-
-
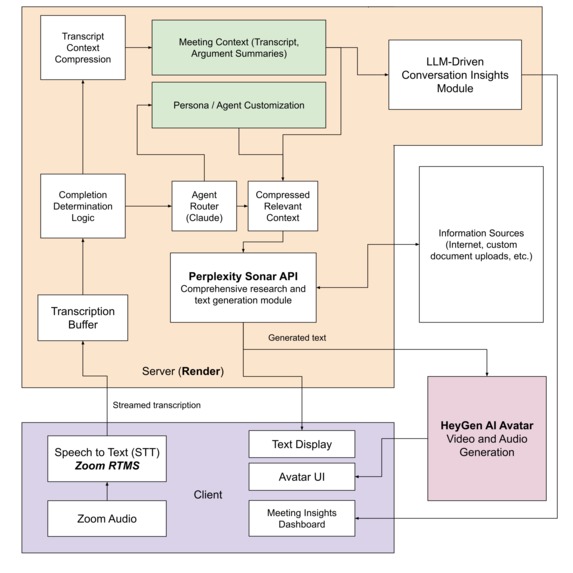
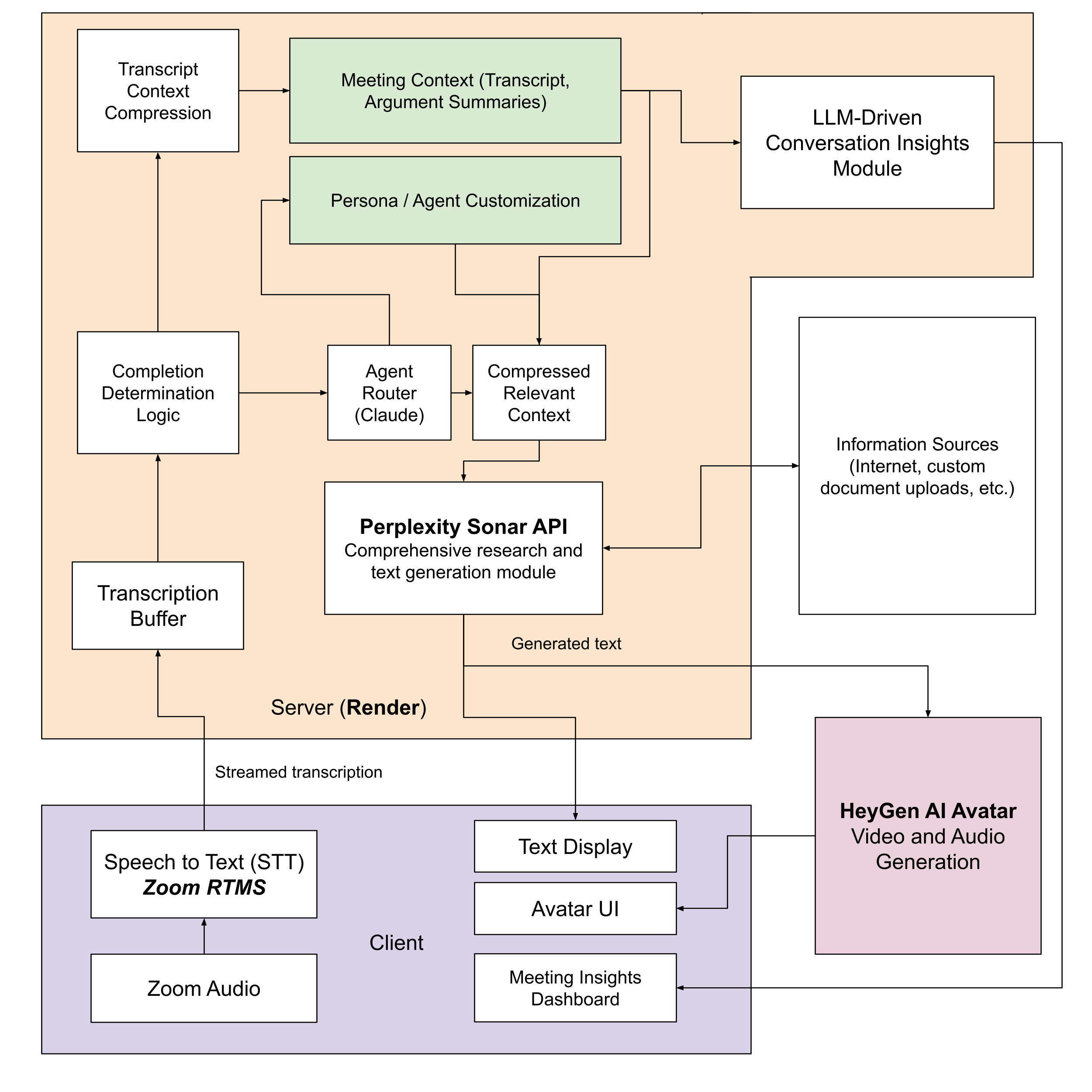
High-level system architecture
-
Homepage
-
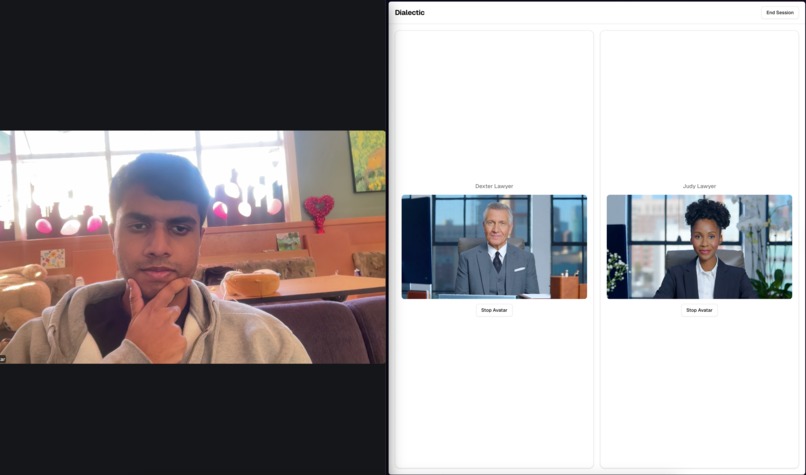
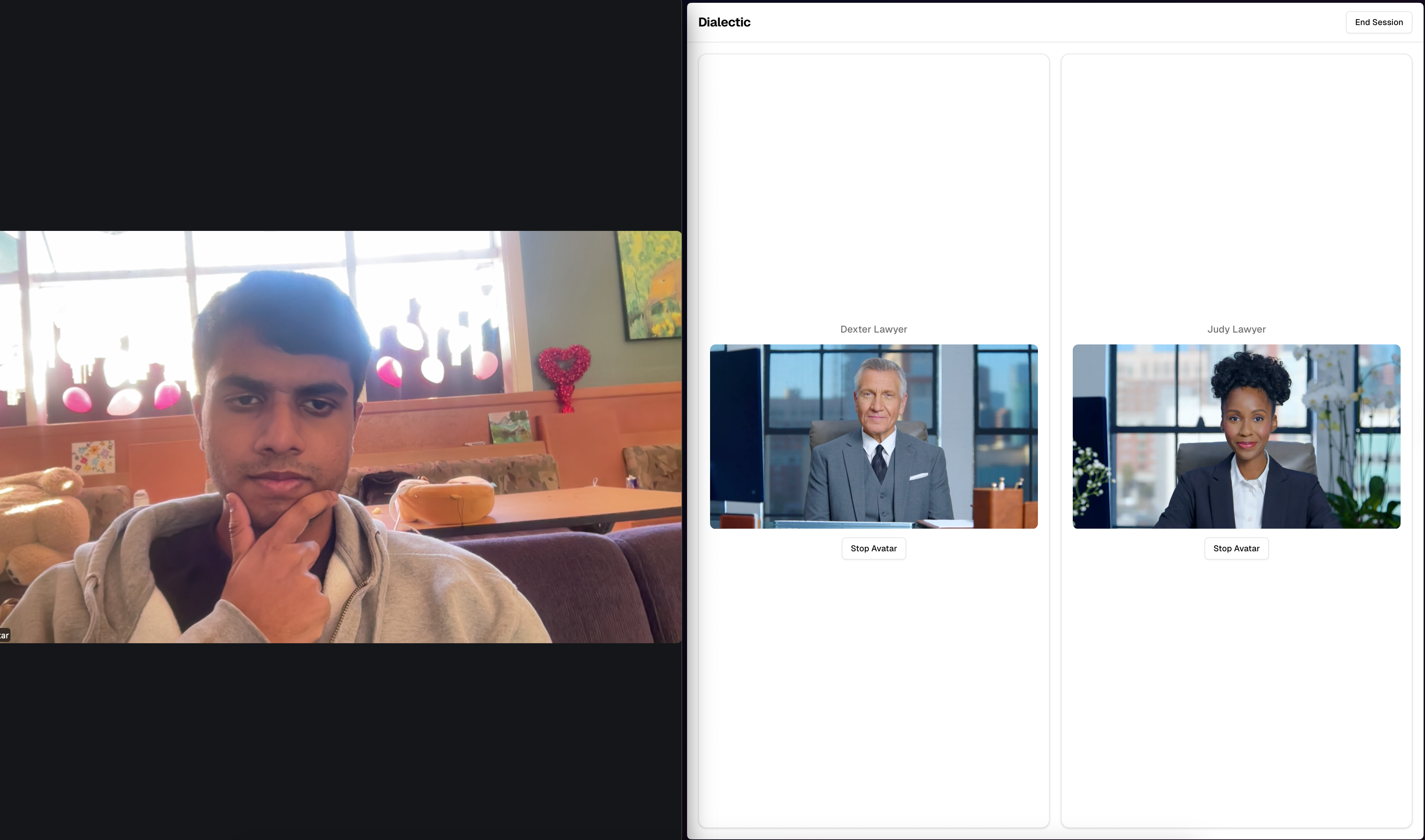
Live interaction between student and AI avatar personas
-
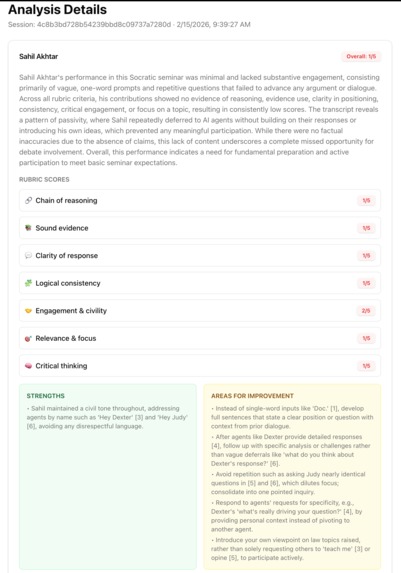
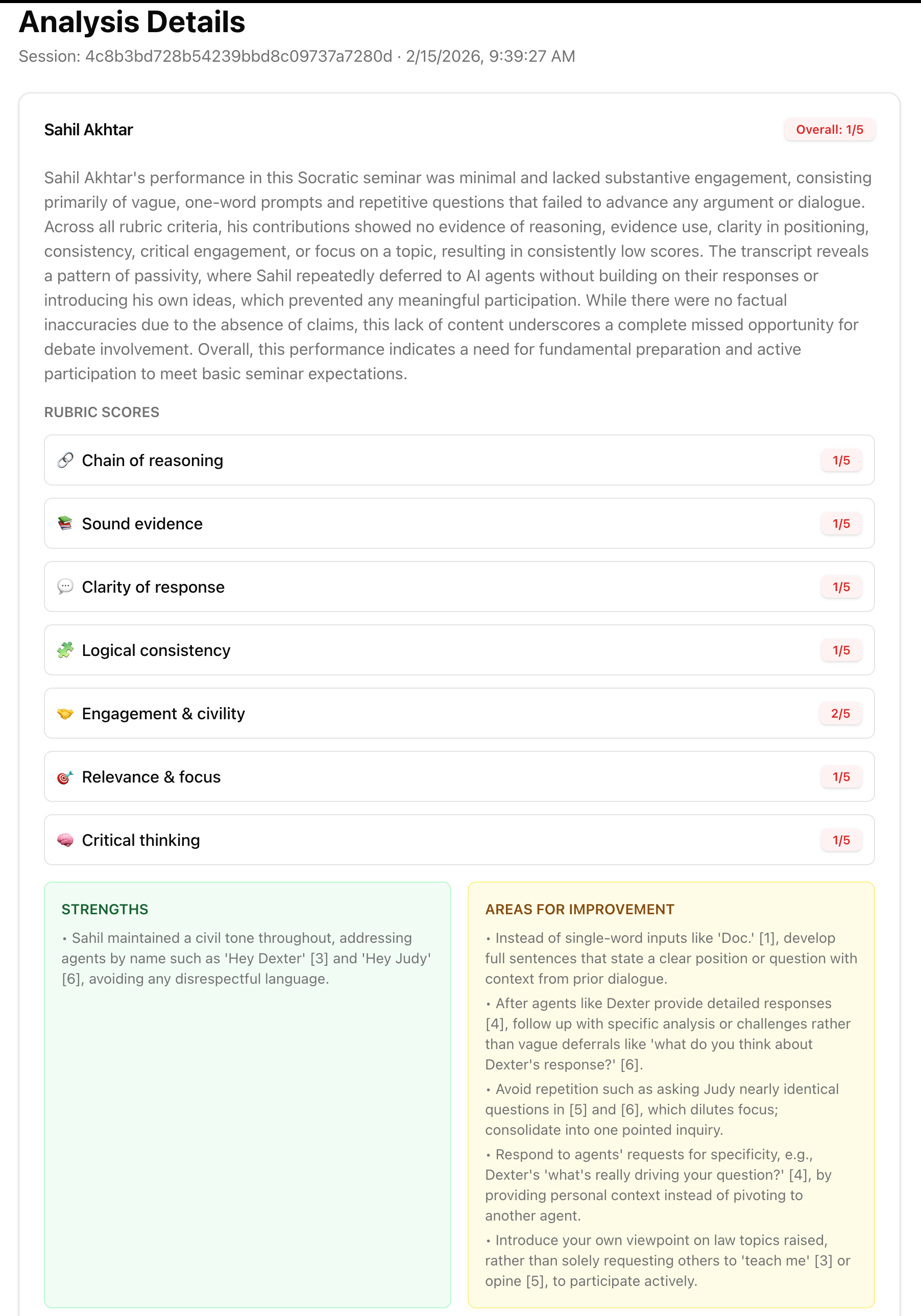
Post-seminar analysis dashboard for student performance
Dialectic
The world's thinkers, one conversation away.
Inspiration
The Socratic method works because it forces students to defend what they think they know. The problem is that in most classrooms, that dialogue happens with a teacher or a textbook, not with the people whose ideas are actually being studied. We started