-
Basic landing page as this is a prototype version
-
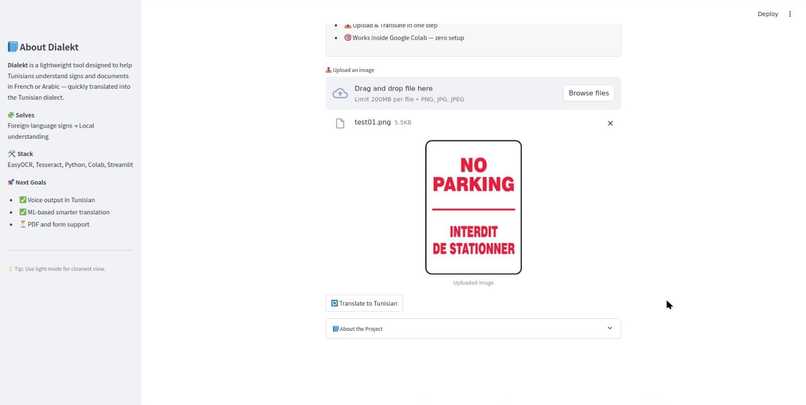
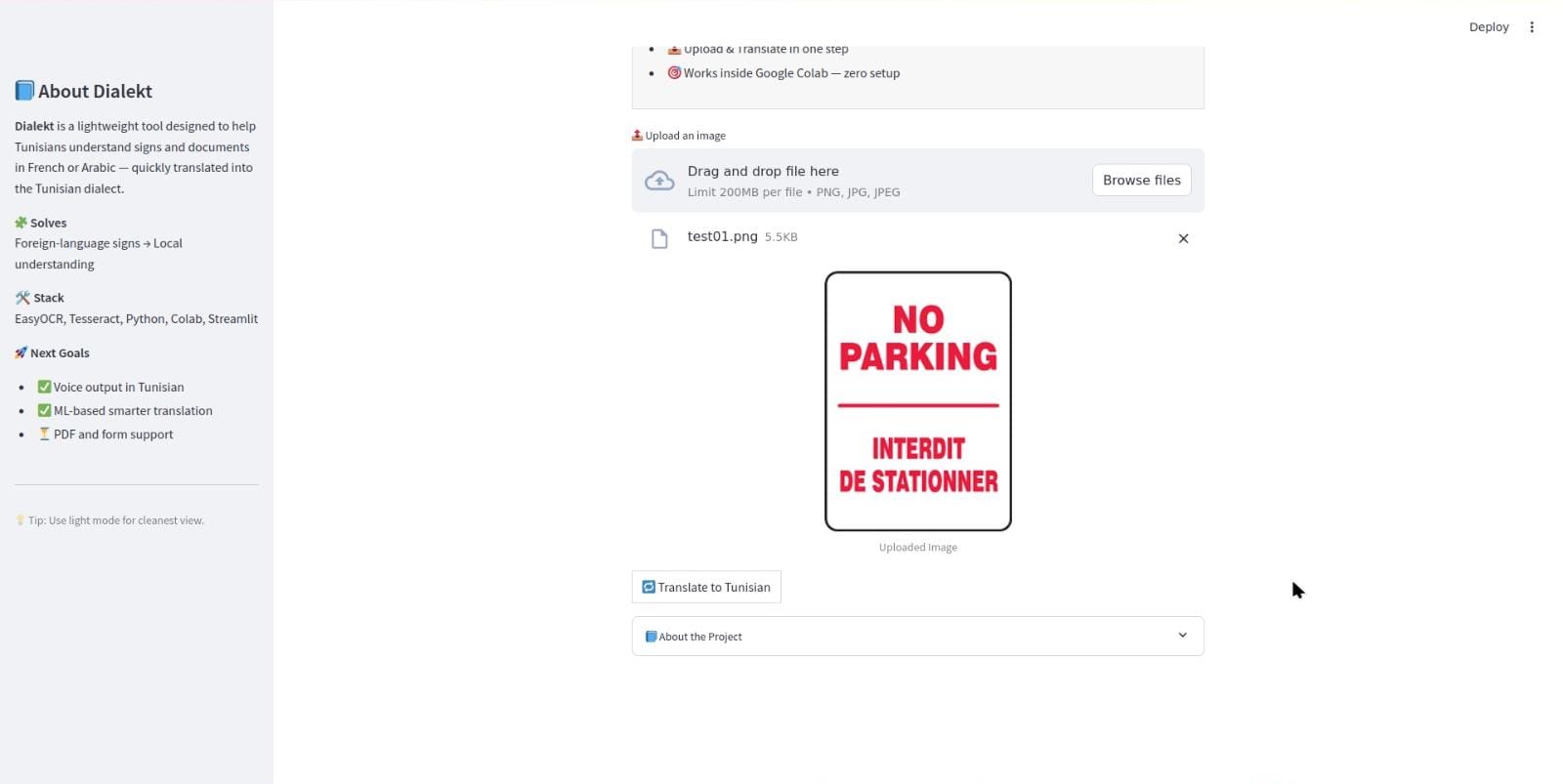
Here you can select any image from gallery or you can click from camera not added yet
-
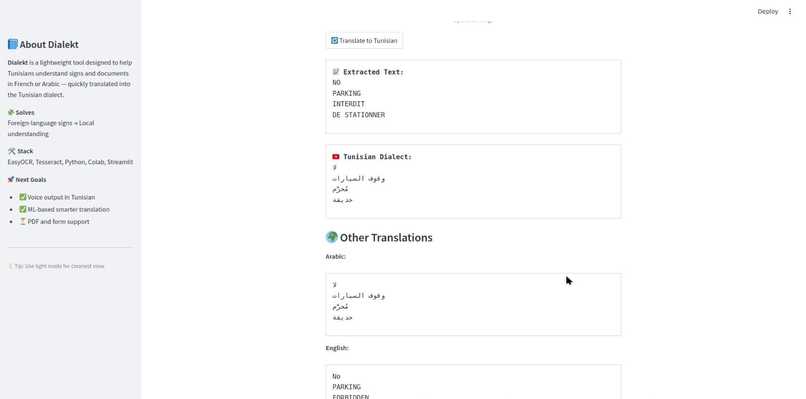
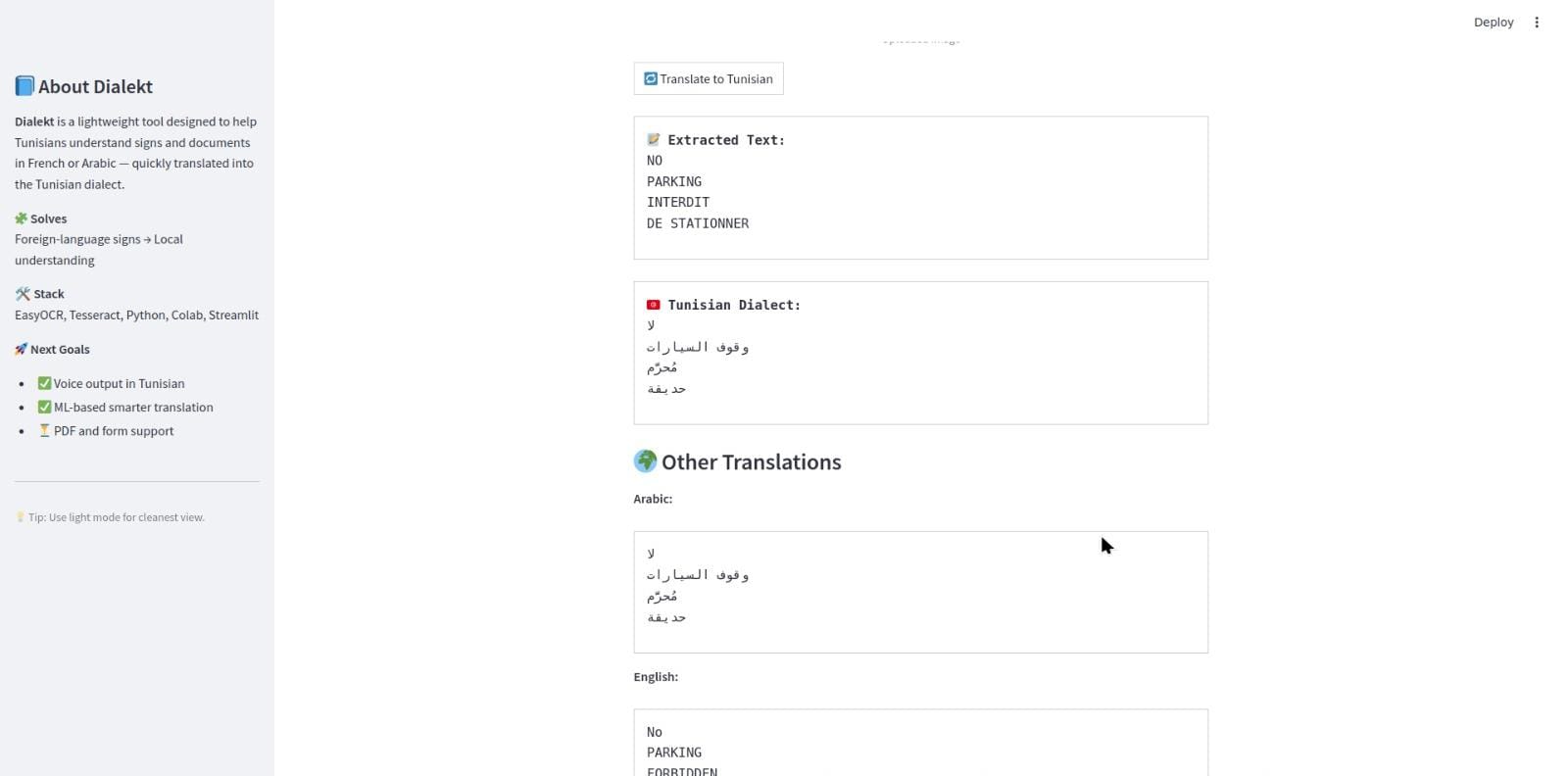
Here is the translation
-
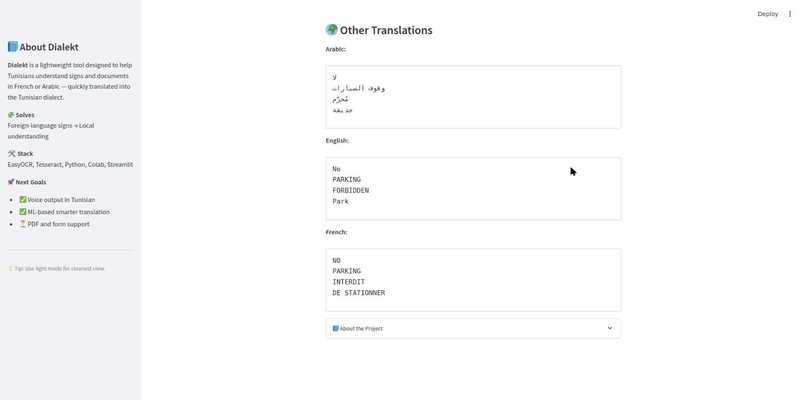
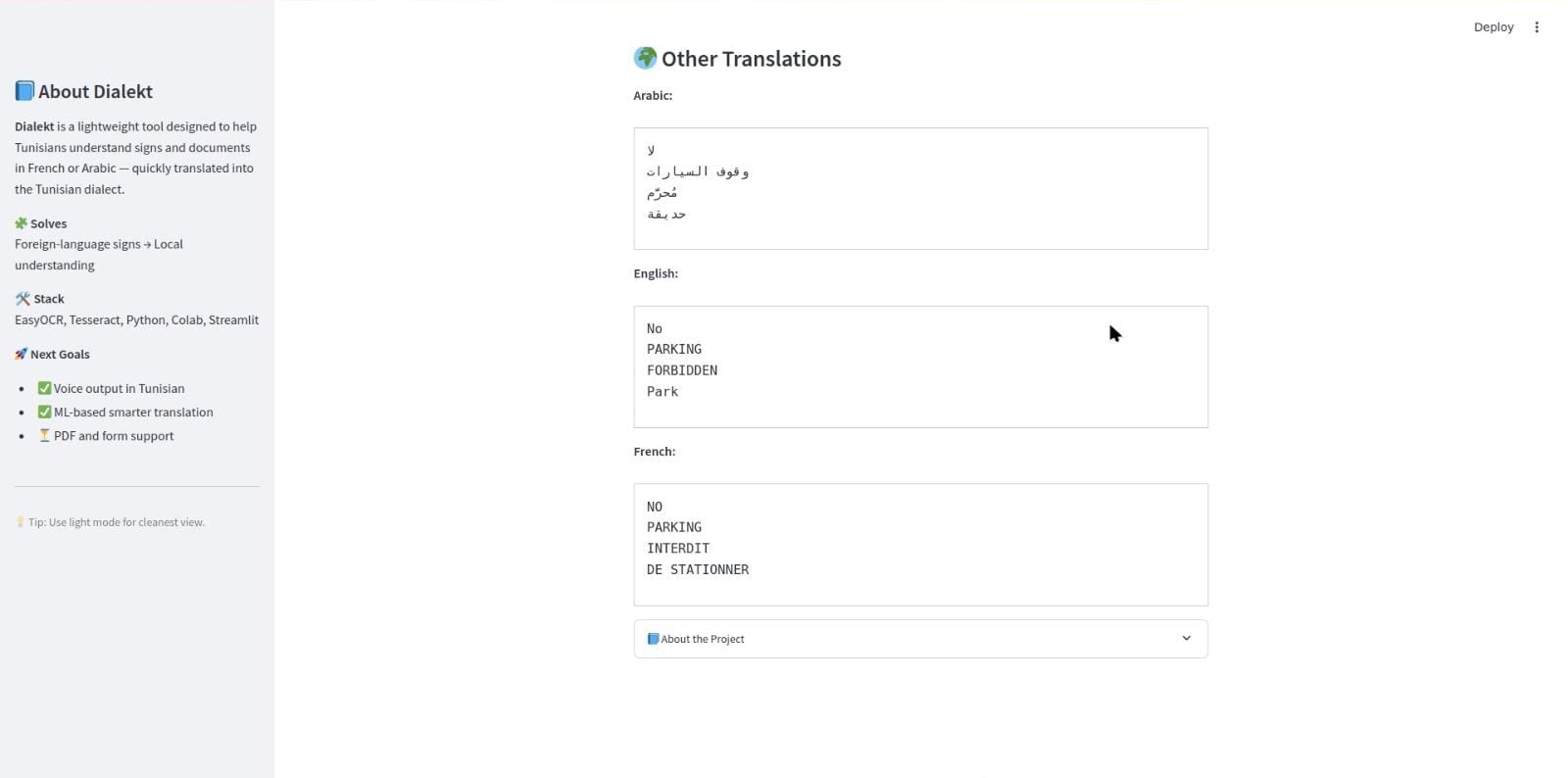
Same here is the translation
Inspiration
While building for a hackathon, we wanted to solve something real. In Tunisia, most public signs and forms are in French or Arabic, but many locals