-
-
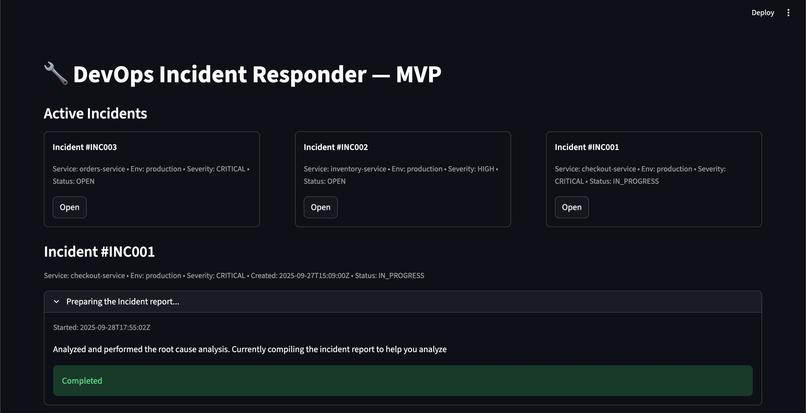
Landing Page
-
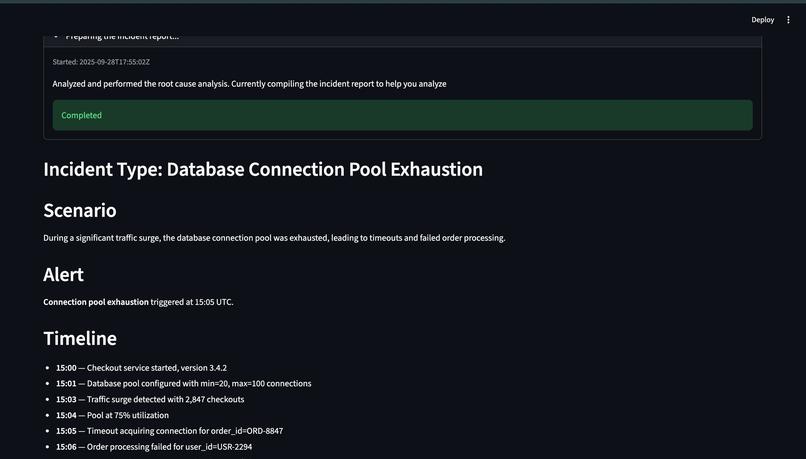
Incident analyzed and reported
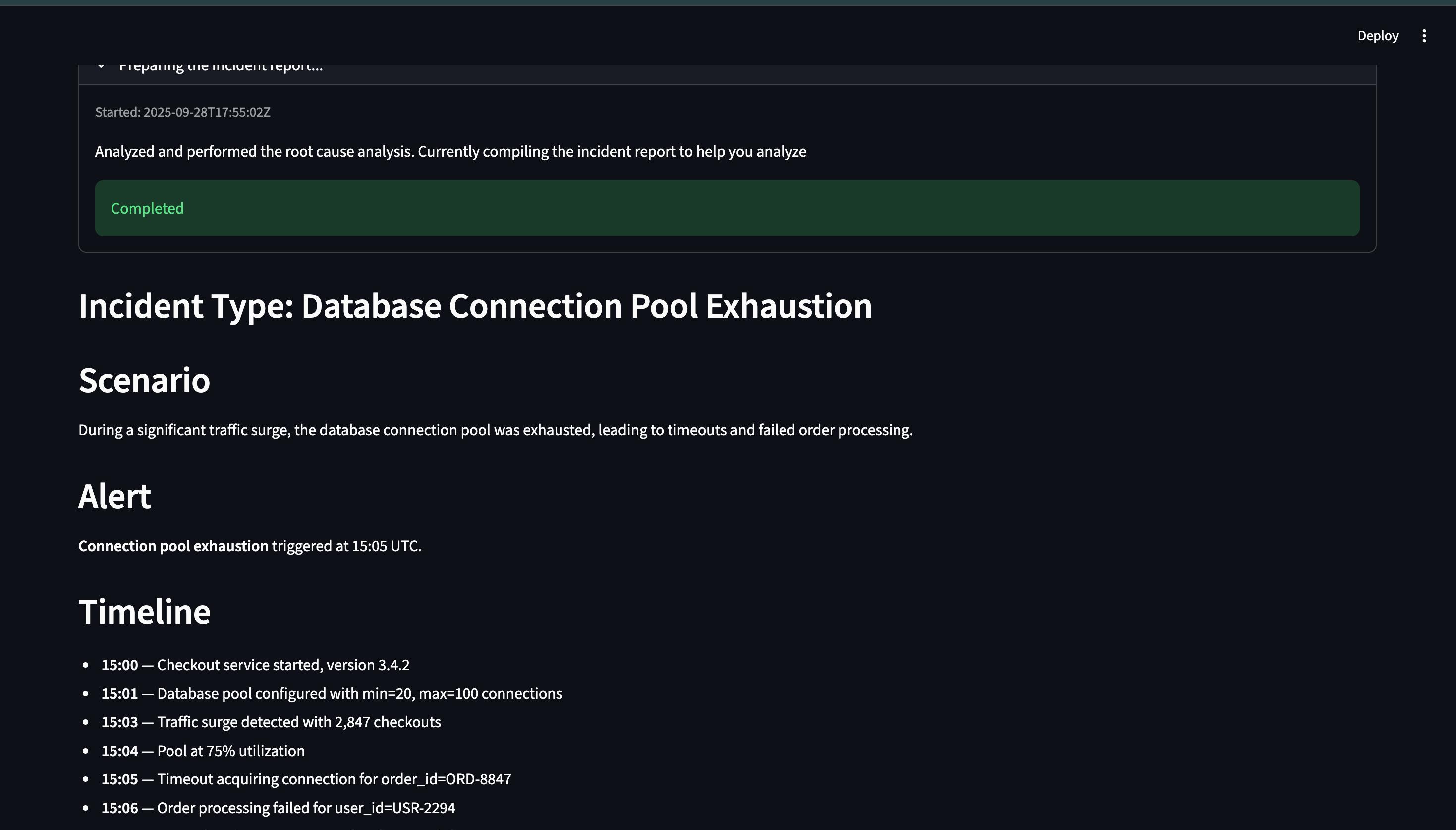
Inspiration On-call is chaotic. When an alert fires, engineers bounce between CloudWatch, S3, dashboards, and tons of wikis and documentation manually just to answer: What broke? Where? Why?
This significantly undermines developer productivity, while ineffective manual triaging cascades into substantial business impact for the enterprise due to delays in incident mitigation.
So... the solution? We wanted a calm, AI first-responder that turns noisy logs into a clear incident story and concrete next steps-so fewer 3 AM escalations and faster recoveries.
What it does Auto-triage: Listens for new incidents, pulls only the relevant logs/metrics, and detects patterns (deadlocks, spikes, timeouts, oversell, etc.).
Agentic analysis: Analyzes logs with a guided workflow to extract an incident timeline, root-cause hypothesis, and confidence score.
Actionable output: Produces a concise, shareable RCA plus a ranked playbook of fixes and safe checks to run.
Simple UI: A Streamlit dashboard shows active incidents, step-by-step reasoning, action plan that it takes and the generates the comprehensive incident report.
Drop-in: Works today with S3 logs + a lightweight SQLite store; built to add other providers easily.
How we built it
Architecture UI: ui/streamlit_app.py for incident cards, steps, and reports. Middleware: app/middleware/poll_incidents.py watches for new incidents and orchestrates analysis. Data layer: app/db/dev.db (SQLite) with tables for incidents, agent steps, and reports Agentic AI using LangGraph: A ReAct Agent that is engineered to perform the following: 1) scopes the incident, (2) fetches relevant logs (3) Compares with historical incident examples (4) explains the failure with historical evidence, (5) proposes next actions based on the knowledge base
Tech Python, Streamlit, SQLite, boto3, LangGraph for Agentic AI (ReAct Agent), PineCone for Knowledge base, S3 for incident logs
