-
-
Homepage
-

Homepage
-
Loading
-
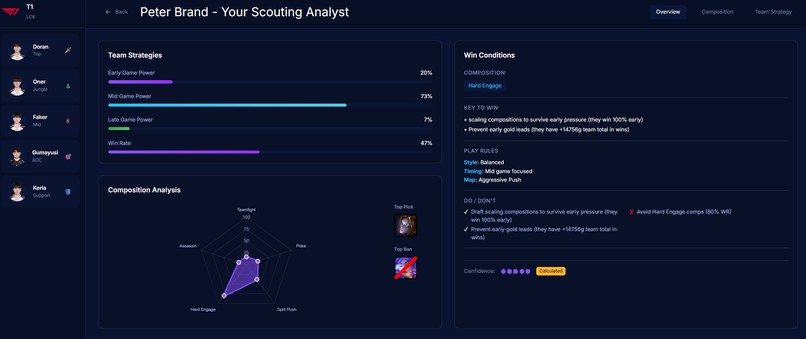
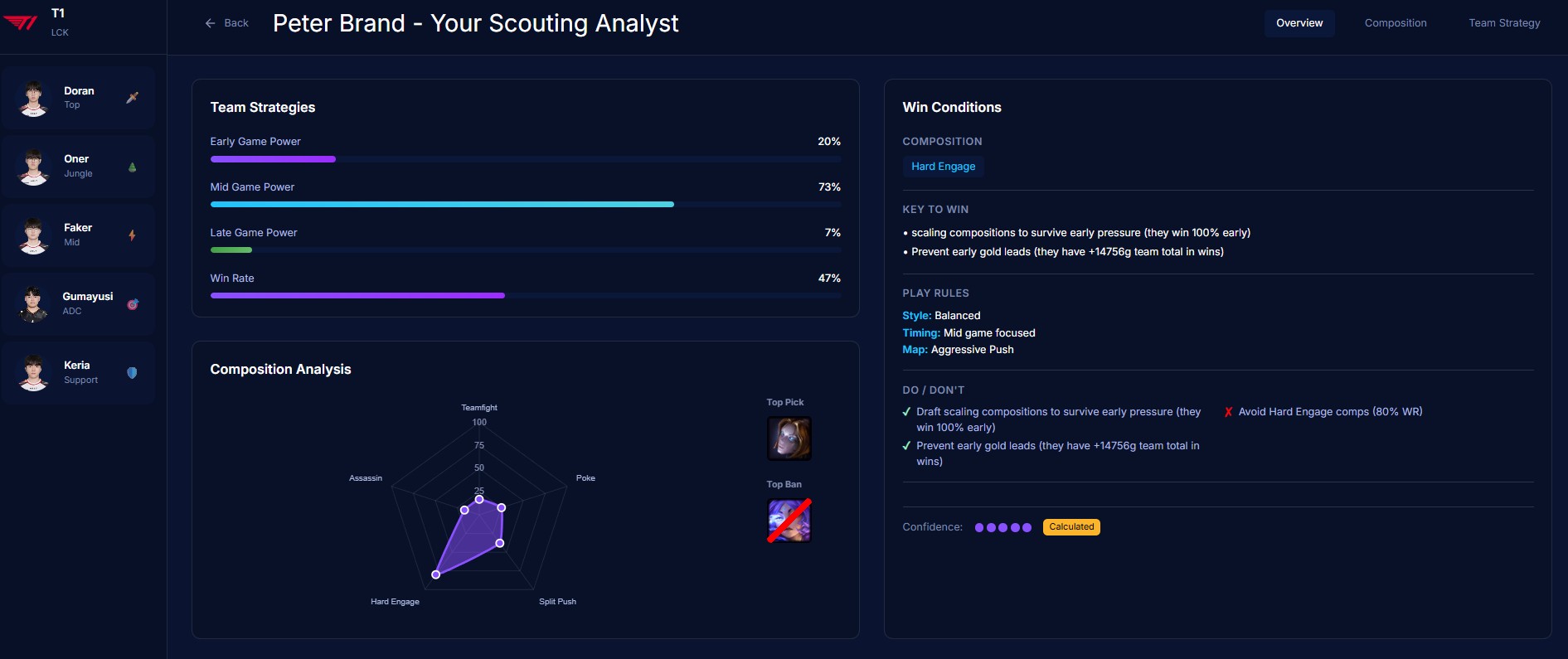
Overview
-
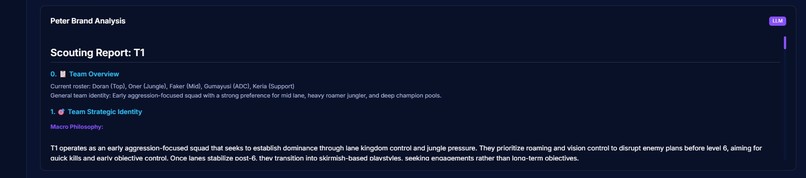
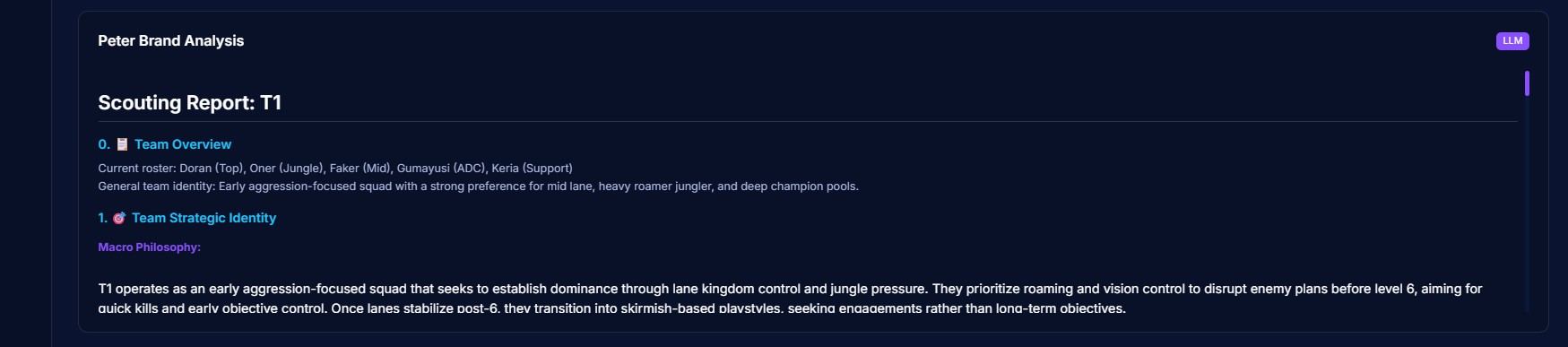
LLM scouting report
-
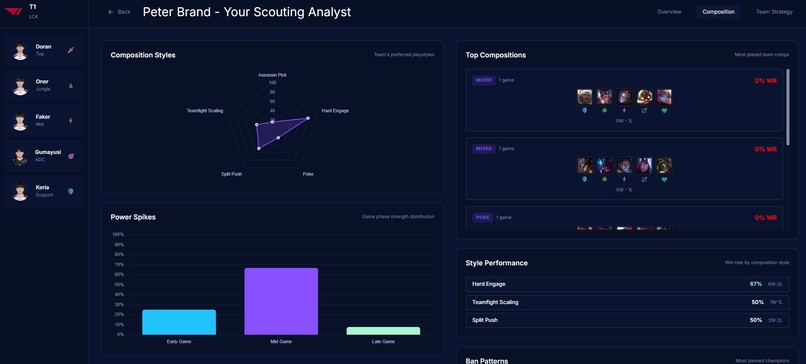
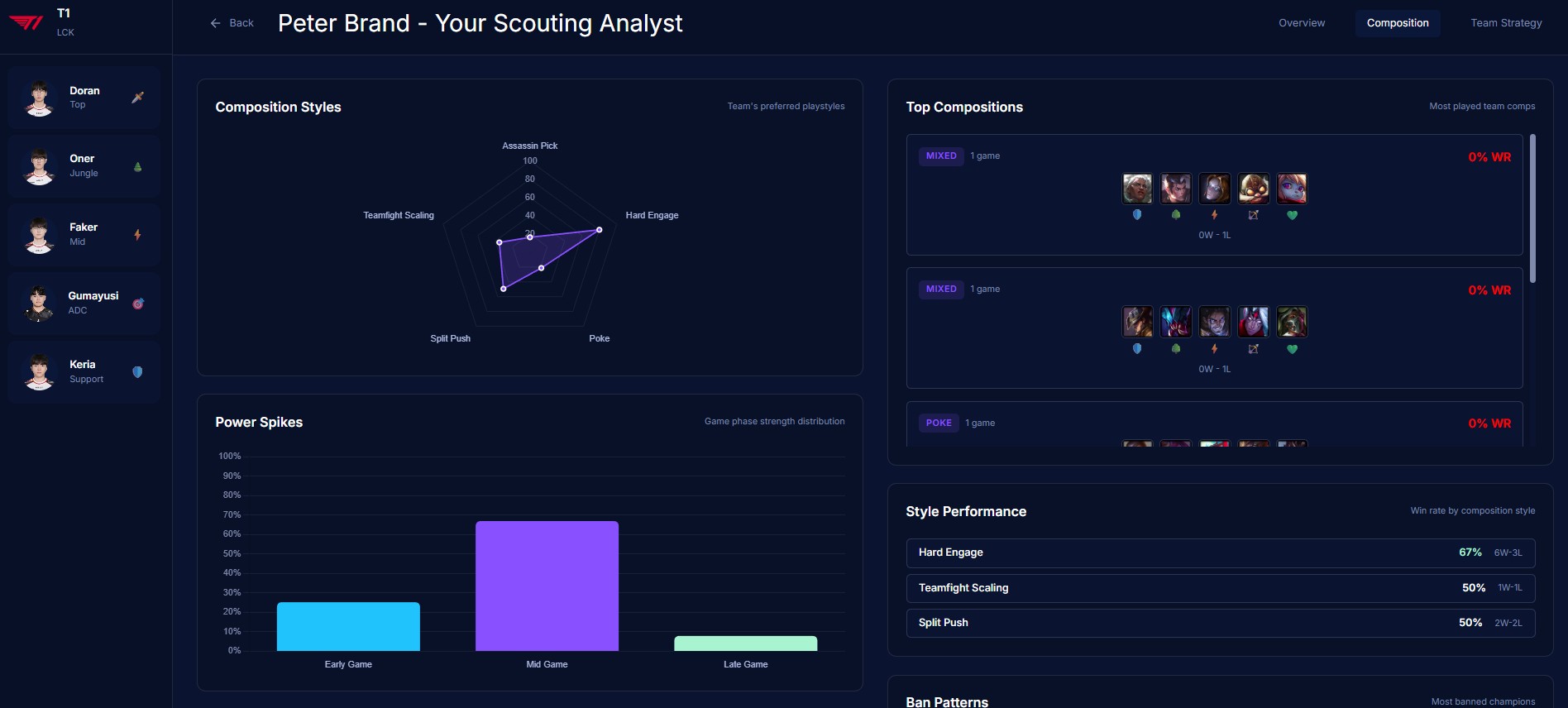
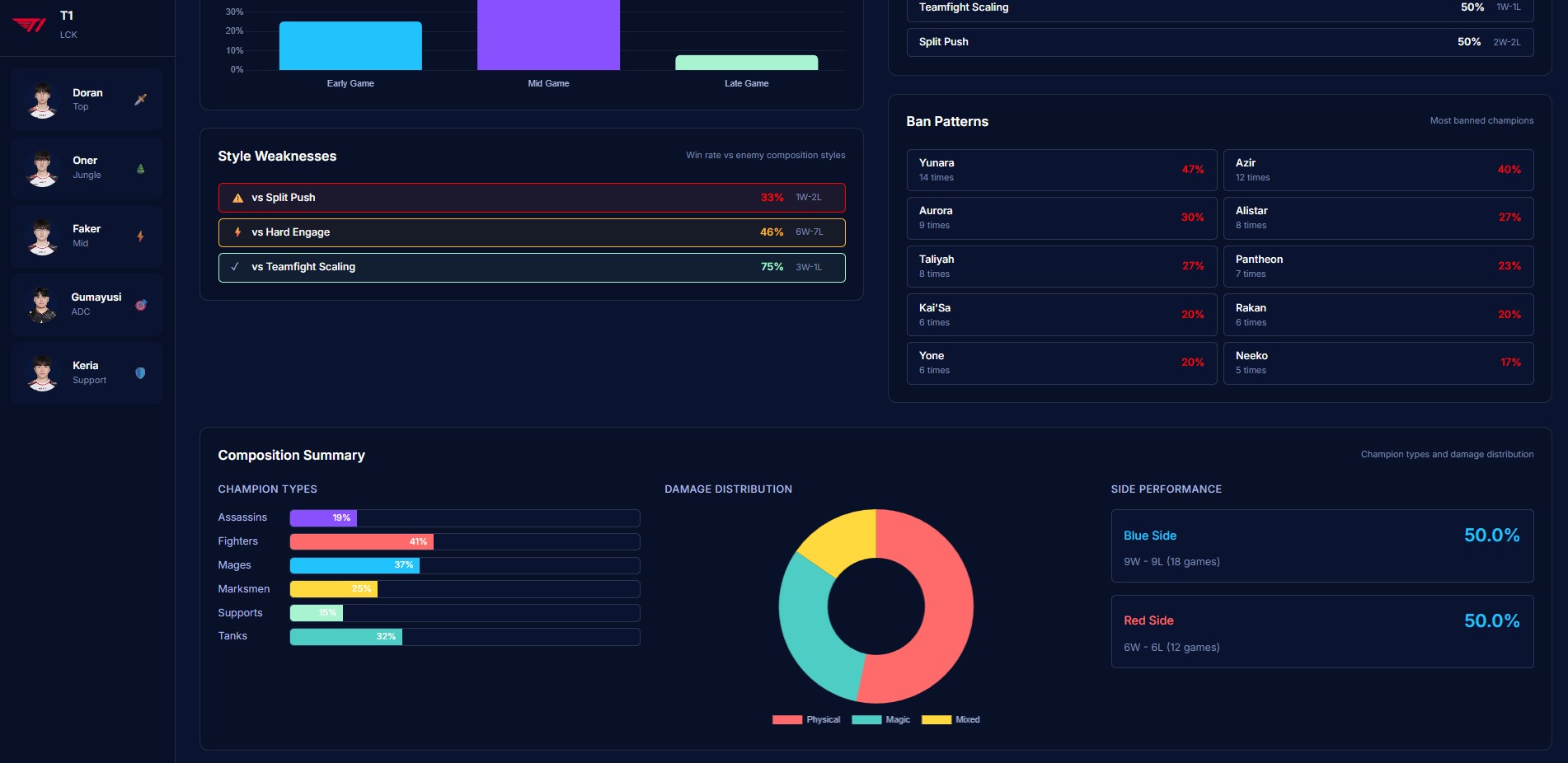
Composition
-
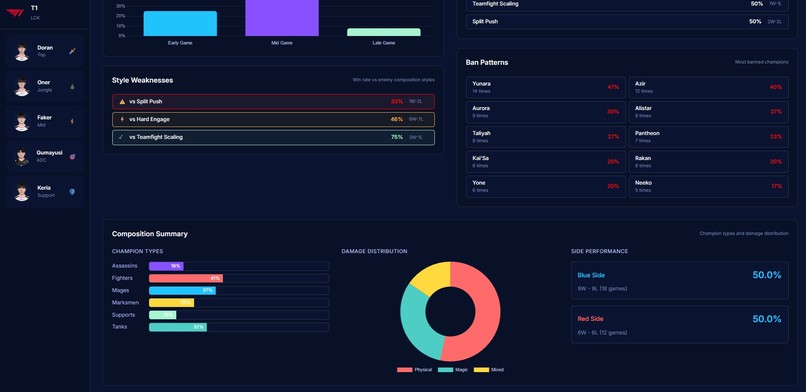
