-
-
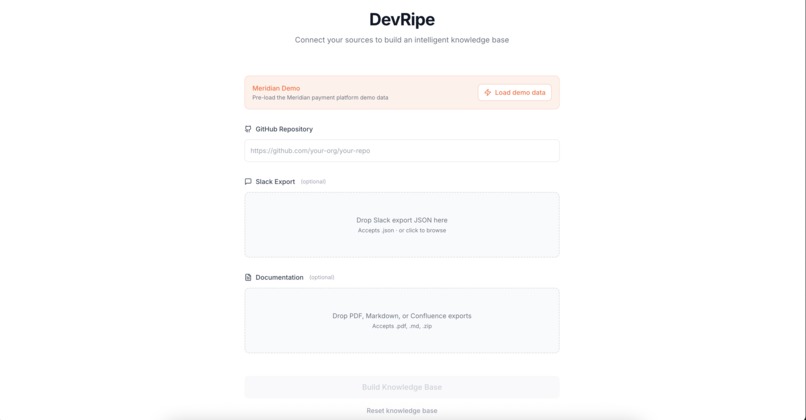
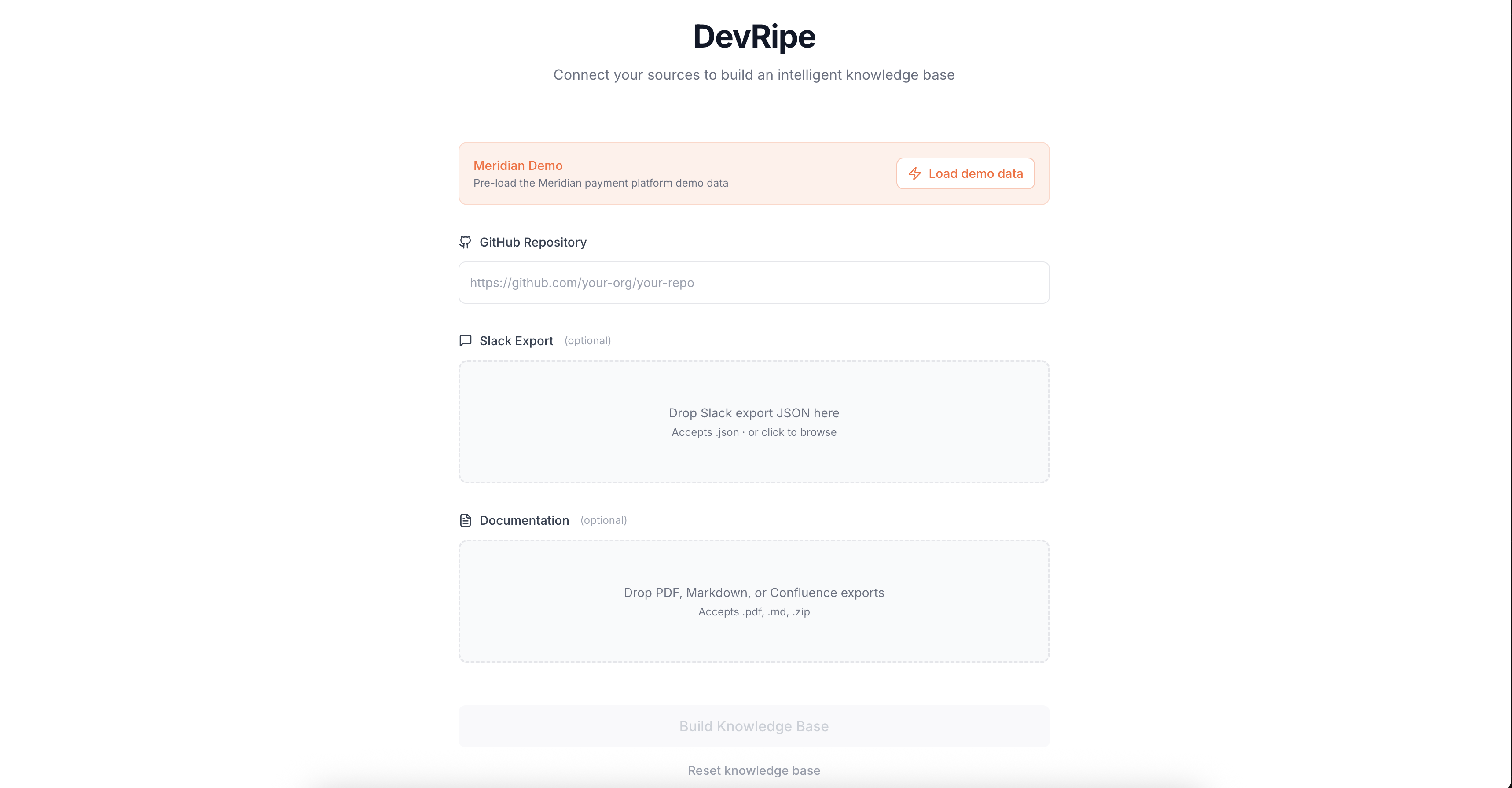
Senior Engineer Interface: Knowledge Ingestion (GitHub, Slack, Confluence)
-
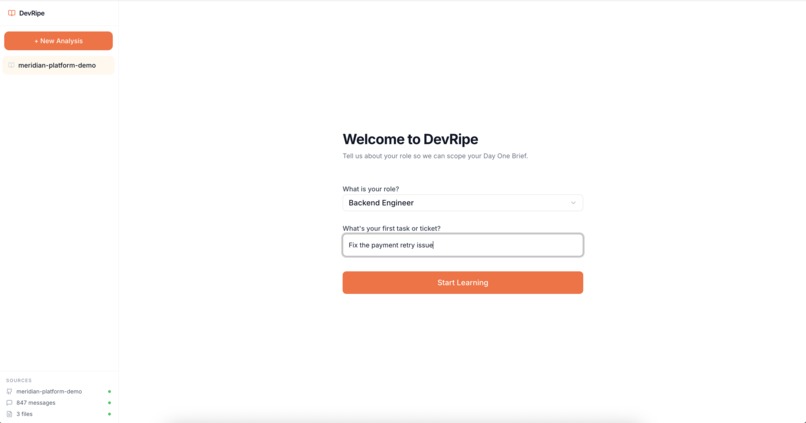
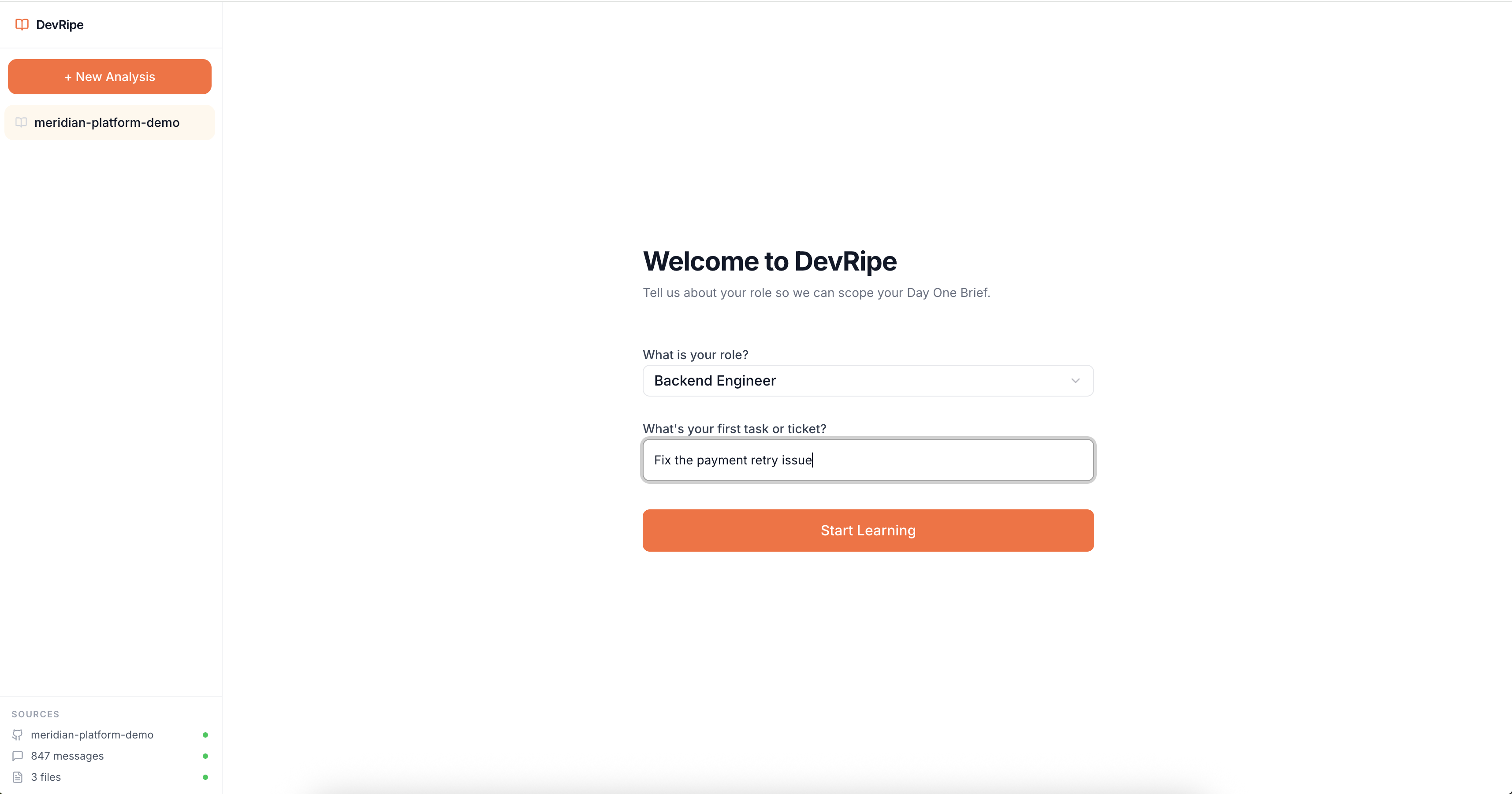
Junior Engineer Interface (Role and First Ticket Input)
-
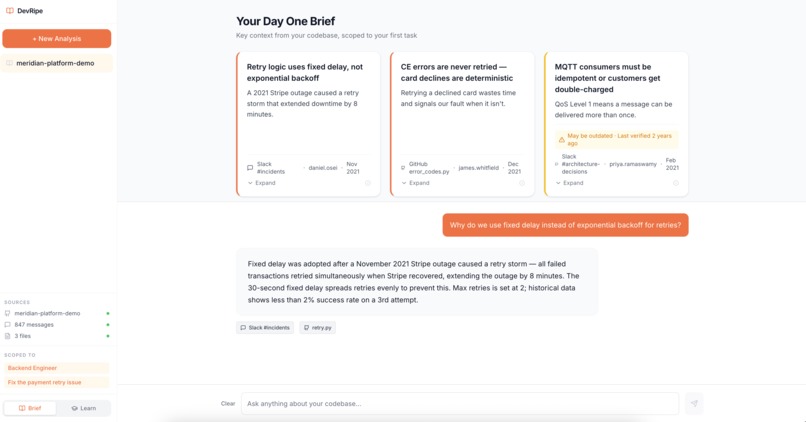
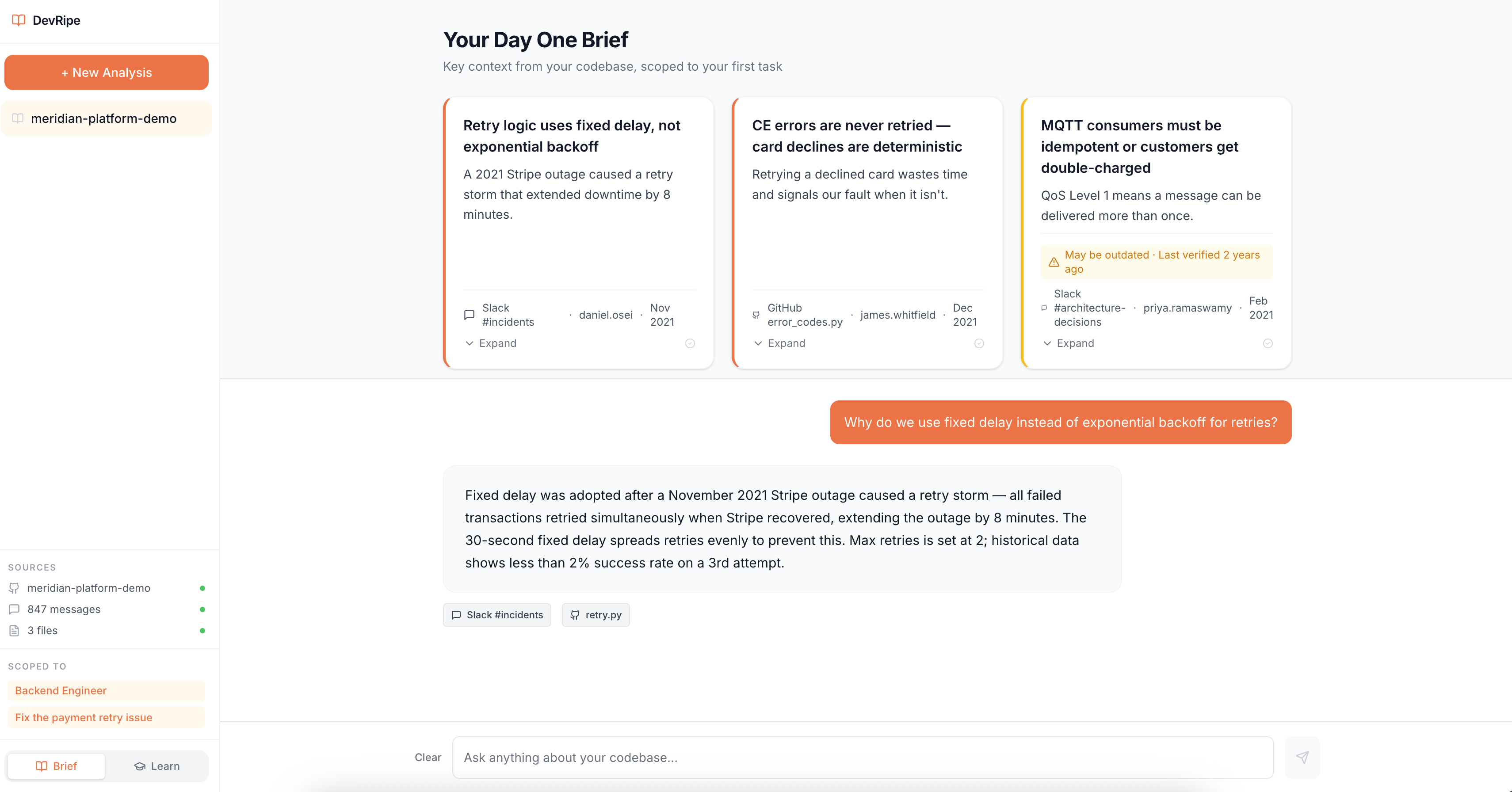
Day One Brief for Junior Engineer
-
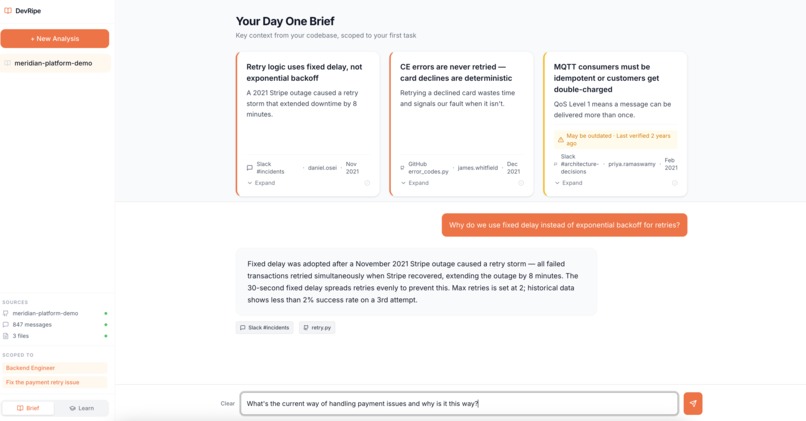
