Inspiration
Developer Relations teams and open-source maintainers face a recurring challenge, turning complex codebases into clear, engaging content that reaches developers across many channels. Tutorials, blog posts, social threads, and talks all need deep technical understanding and high accuracy to maintain trust, which makes content creation slow and expensive.
We asked: What if AI could analyze any GitHub repository and automatically generate a complete, multi-channel DevRel campaign, with quality checks built in?
The idea grew from three observations:
- Content creation bottleneck: DevRel teams often spend 60–70% of their time manually turning repository features into narrative content.
- Quality vs. speed tradeoff: Fast content usually risks errors; careful review improves quality but slows output.
- Multi-channel consistency gap: Keeping messaging aligned across Twitter, blogs, tutorials, and talks requires heavy manual coordination.
DevRel Campaign Generator addresses this with AI-powered campaign generation plus automated validation, code review, and quality scoring, turning hours of content work into minutes while keeping quality high.
What it does
DevRel Campaign Generator is an AI-powered platform that transforms any public GitHub repository into a complete, multi-format DevRel campaign.
Input
- GitHub Repository URL (e.g.,
https://github.com/vercel/next.js) - Analysis Time Window (1 week, 1 month, 3 months, 6 months, 1 year)
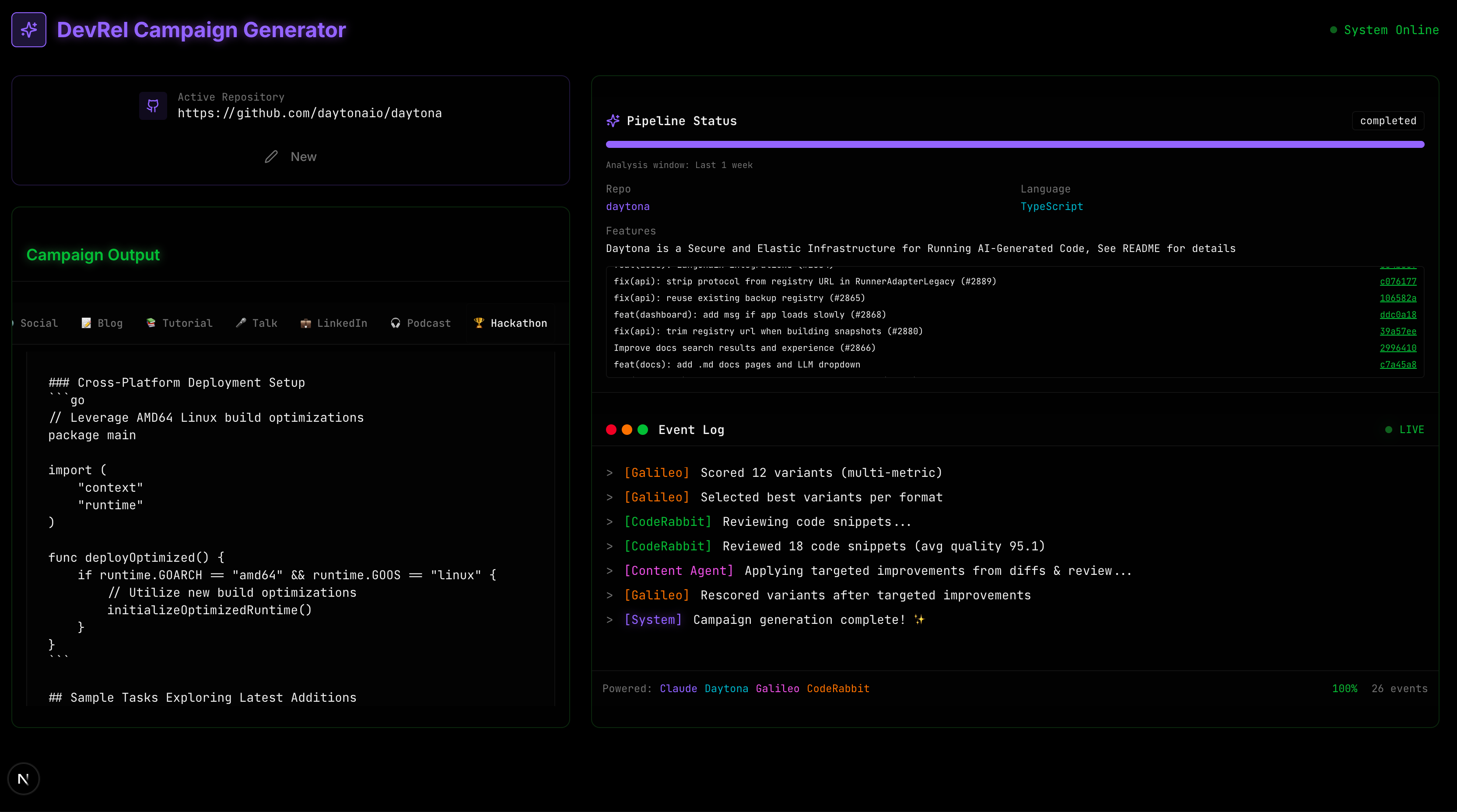
Output (Generated Content Formats)
📚 Step-by-Step Tutorial Getting started guide including prerequisites, installation, first example, and basic troubleshooting.