Composition
-
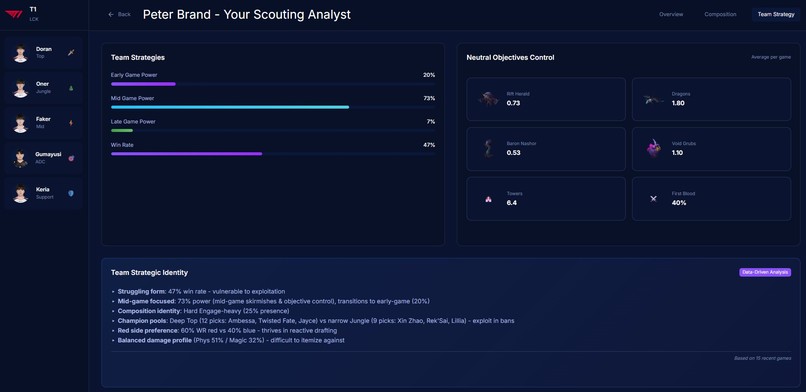
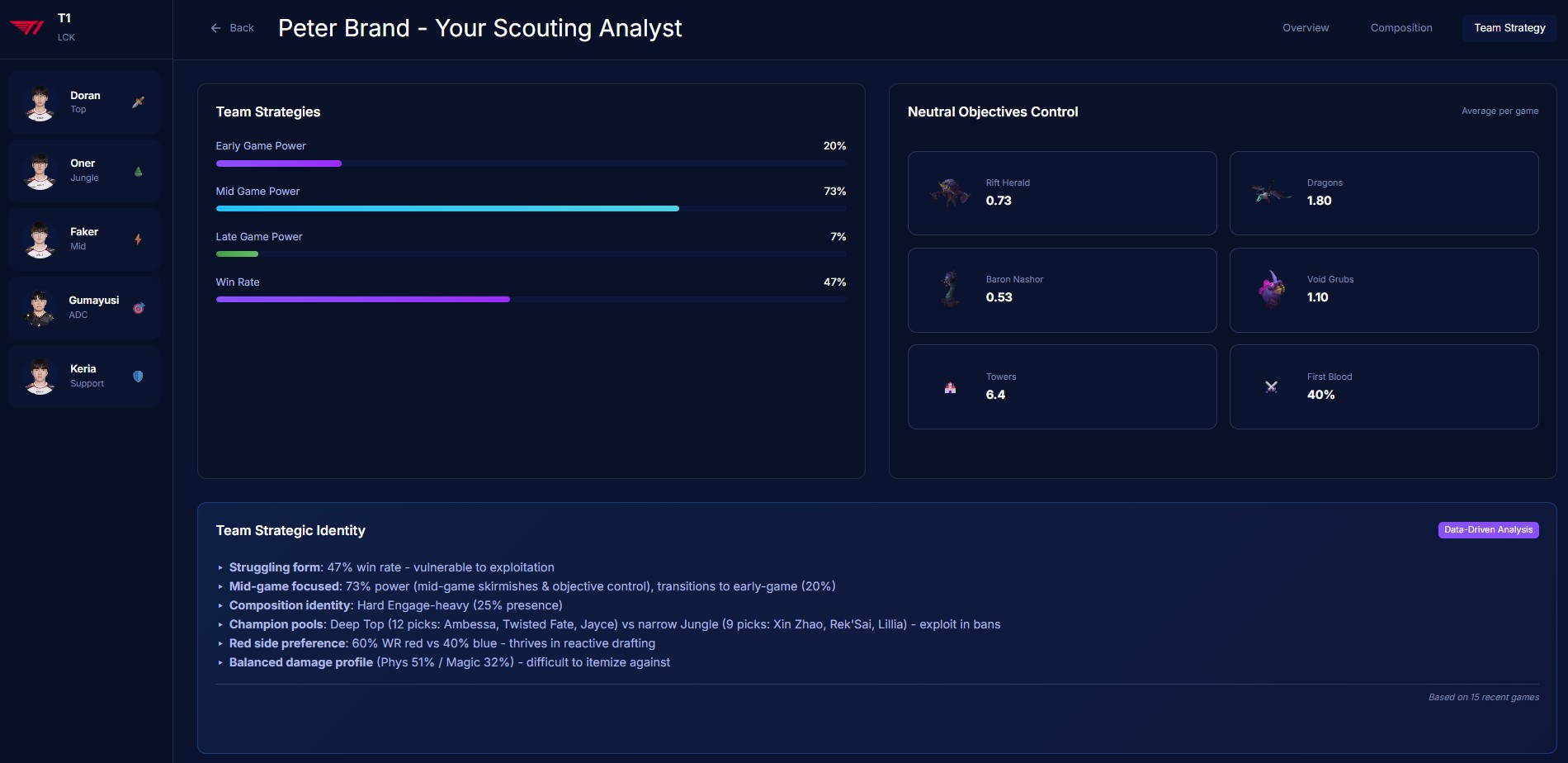
Team Strategy
-
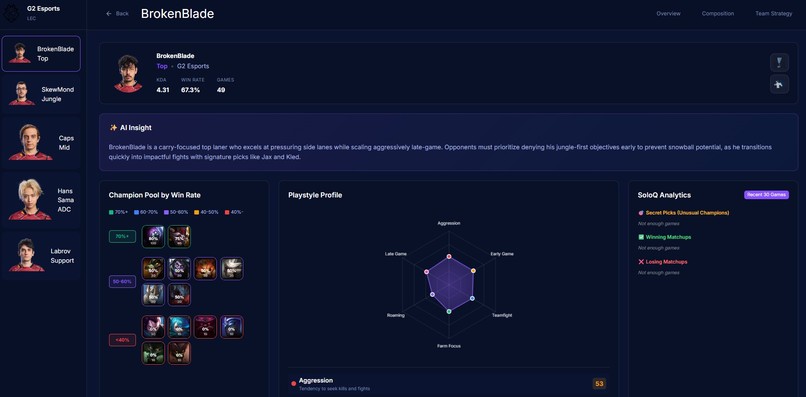
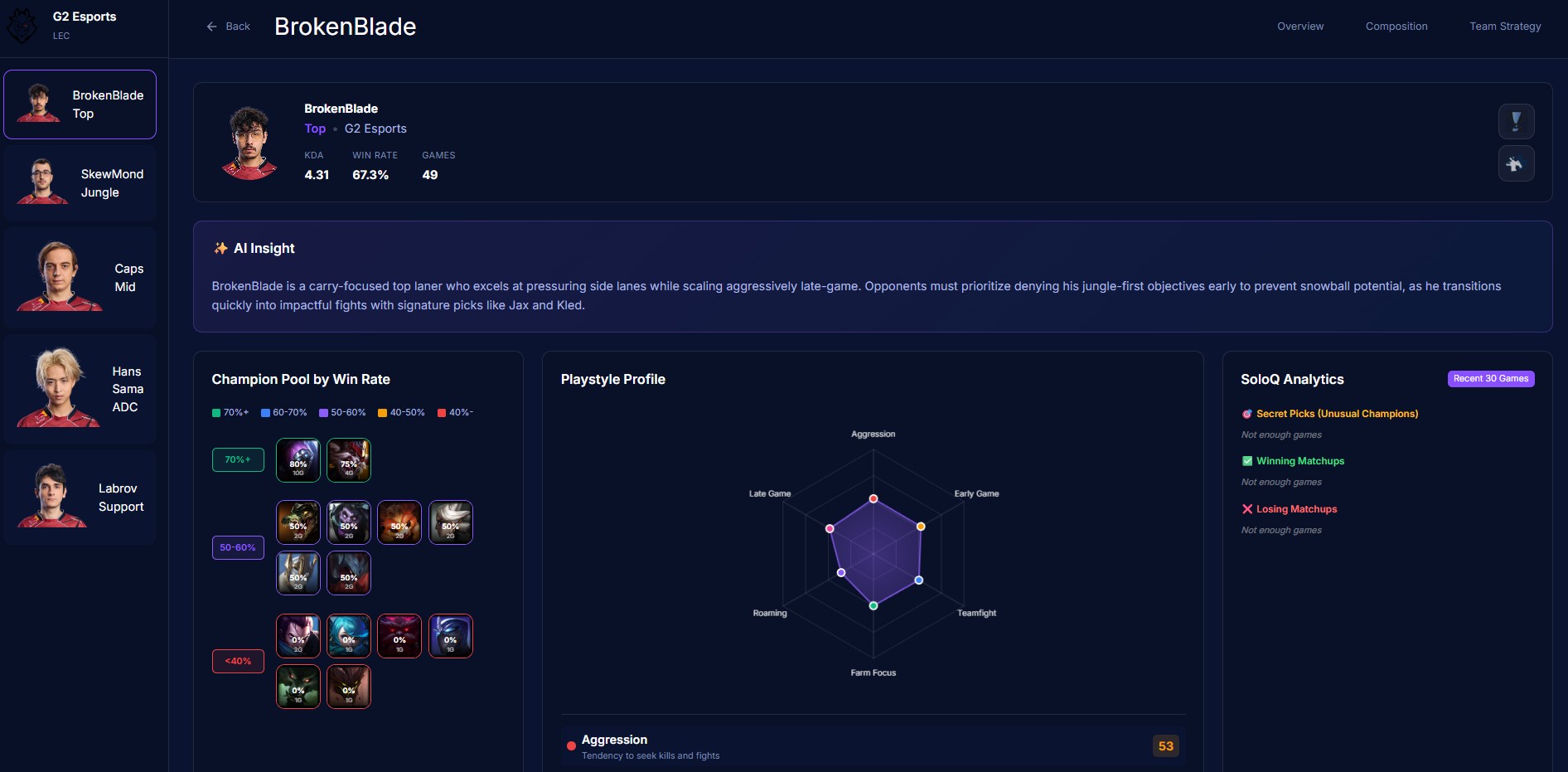
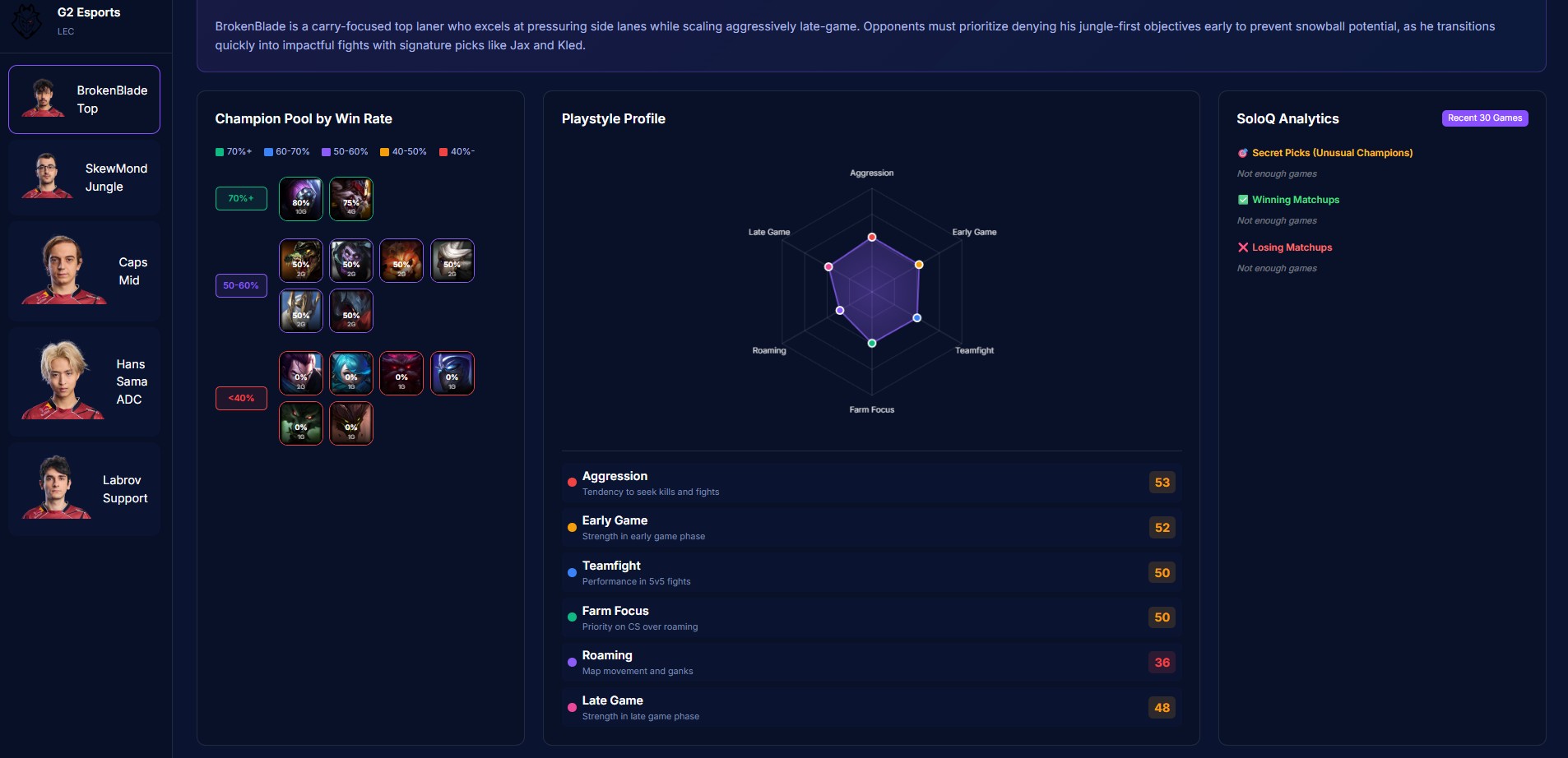
Player Stats
-
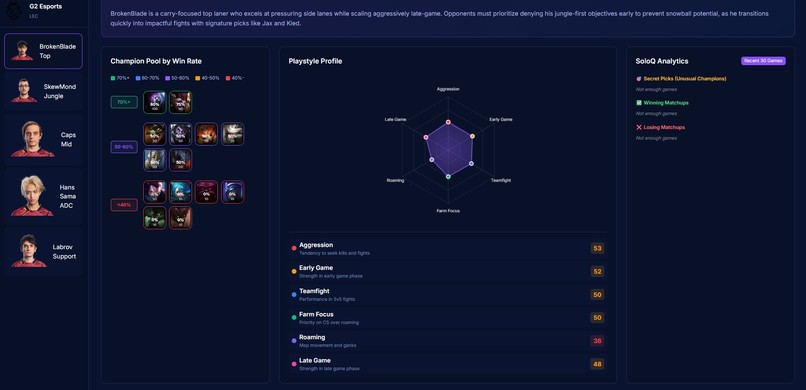
Player Stats

Inspiration
In professional League of Legends, coaching staffs spend 6+ hours per opponent manually