-
-
GCS-images
-
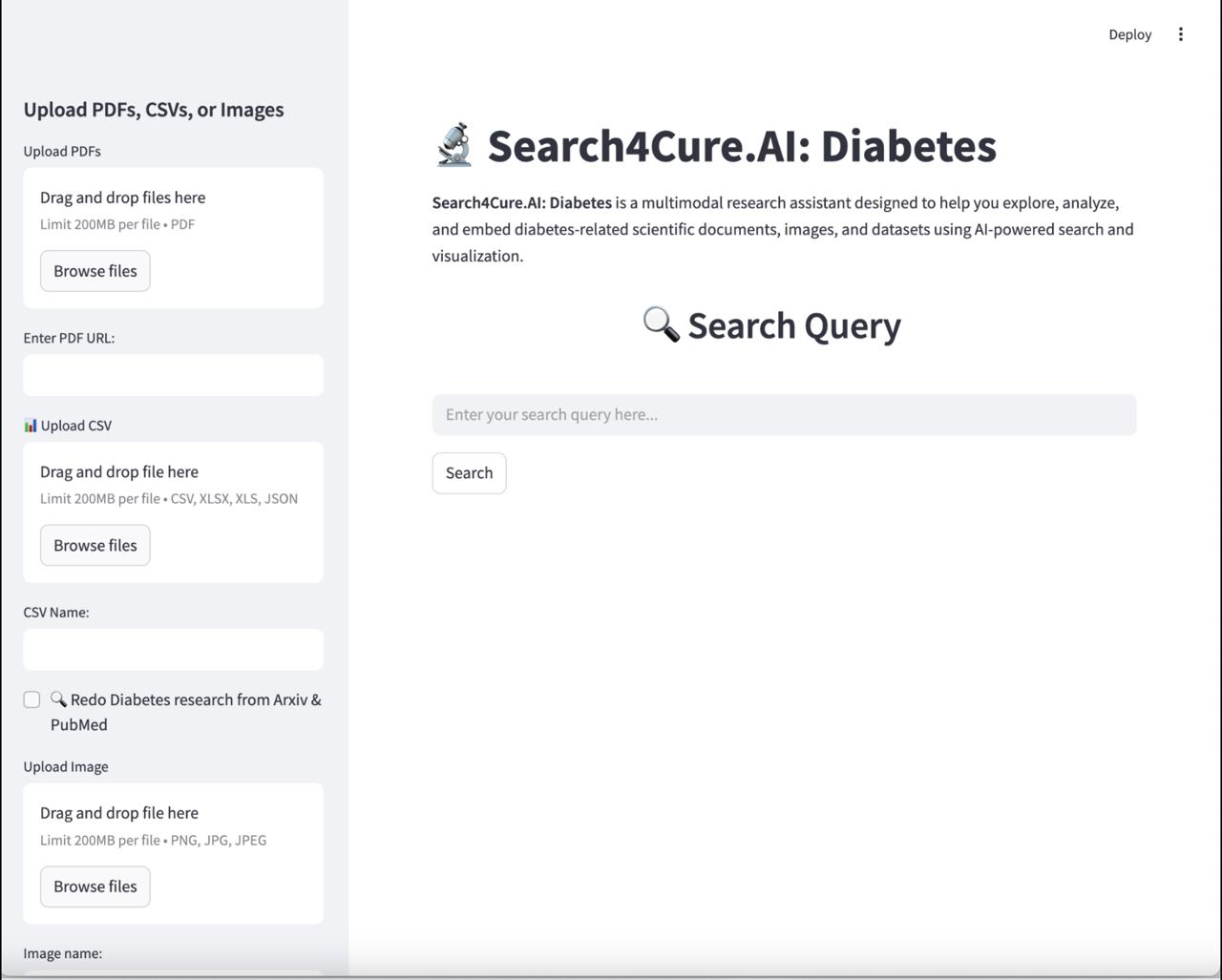
streamlit app
-
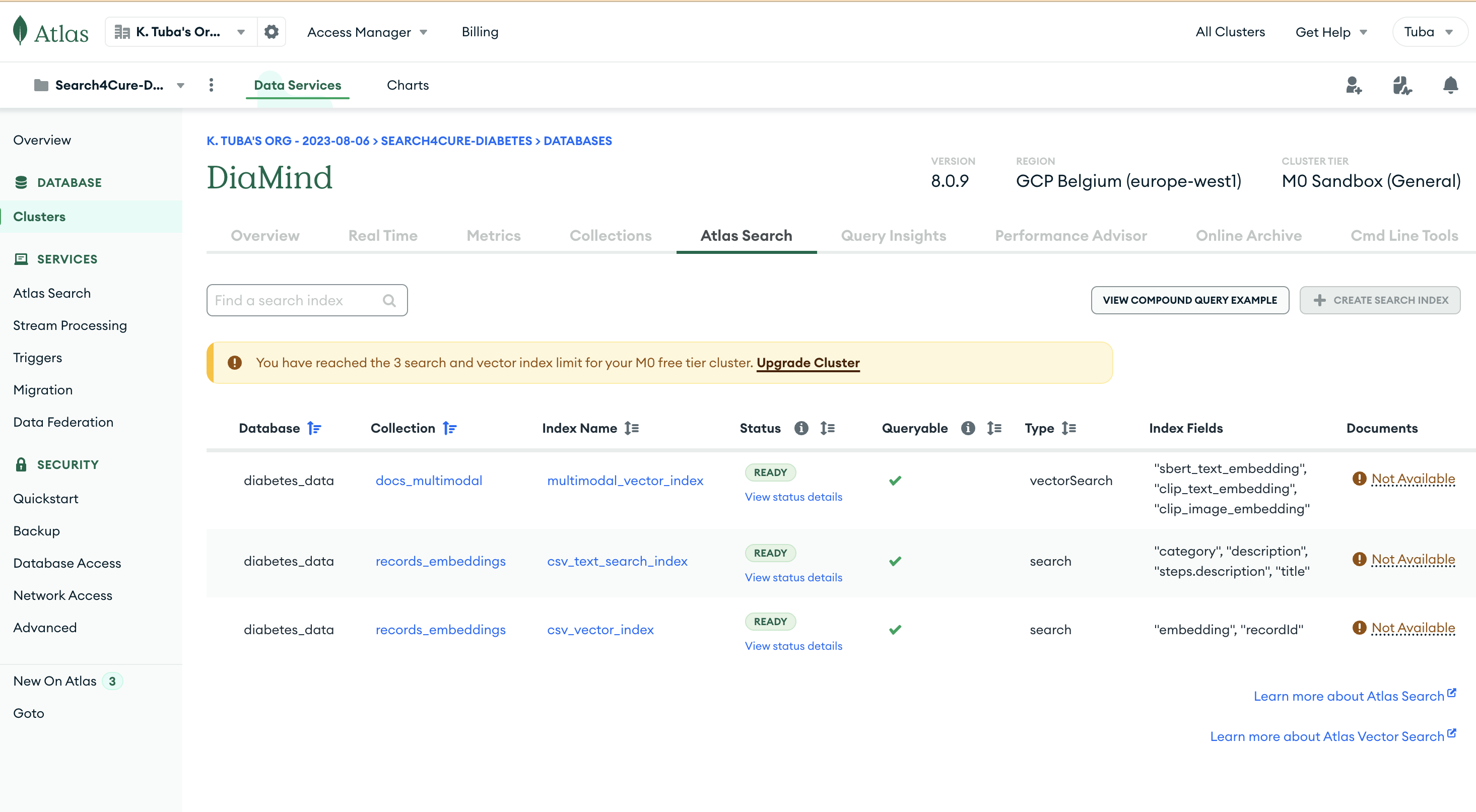
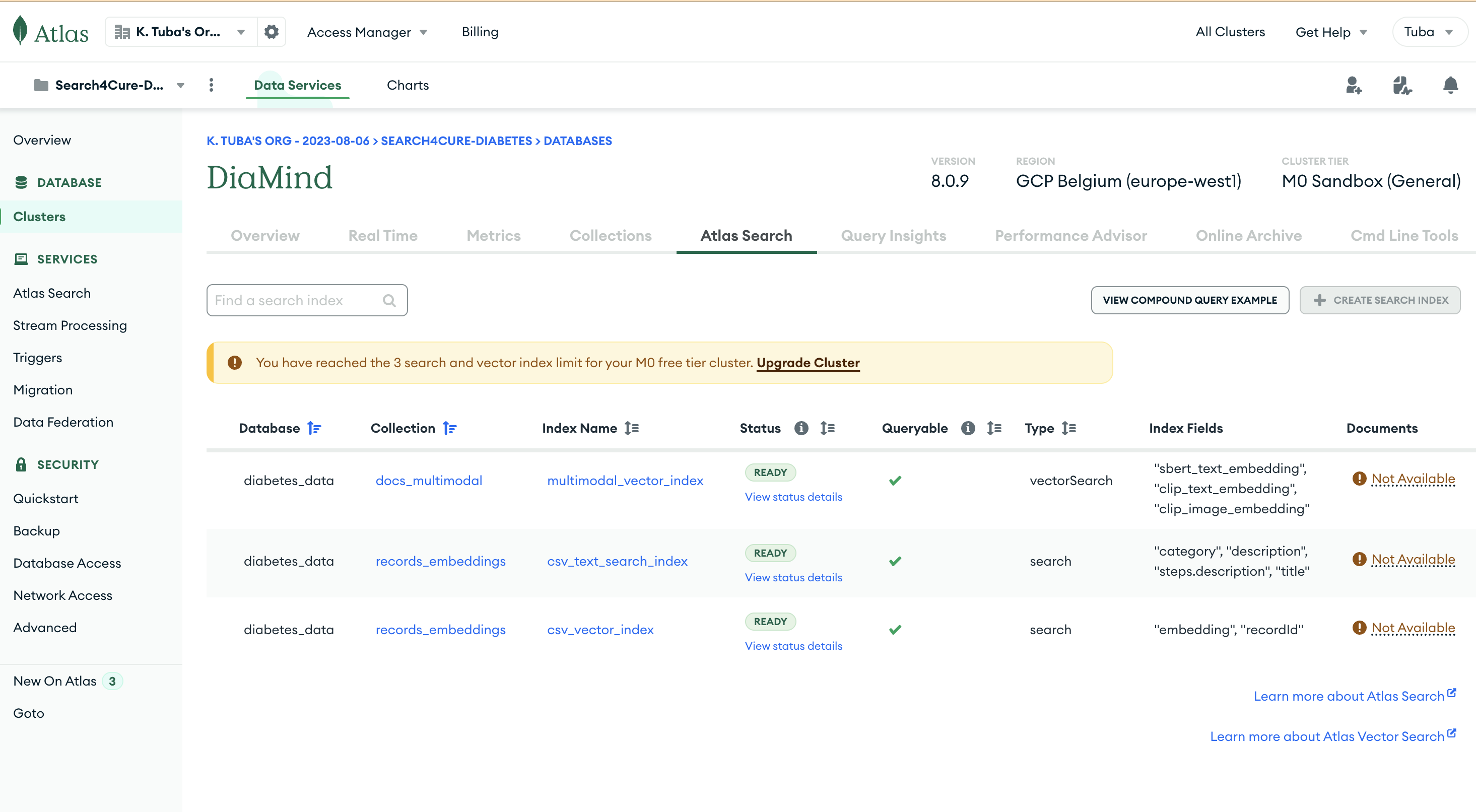