📝 Technical Blog Post Announcement-style post with technical overview, key features, code samples, and a clear call to action.
🎤 Conference Talk Outline A 30–45 minute talk structure with title, abstract, slide outline, speaker notes, and Q&A preparation.
🐦 Twitter/X Thread A 5–7 tweet thread with technical highlights, emojis, and engagement hooks.
💼 LinkedIn Post A 200–300 word professional update targeted at technical leaders.
🏆 Hackathon Challenge A 24–48 hour hackathon prompt based on the repo, with judging criteria and starter resources.
🎧 Podcast Audio (via ElevenLabs) Text-to-speech audio generated from the blog or talk content.
How we built it
Architecture Overview
DevRel Campaign Generator is a Next.js 16 full-stack application built around a multi-agent AI pipeline:
User Input → GitHub Analysis → Profile Extraction → Validation → Content Generation → Quality Evaluation → Code Review → Targeted Improvements → Best Selection → Display
Tech Stack
Frontend
- Next.js 16 (App Router) with React 19
- TypeScript 5 for full type safety
- Tailwind CSS v4 with a custom cyberpunk theme (OKLCH color space)
- shadcn/ui + Radix UI components (accordion, tabs, cards, select, etc.)
- Lucide React icons
Backend
Next.js API Routes as serverless functions:
/api/generate, starts a generation job/api/status/[jobId], returns job progress/api/tts, handles text-to-speech requests
In-memory job tracking (
lib/jobs.ts) with automatic cleanup after 1 hourAsync pipeline processing with real-time log streaming
AI & External Services
| Service | Role | Implementation Status |
|---|---|---|
| Anthropic Claude Sonnet 4 | Repository profiling and content generation | ✅ Fully integrated |
| GitHub API | Repository metadata, README, languages, commits, diffs | ✅ Fully integrated |
| Daytona | Ephemeral workspace to validate code examples | ✅ Implemented (API key optional, otherwise mock) |
| Galileo | Content evaluation and hallucination scoring | ✅ Implemented (API key optional, otherwise mock) |
| CodeRabbit | Code review and snippet quality scoring | ✅ Implemented (API key optional, otherwise mock) |
| ElevenLabs | Text-to-speech audio synthesis | ✅ Fully integrated |
Challenges we ran into
1. API Rate Limits & Key Management
Problem: GitHub API rate limits (60 unauthenticated requests per hour, 5000 authenticated) caused frequent failures early on.
Solution:
- Optional
GITHUB_TOKENsupport to increase rate limits - Basic token budget awareness in fetch logic
- One-hour caching of repository metadata to avoid redundant requests
2. Hallucination Risk in Generated Content
Problem: Claude, like all LLMs, can invent technical details, especially in code examples.
Solution:
- Used Daytona to execute and validate code examples
- Added Galileo hallucination risk score (0–1)
- Grounded prompts with repo facts: README, language stats, commit history
- Iterative improvement for high-risk variants
- Anchored examples in real commit diffs instead of hypothetical APIs
3. External Service Integration Complexity
Problem: Each sponsor service used a different API style, auth pattern, and response shape. Some were in beta with partial documentation.
Solution:
- Built a modular adapter layer in
lib/services.tswith a consistent interface - Added mock implementations for local development and testing
- Implemented content-type checks to handle HTML error pages as well as JSON
- Graceful degradation, missing API keys trigger mocks instead of breaking the pipeline
4. UI Blocking During Long Generation
Problem: The first version waited for the full pipeline to complete before showing any content, which made a 60–90 second process feel opaque and slow.
Solution:
- Client-side polling (
/api/status) every second - Real-time event log for each agent and stage
- Incremental display of content, variants appear as soon as they are ready
- Progress bar showing completion percentage
- Color-coded log output (for Claude, Daytona, Galileo, CodeRabbit) to clarify stages
5. Type Safety Across Service Boundaries
Problem: TypeScript struggled with partial job states, optional fields, and unions across async steps.
