-
-

The Logo and Thumbnail
-
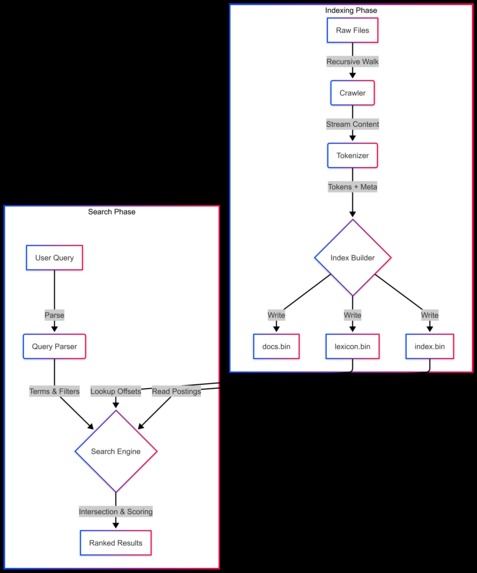
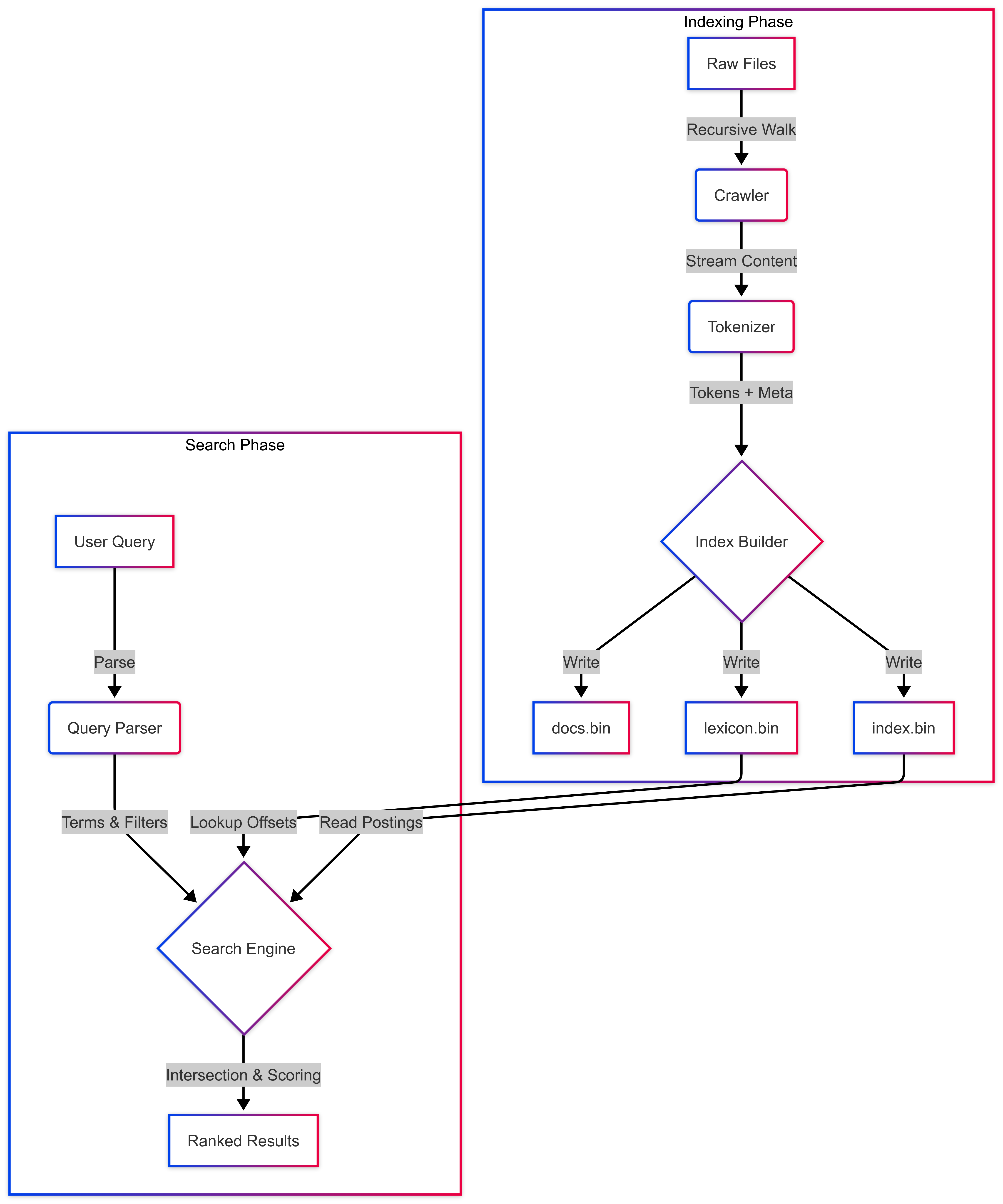
The Architecture
-
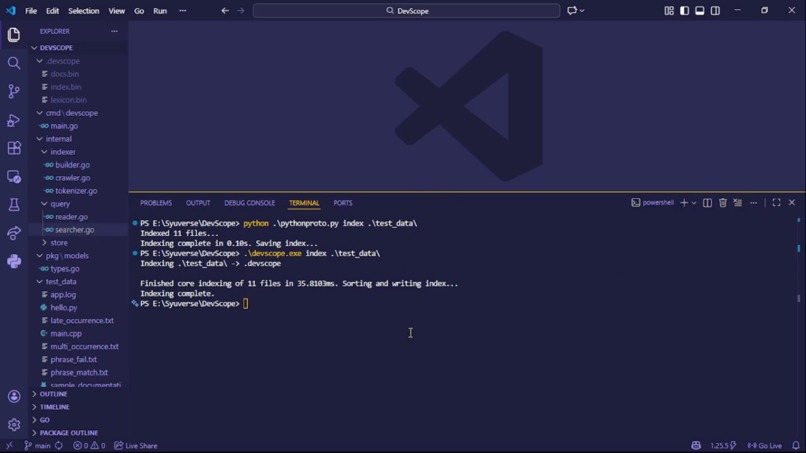
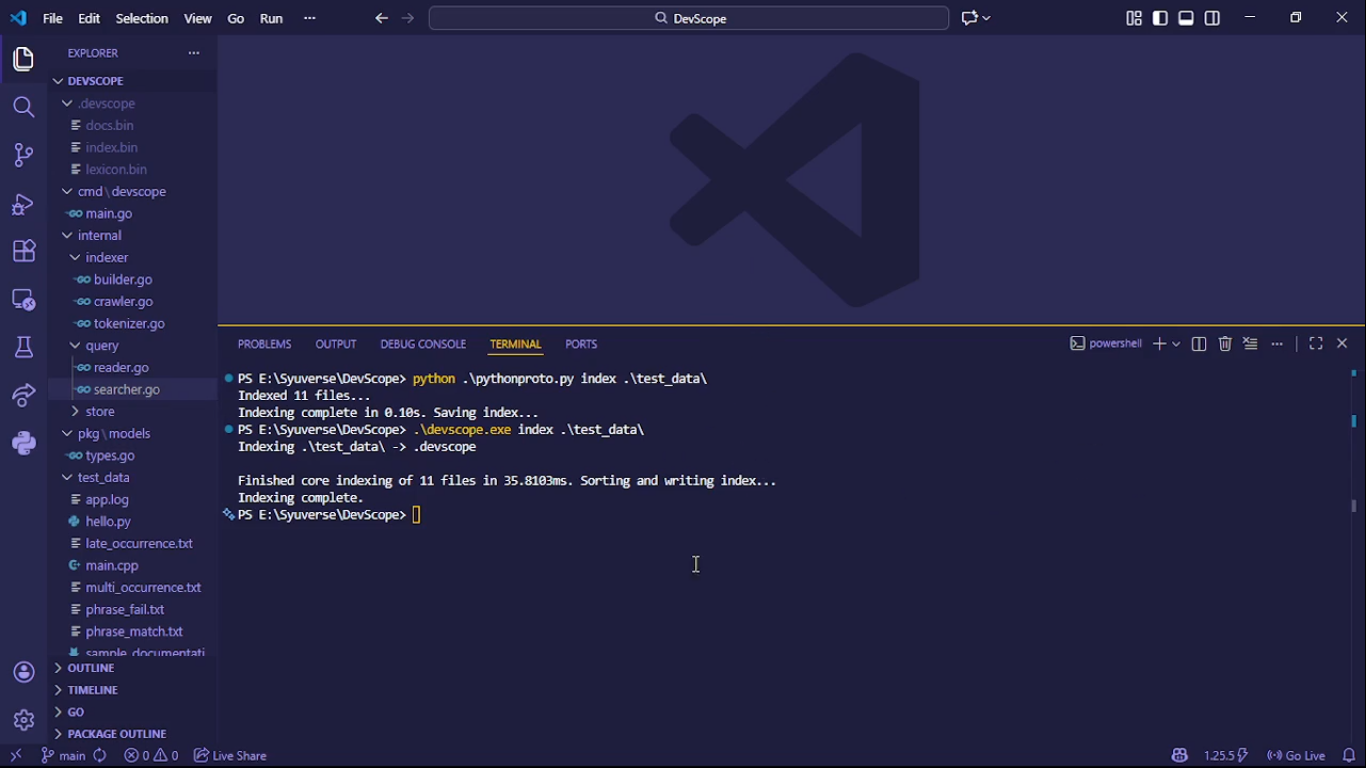
Benchmark Comparison Go vs Python

🚀 Inspiration
Searching across codebases and application logs is painfully slow and fragmented. Developers switch between multiple tools—IDE search, grep, log viewers, and Elasticsearch—none of which truly understand code structure. I wanted to build something different: a search engine optimized for developers, built entirely from scratch, that treats both code and logs as first-class citizens.
The real insight came from asking: What if I could build a database engine that doesn't hide complexity, but exposes it?
Traditional search engines like Lucene and Elasticsearch abstract away the internals. To truly understand systems design, I needed to understand every byte, from disk layout to ranking logic.
🧠 What We Built
DevScope is a from-scratch, high-performance search engine for source code and application logs. Built entirely in Go—without external search libraries—it implements:
- Custom binary indexing: Compact
.binfile formats (docs,lexicon,index) for minimal storage and fast disk seeks - Inverted index architecture: Positional posting lists enabling exact phrase matching (e.g.