mongodb-atlas-search
-
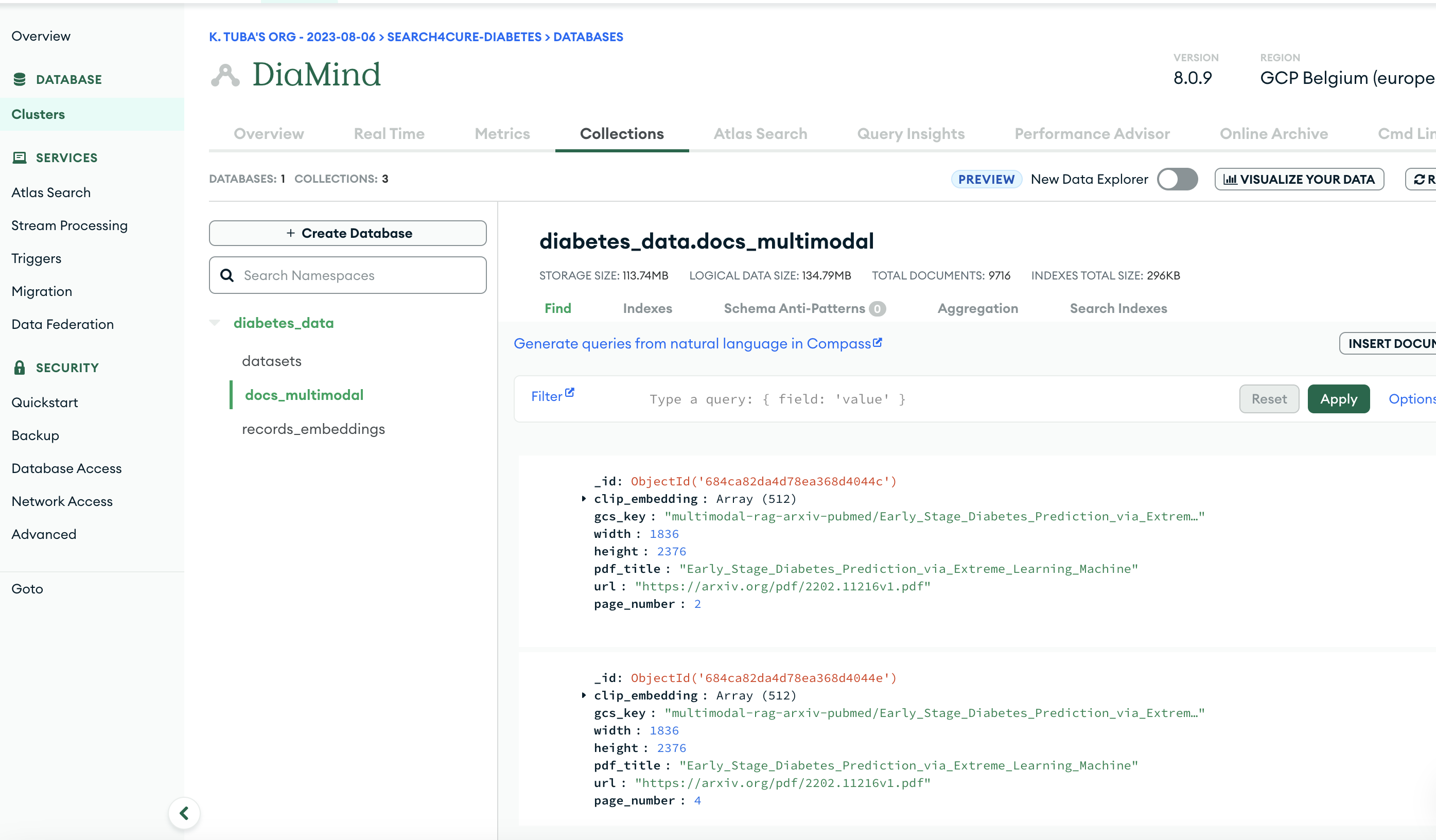
mongodb-multimodal-embeddings
-
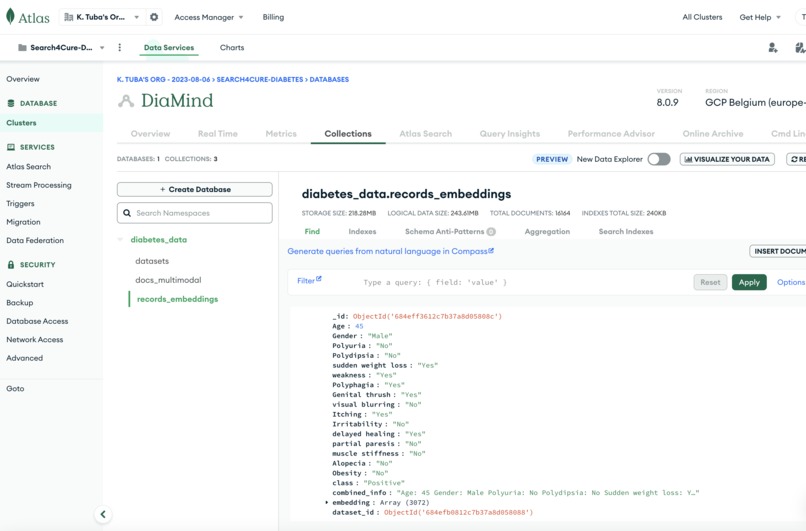
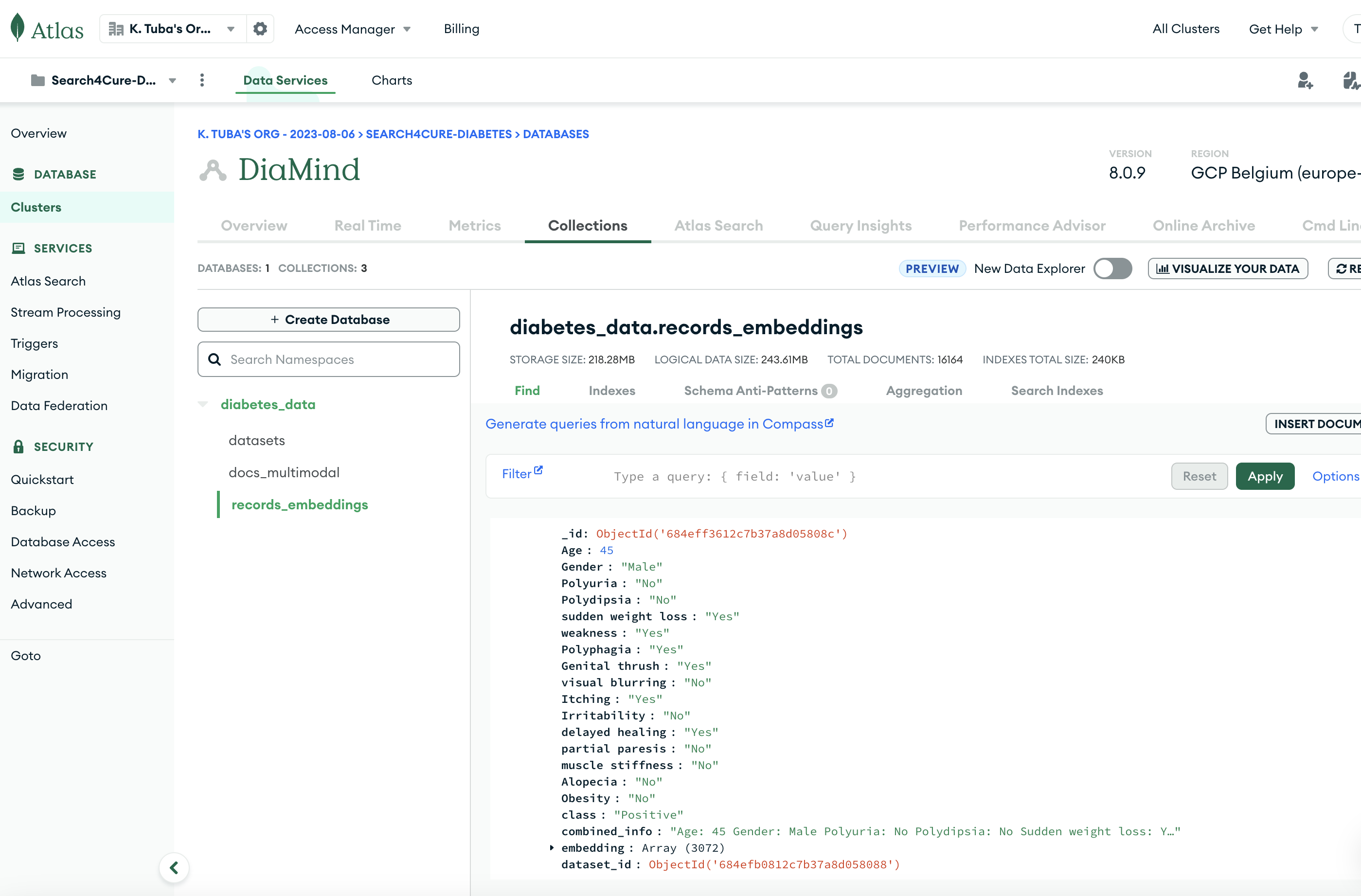