Solution:
- Centralized type definitions in
lib/types.ts - Strict TypeScript mode with careful optional chaining
- Runtime type guards for external API responses
- Safe defaults for missing data, for example
commits?: RepoCommit[]
Accomplishments that we're proud of
1. End-to-End Quality Assurance, Not Just Text Generation
Most AI tools stop at generation. We implemented a closed-loop QA pipeline:
- ✅ Daytona validates that code examples actually run
- ✅ Galileo scores content across multiple dimensions and flags hallucination risk
- ✅ CodeRabbit reviews code snippets for best practices
- ✅ Low-scoring variants automatically go through another improvement pass
- ✅ Content is grounded in real commit diffs and repository structure
The result is content that is much closer to production-ready than a raw AI draft.
2. A Live, Transparent User Experience
Instead of a static form and spinner, the UI:
- Streams agent logs while the pipeline runs
- Shows content variants as soon as they are produced
- Updates scores and metrics in real time
- Explains why one variant is preferred over another
- Surfaces commit history and diff snippets alongside the content
This transparency helps users trust the output because they can see the reasoning and validation steps.
3. Graceful Degradation and Developer-Friendly Behavior
The system runs even without external API keys, handles rate limits, and avoids hard crashes. We added:
- Content-type validation for every external response
- Fallback content templates if Claude is unavailable
- Warning banners when using mock data
- Planned retry logic with backoff for transient failures
- One-hour job cleanup to avoid memory growth
What we learned
1. Grounding LLMs is Essential for Technical Trust
When we let Claude generate with fewer constraints, the output often:
- Referenced APIs that did not exist
- Used wrong dependency names
- Described features not present in the repo
Learning: Always ground generation in structured project data such as README, commits, diffs, and language stats, and make these constraints explicit in prompts.
2. Multi-Variant Generation Beats Single-Pass Output
We generate multiple variants per content type with different temperatures, then score them. Quality scores from Galileo varied widely, often from 70 to 95, even with similar prompts.
Learning: Do not rely on a single LLM output. Generate several candidates, score them, and choose the best.
3. External APIs Fail in Many Ways
We saw:
- JSON parsers fail because the API returned HTML
- Missing fields like undefined metrics
- Incorrect or missing content-type headers
- 429 rate limit responses without useful retry hints
Learning: Treat external APIs as unreliable by default. Validate headers, check fields carefully, and always define a fallback path.
4. Real-Time Feedback Changes Perception of Speed
With a blank screen and spinner, 90 seconds felt slow and broken. After adding:
- Live logs
- Incremental content
- Progress metrics
- Clear stage updates
The same duration felt responsive and under control.
Learning: Transparency, partial results, and progress indicators dramatically improve perceived performance.
5. Developer Tool UX Patterns Work Well for AI Products
We borrowed familiar patterns:
- VS Code terminal, for the event log
- GitHub Actions logs, for step-by-step stages
- Network inspector, for understanding requests and responses
- Test runner UI, for pass/fail and progress indicators
Learning: Developers trust interfaces that look and feel like the tools they already use. Reusing proven patterns increases adoption and comfort.
6. Sponsor Requirements Deepened the Product
Integrating Daytona, Galileo, and CodeRabbit forced us to clarify:
- What “validation” should cover
- How to define “quality” beyond style and grammar
- What a “review” means at the code snippet level
Learning: External requirements can sharpen product thinking and lead to a more robust system when treated as constraints, not checkboxes.
What's next for DevRel Agent (Campaign Generator)
1. Persistent Job Storage
- Replace in-memory job state with Redis or Upstash
- Allow users to revisit past jobs and download previous campaigns
- Store repo profiles so future runs only process code changes
2. Production-Grade Testing and Optimization
- Daytona: Run more real-world workspaces, refine scripts, and add retries
- Galileo: Validate scoring against human judgment, tune weightings
- CodeRabbit: Use diff-aware review and tighten mapping from suggestions to content edits
3. Content Export and Sharing
- Export generated content as individual markdown files
- Offer a single ZIP archive for a full campaign
- Add copy-to-clipboard for quick posting
- Provide shareable links for teams and stakeholders
4. Deeper Customization
- Let users choose only the formats they need
- Add audience level controls: beginner, intermediate, advanced
- Support tone guidance, such as formal, neutral, or playful
- Introduce templates that match an organization’s internal standards
5. More Robust Code Validation
- Daytona support for running multiple setup and example scripts
- Step-by-step validation to ensure tutorials are actually executable
- Automatic retries for transient execution failures
- Multi-environment support (for example Node.js versions, Python variants)
Built With
- daytona
- intel-galileo
- nextjs


Log in or sign up for Devpost to join the conversation.