don’t fully understand them. So we thought — why not build something that reads those signs and shows them in Tunisian dialect? A simple idea that can actually help.
What It Does
Dialekt is a small tool that:
- Takes an image of any sign, board, or document
- Reads the text in French or Arabic using OCR
- Translates it to Tunisian dialect
- Shows it in a clean and simple interface
It’s built to be lightweight, fast, and easy to use.
How We Built It
- Used Tesseract OCR to get text from images
- Made a custom rule-based translator (French to Tunisian)
- Ran the backend on Google Colab, exposed with ngrok
- Built the frontend using Streamlit
- Styled it using basic CSS to keep the layout clean and modern
Challenges We Faced
- OCR didn’t work well with poor quality or stylized fonts
- Translating to a dialect (not a full language) took manual work
- Streamlit UI was limited — had to tweak it using CSS
- Had to keep everything minimal due to time and resource limits
Accomplishments
- Fully working flow: upload → extract → translate → show
- Runs completely on Colab — no setup needed
- Solves a real local problem with a working MVP
- Made a clean UI inside Streamlit without using extra tools
- Sometimes the link (streamlit) may not work because i am using ngrok to connect both backend and the frontend so it may change.
What We Learned
- How OCR tools like Tesseract actually work
- Why keeping things local and simple makes a difference
- How to customize Streamlit beyond its defaults
- That even small, focused ideas can create real value
What’s Next
- Add voice output in Tunisian
- Improve translation using ML
- Support more content like legal forms and admin papers
- Make the UI mobile-friendly
- Package it as a PWA or native mobile app


Log in or sign up for Devpost to join the conversation.