-
-
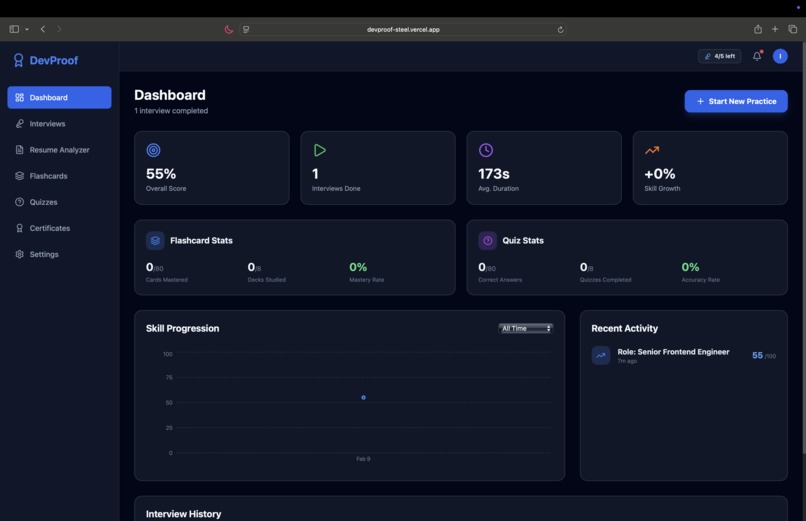
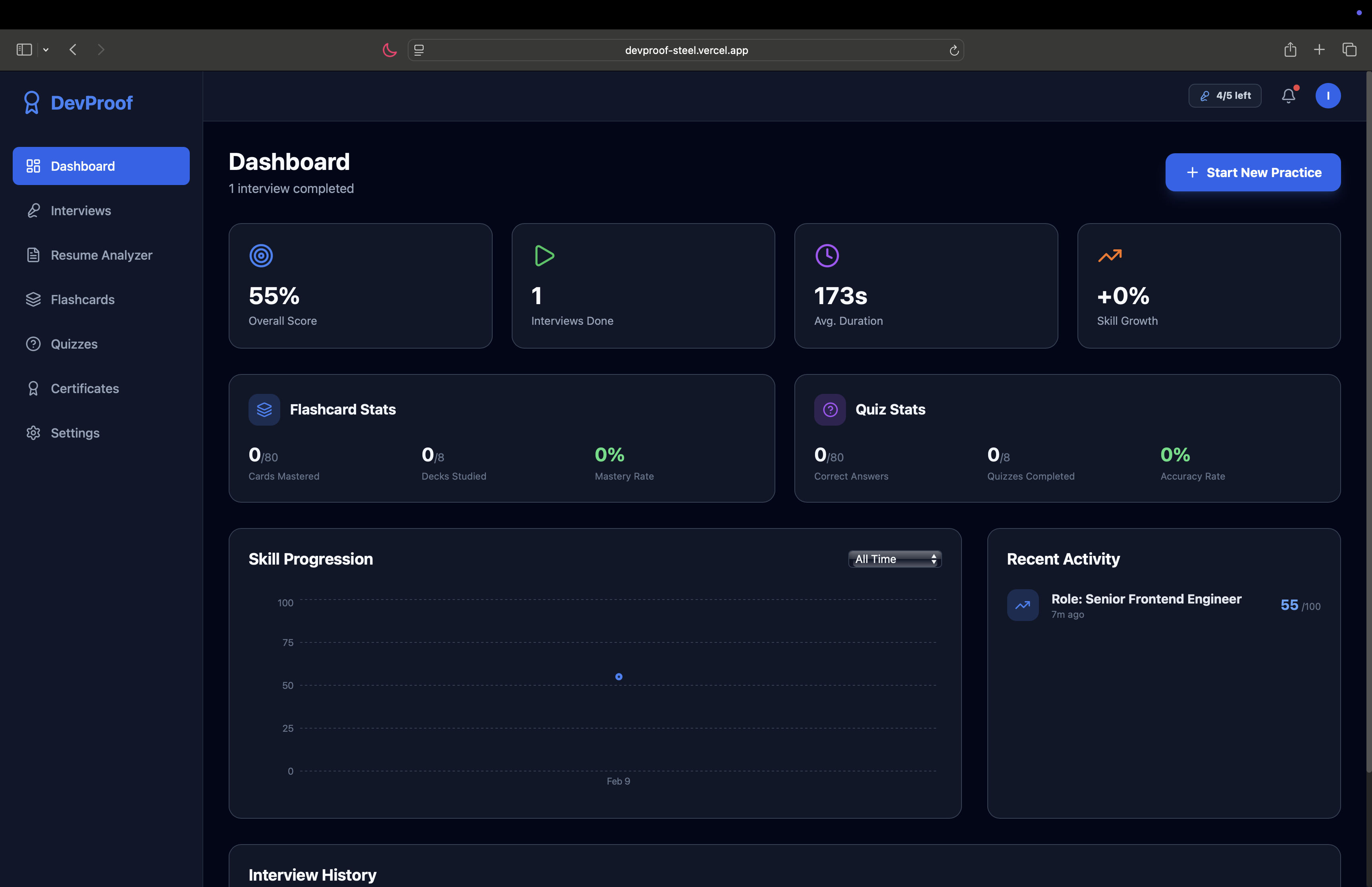
Personalized Dashboard with Skill Tracking
-
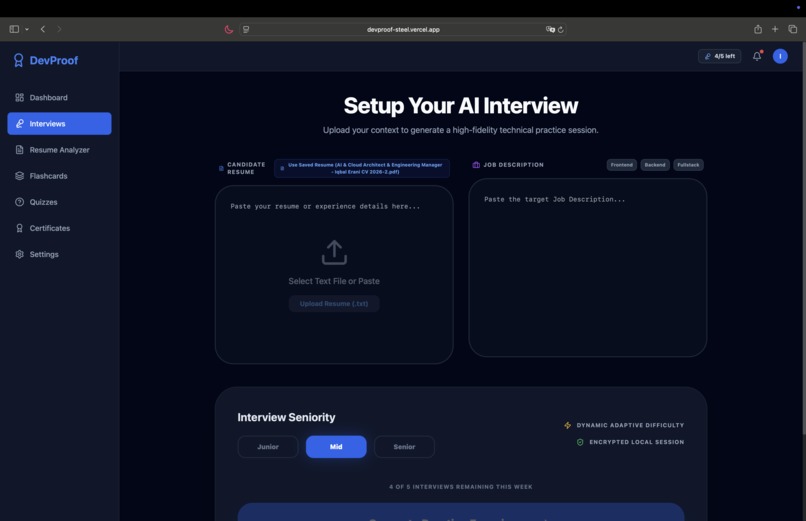
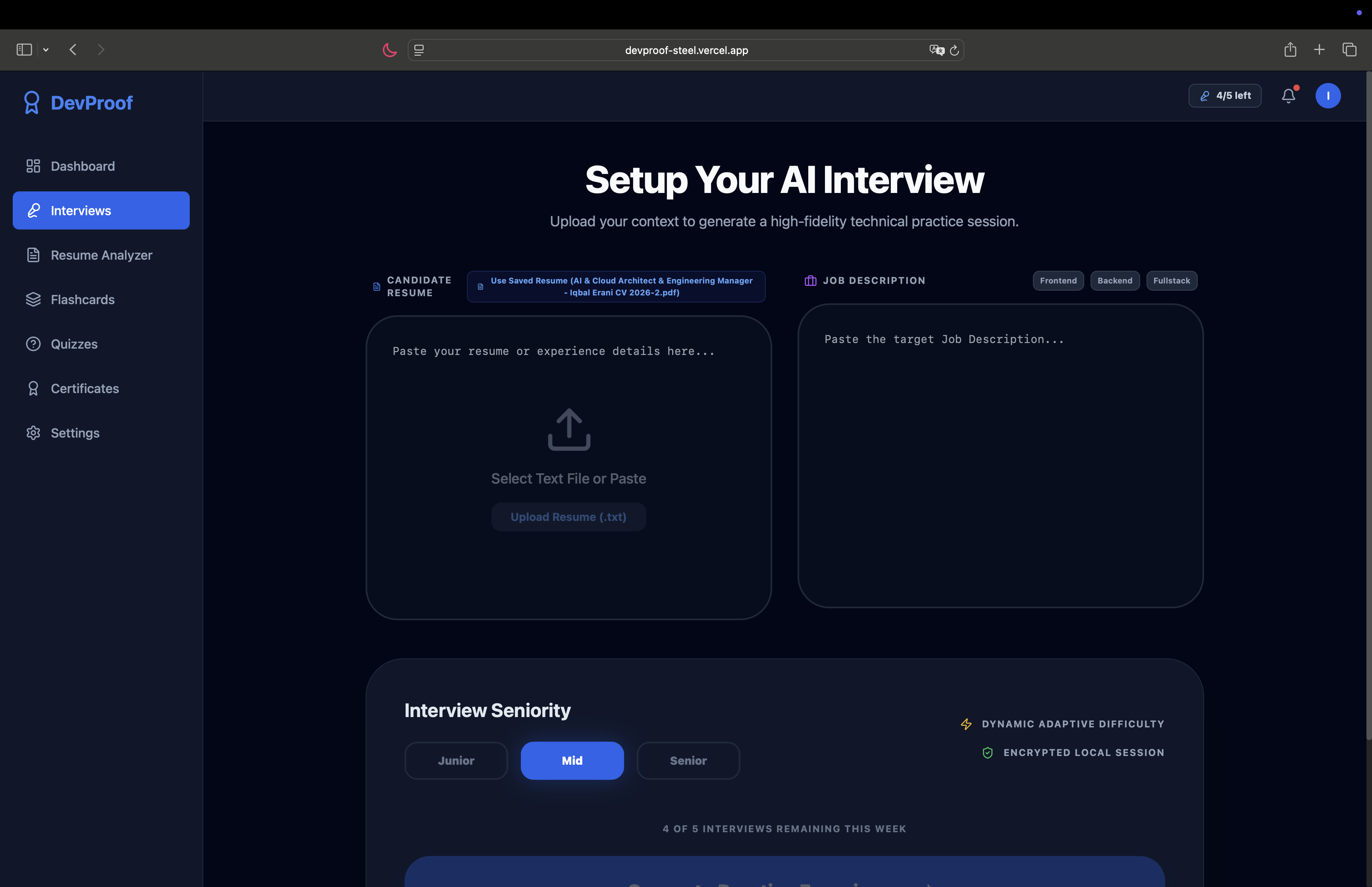
Live Voice Interview powered by Gemini Live API
-

AI-Verified Skill Certificate with Shareable Link
-
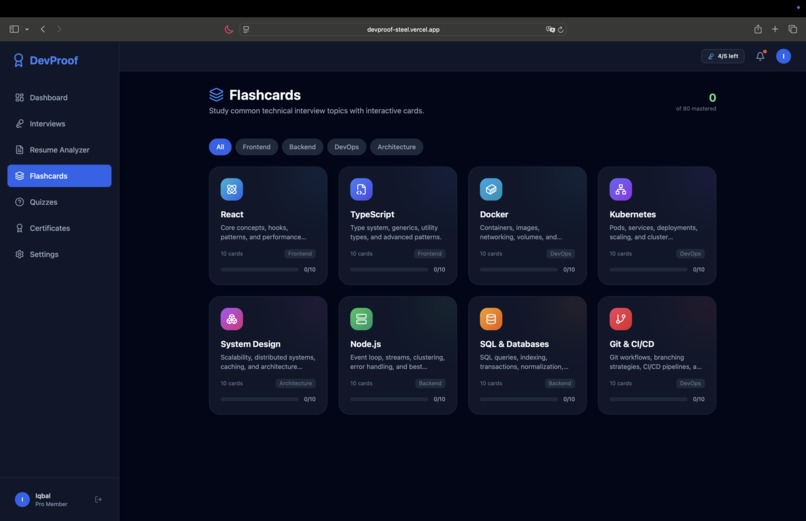
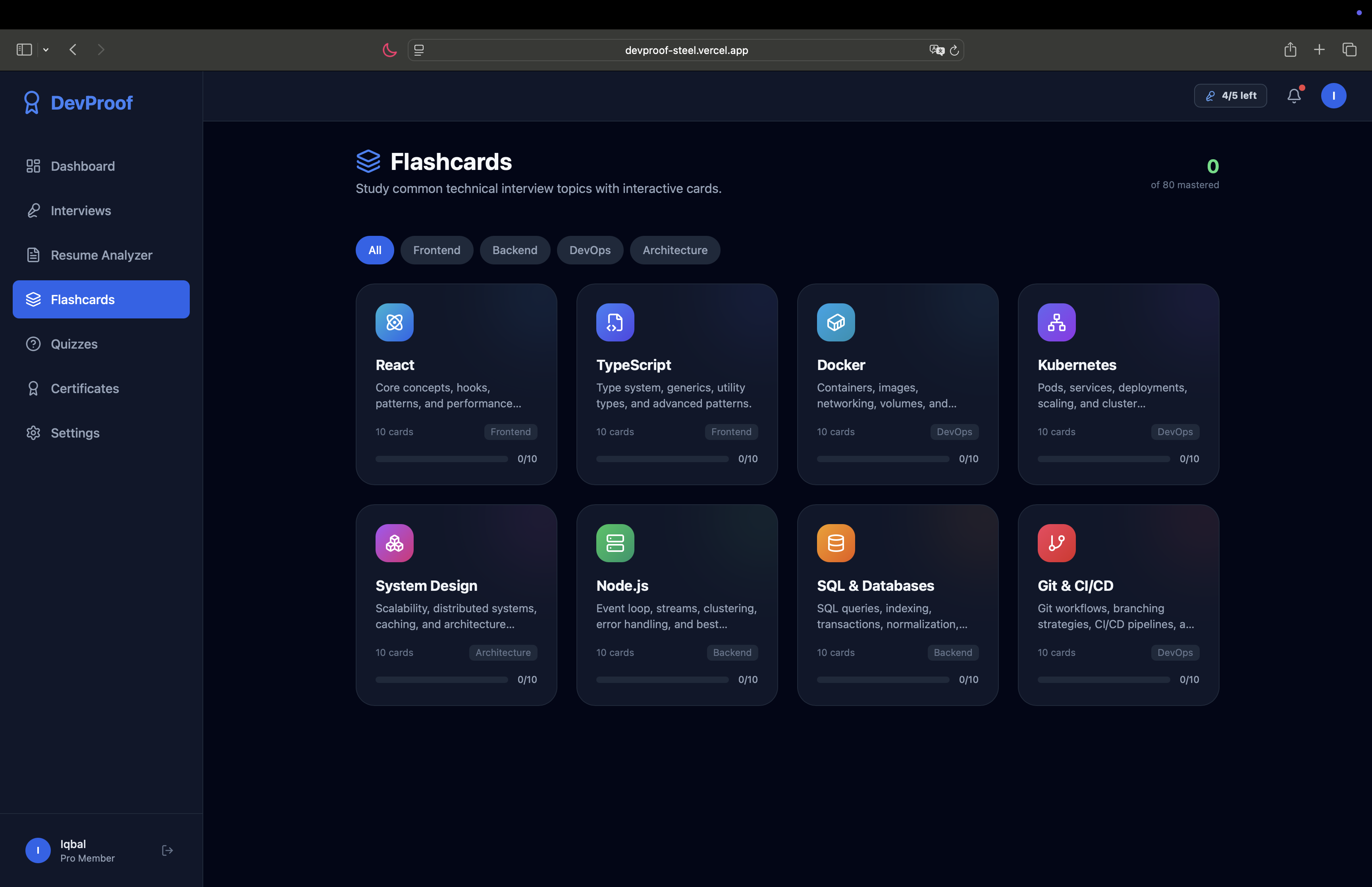
Technical Flashcards
-
