-
-

Home_page
-
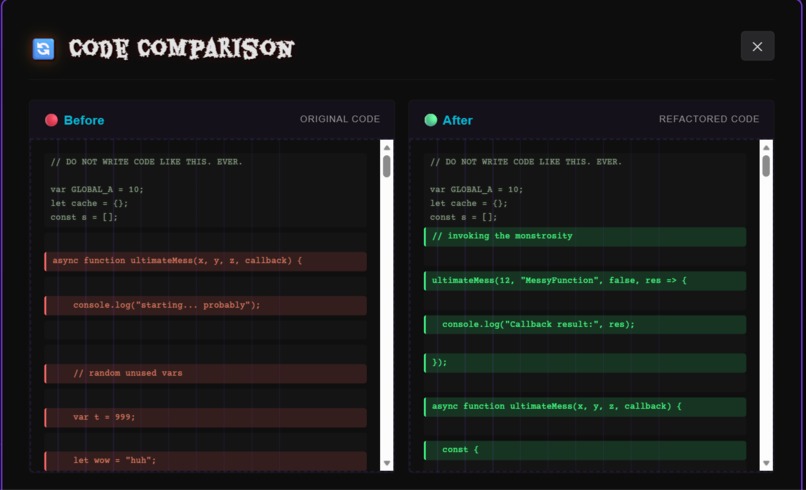
Code_compare
-

Initialization_screen
-
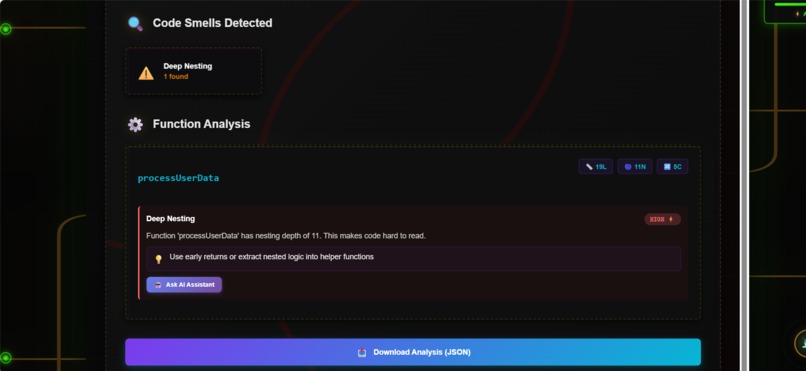
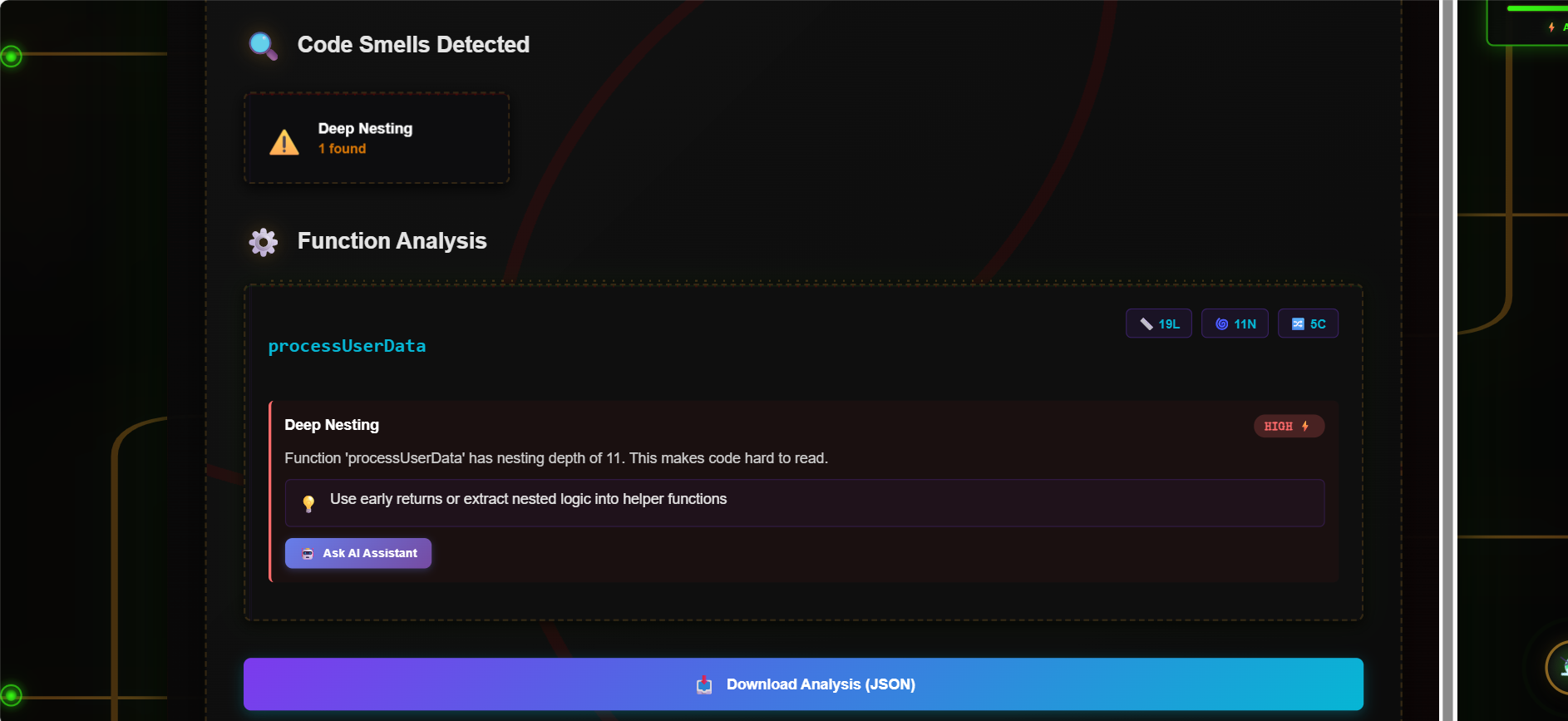
Analysis
-
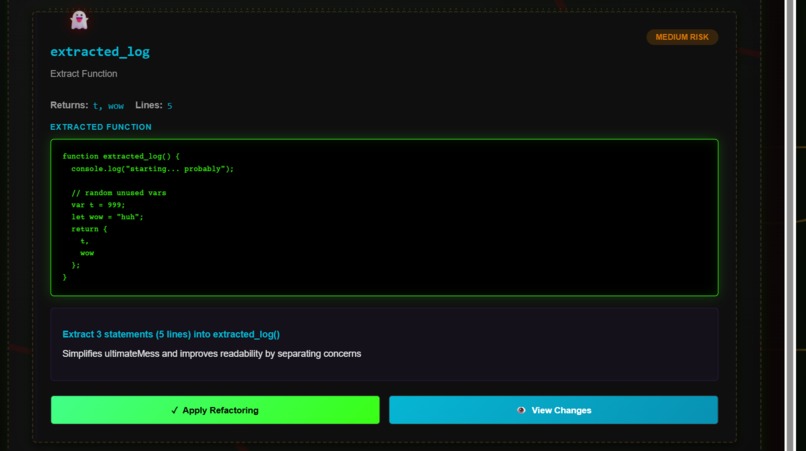
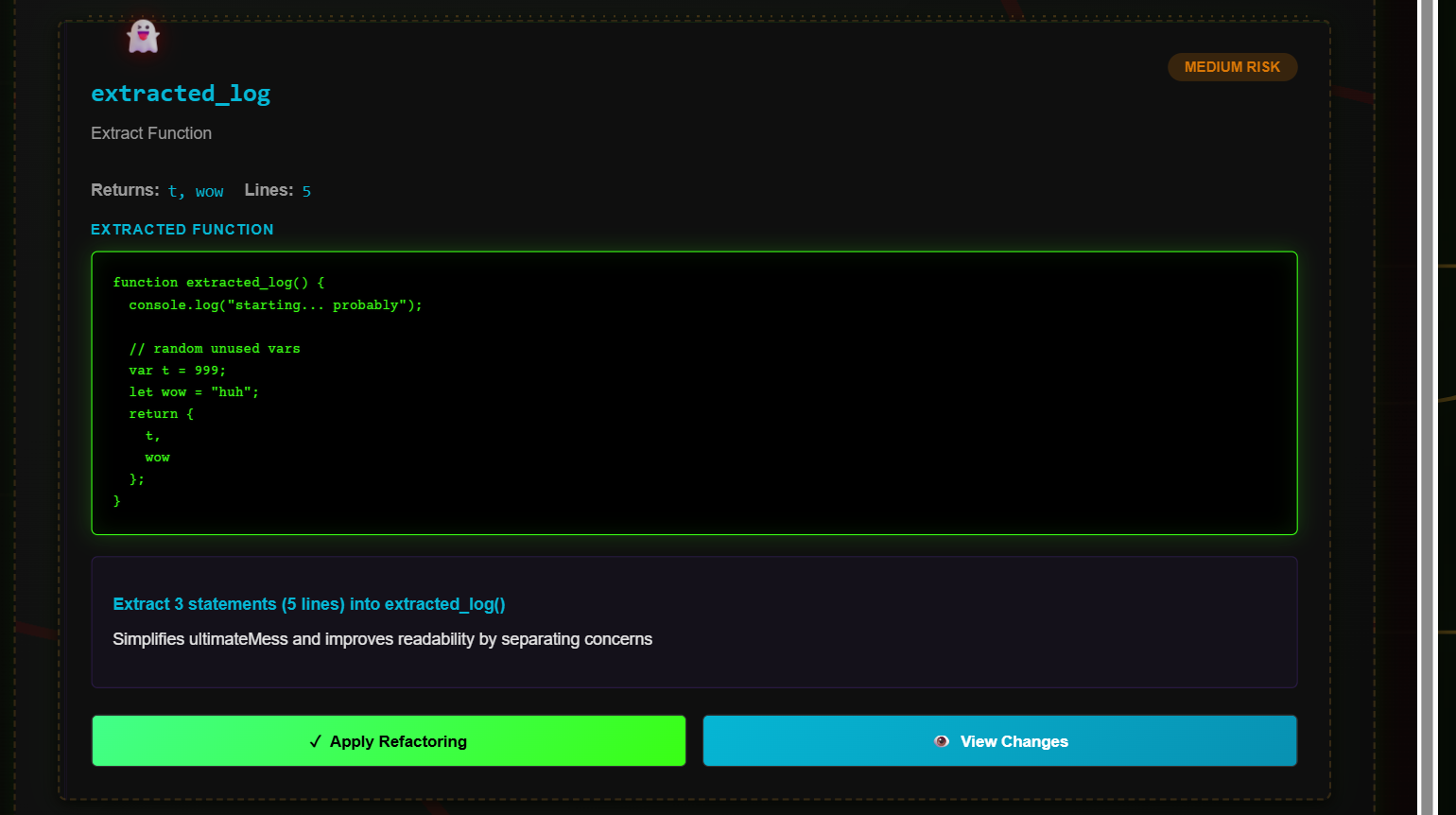
Refactoring_code
-
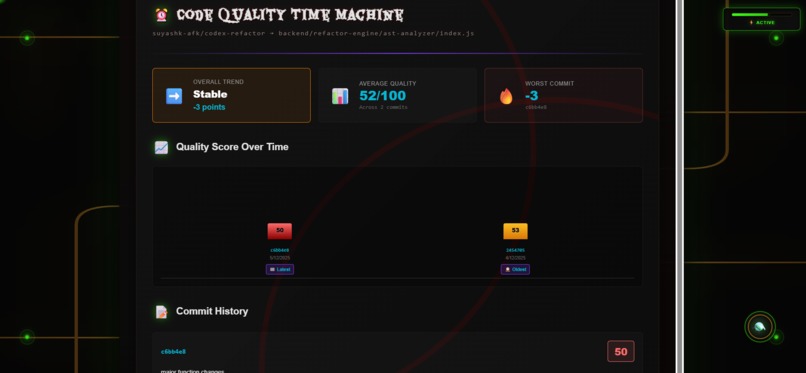
Time_machine
-
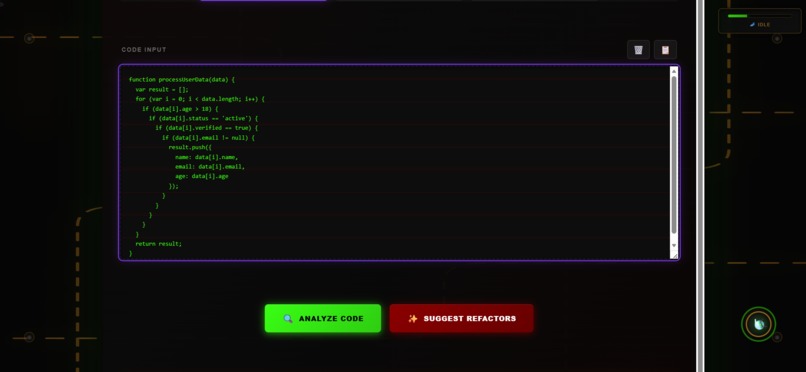
Code_snippet

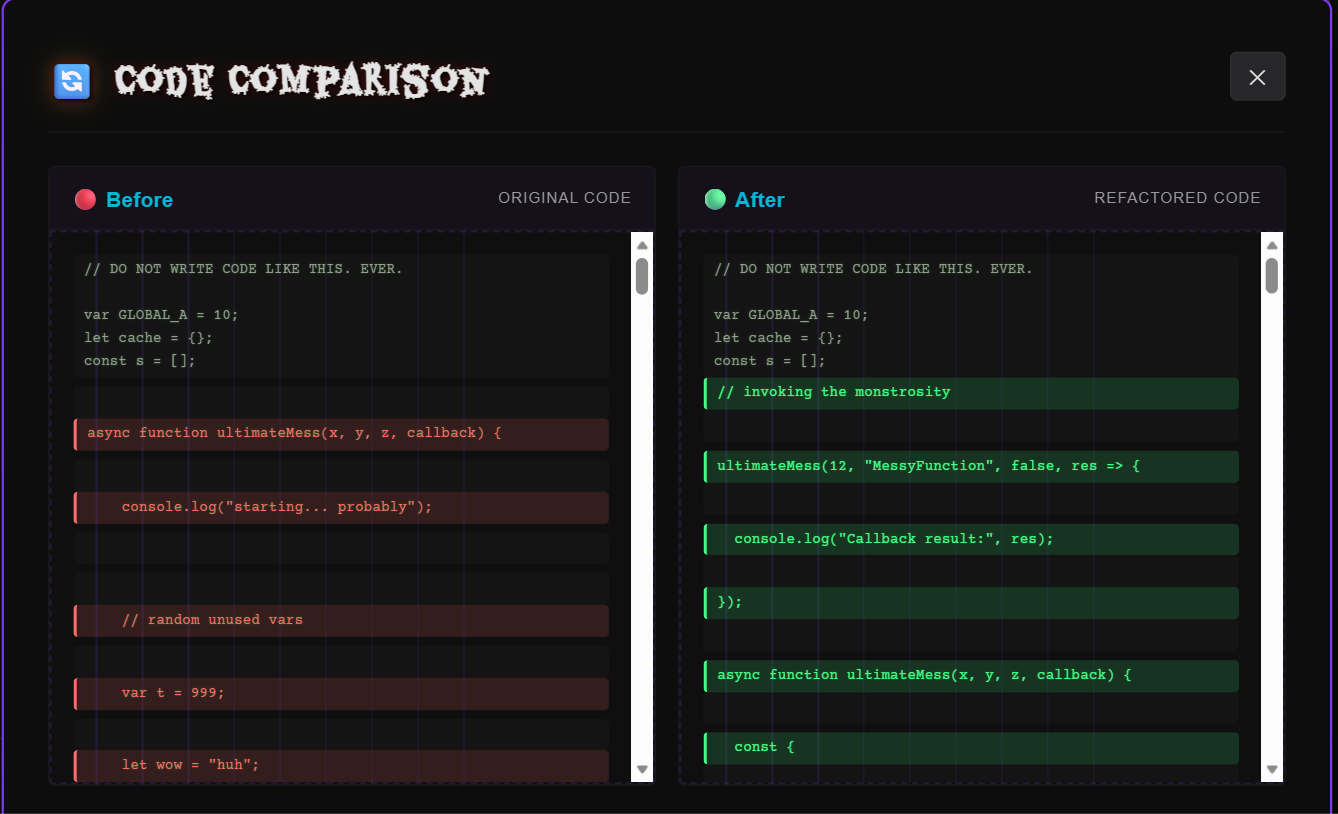


Inspiration# 🕰️ Time Machine Codex: A Journey Through Code's Past
Inspiration
When I joined the project, I wasn’t dealing with production at a big company —
I was dealing with something more common for students: a codebase built by several teams over several semesters.
