using buzzwords for MLH hackathons
-
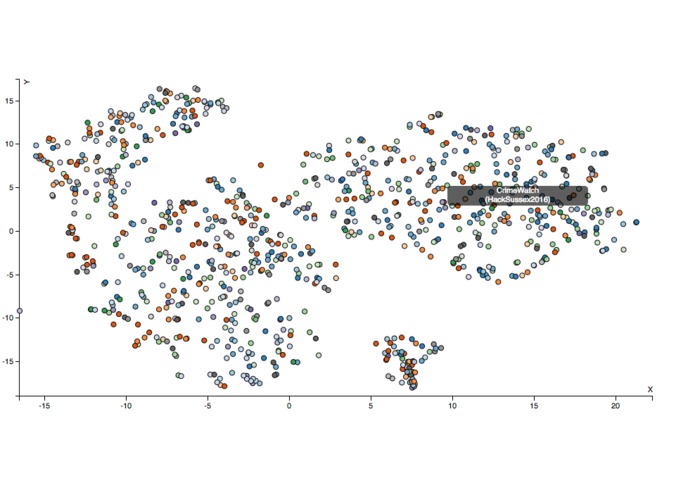
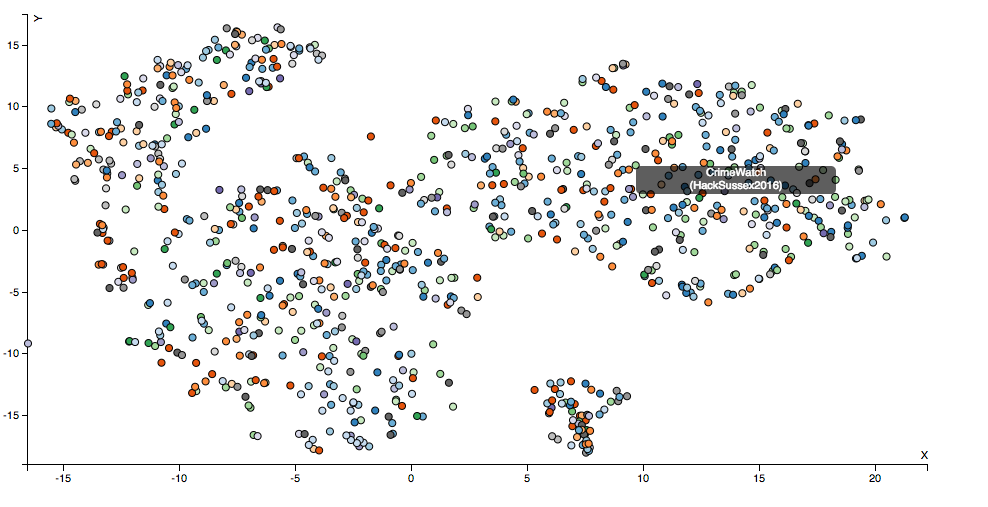
The plot after applying t-sne to our text vectors

Inspiration
After seeing people at hackathons submit the same projects repeatedly, we were a little annoyed with the fact that no one seem to know that the cool sounding project they saw at the last hackathon was also done at the hackathon before that, and the one before that. Moreover, the idea of using advanced natural language techniques to analyse a huge source of data quite excited us. Ultimately, we were able to make a data driven argument which proves our hypothesis of quite similar hackathon projects, some often plagiarised.