reviewing VODs, cross-referencing stats across multiple platforms, and building scouting reports before every match. The process is tedious, inconsistent, and doesn't scale, especially for teams competing in multiple tournaments. We asked ourselves: what if an AI analyst could do this in minutes, with the same rigor and depth a human analyst would bring?
The name "Peter Brand" comes from the character in Moneyball, the analyst who proved that data-driven decisions could compete with traditional scouting. We wanted to bring that same philosophy to esports: replace gut feelings with statistical evidence, and make world-class scouting accessible to any team.
What it does
Peter Brand is an AI-powered scouting platform that generates comprehensive opponent analysis reports for League of Legends esports teams. Using data from GRID Esports (professional match data) and the Riot Games API (Solo Queue), it:
- Analyzes team strategic identity — playstyle classification, macro patterns, tempo preferences, objective control rates
- Grades every player with a threat ranking system based on role-specific percentile benchmarks across combat, economy, vision, and survival metrics
- Detects win conditions automatically — early game dominance, late scaling dependency, carry-focused comps, objective-centric patterns
- Generates counter-strategies — priority bans, draft recommendations, macro counter-play windows, player-specific weaknesses to exploit
- Integrates Solo Queue data — pocket pick detection, matchup win rates, recent champion practice trends
- Produces natural language reports via a LoRA fine-tuned LLM augmented with RAG, giving narrative context to the raw numbers
The web interface lets you navigate by team overview, composition analysis, strategic breakdown, or individual player pages, each with radar charts and detailed statistical profiles.
How we built it
We committed to a 100% local-first architecture from day one. No cloud APIs, no external inference costs, no data leaving the machine. Everything runs on your hardware.