Each group left their mark on it… and not always in a good way.
One part of the project kept breaking every time we added features, so I volunteered to investigate. I opened the file and immediately saw why everyone avoided it:
- deeply nested logic
- inconsistent coding styles
- patches that were added because “we just need it to work for the demo”
It wasn’t bad coding — it was student reality.
Tight deadlines, limited experience, different people each term.
I tried to understand how the code got this way.
I opened git log and git blame, but the only thing I learned was who changed what, not why or whether the change improved or worsened the code quality.
And I realized something important:
Students inherit messy code constantly, but we don’t have tools to visualize how that mess formed.
That’s when I got the idea to build a tool that tracks the evolution of code quality over time.
Not just static analysis — but a timeline:
- When did complexity increase?
- Did certain commits accidentally introduce technical debt?
- Did refactors actually improve the structure?
I stitched together Python for analysis, Node.js for the interface, MCP for connecting the pieces, and Gemini to interpret the patterns.
The goal wasn’t to create something perfect — it was to help students understand the story behind the code they inherit, instead of being lost in it like I was.
What it does
Time Machine Codex analyzes code quality across three dimensions:
1. Code Snippet Analysis
- Calculates McCabe cyclomatic complexity
- Detects code smells (deep nesting, long functions, magic numbers)
- Computes scientific toxicity scores
- Provides AI-powered refactoring suggestions
2. Repository Analysis
- Scans entire GitHub repositories
- Calculates maintainability index
- Identifies files needing attention
- Estimates technical debt in hours
3. Time Machine (Unique Feature)
- Analyzes Git commit history
- Tracks quality evolution over time
- Detects regressions automatically
- Shows which commits improved or hurt quality
All metrics are based on industry standards: McCabe's cyclomatic complexity (1976), Microsoft's Maintainability Index, and SonarQube's technical debt model.
How we built it
The Frankenstein Architecture
┌─────────────────────────────────────────────┐
│ React Frontend (JavaScript) │
│ ↓ HTTP │
│ Express Backend (Node.js) │
│ ↓ Child Process (stdio) │
│ Python Analyzer (AST) │
│ ↓ MCP Protocol │
│ Kiro IDE (AI Agent) │
│ ↓ REST API │
│ Google Gemini AI │
└─────────────────────────────────────────────┘
The challenge was making these technologies communicate. I used Node.js child processes to spawn Python analyzers, passing code through stdin and receiving results through stdout. The MCP server exposes tools that Kiro can call directly. Google Gemini provides AI insights through REST API.