mongodb-csv-records
-
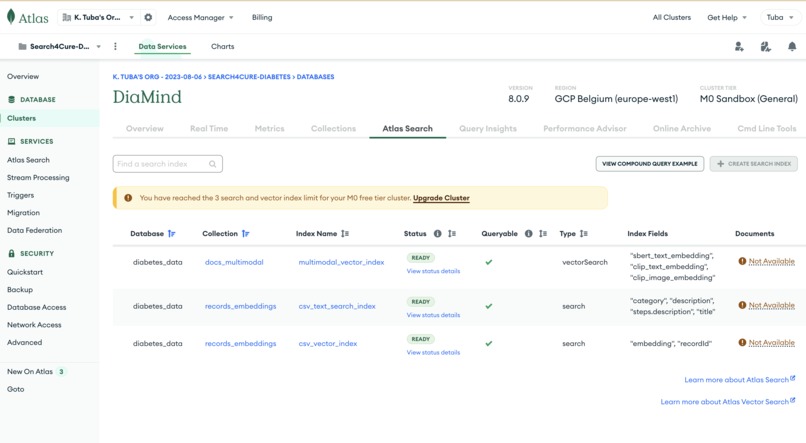
mongodb-atlas-search
Search4Cure.AI-Diabetes: AI-Powered Research Assistant
🧠 Inspiration
Diabetes is one of the world’s most prevalent and complex chronic diseases. Despite vast amounts of research, the process of discovering new insights remains time-consuming. I was inspired by the idea of building an AI system that could bridge gaps between text, data, and images — and help researchers find connections faster.