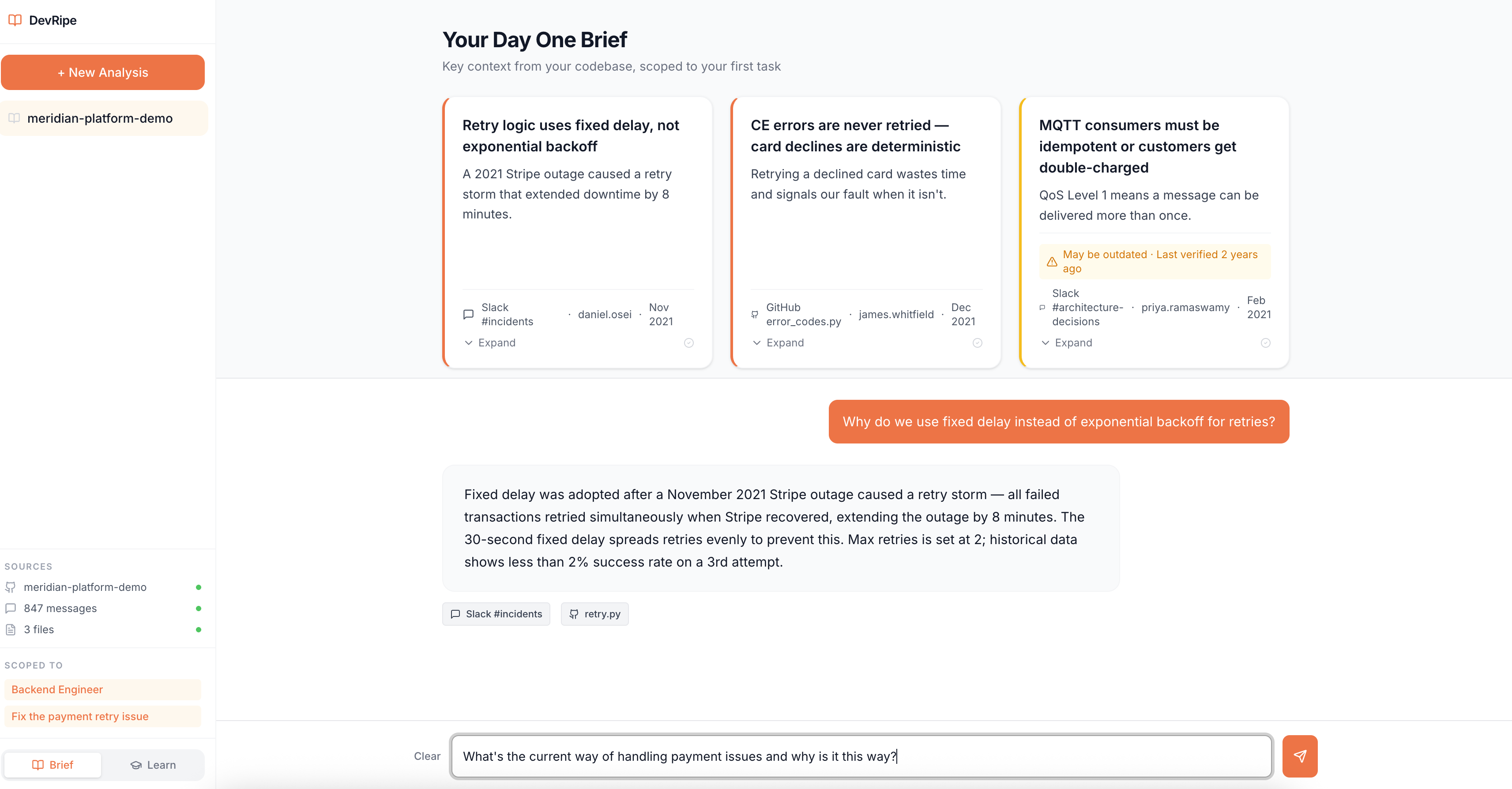
24/7 Access to Dynamic Senior Engineer Agent via Chat Interface
-
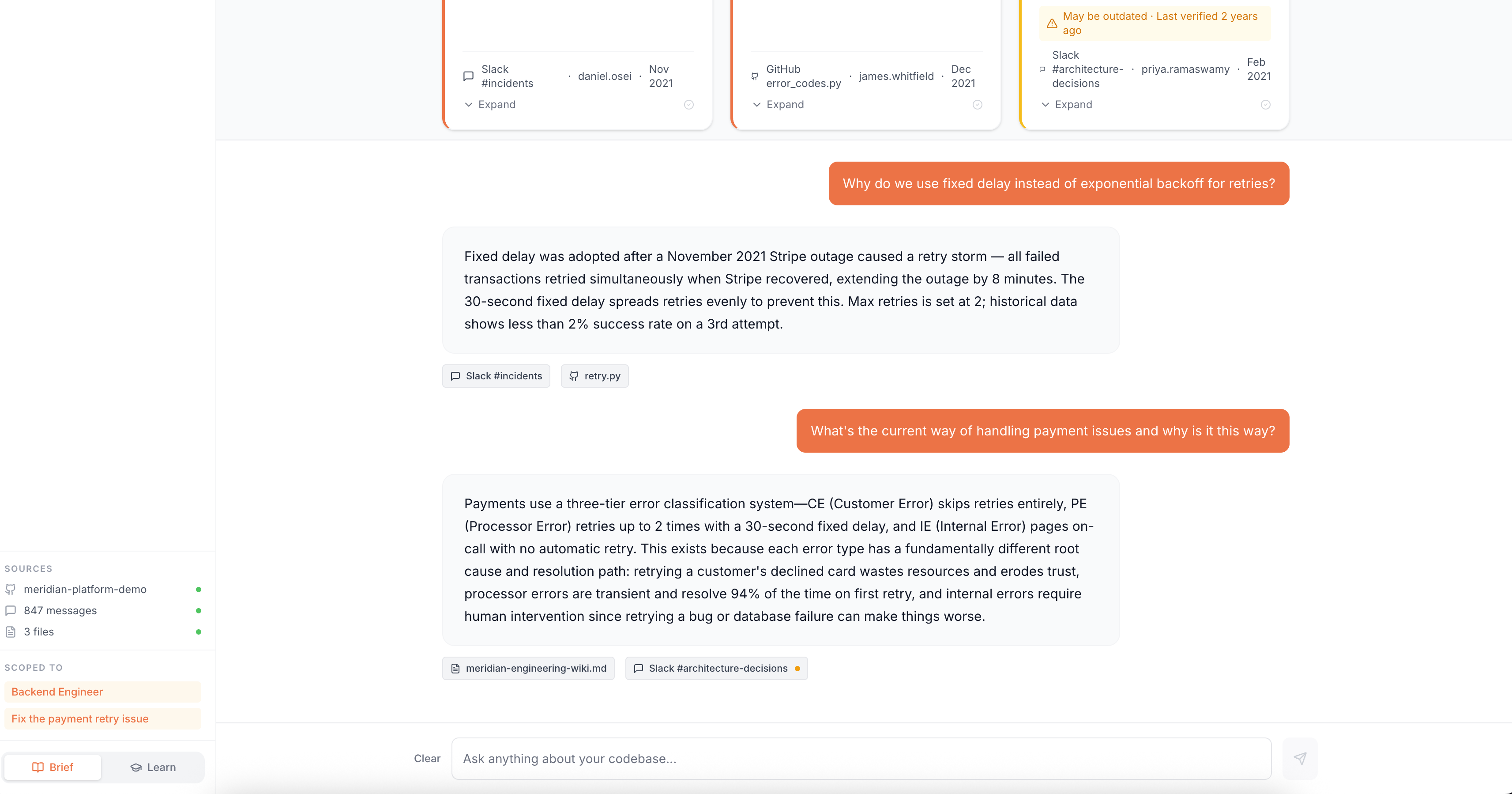
Contextual Answers from Dynamic Senior Engineer Agent with Sources for Trust
-
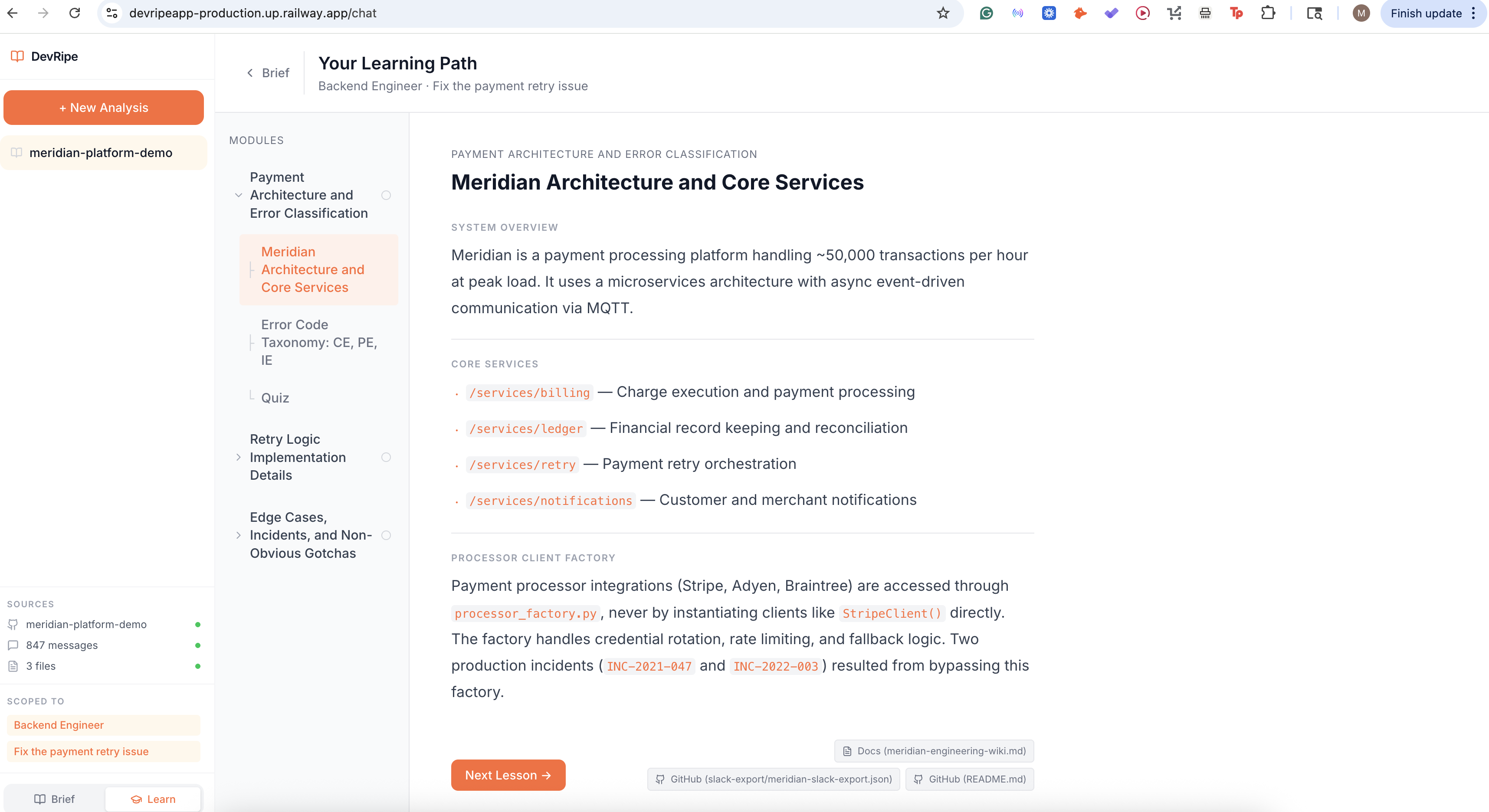
Personalized Onboarding Platform (Modules, Lessons, Quizzes)
-
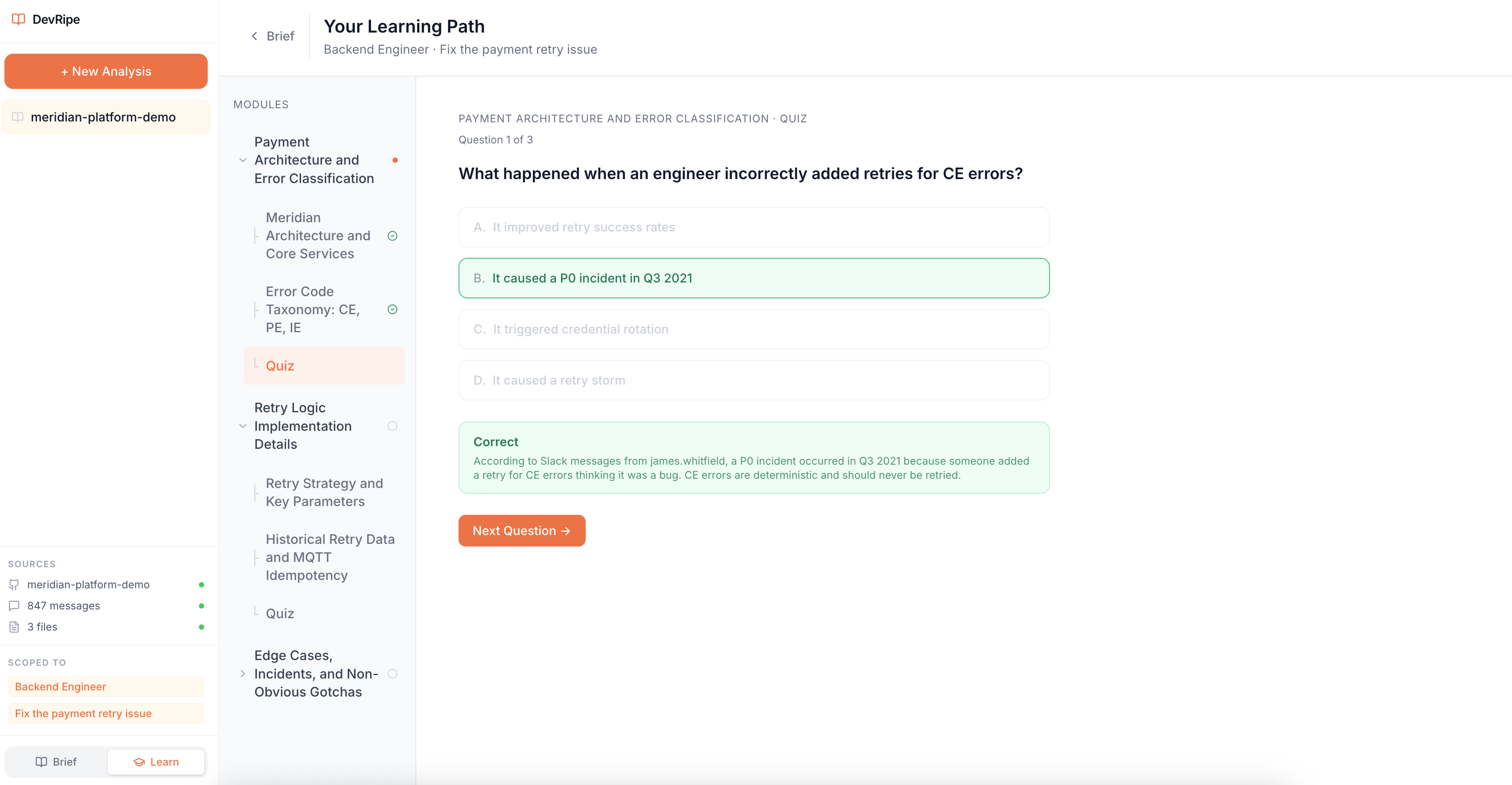
Personalized Domain Knowledge + Codebase Quizzes - Wright Answer
-