wondering what it would look like if a student studying the ethics of war could argue their position with Sun Tzu directly, or if a philosophy class could have Socrates question them in real time rather than just reading his words on a page. Education research consistently shows that active dialogue produces deeper retention and critical thinking than passive instruction — but genuinely interactive dialogue with historical figures has never been possible at scale. The tools to try this (AI agents, real-time avatar rendering, Zoom RTMS integration) have gotten good enough that it felt worth attempting. So we built it.
What We Built
Dialectic is a Zoom-based platform where students hold live spoken conversations with AI-powered personas that are historical, current, or role-based. A teacher sets up a session, picks a persona (Socrates, Marie Curie, Abraham Lincoln, whoever fits the lesson), and students join a normal Zoom call. The figure appears in a dedicated avatar component alongside the call, listens to what students say, and responds in character based on that person's documented views, writing style, and historical context. A few things power this under the hood. Each persona runs as its own AI agent, built with the figure's known positions, rhetorical patterns, and historical context loaded in. Multiple agents can be active at once and share enough context to respond to each other, not just to students. Each agent also has access to a live Perplexity Sonar API research pipeline, so when a student asks something that needs factual grounding, the agent can retrieve sourced, up-to-date information and incorporate it rather than guessing. The responses get streamed to HeyGen's Avatar API, which generates a photorealistic lip-synced video of the figure speaking in real time. Teachers can configure each persona before the session: subject focus, era constraints, how aggressively the figure uses the Socratic method. A Cold War history class could run two agents at once, one representing Harry Truman and his containment doctrine and one representing Soviet leaders and their expansionist policies, and have them debate while students moderate.