🚀 What it does
Search4Cure.AI-Diabetes is an AI-powered research assistant that enables scientists and clinicians to:
- 🔍 Search across Arxiv, PubMed, CSV files, and images for diabetes-related insights.
- 🧠 Perform multimodal similarity search using both text and images.
- 🤖 Use agentic workflows to extract structured answers and recommendations with humans in the loop.
- 📊 Leverage LLMs, CLIP embeddings, and vector databases to surface meaningful connections in large datasets.
🛠️ How I built it
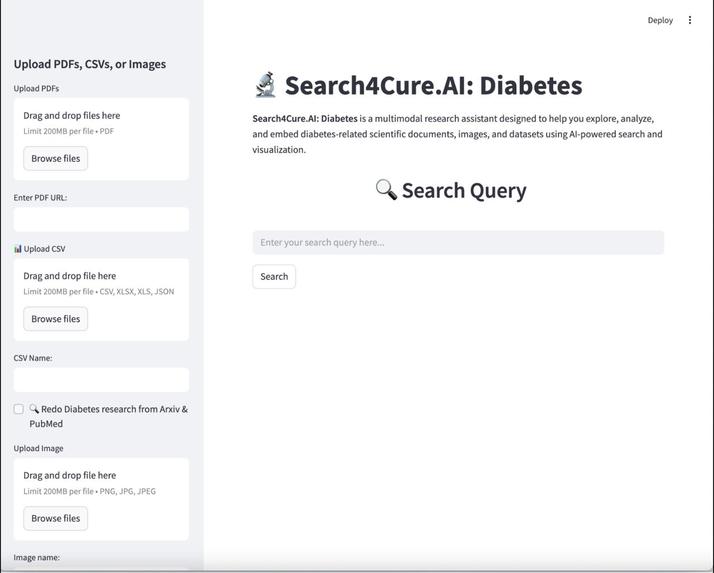
Frontend: Built with Streamlit for an intuitive UI allowing query entry, file uploads, and result visualization.
Data Sources:
- Scientific articles from Arxiv and PubMed
- Tabular data via CSV uploads
- Medical images for embedding-based search
- Scientific articles from Arxiv and PubMed
Embeddings:
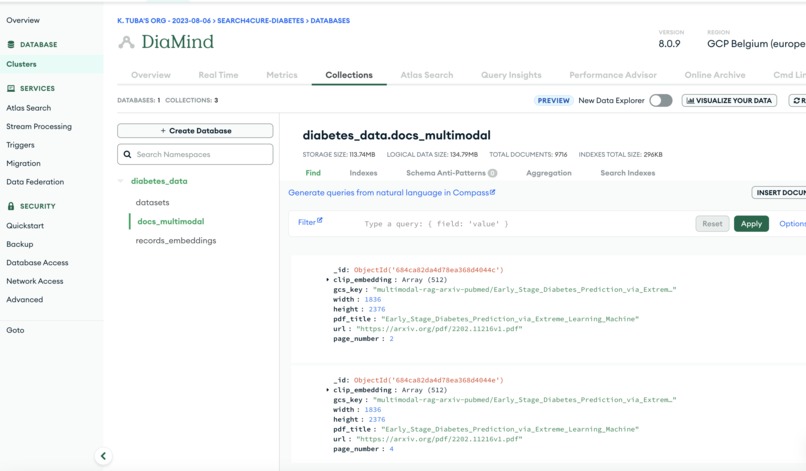
sbert_text_embedding(384-dim): Semantic search across documentsclip_text_embeddingandclip_image_embedding(512-dim): For multimodal alignmentgemini_embedding(256-dim): For CSV records and structured text
Storage & Retrieval:
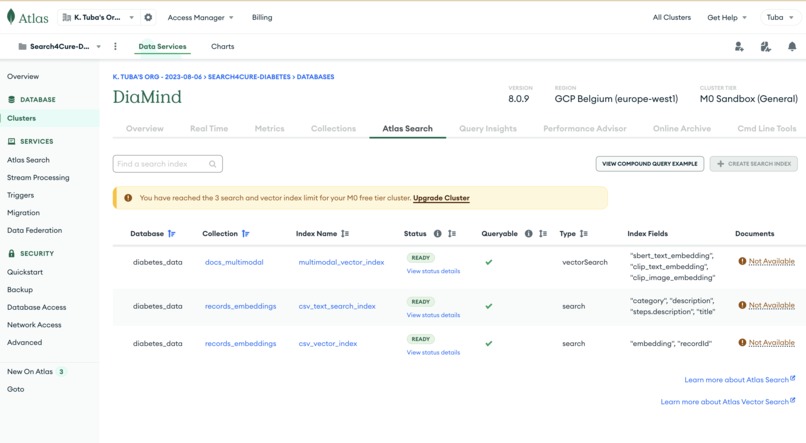
- 🧠 MongoDB Atlas Vector Search for fast, scalable similarity lookups
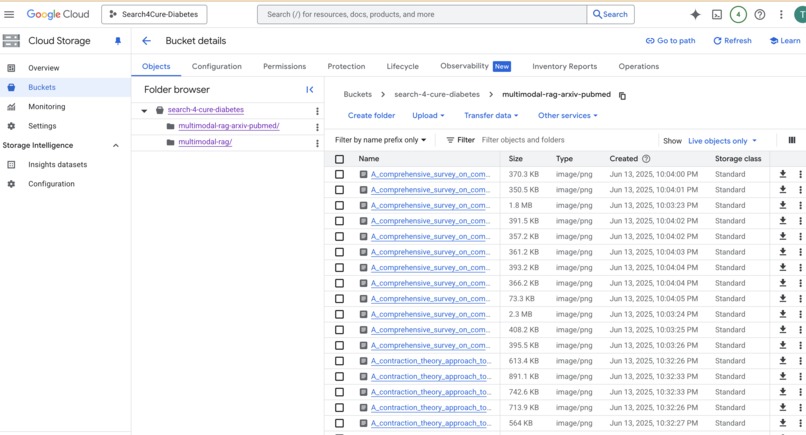
- ☁️ Google Cloud Storage (GCS) for storing and retrieving uploaded images
- 🧠 MongoDB Atlas Vector Search for fast, scalable similarity lookups
Agentic Reasoning:
- Used modular LLM workflows to simulate human-in-the-loop interactions and structured reasoning chains.
⚠️ Challenges I ran into