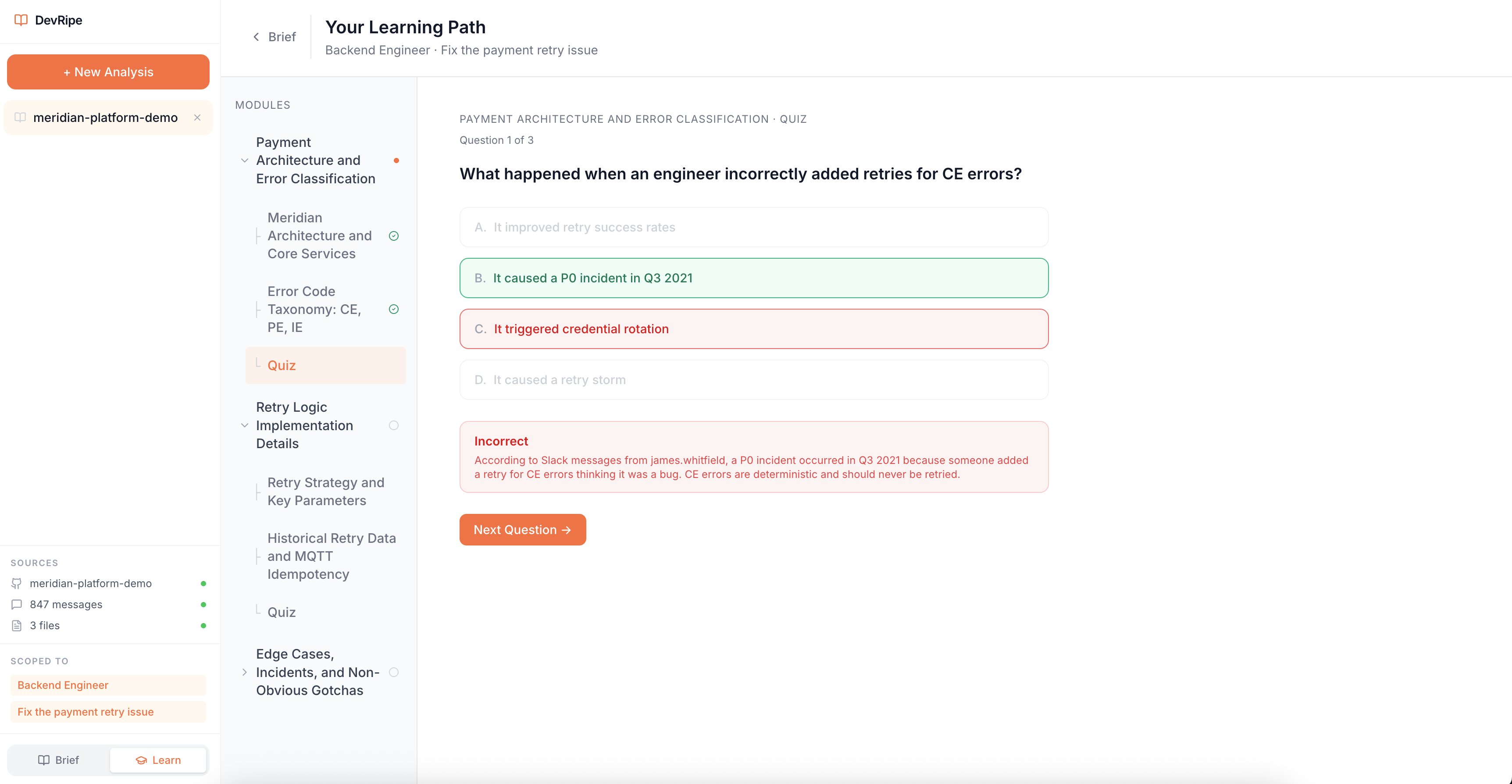
Personalized Domain Knowledge + Codebase Quizzes - Wrong Answer
Inspiration
Onboarding into a new codebase can feel like being dropped into a foreign city with no map. Critical context is scattered across GitHub commits, Slack threads, Confluence pages, and, most frustratingly, inside the heads of senior engineers who already have too much on their plates.
