Inspiration
Modern systems generate huge volumes of logs, but teams often only dig into them after something has already gone wrong. I wanted to build something that treats logs as a real-time signal—capable of surfacing unusual behavior early (error bursts, repeated failures, suspicious sequences, or unexpected patterns). The goal was to turn reactive debugging into proactive monitoring, using logs as the primary data source.
What it does
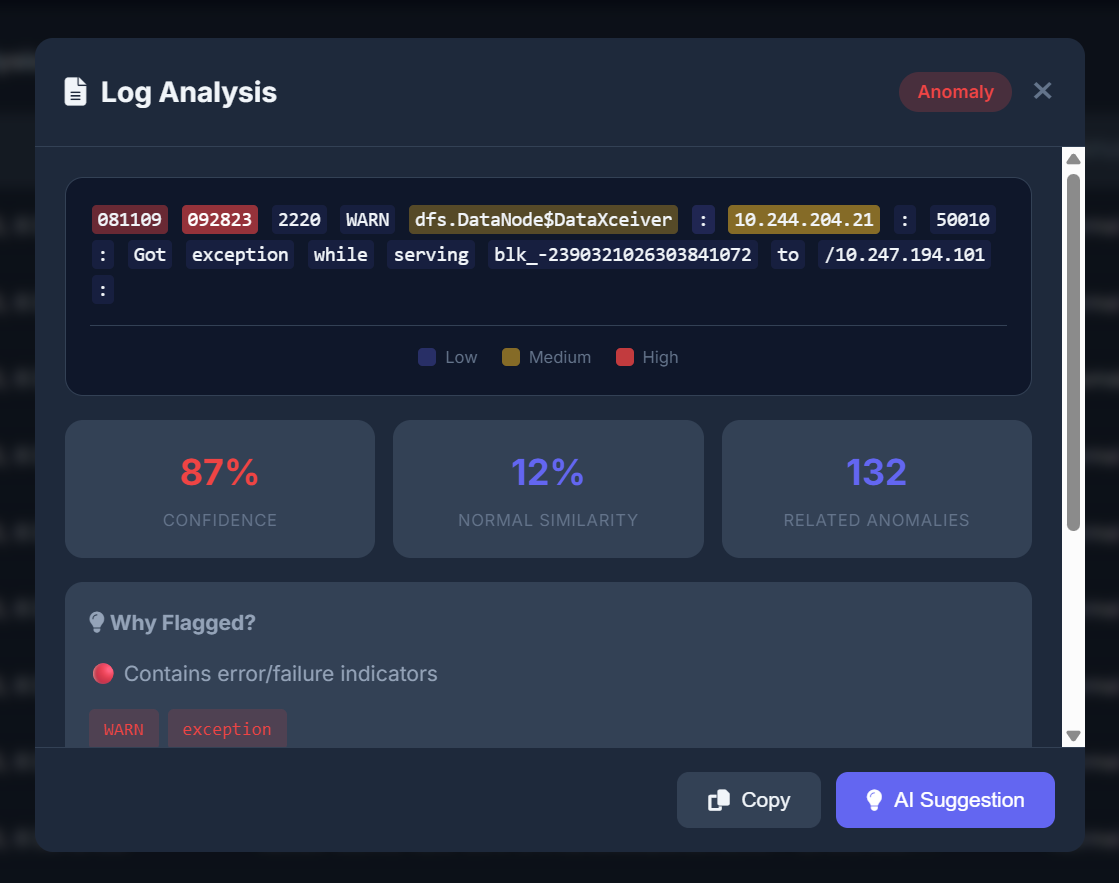
Dexter — Autonomous Log Monitoring and Anomaly Detection continuously analyzes log streams/files to detect anomalies such as:
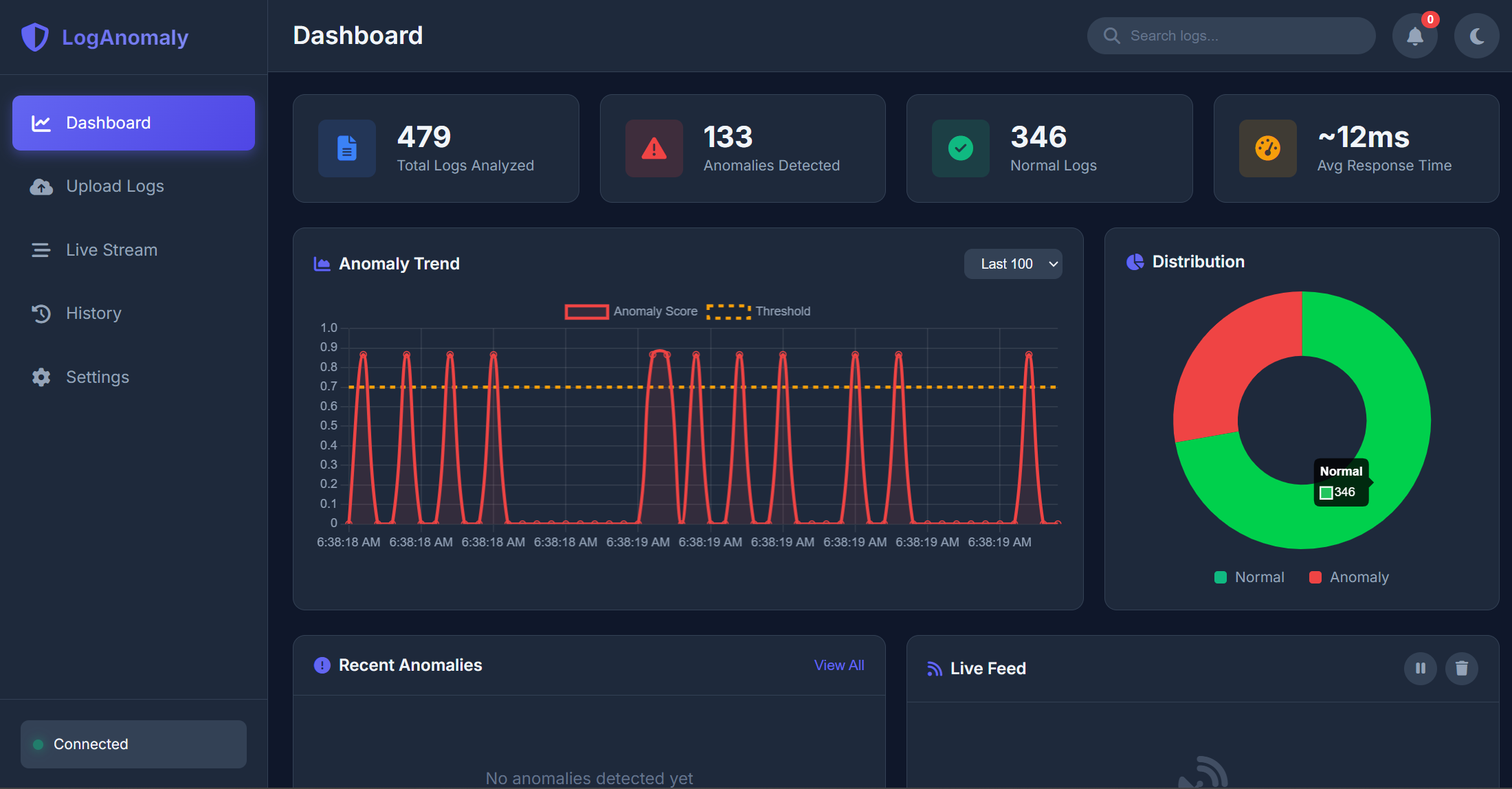