- Ensuring dimensional compatibility across multimodal embeddings (text vs image).
- Handling varied formats from PubMed XML, Arxiv JSON, and user-uploaded CSVs.
- Implementing efficient chunking and deduplication to reduce noise in search results.
- Managing API quotas, rate limits, and latency
## 🏆 Accomplishments That I'm Proud Of
- 🛠️ Successfully integrating multiple modalities (text, tabular data, images) into a unified semantic search framework
- 🤖 Designing a working agentic LLM pipeline to simulate human reasoning in research workflows
- 🌐 Deploying a full-stack app with real-time similarity search using MongoDB Atlas Vector Search and Google Cloud Storage
- 💡 Building a tool that can potentially accelerate biomedical research and generate actionable insights
📚 What I Learned
- 🚀 How to build scalable, multimodal embedding pipelines combining SBERT, CLIP, and Gemini
- 🧠 Designing agentic AI workflows that simulate scientific exploration with LLMs
- ☁️ Integrating and deploying services using MongoDB Atlas, GCS, and Streamlit
- 🧵 Combining usability, performance, and AI reasoning in a single end-to-end application
🔮 What's Next for Search4Cure.AI-Diabetes
- 🧬 Generalize the assistant to support other diseases such as cancer, Alzheimer’s, and rare genetic disorders
- 🤝 Enable collaborative research with shared workspaces, annotations, and versioning
- 📈 Enhance explainability and transparency of AI-generated insights for trust and adoption
- 🌍 Integrate additional data sources like clinical trials, patents, and medical guidelines

Log in or sign up for Devpost to join the conversation.