-
-
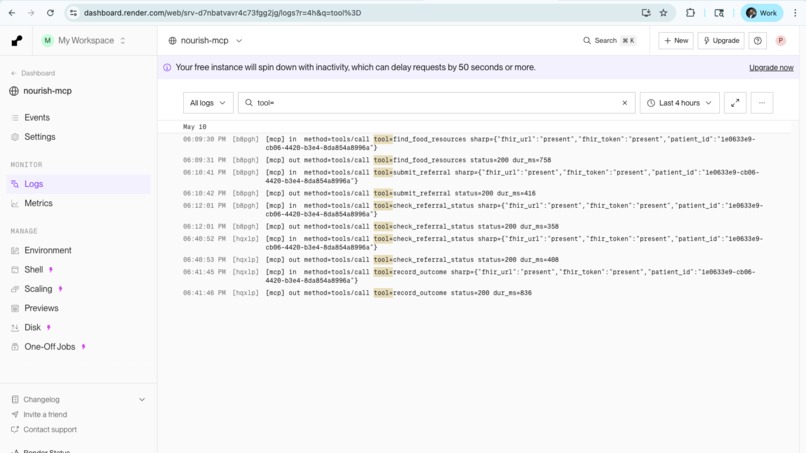
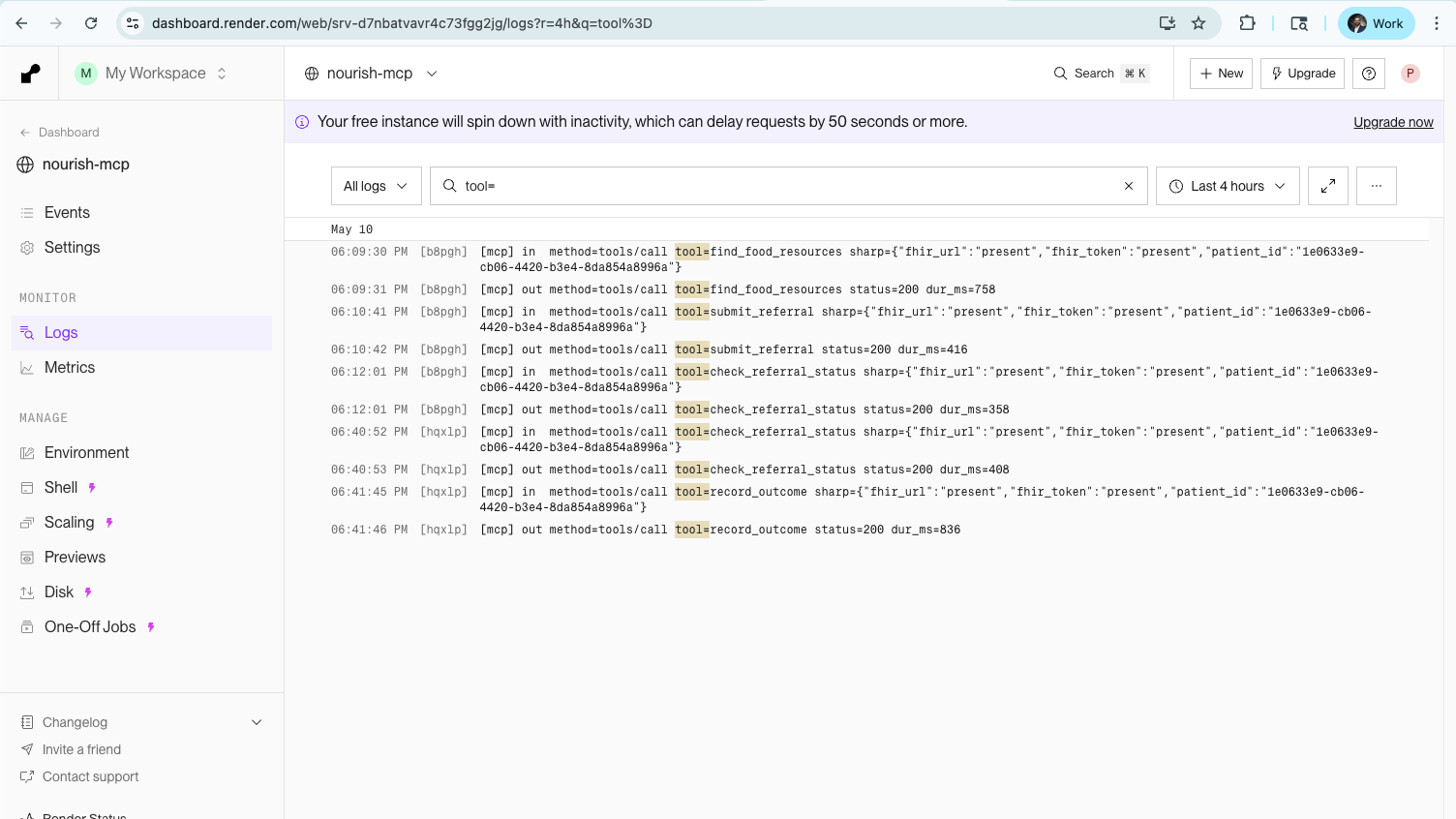
End-to-end verified. Four MCP tool calls — find, submit, check, close — fire against the live FHIR server on a paediatric patient
-

Nourish architecture — clinician → BYO agent → MCP server → FHIR R4. Four tools enforce safety as deterministic code filters, & close loop

Inspiration
The American Academy of Paediatrics now recommends screening every child for food insecurity at well-child visits. The intent is good. The follow-through is broken.