Our team has lived this firsthand. Working at companies like Amazon and early-stage startups, we watched new engineers spend weeks just finding answers that a senior already knew. The senior gets interrupted. The new hire feels lost. Productivity tanks on both sides.
We kept asking: why does this knowledge have to live only in someone's head?
The problem became impossible to ignore once we put numbers to it. A senior engineer earning ~$180K/year costs roughly:
$$\frac{\$180{,}000}{2{,}080 \text{ hrs}} \approx \$87/\text{hr}$$
With new hires typically ramping over a 3-month window, and seniors losing an estimated 30% of their focus to onboarding interruptions, the hidden senior cost per hire is:
$$520 \text{ hrs} \times 0.30 \times \$87/\text{hr} \approx \$13{,}000$$
Stack that on top of the $21,000 in new hire productivity loss, and the true cost per engineer hired is:
Total Onboarding Cost = $21,000 (new hire ramp) + $13,000 (senior interruptions) = $34,000
For a typical team onboarding 5 new engineers with a single senior leading ramp-up, the math shifts. The senior absorbs interruptions from all 5 hires at once, but there is still only one senior losing productivity:
Team Onboarding Cost = 5 × $21,000 (5 junior ramps) + 1 × $13,000 (1 senior interrupted) = $105,000 + $13,000 = $118,000
We built DevRipe because tribal knowledge shouldn't die in a Slack thread or sit locked behind a busy calendar.