- Data layer: Python pipeline ingesting from GRID's GraphQL API and Riot's Match-v5 API into structured CSV datasets (15,600+ player performances, 6,700+ team compositions, 55 teams)
- Analytics engine: Custom Python analyzers for team patterns, player profiling, win condition detection, and champion pool analysis — all operating on pre-downloaded data for reproducibility
- LLM: Qwen 2.5 7B fine-tuned with LoRA on 227 professionally written scouting reports, quantized to Q6_K (~5.9 GB), served locally via Ollama
- RAG system: ChromaDB vector database with 4 knowledge collections (team, player, meta, strategy), sentence-transformer embeddings, and temporal relevance boosting so recent data is prioritized
- Web UI: Flask + vanilla JS + Chart.js — no heavy frontend framework, just fast and functional
- Graceful degradation: 3-tier fallback — fine-tuned LLM → base model → template-based reports. No tier ever produces fake data.
Challenges we ran into
- Finding training data for LoRA: There's no public dataset of professional scouting reports. We had to generate and curate 227 high-quality reports ourselves to fine-tune the model, which was a significant effort to get the writing style and analytical depth right.
- Fine-tuning the model: Getting LoRA to work properly on Qwen 2.5 7B required navigating quantization formats, PEFT configurations, and training on a Google Colab T4 GPU. Balancing between overfitting on our small dataset and maintaining generalization was tricky.
- Data normalization: Team and player names differ between GRID data and Riot API data. Building a reliable mapping system that handles roster changes, name variations, and regional differences was a constant battle.
- RAG relevance tuning: Getting the right balance between semantic similarity and temporal relevance so the LLM receives useful context without noise — especially when dealing with meta shifts between patches.
- Keeping it local: Running a 7B parameter model + ChromaDB + embeddings + Flask on a single machine with reasonable response times required careful optimization of memory usage and inference configuration.
Accomplishments that we're proud of
- 6 hours → 2 minutes: A full scouting report that would take an analyst half a day is generated in under 2 minutes, with comparable depth and structure.
- Zero external API calls during analysis: The scouting engine is fully offline — same input always produces the same output. Reproducibility is guaranteed.
- End-to-end custom ML pipeline: From data collection to LoRA fine-tuning to RAG-augmented inference to web UI — every layer was built by us, running locally.
- No fake data, ever: Across all 3 fallback tiers, the system never fabricates statistics. If a stat isn't available, it's
None, not an average or a guess. - Role-specific threat grading: Players are ranked against their positional peers using percentile benchmarks, not generic cross-role comparisons. A support with 200 DPM isn't penalized the same way a mid laner would be.
- Solo Queue integration: Bridging the gap between stage play and ranked ladder data to detect pocket picks and recent practice patterns that pure competitive data would miss.
What we learned
- LoRA is incredibly powerful for domain specialization: With only 227 training samples and 2 hours on a T4 GPU, we turned a general-purpose LLM into a convincing esports analyst. The parameter efficiency (~0.5% of the model fine-tuned) makes this accessible to anyone.
- RAG and fine-tuning are complementary, not competing: Fine-tuning teaches the model how to write scouting reports. RAG injects what it should write about. Together they produce reports that neither approach could achieve alone.
- Data quality > data quantity: Spending time curating clean, consistent datasets paid off far more than accumulating raw data. Defensive data handling (no fallback values, no fabrication) kept our analysis trustworthy.
- Local-first is viable for real ML applications: You don't need cloud GPUs or API subscriptions to run meaningful AI workloads. A quantized 7B model on consumer hardware produces genuinely useful output.
- Esports analytics is still an untapped space: Despite League of Legends being one of the biggest esports in the world, the tooling available to coaches and analysts is surprisingly limited. There's real potential for data-driven tools in this space.
What's next for Peter Brand – Your scouting analyst
Multi-game support
Extending the platform to other esports titles (Valorant, CS2) using the same modular and data-driven architecture.Patch-aware meta tracking (Agentic RAG)
Moving beyond static updates by introducing an agentic RAG system that autonomously monitors patch notes, meta shifts, and emerging trends.
The agent selectively gathers and injects only relevant information (buffs, nerfs, systemic changes) to keep champion evaluations, tier lists, and strategic insights continuously up to date — without manual intervention.Cloud-native deployment
Migrating the entire stack to the cloud (models, databases, and pipelines), enabling access from any device, desktop, tablet, or mobile.
This unlocks real-time collaboration, scalability, and frictionless access for coaching staffs wherever they are.PDF export
One-click export of complete scouting reports as clean, structured PDFs for offline review or team meetings.Historical trend analysis
Tracking how a team’s playstyle evolves over time, detecting long-term patterns, improvements, or regressions across patches and stages of competition.Expanded LoRA training
Continuously enriching the training data with new report styles and direct coach feedback to improve analysis depth, tone, and relevance.Team comparison mode
Side-by-side analysis of two teams to anticipate matchup dynamics, highlight strategic mismatches, and identify key win conditions before a series.
Built With
- chromadb
- css
- flask
- javascript
- ollama
- python

Log in or sign up for Devpost to join the conversation.