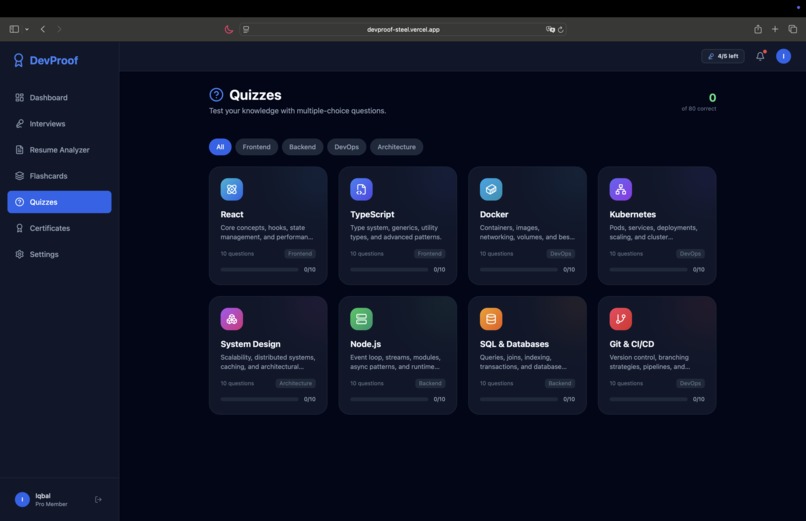
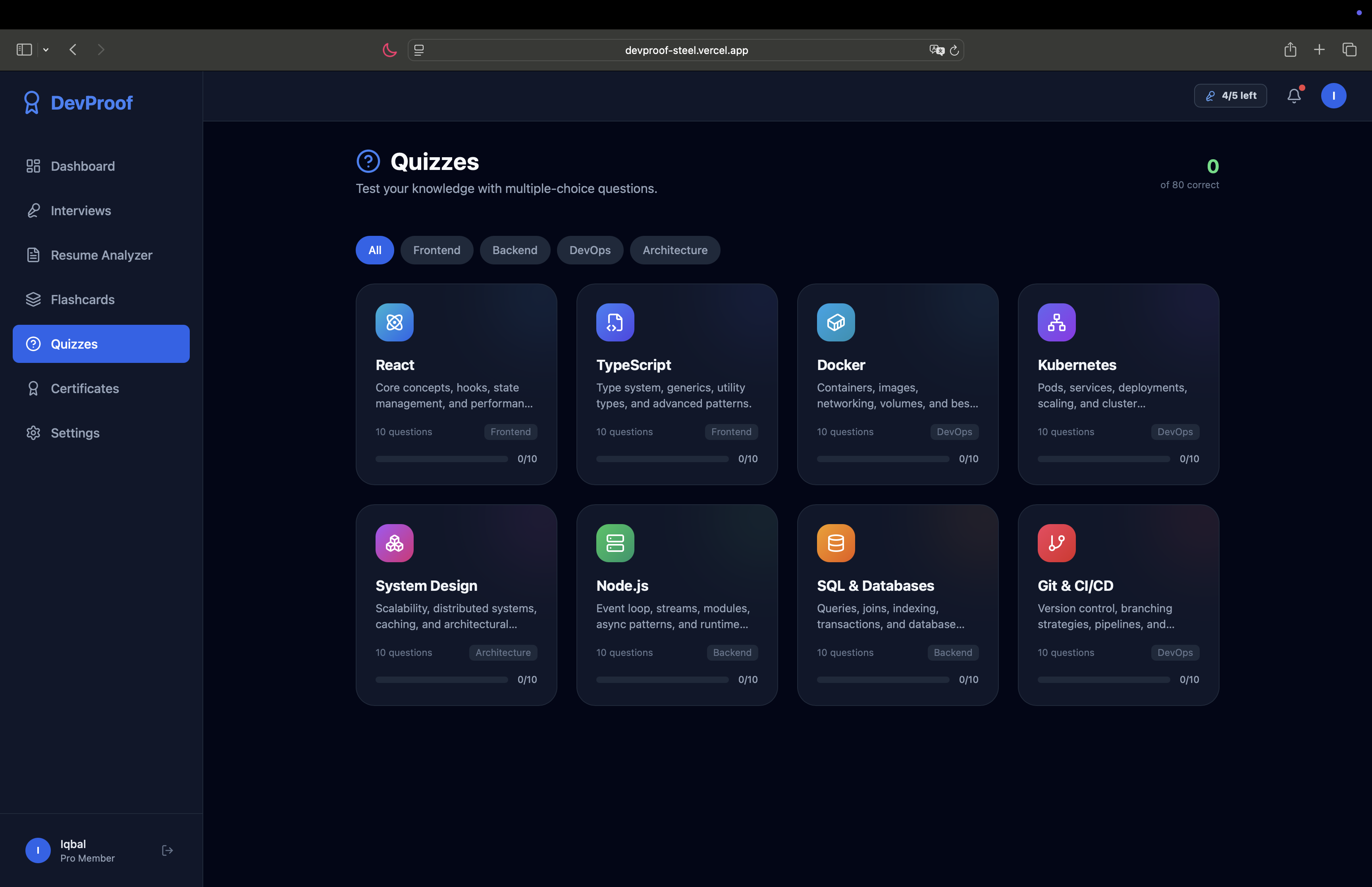
Quizzes with Progress Tracking & Mastery Scores
-
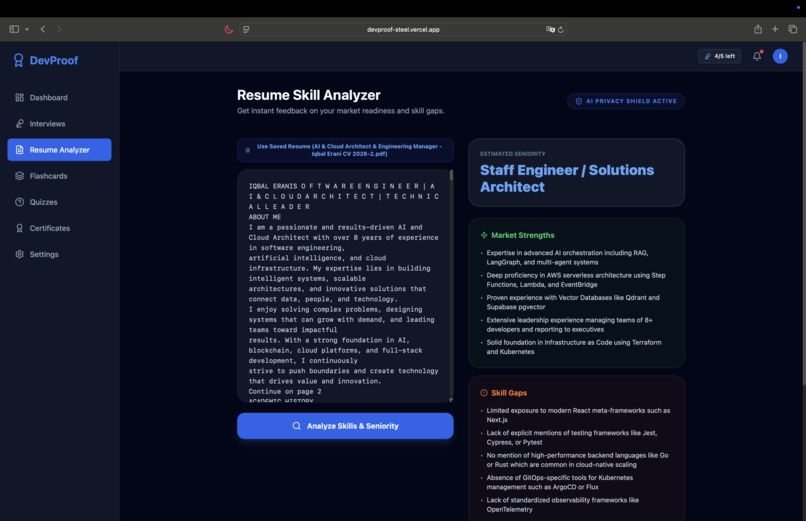
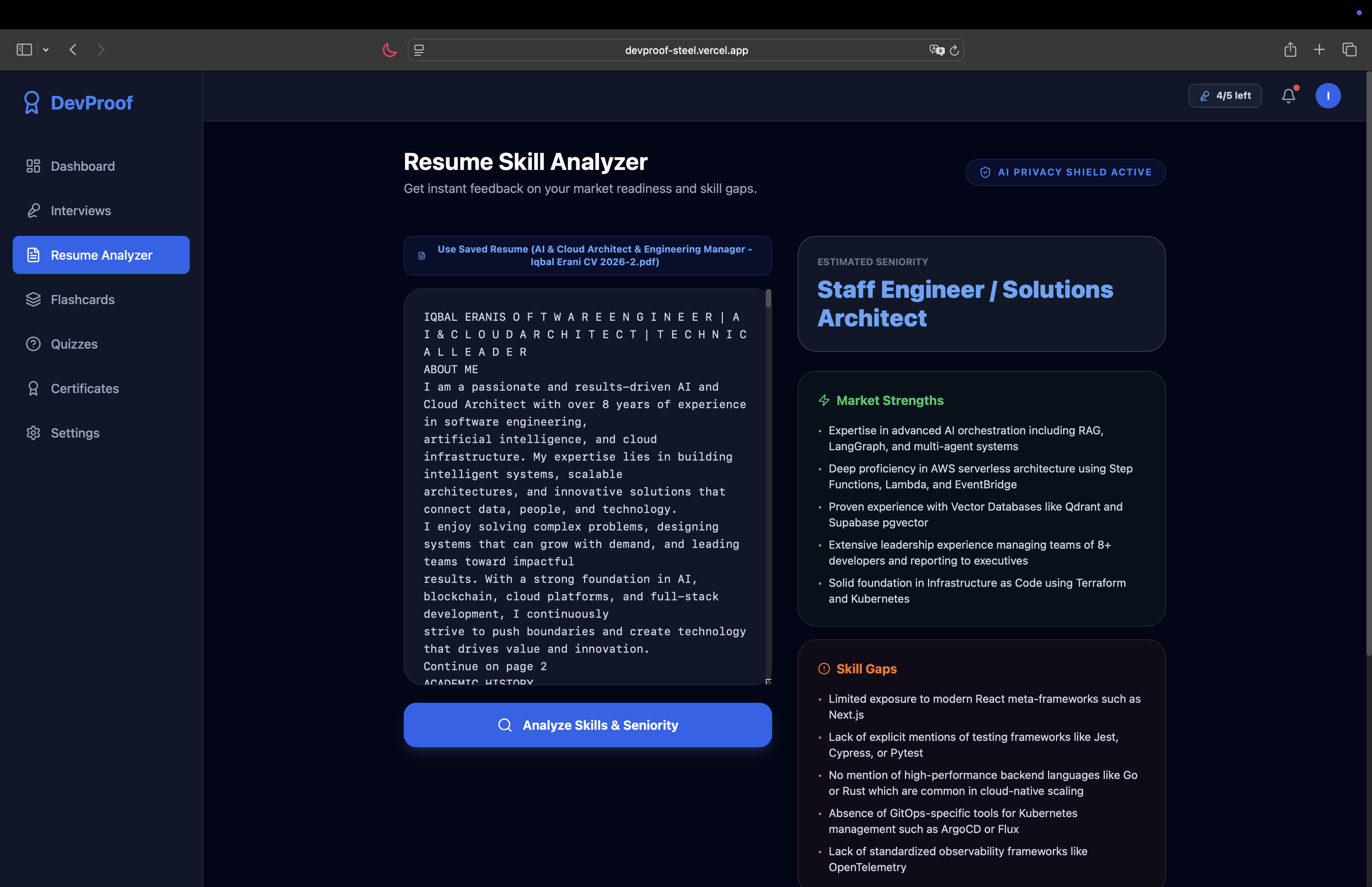
AI Resume Skill Analyzer with Privacy Shield

Inspiration
Technical interviews are broken. Developers spend weeks grinding LeetCode in isolation with zero feedback on how they actually communicate, think through problems, or