Inspiration
The ability to predict a disease in its early stages is a field of active research. Diabetes, specifically is a difficult disease to predict with a decent level of accuracy. Early stage detection of the disease might be an effective way to understand the biochemical pathways linked to the disease. We intend to provide a different perspective to diabetes class detection.
What it does
As opposed to the usual way of measuring sugar levels in the blood to predicting diabetes, our model draws lines between diabetes and lipids(fats), metabolites and protein content in the human body obtained via mass spectroscopy and liquid crystallization of the tissue and blood samples.
How we built it
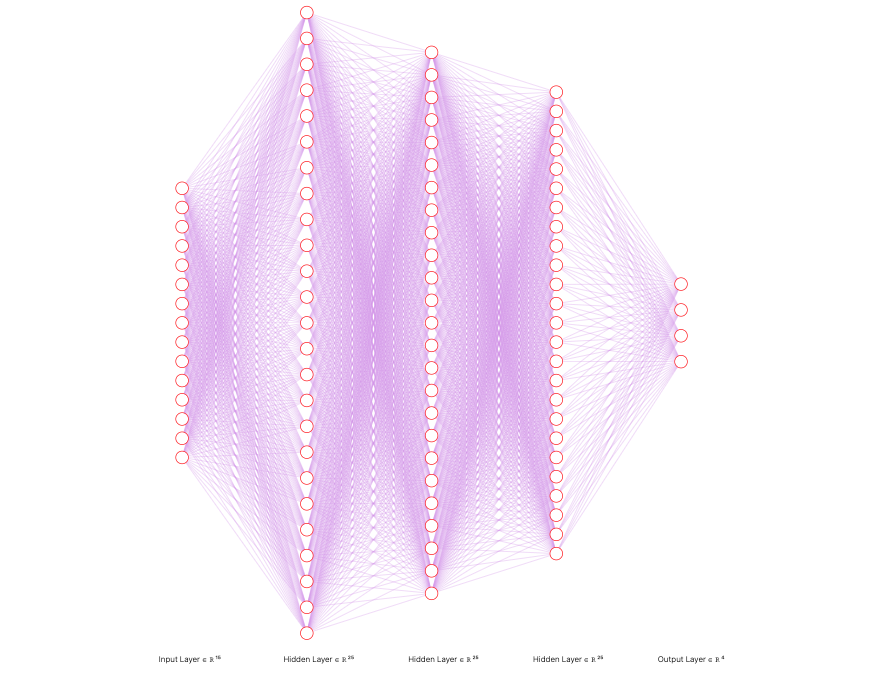
A simple ANN model -having 4 layers, is built which classifies the patient record into 4 classes - diabetic, pre-diabetic, control, and crossover. The final output layer consists of a 'softmax' activation which gives us the probability of the sample belonging to one of the classes.
Challenges we ran into
- Data integration
- Lack of R environment on IBMz platform.
- Optimizing loss
Accomplishments that we're proud of
We are happy that we got an opportunity to work with the IBMz L1CC platform and were able to explore and exploit all features that the platform provided and use it to its full potential. After trying multiple model variations, we are proud to achieve 82% accuracy in predicting the class of diabetes of a sample. We believe that the combination of ANN with multi-omics integration has huge research potential.
What we learned
We learnt about different factors and omics that may lead to diabetes. We also enhanced our knowledge about Artificial Neural networks and how to fine-tune the model.
What's next for DATAVENGERS_Team_107_diabetes_detection
We would like to explore more about the multi-omics data integration approaches and possibly achieve higher accuracy and find more influential factors which may cause diabetes.


Log in or sign up for Devpost to join the conversation.