"fatal error") without storing raw text - Context-aware tokenization: Understands code structure (function and class definitions) and log metadata (timestamps, severity levels)
- TF-IDF + metadata scoring: Ranking algorithm that boosts matches in filenames and function names
- Streaming processing: Memory-efficient indexing using Go channels, capable of handling large codebases without exhausting RAM
Result: ~10× faster than a Python prototype on identical datasets.
🛠️ Engineering Challenges
Challenge 1: Persistent Data Structures on Disk
In-memory indexes fail at scale. I designed a custom binary format using Go’s encoding/binary with magic headers, enabling efficient disk seeks and minimal overhead.
Challenge 2: Phrase Matching Without Storing Text
To support queries like "critical failure" without bloating the index, token positions are stored in posting lists. Phrase validity is checked by ensuring:
Position["failure"] = Position["critical"] + 1
Challenge 3: Efficient Disk-Based Search
Reading the entire index per query doesn’t scale. The lexicon is stored alphabetically with byte offsets. At search time, DevScope performs a direct Seek() to read only the relevant posting lists.
Challenge 4: Relevance Beyond Frequency
A term appearing frequently in verbose output should not outrank its appearance in a function definition. DevScope uses metadata-boosted TF-IDF, where structural importance overrides raw frequency.
🔬 Key Technical Innovations
Bitmask-Based Metadata
Instead of storing complex metadata structures, DevScope uses a single byte with bitflags:
const MetaInFunctionName = 1 << 1
if (Meta & MetaInFunctionName) != 0 {
boost score
}
This allows metadata checks using a single CPU bitwise operation.
Buffered I/O
All disk writes are wrapped in buffered writers, batching system calls and significantly improving indexing speed.
Low-Level Types
Fixed-width types like uint32 are used throughout the system to reduce garbage collection overhead and improve predictability.
🎯 Why This Matters
DevScope demonstrates that understanding fundamentals beats framework adoption. Instead of wrapping Elasticsearch, this project provided hands-on experience with:
- Inverted index construction
- Binary file format design
- Query planning and execution
- Ranking algorithms in practice
For a Build From Scratch challenge, this is not a wrapper—this is a real database engine.
Built With
- cli
- custom-binary-file-formats
- go-(golang)
- positional-inverted-index
- regex-based
- tf-idf
- tokenization


")








Log in or sign up for Devpost to join the conversation.