Tech Stack:
- Frontend: React + Framer Motion + Tailwind
- Backend: Express.js + Python AST
- AI: Google Gemini 2.0 Flash
- Integration: MCP Protocol for Kiro
- Analysis: Babel (JS/TS) + Python
astmodule
The Scientific Foundation
McCabe Cyclomatic Complexity
The industry standard since 1976. The formula is elegant:
$$M = E - N + 2P$$
Where:
- $M$ = Cyclomatic complexity
- $E$ = Number of edges in the control flow graph
- $N$ = Number of nodes
- $P$ = Number of connected components
Simplified for practical use:
$$M = \text{decision_points} + 1$$
I implemented this properly—counting every if, for, switch, &&, ||, and catch. Not approximations. Real complexity.
Code Toxicity Model
Inspired by SonarQube's technical debt model, I created a severity-weighted toxicity score:
$$T = \sum_{i=1}^{n} (S_i \times I_i \times D_i)$$
Where:
- $S_i$ = Severity weight (Critical=10, High=5, Medium=2, Low=1)
- $I_i$ = Impact multiplier (Complexity=1.5x, Nesting=1.3x, etc.)
- $D_i$ = Density factor (smells per 100 lines)
Then normalized to 0-100:
$$\text{Toxicity} = \min\left(100, \frac{T}{L} \times 100\right)$$
Where $L$ = Total lines of code.
This approach is based on SonarQube's technical debt model.
Maintainability Index
Based on Microsoft's formula:
$$MI = \max\left(0, 100 \times \frac{171 - 5.2 \times \ln(V) - 0.23 \times G - 16.2 \times \ln(L)}{171}\right)$$
Simplified for repository-level analysis:
$$MI = 0.5 \times Q + 0.3 \times (100 - T) + 0.2 \times (100 - 5C)$$
Where:
- $Q$ = Quality score
- $T$ = Toxicity
- $C$ = Average complexity
Each metric is backed by research papers and industry standards, ensuring the analysis is meaningful and actionable.
Challenges we ran into
Challenge 1: The Python-Node.js Bridge
Problem: Python has the best AST libraries. Node.js has the best web ecosystem. They don't talk.
Solution: I used child_process.spawn() to create a bridge. The Node.js backend spawns a Python process, sends code via stdin, and receives analysis via stdout. It's hacky. It's beautiful. It works.
const python = spawn('python', ['analyzer.py']);
python.stdin.write(JSON.stringify({ code, filename }));
python.stdin.end();
Challenge 2: The Magic Numbers False Positive Nightmare
Problem: Initial testing on Lodash showed 617 code smells but a quality score of 94/100—a contradiction.
The culprit: Magic number detection was flagging every 0, 1, 2 in utility functions.
Solution: I refined the detection logic:
- Ignore common values (0, 1, 2, 10, 100, 1000)
- Ignore array indices (
arr[0]) - Ignore variable declarations (
const MAX = 100) - Only flag if 3+ magic numbers in calculations
Result: Smells dropped to realistic levels. Quality score now makes sense.
Challenge 3: The Time Machine
Problem: GitHub API rate limits. Analyzing 10+ commits could take minutes.
Solution:
- Batch requests with exponential backoff
- Cache analysis results
- Parallel processing where possible
- Smart commit selection (skip merge commits)
The math:
- 10 commits × 1 file = 10 API calls
- Rate limit: 60 requests/hour (unauthenticated)
- With caching: ~3 API calls (tree, commits, content)
Challenge 4: The Complexity Meter Calibration
Problem: A function with complexity 6 showed 60% on the meter. That's wrong—complexity 6 is moderate, not high.