Sudden spikes in ERROR/WARN events Repeated failures (e.g., authentication errors, timeouts, retries) Unusual frequency of specific log templates/messages Behavior shifts compared to a learned “normal” baseline At a high level, it:
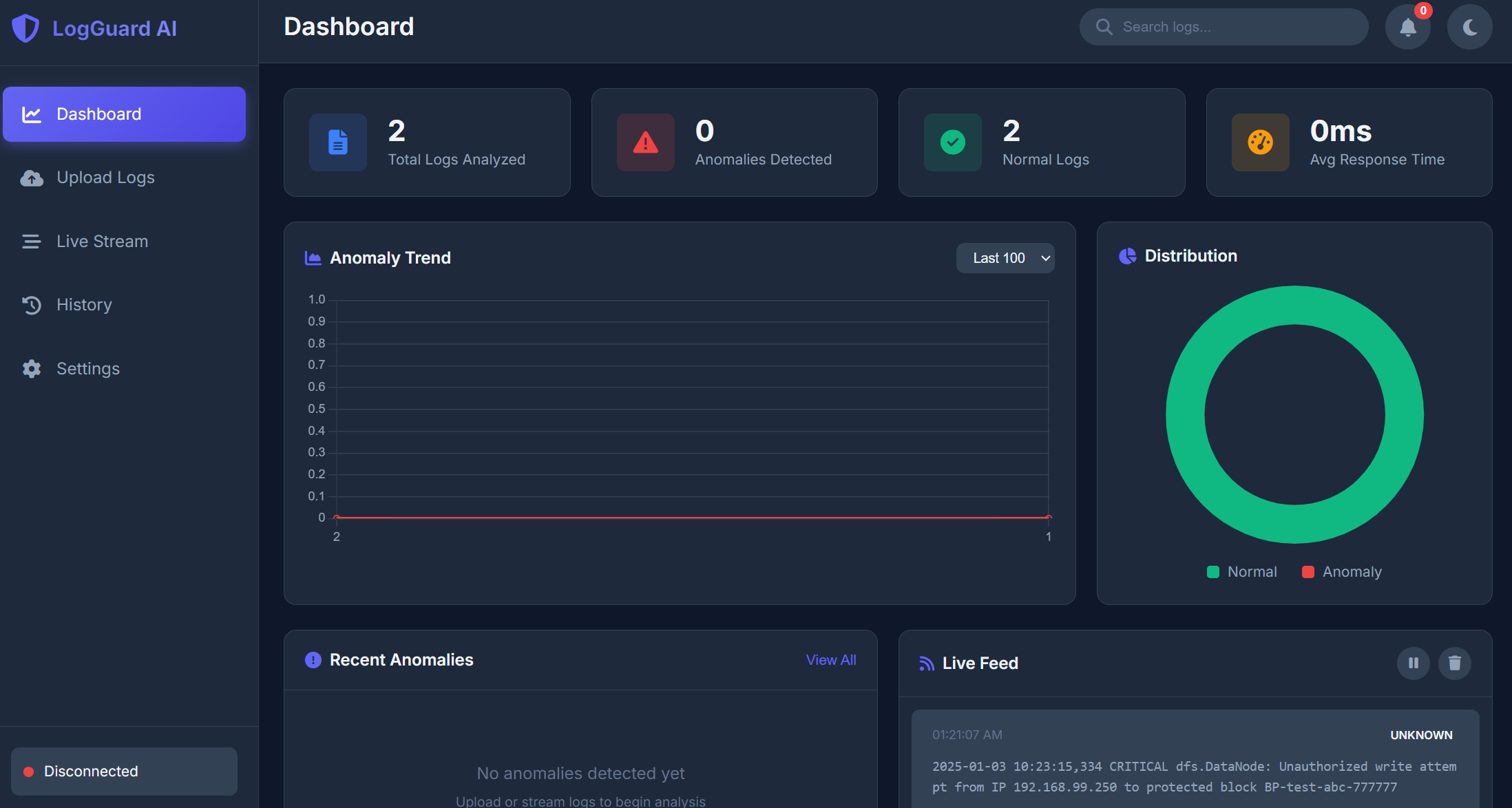
Ingests logs Parses and normalizes them Extracts useful signals/features Detects deviations from normal behavior Reports flagged anomalies for investigation
How we built it
We built Dexter as a pipeline-based system:
Log ingestion: Read logs from a source (file/stream) in consistent windows (e.g., per minute or per N lines). Parsing & normalization: Extract structured fields like timestamp, severity level, and message, and normalize variable parts of messages so similar events can be grouped. Feature extraction: Convert logs into measurable signals (counts by severity, counts per template, error rates over time). Anomaly detection: Compare recent behavior against a baseline using statistical thresholds. One simple approach is a z-score style trigger:
Challenges we ran into
Messy log formats: Logs are often inconsistent across components and evolve over time, which makes parsing and grouping difficult. No labeled anomalies: Without ground truth labels, evaluation depends on simulation, injection tests, and manual inspection. False positives vs. missed issues: Tuning sensitivity is tricky—too sensitive and the system becomes noisy; too lax and it misses real incidents. Actionability: Detecting “something is weird” is easy; explaining what changed and why it matters is harder.
