-
-
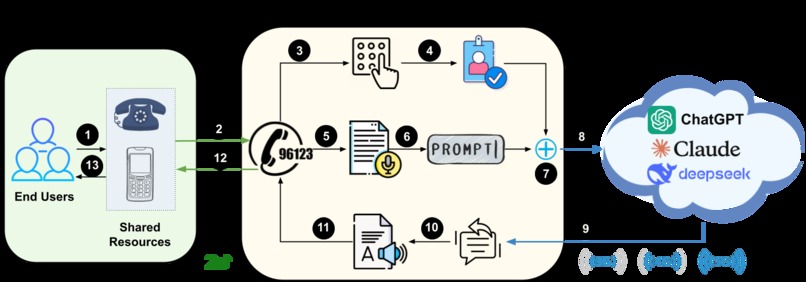
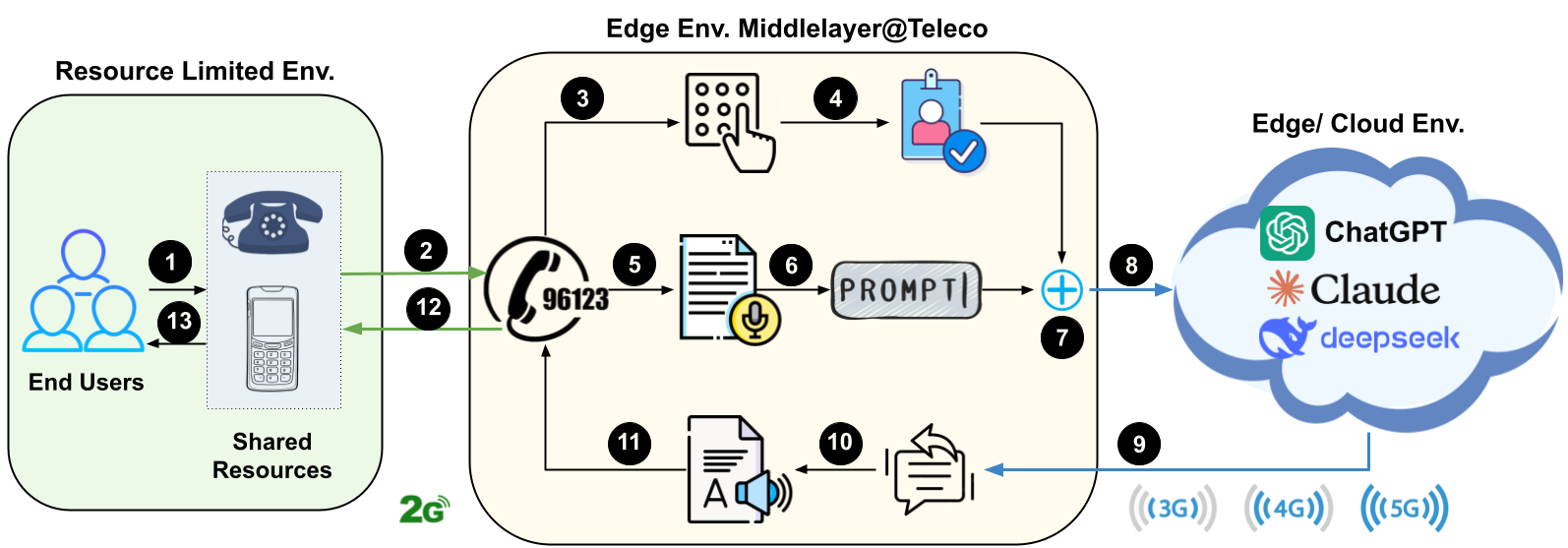
Overall Flow
-
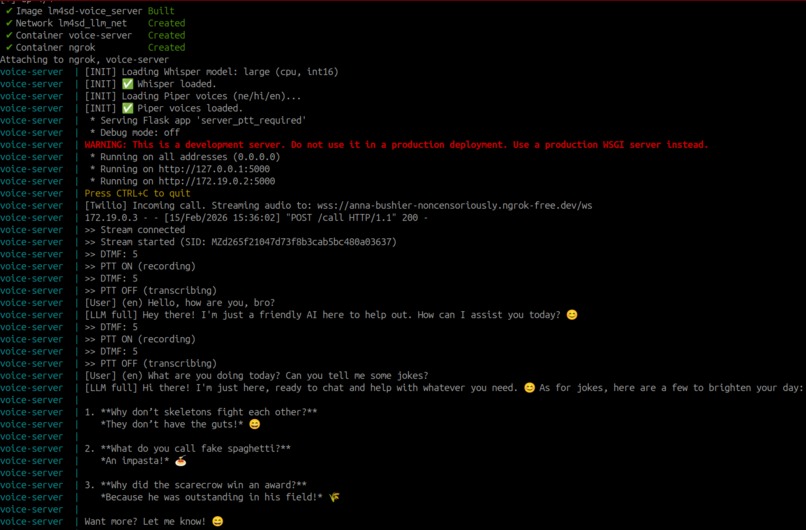
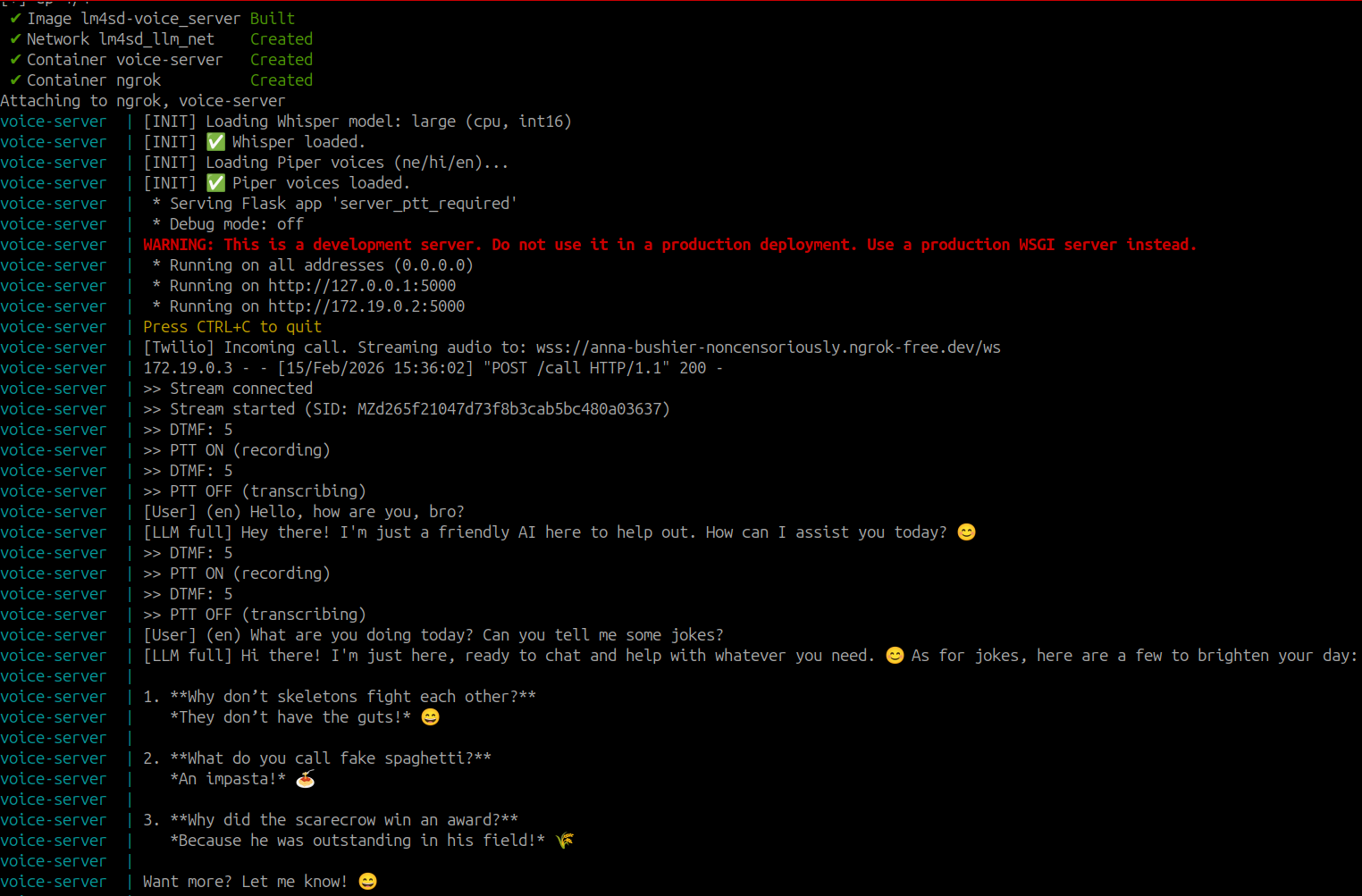
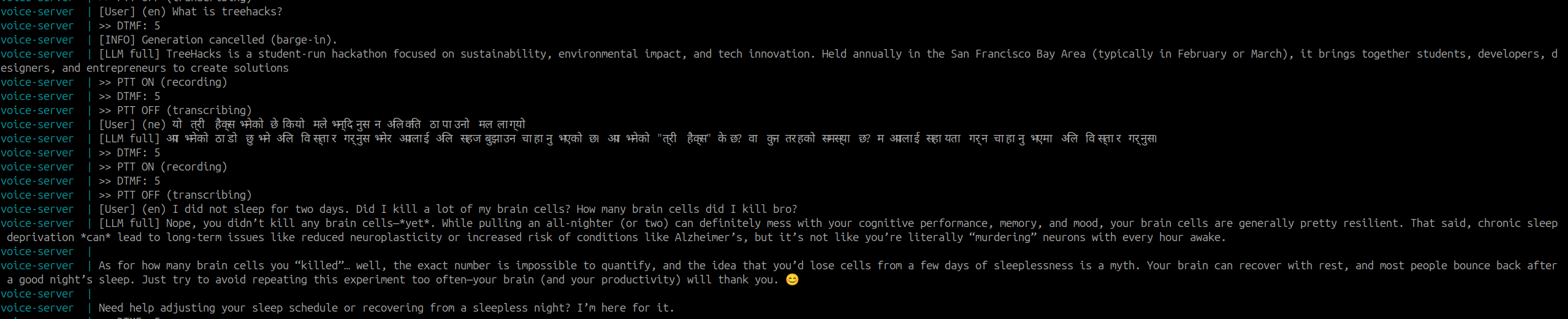
General English Questions
-
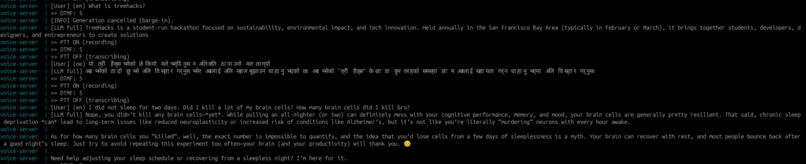
General English Q&As
-
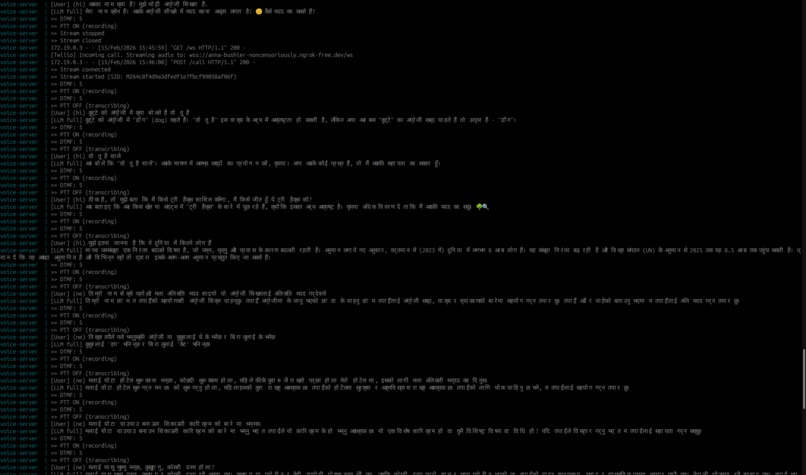