What it does
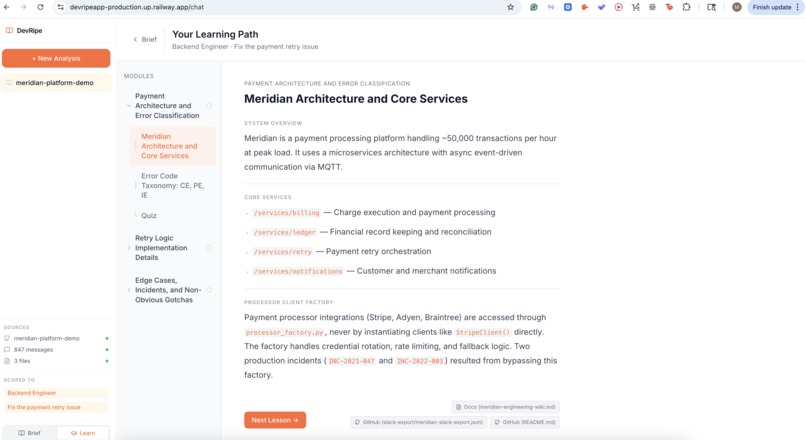
Beyond Q&A, DevRipe generates a custom onboarding course for every new engineer based on their role, their team's stack, and the actual codebase they'll be working in. Instead of a generic wiki dump, each hire gets a structured learning path with lessons, coding prompts, and checkpoints pulled directly from your repos and docs, so they ramp on what actually matters, not what someone remembered to write down.
This is how DevRipe attacks the $34,000 per hire problem directly. The faster a new engineer reaches their first meaningful contribution, the less time your senior spends getting interrupted, and the sooner the hire starts generating value instead of draining it.
The goal: make tribal knowledge repeatable, searchable, and always available, so your best engineers can stay heads-down.
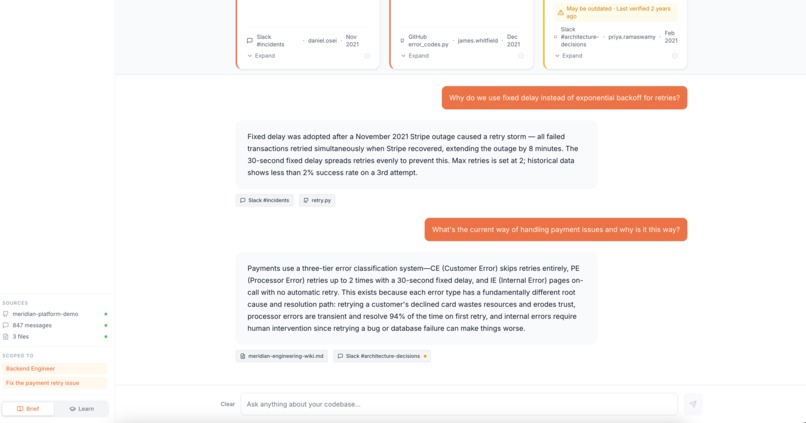
DevRipe is also an AI-powered onboarding agent that ingests your GitHub repositories, Slack workspace, and internal documentation, then gives new engineers a single place to ask questions and get instant, cited, source-grounded answers.
Instead of pinging a senior to ask "why do we use MQTT instead of REST?", a new engineer asks DevRipe and gets an answer traced directly back to the ADR, the Slack thread where the decision was debated, and the Confluence doc that benchmarked the alternatives.
Key capabilities:
- Multi-source ingestion, connects to GitHub, Slack, Confluence, Jira, and more
- RAG-powered Q&A, answers grounded in your actual codebase and docs, never hallucinated
- Cited responses, every answer links back to the exact source so engineers can verify and dig deeper
- Stale content flagging, automatically detects when a source may be outdated and surfaces that warning inline
- Role-aware context, answers tailored to the engineer's role and current project
- Access controls, respects existing permissions so engineers only see what they're supposed to
- Custom onboarding courses, auto-generates a role-specific learning path with lessons, coding prompts, and checkpoints built from your actual codebase, not generic templates
How we built it
DevRipe is built as a multi-agent RAG (Retrieval-Augmented Generation) system that transforms scattered tribal knowledge into a unified, queryable knowledge base.
1. Multi-Source Ingestion Pipeline
- GitHub Parser Agent, clones repositories, extracts commit history, PR discussions, code comments, and README files. Uses tree-sitter for syntax-aware code chunking.
- Slack Connector, ingests message exports, preserves threading context, and identifies decision-making conversations through keyword detection (ADR, RFC, decision, etc.).
- Documentation Processor, handles Markdown, Confluence exports, and PDFs. Extracts structured content while maintaining document hierarchy.
2. Knowledge Base Construction
- Vector Database, Pinecone for semantic search across all ingested content. Each chunk is embedded using OpenAI's text-embedding-3-large model.
- Metadata Layer, PostgreSQL stores source metadata, timestamps, author information, and cross-references between related content.
- Chunking Strategy, adaptive chunking based on content type — code uses function/class boundaries, docs use section headers, Slack uses message threads.
3. RAG Query Engine
- Retrieval, hybrid search combining semantic similarity (vector) and keyword matching (BM25) to surface relevant context.
- Reranking, cross-encoder model reranks top-k results to prioritize the most relevant sources.
- Generation, Claude 3.5 Sonnet generates answers with strict citation requirements — every claim must link back to a source chunk.
4. Staleness Detection
Timestamps on all sources are compared against recent activity (commits, messages, doc updates). Heuristic rules flag content older than 18 months or contradicted by newer sources, and inline warnings surface automatically in responses.
5. Custom Learning Path Generator
- Role Analysis Agent, analyzes job role and assigned task to identify required knowledge areas.
- Curriculum Builder Agent, extracts relevant code patterns, architectural decisions, and best practices from the knowledge base.
