Inspiration
- My inspiration comes from my first year of university. There was too much work, and I fell behind on many many many lectures totaling 15 hours of content that I did not have time to watch. It was almost EXAM WEEK playing the videos at 2 times speed wasn't going to cut it. At that moment I hoped for a tool to summarize key aspects of the lectures, and narrow down the topics for me to study for the exam.(Xiang)
- Another inspiration comes from personally learning biology. There are many different terms in biology, and it can be especially daunting for a non-native English reader. (Jordan)
- We have wanted a way to help fellow students learn about their desired subjects in an easier manner. So, we thought about how could we make the teachings more streamline and understandable for current students. How could we take what is learned from school or other activities to great online resources for students to learn from. (Tom)
What it do baby
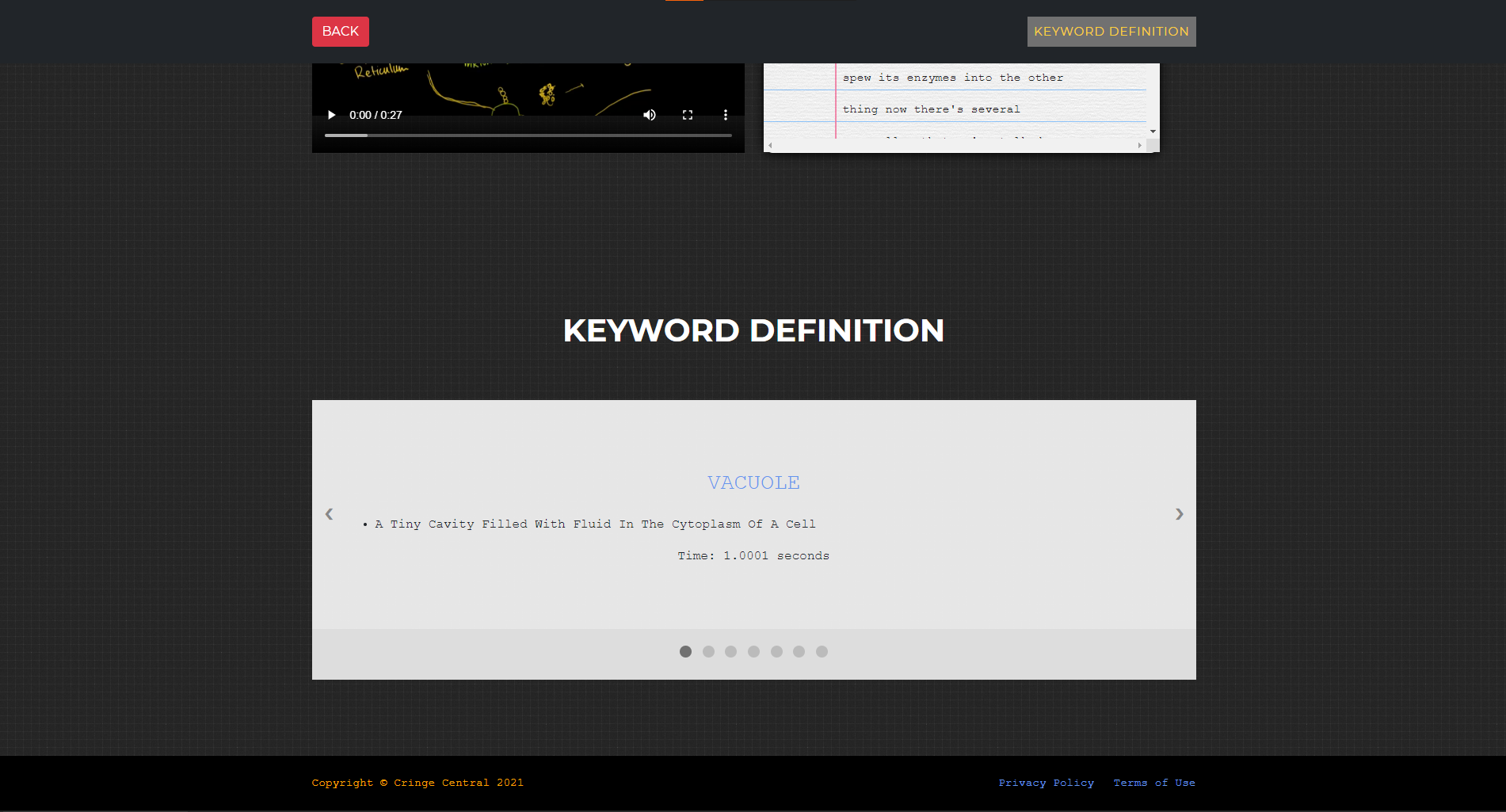
The application takes the user's uploaded video/lecture, and transcribes using the Cloud Speech-to-Text. We use the transcript to query the keyword bank for matches. Then we use a python dictionary library to define the resulting terms. Finally, we display everything, the word, its definition, its timestamp, on the page.
How we built it
- Django, Firebase, and Google Cloud for the backend.
- pyrebase for Firebase API
- pydictionary library for definitions
- Cloud Speech-to-Text for transcriptions
- bootstrap for the frontend
Challenges we ran into
One major challenges we went through is with pathing and URLs with Django. We were constrained by time and couldn't develop some of the cooler features we have in mind.
Accomplishments that we're proud of
- Implementing Google storage buckets and being able to store videos
- being able to transcript file bigger than 10Mb asynchronously
- the frontend looks great
- the feasibility of this application
What we learned
We learned how to integrate Firebase with Django, as well as using Pyrebase, a python wrapper, to interact with it.
What's next for Proxy Lecturer
Currently, we only have a limited word bank of keywords. It is also limited to biology terms.
- some things we have to fix:
- have relative filepaths
- convert mp4 files into wav or flac audio files with python.
- In the future, the word bank will be replaced with AI instead. We will extract keywords about any topic by using machine learning artificial intelligence with natural language processing.
- Another feature we want to implement is download, so the user can keep their transcription as a convenient PDF.
- We also want to replace the link to the YouTube search results with a preview of a related video.



Log in or sign up for Devpost to join the conversation.