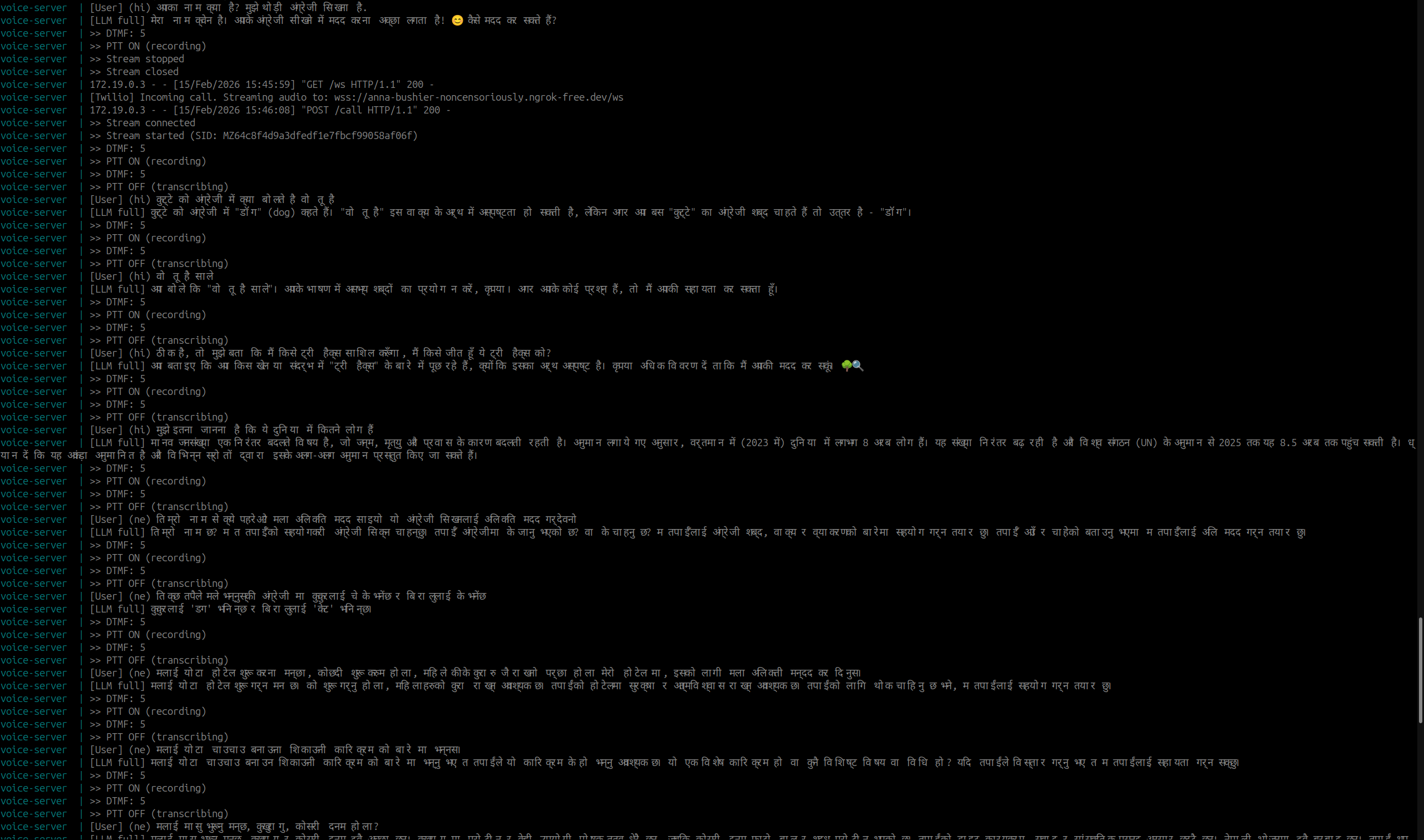
Multilingual Conversations with Q&A (Hindi & Nepali)
DialAI: From any phone, to expert answers
Inspiration
Millions of people still rely on basic phones or have unreliable/expensive internet. That creates a “voice gap”: not all people can access high-quality information when they need it (health, farming, education, legal aid, disaster help). This project is inspired by the idea that a normal phone call should be enough to access an AI assistant, without requiring a smartphone, apps, or data plans.
Also, brainstormed the fairness angle: if AI access is expensive, communities should be able to share access responsibly through quotas and shared plans, similar to how public utilities are managed.
What it does
DialAI lets anyone dial a phone number and talk to an AI assistant.
- Works through a simple voice call (no smartphone required).
- Converts speech → text, the text serves as prompts with added prompt engineering efforts, sends it to a locally at the edge or remotely cloud deployed language model, response text → speech, and speaks the answer back.