Roughly 13 million children in the United States live in food-insecure households. Paediatricians ask the screening questions, document the positives, and hand families a printed list of food pantries. Then nothing closes the loop. National research consistently shows that fewer than a third of clinical referrals to community food resources ever connect a family with food. The pantry never receives the referral. The family doesn't follow through. The doctor never finds out either way. The screening becomes a checkbox.
Meanwhile, the supply side has its own coordination problem. Pantries can't predict demand, can't match dietary or cultural needs to what's on their shelves, and have no clinical context for the families they're trying to serve. Halal, kosher, vegetarian, allergen-safe, age-appropriate infant formula, lactose-free, gluten-free, culturally familiar, these aren't preferences. They're whether the food gets eaten.
This is the last-mile gap Prompt Opinion describes. Raw clinical intelligence (the screening result) never converts into an actionable deliverable (food on the table). Nourish exists to close that gap.
What it does
Nourish is an MCP server that turns a paediatric food-insecurity screening into a closed-loop, outcomes-tracked clinical referral. It is paired with a BYO Agent on the Prompt Opinion platform that brings the tools into a clinician's workspace.
When a clinician identifies food insecurity in a paediatric encounter, Nourish exposes four MCP tools that any compliant agent can invoke from the clinician's workspace:
- find_food_resources — given the patient's location, household composition, dietary constraints, allergens, cultural preferences, and clinical urgency, returns ranked community food resources with capacity, hours, and language match.
- submit_referral — creates a FHIR ServiceRequest for the chosen resource and propagates SHARP context (patient ID, encounter, ordering provider, language, dietary flags) so the referral arrives with full clinical context.
- check_referral_status — reads the referral state through to delivery: active, completed, revoked. Flags any referral active more than 72 hours so the provider can follow up.
- record_outcome — transitions the referral to its terminal state and writes the outcome back to the chart as a FHIR Observation linked via derivedFrom to the original ServiceRequest. The next provider sees both the screening result and whether the intervention actually reached the family.
Every tool runs on FHIR R4 data structures. SHARP context handles credentials and patient continuity across the call chain. Nothing is glued together with bespoke token plumbing, that's the whole point of building on Prompt Opinion.
How I built it
I designed the server around four principles, each one earned from a previous failure mode in food-rescue and clinical-referral systems.
1. Architectural matching, not prompt-based matching. Dietary constraints, allergens, and cultural fit are enforced as typed function parameters, not free-form prompt instructions. An agent physically cannot route a peanut-containing pantry box to a family with a documented peanut allergy because the matching tool doesn't return that resource. The safety properties are proven in code: 14 tests cover peanut allergy, halal, kosher, infant formula, age window, and combined-constraint cases.
2. Closed loop or it didn't happen. Every referral creates a FHIR ServiceRequest with a state machine, active while in flight, completed on delivery, revoked on no-show or decline. The absence of a closure event is itself a signal, surfaced to the provider as a 72-hour stale flag.
3. Outcomes back in the chart. The intervention doesn't end at the pantry door. Delivery confirmation flows back as a FHIR Observation linked to the original referral, so the system can answer the only question that matters: did this child eat?
4. Standards built-in. MCP for the tool layer, A2A for cross-agent collaboration, FHIR for clinical data, SHARP for context propagation. No proprietary glue. Any compliant clinical agent can pick up Nourish tomorrow.
The stack
TypeScript in strict mode. Node 22 LTS. The official MCP SDK with Streamable HTTP transport. Express. Zod schemas for every tool input. FHIR R4 with a minimal custom client. The ai.promptopinion/fhir-context SHARP extension declaring seven scopes. Node's built-in test runner. Render for hosting. The agent is Gemini 2.5 Flash.