What it does
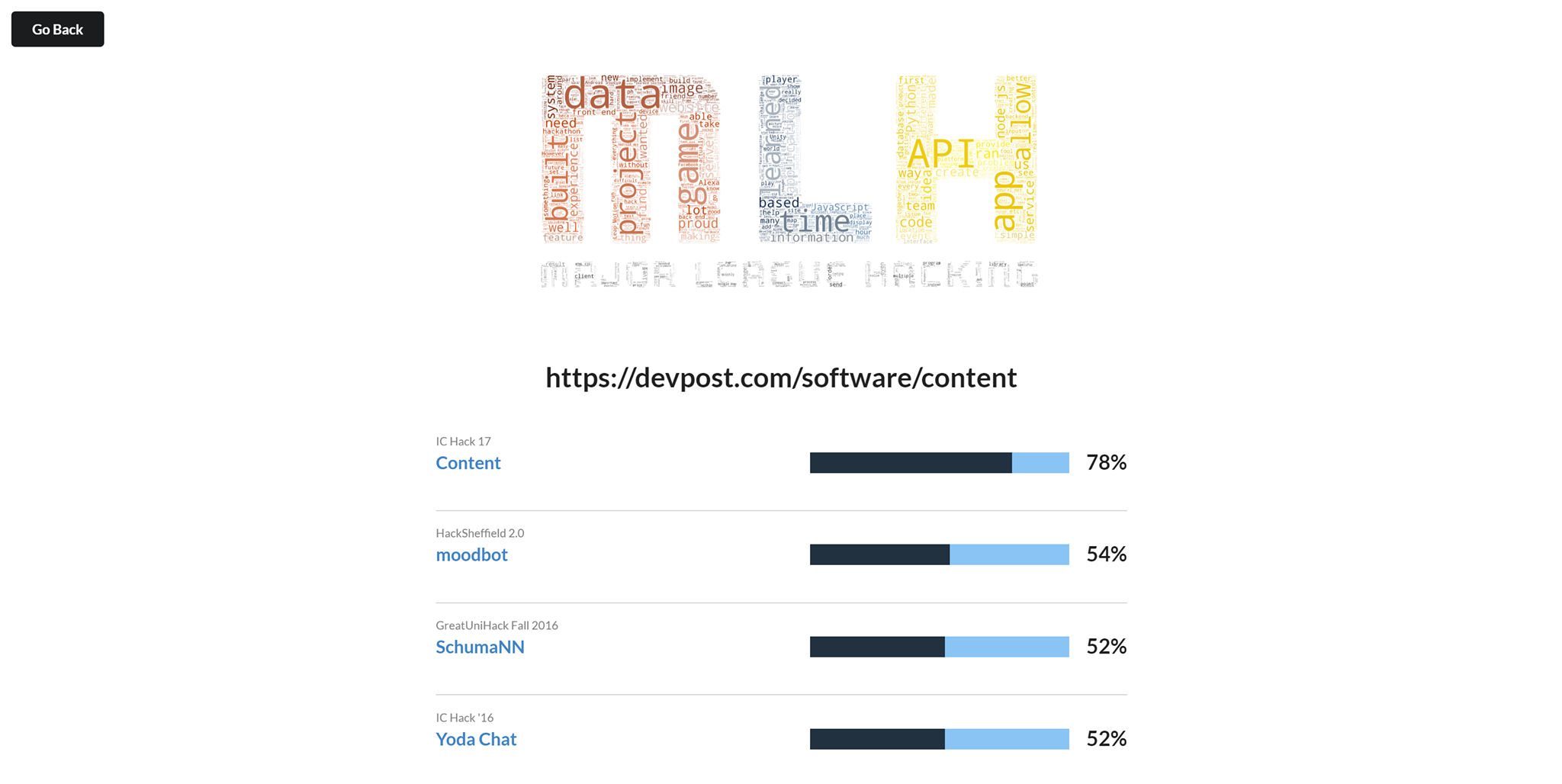
Diff-post is a web portal where you can upload the url of your dev post project which you submitted at a hackathon and then we index it against our database of close to 1000 projects to compute a similarity score based on 3 features, normalised word2vec vectors, common tags for technologies used and keywords obtained using tf-idf.
How we built it
We used Python to automate data collection from Devpost and then stored it in a database that was accessed by our Python scripts which extracted the features required for text mining. Once the features were extracted, we used another script to rank close to 1000 projects based on how similar they were to the submitted project. Once we had the projects ranked, we displayed them in a dashboard which showed how similar your project was in percentage terms and what technologies other such projects had used. We also utilised t-distributed stochastic neighbour embedding to project our 100 dimension vectors to 2 dimensions so we could visualise how similar the workings of projects on DevPost were.
Challenges I ran into
This was probably our most ambitious project to date. And it was fraught with challenges. For starters, scraping DevPost was tricky since the HTML pages weren't well organised and we often had to loop over groups of similar tags to find the ones we were interested in. With the data in place, it was challenging to make use of the word2vec and tf-idf models and it nearly took us all night to first index the database with those features and then generate those features for all new links was challenging too. Finally, we had to make the various pieces of the puzzle play well together and that took nearly all of morning.
Accomplishments that we are proud of
- Scraping such a vast and varied data source.
- Using natural language processing algorithms to extract meaningful information from textual data.
- Building a pipeline that did this over and over again.
What I learned
- We learnt a lot about how text analysis is such a complex field to work in.
- The various preprocessing steps involved in dealing with text data.
- Scraping while being responsible and trying not to bring down DevPost.
- Using Flask
What's next for Diff-Post
- Turning it into a world wide service with a larger database that grows with each hackathon.



Log in or sign up for Devpost to join the conversation.