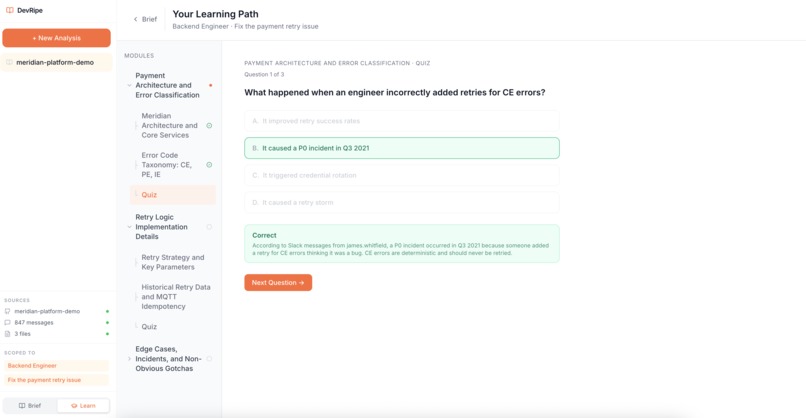
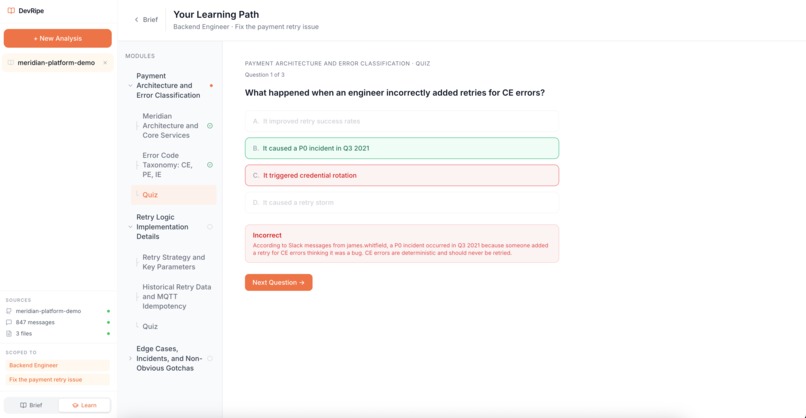
- Quiz Generator Agent, creates comprehension checks based on actual codebase scenarios.
- Output, structured JSON course with modules, lessons, and quizzes rendered as an interactive learning interface.
Tech Stack
| Layer | Tools |
|---|---|
| Frontend | React, TypeScript, TailwindCSS, Framer Motion |
| Backend | Node.js, Express, Server-Sent Events (SSE) |
| LLM | Anthropic Claude API (reasoning), OpenAI API (embeddings) |
| Data | Pinecone (vectors), PostgreSQL (metadata) |
| Infra | Vite, GitHub API, Slack API |
Key Design Decisions
Why multi-agent architecture? Each source type (code, conversations, docs) has unique structure and semantics. Specialized agents handle domain-specific parsing, then feed into a unified knowledge graph.
Why Claude over GPT-4? Claude's 200K context window allows more retrieved chunks per prompt, improving answer quality. Its instruction-following is also more reliable for citation formatting.
Why hybrid search? Pure semantic search misses exact keyword matches like function names or error codes. Pure keyword search misses conceptual queries. Combining both gives the best results.
Challenges we ran into
Multi-agent coordination, early versions had agents producing inconsistent output formats. We fixed this by implementing strict JSON schema validation with Zod, with retry logic and schema examples baked into each prompt.
Citation accuracy, the LLM occasionally hallucinated citations referencing sources that didn't contain the claimed information. We added a post-generation verification step that checks each citation against retrieved chunks, regenerating or flagging unverified ones.
GitHub parsing at scale, large monorepos (10K+ files) caused memory issues and slow ingestion. We solved this with streaming file processing and selective indexing, prioritizing recently modified files and content relevant to the user's role.
Slack thread context, short messages like "Agreed, let's go with MQTT" are meaningless without their thread. We implemented thread-aware chunking that includes parent messages and replies so every chunk carries full conversation context.
Handling contradictory information, different sources sometimes conflict (e.g., old docs say "use REST", a recent Slack thread says "migrated to MQTT"). Timestamp-aware ranking prioritizes newer sources, and when contradictions are detected, the answer explicitly flags both perspectives.
Accomplishments that we're proud of
- Built an end-to-end pipeline ingesting heterogeneous sources (code, conversations, docs) and surfacing unified, cited answers in seconds
- Designed a staleness detection system that proactively warns engineers when information may be out of date, without requiring manual doc maintenance
- Created a cross-source knowledge cortex linking concepts across GitHub, Slack, and docs so answers reflect the full context of a decision
- Validated the core pain point with real engineering teams, the $34,000 cost-per-hire problem is universal from 10-person startups to enterprise orgs
What we learned
- The real product is trust. Engineers won't use an AI onboarding tool if they can't verify answers. Citations aren't a nice-to-have, they're the core feature.
- Tribal knowledge is a systems problem, not a documentation problem. Teams don't fail at onboarding because they're lazy about writing docs. Knowledge is inherently distributed and dynamic, the solution has to meet it where it lives.
- Chunking and retrieval quality compound. Small improvements in how we chunk source content had outsized downstream effects on answer quality. This deserved more early investment.
- Senior engineers are the real customer. New hires feel the pain, but it's seniors whose time gets drained. Framing DevRipe as a tool that frees seniors, not just helps juniors, changed how we pitched and prioritized.
What's next for DevRipe
- Deeper repo intelligence, Architecture-aware indexing that understands service boundaries, data flows, and dependency graphs, not just file contents
- Proactive onboarding flows, DevRipe surfaces relevant context based on what files a new engineer is actively working in, rather than waiting to be asked
- Role-based learning paths, Curated onboarding journeys tailored by role (backend, frontend, platform) and team
- Knowledge gap analytics, Dashboards for engineering leads showing top-asked questions, thinnest knowledge areas, and stalest docs
- Enterprise integrations, Deeper support for Jira, Linear, Notion, and internal wikis, plus SSO and SOC 2 compliance
- Path to scale, DevRipe's long-term vision is a per-seat SaaS model targeting the $34,000-per-hire problem across the 4M+ software engineers hired annually in the US alone, a multi-billion dollar market we're just beginning to unlock
Built With
- anthropic-claude-api
- bm25
- events
- express.js
- framer
- github-api
- motion
- node.js
- pinecone
- postgresql
- react
- react-router
- server-sent
- tailwindcss
- tree-sitter
- typescript
- vite
- zod



Log in or sign up for Devpost to join the conversation.