handle pressure. Meanwhile, employers rely on inconsistent interview processes with no standardized way to verify technical skills beyond a resume bullet point.
I wanted to build something that feels like sitting across from a real interviewer — where you talk, think out loud, get follow-up questions, and receive structured feedback. Not a chatbot. A real conversational experience powered by AI.
What it does
DevProof AI is a full-stack platform that conducts live voice technical interviews using Google Gemini's Live API. Here's the flow:
Upload your resume + paste a job description — the AI analyzes both, generates a match score, and builds a personalized interview plan with behavioral, technical, and coding questions tailored to your background and the target role.
Enter a real-time voice interview — you talk to an AI interviewer that asks follow-up questions, transitions through phases (intro → behavioral → technical → coding → closing), and adapts based on your responses. A Monaco code editor appears during the coding phase for live problem solving.
Get scored and certified — after the session, Gemini evaluates the full transcript across 4 dimensions (Technical, Coding, Communication, Problem Solving), provides per-question feedback, and generates a downloadable PDF certificate.
Study between interviews — flashcard decks and quizzes cover 80+ technical concepts across 8 topic areas (React, TypeScript, Docker, Kubernetes, System Design, Node.js, SQL, Git & CI/CD) with progress tracking.
Analyze your resume — an AI-powered Resume Skill Analyzer evaluates your technical breadth, depth, and seniority alignment with instant feedback.
How we built it
Frontend: React 19 with TypeScript, Vite 6 for the build toolchain, Tailwind CSS 4 for styling, and Framer Motion 12 for animations. The audio pipeline uses the Web Audio API with AudioWorklet processors to capture microphone input at 16kHz PCM, which is streamed to the backend via native WebSockets. AI audio responses are decoded at 24kHz and played back through a separate AudioContext. Monaco Editor powers the coding phase, and Recharts handles data visualization.