Accomplishments that we're proud of
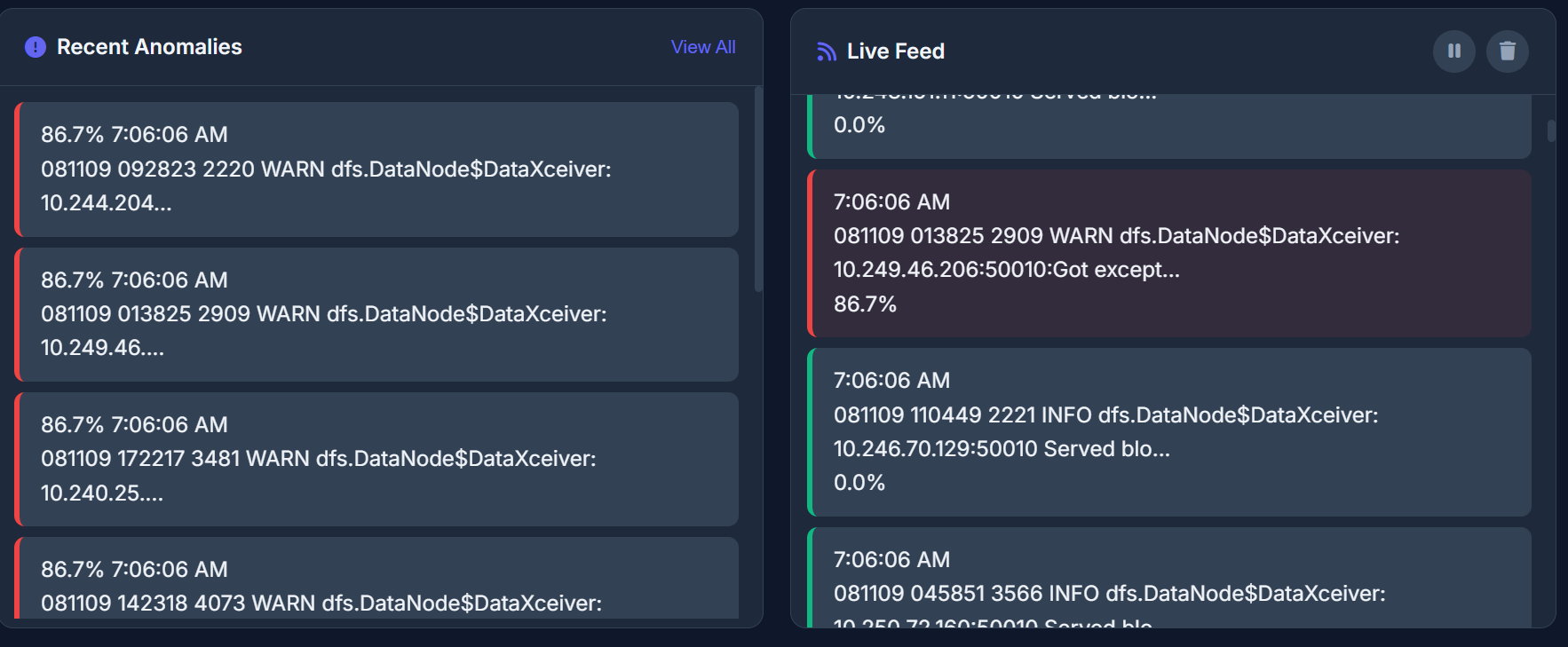
Built an end-to-end log anomaly monitoring workflow (ingest → process → detect → report). Achieved detection of meaningful anomaly patterns like error bursts and unusual message frequency shifts. Focused on interpretable outputs—highlighting top contributing log patterns instead of returning only a generic score. Created a foundation that can be extended into a more production-ready monitoring tool.
What we learned
Preprocessing is the core of log ML. The detector is only as good as the parsing and normalization. Explainability beats complexity in operational tools—clear signals and reasons drive faster incident response. “Normal” is contextual. Deployments, traffic spikes, and scheduled jobs can all look anomalous unless the baseline accounts for them. Practical anomaly detection is iterative, requiring repeated tuning and validation against real log behavior. What's next
What's next for Dexter - Autonomous Log monitoring and anomaly detection
Add template mining / clustering to group similar log messages more reliably. Support seasonality-aware baselines (daily/weekly patterns) to reduce false positives. Implement alert deduplication and grouping so one root cause doesn’t generate many redundant alerts. Build a lightweight dashboard to visualize anomaly windows and drill into contributing log patterns. Expand inputs to support more sources (multi-service ingestion, streaming pipelines) and richer context (deploy markers, traffic metrics).

Log in or sign up for Devpost to join the conversation.