How We Built It
The core engineering problem was building a pipeline tight enough to feel like a real conversation. Every stage — speech input and transcription via the Zoom RTMS, AI inference, Perplexity Sonar retrieval, text synthesis, and HeyGen avatar rendering — had to complete quickly enough that the back-and-forth didn't feel awkward or delayed.
Multi-Agent Persona Orchestration
Each persona is a discrete agent with a spec that encodes the figure's worldview, rhetorical habits, known contradictions, and historical moment. An orchestration layer routes student input to the right agent and manages turn-taking. When multiple figures are in the same session, it also manages a shared context window so agents can follow and respond to each other's outputs without losing their individual voice. Each agent reasons over the full conversation history across turns — tracking what's been claimed, challenged, and conceded — to dynamically decide how to engage next.
Grounded Research via Perplexity Sonar API
When a student raises a factual claim or asks something that needs specific knowledge, the agent fires a structured Perplexity Sonar query, gets source-backed results, and folds them into a persona-consistent response. Retrieval is conditional, not always-on — the agent determines whether a question requires a live lookup or can be answered from the persona's pre-loaded context, keeping latency low on the fast path and engaging Sonar when accuracy is on the line. This was critical for keeping figures accurate on questions where confabulation would be obvious and actively harmful in an educational context.
HeyGen Real-Time Avatar Rendering
Response text gets streamed to HeyGen's Avatar API, which returns a photorealistic lip-synced video of the figure, rendered in a dedicated component alongside the Zoom session. Most of our latency optimization work happened at the interface between text generation and avatar rendering, since that's where the most time was being lost. We addressed this through token-level streaming — sending text to HeyGen as it's generated rather than waiting for the full response — which made the experience feel significantly more live.
Zoom RTMS Integration
We used the Zoom RTMS functionality to capture and transcribe human speakers in real time, feeding student speech directly into our agent pipeline. Zoom RTMS handles the live meeting layer while our Render-hosted backend handles all agent computation — AI inference including Perplexity Sonar, context management, and avatar rendering coordination — keeping the two concerns cleanly separated and independently scalable. Integrating real-time transcription from the Zoom client with server-side agent execution proved to be one of our harder architectural challenges.
Challenges We Ran Into
Latency
Chaining inference, retrieval, rendering, and response delivery into something that feels live was harder than it seemed. Any single slow stage breaks the conversational feel. We iterated on the architecture several times, adding response streaming, making Perplexity retrieval conditional rather than always-on, and doing some pre-generation where we could predict the shape of a response early. We got it to a reasonable range but there's still work to do here.
Zoom RTMS integration
Synchronizing real-time transcription from the Zoom RTMS with server-side agent execution took significantly more work than we expected. RTMS has some undocumented behaviors that we had to work through manually, and this ate more time than any other single part of the project.
What We Learned
Going in, we had a decent understanding of the individual pieces. What we underestimated was how much of the real work lives in the integration layer. Getting LLM agents, a Perplexity Sonar retrieval pipeline, HeyGen's avatar API, and the Zoom RTMS to work together reliably in real time is a different kind of problem than building any one of them on its own. It pushed us to think much more carefully about pipeline design, failure modes, and where latency actually accumulates. We also got a lot of hands-on experience with prompt engineering for long-context persona consistency, designing multi-agent systems where agents need to share state, and building complex and API-driven streaming pipelines.
What's Next
The immediate priorities are bringing latency down further and expanding the persona library. Beyond that, we want to run an actual pilot with a few teachers and get feedback from students who use it in a real class. The platform is general enough to work across subjects (history, philosophy, science, literature) but we want to understand where the format is most useful before trying to broaden it too quickly. We would also like to further extend the app's features, maybe even adding widgets or pop-ups when agents cite various sources or perform other analyses. This also extends to adding further tools for analyzing conversation transcripts after meetings, which could be integrated into a more comprehensive teacher dashboard for tracking insights about students and their progress.
Built With
- claude
- heygen
- javascript
- perplexity
- render
- typescript
- zoom


Log in or sign up for Devpost to join the conversation.