Backend: Node.js with Express 4 serving REST APIs and WebSocket connections. MongoDB with Mongoose 8 handles persistence for sessions, transcripts, evaluations, and user accounts. The interview flow is orchestrated by an XState v5 finite state machine with 9 states (IDLE → CONNECTING → READY → USER_SPEAKING → AI_SPEAKING → TRANSITIONING → EVALUATING → COMPLETED + ERROR) ensuring deterministic transitions and preventing race conditions.
AI Integration: A multi-model strategy using 4 Gemini models:
- Gemini Live API (
gemini-2.5-flash-native-audio-preview) for real-time voice conversation - Gemini 3 Pro for post-interview evaluation
- Gemini 3 Flash for resume analysis
- Gemini 2.0 Flash for code analysis
Infrastructure: BullMQ with Redis for async evaluation processing (3x concurrency, rate-limited at 10 jobs/sec with graceful fallback to inline execution). JWT authentication with bcrypt password hashing. jsPDF for client-side certificate generation.
Key architectural decision: When transitioning between interview questions, the AI context is updated via text messages on the existing Live API session — no reconnection needed. This keeps conversation flowing naturally without losing context.
Challenges we ran into
The biggest challenge was making voice conversations feel natural. Early versions had phase transitions that required WebSocket reconnections, which broke AI context and caused awkward pauses. The solution was maintaining a single continuous Gemini Live API session throughout the entire interview and using text-based context updates for phase transitions.
Audio pipeline complexity. Browser autoplay restrictions, AudioContext resume requirements, and managing separate input (16kHz) and output (24kHz) audio contexts required careful lifecycle management. React's StrictMode caused double-mounting that triggered disconnect loops — we had to disable it and carefully manage useEffect dependencies.
AI interruptions during user speech. The AI would sometimes start responding before the user finished speaking. Implementing client-side voice activity detection with tuned timing thresholds (700-1100ms silence detection) and barge-in support resolved this.
Real-time transcript synchronization. Keeping the frontend UI, backend database, and Gemini session all in sync required careful WebSocket event contracts and MongoDB write ordering.
Accomplishments that we're proud of
- Sub-second latency voice conversations that genuinely feel like talking to a real interviewer
- Zero-reconnect question transitions — the entire multi-phase interview runs on a single persistent Gemini Live API session
- 9-state XState machine that makes the complex interview flow deterministic and debuggable
- Multi-model AI strategy where each Gemini model is optimized for its specific task
- Full-stack production architecture with JWT auth, async job queues, graceful error fallbacks, and real-time database persistence
- A polished UI with 7 distinct sections (Dashboard, Interviews, Resume Analyzer, Flashcards, Quizzes, Certificates, Settings) that feels like a complete product
What we learned
- Single continuous sessions are essential for natural voice AI — any reconnection destroys conversational flow and context
- XState v5 is incredibly powerful for managing complex real-time workflows with multiple actors and side effects
- AudioWorklet is significantly better than the deprecated ScriptProcessorNode for real-time audio processing
- The Gemini Live API is remarkably capable for real-time conversation when you architect around its strengths (persistent connections, text-based context injection)
- Building a hackathon project with production-grade architecture (auth, queues, state machines) pays off in reliability and demo-ability
What's next for DevProof AI
- Real code execution sandbox using Docker containers instead of simulated test runs
- Multi-language support in the coding editor (currently Python-focused)
- Team & enterprise features with candidate comparison dashboards and shared interview templates
- Spaced repetition algorithm for flashcards based on individual performance data
- Public API so companies can embed DevProof interviews into their hiring pipeline
- Full migration of remaining frontend AI calls to the backend for complete API key security
Built With
- 2.0
- bcrypt
- bullmq
- express.js
- flash
- framer-motion
- gemini
- gemini-3-flash
- gemini-3-pro
- google-gemini-live-api
- jspdf
- jwt
- monaco-editor
- mongodb
- mongoose
- node.js
- react
- recharts
- redis
- tailwind-css
- three.js
- typescript
- vite
- web-audio-api
- websockets
- xstate

Log in or sign up for Devpost to join the conversation.