Dev loop Synthetic incidents (e.g., flash-sale deadlock/oversell) to validate end-to-end: ingest → analyze → RCA.
Challenges we ran into IAM and access: Getting the exact S3 permissions right (and learning bucket naming the hard way). Signal vs. noise: Real logs are messy; we had to aggressively scope to keep analysis focused. Token/latency budget: Budgeted evidence selection to stay fast while preserving accuracy. Consistency: Making the agent’s steps auditable so humans can trust (and override) its calls.
Accomplishments that we’re proud of,
End-to-end MVP in a day: From alert to a readable RCA with a ranked fix list. Human-friendly output: Clear incident timeline + hypothesis + confidence, not just blobbed text. Repeatable demos: Synthetic incidents that reliably reproduce deadlocks and contention patterns.
What we learned Scope ruthlessly: the best results came from less context but better evidence. Observability ≠ understanding: pairing logs with pattern detectors and an explanation step builds trust. Tooling matters: small UX touches (cards, steps, copy-paste RCAs) make adoption 10× easier.
What’s next for DevOps Incident Responder Live integrations: Slack/MS Teams summaries, Jira/GitHub issue creation, PagerDuty enrichment. Remediation-as-Code: Safe, parameterized runbooks the agent can execute (with guardrails). More sources: Kinesis/Firehose, Kubernetes events, Postgres/MySQL slow logs. Knowledge memory: Learn from past incidents to auto-suggest fixes that worked before. Eval bench: Replay real outages to measure MTTA/MTTR reductions and explanation quality. Engineering 101: Handle advanced chunking techniques to parse through huge logs and still maintain memory and context on the incidents
Note: Refer to the develop_test_1 branch in the given GitHub repository for the final code.
Built With
- amazon-web-services
- langgraph
- openai
- pinecone
- python
- rag
- react
- s3
- sqlite
- streamlit







Log in or sign up for Devpost to join the conversation.