The seeded resource directory uses real Greater Toronto Area food relief organizations, Daily Bread, Muslim Welfare Centre, B'nai Brith Kosher Food Bank, FoodShare Toronto, Mississauga Food Bank, Yonge Street Mission, Knights Table, Welland Heritage Council, with the dietary, linguistic, and cultural diversity that population actually requires.
The end-to-end demo is real
A halal-observant Urdu-speaking family with a peanut-allergic two-year-old, screened positive at a well-child visit, gets matched to Mississauga Food Bank, Family Hub (halal-certified, peanut-free hamper, Urdu-speaking staff). The agent submits the referral, the FHIR ServiceRequest lands on the chart with a real identifier, status flips to active, status check returns the live state, outcome recording transitions to completed, and the linked Observation records the delivery. Every tool call is timestamped in the server logs. None of it is fabricated.
Challenges I ran into
The hardest problem wasn't technical. It was deciding what not to build. Food-as-Medicine touches Medicaid 1115 waivers, MA plan supplemental benefits, WIC, SNAP, school meal programs, and a dozen state-level pilots. It would have been easy to scope the agent to "everything." I scoped it ruthlessly to paediatric primary-care referrals to community-based food resources, with the loop closed at delivery confirmation. Everything else is a v2.
On the technical side, two failures actually taught me something.
Agents will fabricate tool outputs if you let them
Early on, Gemini would render confident-sounding "the referral has been submitted" responses without actually calling the underlying tool. The Show Tool Calls panel would be empty but the agent would press on, narrating fictional state. I caught this by adding structured request/response logging [mcp] lines for tool calls, [fhir] lines for the FHIR I/O underneath, and seeing the gap between what the agent said and what the server actually received.
The fix was a stronger system prompt rule "Never fake a tool result. Every factual claim about a referral's state must come from a tool you just called in this turn" combined with a "one tool call, then stop" turn-boundary rule. Once both were in place, the hallucinations stopped. The logs are the receipt: if the agent claims it submitted, there's a [fhir] POST ServiceRequest -> 201 line to prove it.
SHARP scope grammar isn't always intuitive
Initially I declared patient/ServiceRequest.cuds thinking it covered everything. It doesn't include read-by-id, so check_referral_status returned a 403 from the FHIR server. The fix was splitting into patient/ServiceRequest.rs and patient/ServiceRequest.cud, same FHIR operations, different scope grammar. A small lesson in how the SMART scope catalog actually works in practice. The Prompt Opinion platform's UI catches this for you by rendering separate checkboxes; the failure mode I hit was downstream of misreading the spec.
Modelling cultural and religious dietary fit as queryable structured data, not free text, took more time than I expected. That's where most of the difficulty in matching actually lives.
What I learned
The "AI" in Food-as-Medicine isn't really about generating anything. It's about routing, matching, and persistence, the unglamorous coordination work that determines whether a screening question becomes a meal. Generative AI's role here is to read messy clinical context, reconcile it against messy resource directories, and reason about cultural and dietary fit in ways rule-based matching can't. That reasoning step is the only place generative AI earns its keep in this workflow. Everything else is plumbing, and Prompt Opinion built that plumbing, so I didn't have to.
I also learned that observability is the difference between demo theatre and real engineering. Without server-side structured logs, you can't distinguish a working agent from a confidently hallucinating one. The cost of adding them is one afternoon. The benefit is the entire premise of the project being verifiable. Every claim Nourish makes is checkable by reading a single line in stdout.
What's next for Nourish
Three concrete extensions.
From food to full SDOH. The same closed-loop architecture extends naturally to transportation, housing stability, and utility assistance. Same MCP shape, different resource directories. Each becomes a sibling MCP server with the same architectural-matching and closed-loop properties.
Pantry-side agent. A reciprocal A2A agent on the community-organization side that surfaces incoming referrals, manages capacity, and signals back to the clinical agent, turning Nourish from a one-way pipe into a true two-sided network. Right now Nourish models the pantry as an asynchronous external system. A2A makes them a first-class participant in the loop.
Population-health view. Aggregate closure rate and outcomes data into a paediatric population-health dashboard so a health system can see, at a glance, what fraction of its food-insecure paediatric panel is actually being fed. The same FHIR resources Nourish writes for individual patients become panel-level quality measures aligned with HEDIS food-insecurity reporting.
The technology is ready. The standards are open. The kids are waiting.
Built With
- a2a
- express.js
- fhir
- fhir-r4
- gemini
- gemini-2.5-flash
- github
- mcp
- model-context-protocol
- node.js
- prompt-opinion
- render
- sharp-extension
- smart-on-fhir
- streamable-http
- typescript
- zod

Log in or sign up for Devpost to join the conversation.