- Supports local languages (depending on speech + text-to-speech (TTS) support).
- Includes an access control + quota layer so communities can share limited resources fairly.
At a high level, we optimize for low connectivity and cost. You can think of it as minimizing the barrier: Access Barrier≈Phone Requirement+Data Requirement+App Requirement
DialAI drives “data requirement” and “app requirement” close to zero by making the interface voice-only over GSM/VoIP at the end user's side.
How we built it
Our system is a simple pipeline:
Call Ingestion (Telephony) We used a telephony layer (e.g., Twilio or equivalent) to receive incoming calls and stream audio.
Speech-to-Text (STT) Incoming audio is transcribed into text using an STT model (e.g., Faster Whisper). This gives us the user’s intent in text form.
Prompting + Safety Layer We add lightweight prompt formatting to keep responses clear, short, and voice-friendly (e.g., structured Q&As, ask one follow-up question if needed). We also apply basic safety rules (avoid harmful instructions, keep medical advice cautious, etc.).
LLM Response (Locally Deployed Models at Telecoms or the Cloud-based Model APIs) The transcribed text is sent to an LLM API to generate an answer.
Text-to-Speech (TTS) The answer is converted back into speech and played to the caller.
Identity + Quotas (IAM) [Optional] We maintain simple identity (caller ID / PIN) and policy enforcement (daily minutes, per-user limits) in a small database.
Challenges we ran into
1. Latency: A voice pipeline can feel slow (STT + LLM + TTS). We had to keep answers concise and tune the flow with optimization at each component so the user doesn’t feel “stuck waiting.”
2. Noisy audio + accents: Call audio quality varies a lot. Transcription errors increase with background noise, weak signals, and code-switching between languages.
3. Conversation design for voice: Voice UX is different than chat UX. Long answers are painful. We had to learn how to produce short, structured, “spoken” answers. And, if requested, be able to easily interrupt the responses, and initiate new responses.
4. Abuse + safety: Even a simple voice agent needs guardrails (prompt injection attempts, unsafe requests, spam calls). We added basic filtering and logging hooks, which further requires much more policies and enforcement based on community policies.
5. Fair usage: If usage is shared, quotas and policy enforcement become essential so one caller can’t drain the system for everyone. This will be explored as a co-design study with members from the communities.
Accomplishments that we're proud of
- Explored various open-sourced models (Gemma, Qwen, Llama) and their variants to better map the tradeoff spaces in terms of the multilingual support, model resource needs (memory, compute), model response quality and accuracy.
- Built an end-to-end (E2E) prototype where a user can call, speak naturally, and hear an AI response, all without having to be connected to the Internet or have an advanced smartphone.
- Designed answers to be voice-first: short, readable, and helpful even on low-quality audio calls.
- Created a foundation that can be deployed as a community/shared service (schools, clinics, municipalities, co-ops).
What we learned
Voice is the real UI: The best model is not enough, factors such as response length, pacing, and clarity matter more than fancy features when trying to design for resource and infra-constrained minority underrepresented communities.
Reliability beats complexity: Simple safeguards (timeouts, retries, fallback prompts) make the experience feel much more “real.”
Fairness is a product feature: Quotas and identity are not “extra add-ons”, they are all required for long-term service sustainability.
Practical lessons about integrating telephony, streaming audio (encoding and decoding with phone audio calls), STT/TTS, and handling edge cases like silence, interruptions, and dropped calls.
What's next for DialAI: From any phone, to expert answers
Reduce latency with streaming STT/TTS and partial-response playback (start speaking while generation continues).
Offline / edge options: run smaller local models at the edge on SBCs (Raspberry Pis, Jetson boards) deployed at Telecoms (the other side of edge computing) when backhaul is unreliable, and fall back to cloud when available.
Stronger trust & safety: better moderation, abuse detection, and privacy controls to be co-designed with the communities (clear retention policy, anonymization options).
Better personalization and privacy mechanisms: caller-ID binding + optional one-time PINs; explore voiceprint only if privacy constraints allow.
Domain packs with expert fine-tuned models: specialized modes (health triage, agriculture, education) with curated prompts and vetted information sources.
Pilot deployment: partner with a community organization to test real usage, gather feedback, and measure impact (call success rate, average latency, satisfaction).



Log in or sign up for Devpost to join the conversation.