Inspiration
Diabetic Retinopathy is one of the leading causes of preventable blindness globally, affecting millions of diabetic patients who often don't realize their vision is at risk until it's too late. Early and accurate detection can save sight but access to Specialist diagnosis is limited in many regions. We wanted to build an accessible, automated screening tool that puts early detection within reach of anyone with a retinal fundus image.
What We Learned
- How to fine-tune Swin Transformers for medical image classification
- Techniques for handling severe class imbalance in clinical datasets (WeightedRandomSampler + Focal Loss)
- The importance of contrast enhancement and augmentation for retinal images, where subtle visual differences between severity stages are clinically significant
- End-to-end ML deployment via Hugging Face Spaces
How We Built It
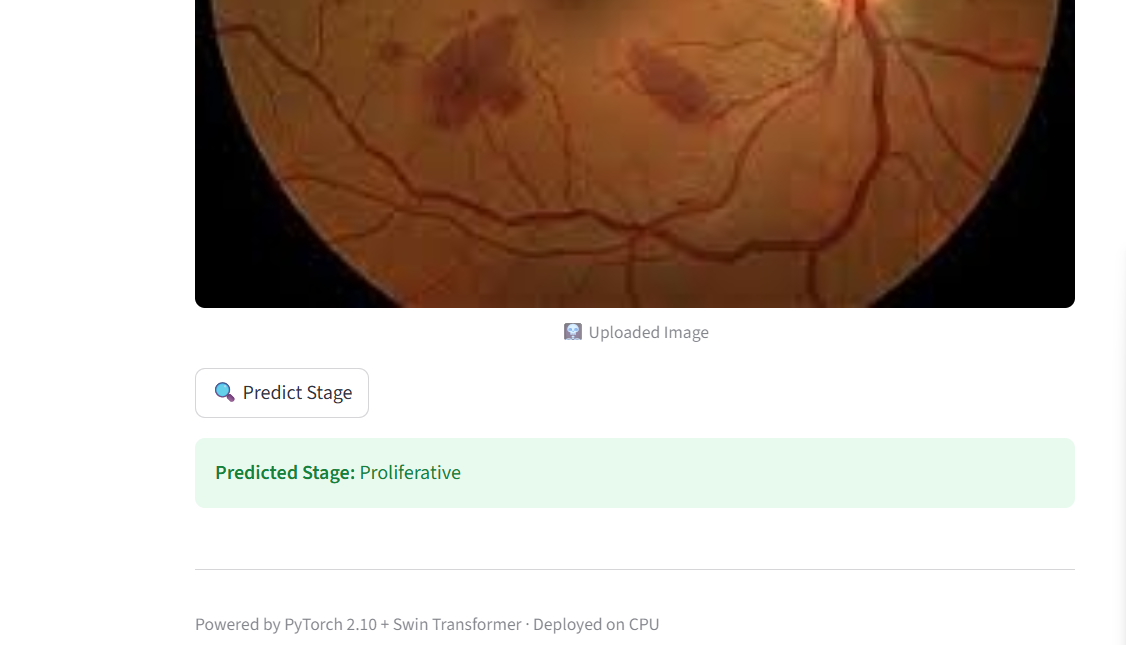
We trained a Swin Transformer (pretrained on ImageNet, fine-tuned on retinal data) to classify fundus images into 5 DR severity levels:
| Label | Stage |
|---|---|
| 0 | No DR |
| 1 | Mild |
| 2 | Moderate |
| 3 | Severe |
| 4 | Proliferative DR |
Dataset: APTOS 2019 Blindness Detection (Kaggle)
Preprocessing & Augmentation:
- Image resizing and normalization
- Contrast enhancement (CLAHE-style)
- Random geometric transforms
- ColorJitter for color-space robustness
Training Setup:
- Transfer learning with pretrained Swin weights
- Focal Loss to penalize misclassification of minority classes
- WeightedRandomSampler for balanced mini-batches
- Adaptive learning rate scheduling
- 15 epochs of fine-tuning
Result: 87% overall accuracy across all 5 severity classes
The model was then deployed as an interactive web app on Hugging Face Spaces, where users can upload any retinal fundus image and receive an instant prediction.
Challenges We Faced
- Class imbalance: The APTOS dataset is heavily skewed toward the "No DR" and "Moderate" classes. Naive training produced a model biased toward majority classes. We resolved this with Focal Loss and weighted sampling.
- Subtle inter-class differences: Stages 1–3 are visually similar, making fine-grained classification difficult even for clinicians. Careful augmentation and contrast preprocessing helped the model learn discriminative features.
- Training stability: Fine-tuning transformers on small medical datasets risks overfitting. We used adaptive LR scheduling and monitored validation metrics closely across all 15 epochs.
What's Next
- Grad-CAM visualizations to highlight the retinal regions driving each prediction
- Experiment with EfficientNet and larger ViT variants for comparison
- Expand dataset with additional public DR datasets for better generalization
- Optimize inference latency for mobile/edge deployment

Log in or sign up for Devpost to join the conversation.