Solution: I calibrated it to McCabe's thresholds:
$$\text{Meter\%} = \begin{cases} \frac{C}{4} \times 20 & \text{if } C \leq 4 \text{ (Simple)} \ 20 + \frac{C-4}{3} \times 20 & \text{if } 5 \leq C \leq 7 \text{ (Moderate)} \ 40 + \frac{C-7}{3} \times 20 & \text{if } 8 \leq C \leq 10 \text{ (Complex)} \ 60 + \frac{C-10}{10} \times 30 & \text{if } 11 \leq C \leq 20 \text{ (Very Complex)} \ \min(100, 90 + \frac{C-20}{10} \times 10) & \text{if } C > 20 \text{ (Untestable)} \end{cases}$$
Now complexity 6 shows 33%—properly calibrated to industry standards.
Accomplishments that we're proud of
The Time Machine Feature - This is the core innovation. Being able to visualize code quality evolution across Git history fills a gap that existing tools don't address. Seeing quality trends helps teams understand their technical debt trajectory.
Scientific Accuracy - Every metric uses established formulas (McCabe, Maintainability Index, severity-weighted debt). The numbers mean something and can be trusted for decision-making.
Multi-Language Support - Supporting both Python and JavaScript in a single tool required bridging two ecosystems. The solution works seamlessly.
Kiro Integration - Building MCP tools that extend Kiro's capabilities shows how AI agents can be enhanced with domain-specific analysis.
Polish - The spooky laboratory theme makes code analysis engaging rather than dry. The UI animations and effects create an experience, not just a tool.
What we learned
Technical Lessons
- Child processes are powerful - You can bridge any two languages with
stdin/stdout - AST analysis is deep - Babel and Python's
astmodule are incredibly powerful - Calibration matters - Raw metrics mean nothing without proper scaling
- False positives kill trust - One bad metric ruins credibility
Kiro Lessons
- MCP is the future - Protocol-based tool integration is brilliant
- AI agents need context - Kiro's ability to read files and execute commands is game-changing
- Iteration speed matters - Kiro helped me refactor faster than I could manually
Design Lessons
- Constraints inspire creativity - The Frankenstein theme pushed me to explore unconventional architecture
- Calibration matters - Raw metrics need proper scaling to be meaningful
- False positives erode trust - One inaccurate metric can undermine the entire tool
- User experience matters - Making analysis engaging increases adoption
What's next for Time Machine CODEX
Expanded Language Support - Add Java, C++, Rust, and Go analysis to cover more ecosystems.
Team Analytics - Compare quality trends across team members to identify patterns and share best practices.
CI/CD Integration - Add GitHub Actions and GitLab CI plugins to automatically analyze PRs and block quality regressions.
Predictive Analysis - Use machine learning to predict which files are likely to become problematic based on historical patterns.
VS Code Extension - Bring real-time analysis directly into the editor with inline suggestions.
Collaborative Features - Allow teams to annotate commits with context about why quality changed, creating institutional knowledge.
The goal is to make code quality visible, measurable, and improvable—not through enforcement, but through understanding.
Technical Implementation
Performance Optimizations
- Lazy loading - Components load on demand
- Debounced animations - Updates throttled to 100ms intervals
- Passive event listeners - Non-blocking scroll and mouse events
- Memoization - React.memo prevents unnecessary re-renders
Security
- API keys stored in
.env(gitignored) - Code analyzed in isolated child processes
- GitHub API rate limiting respected
- CORS restricted to localhost during development
Built With
- axios
- babel
- css3
- eslint
- express.js
- git
- github-api
- google-gemini-ai-api
- html5
- javascript
- json-rpc
- kiro
- model-context-protocol-(mcp)
- node.js
- postcss
- python
- python-ast
- react-19
- render
- stdio
- tailwind-css
- typescript
- vercel
- vite

Log in or sign up for Devpost to join the conversation.