-
-
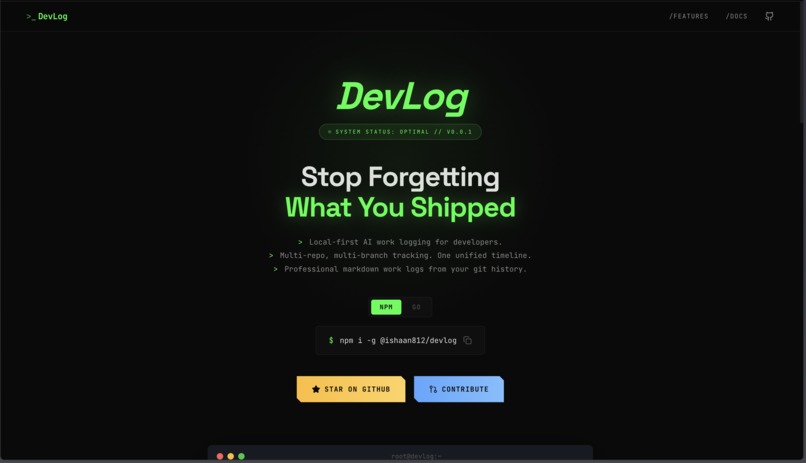
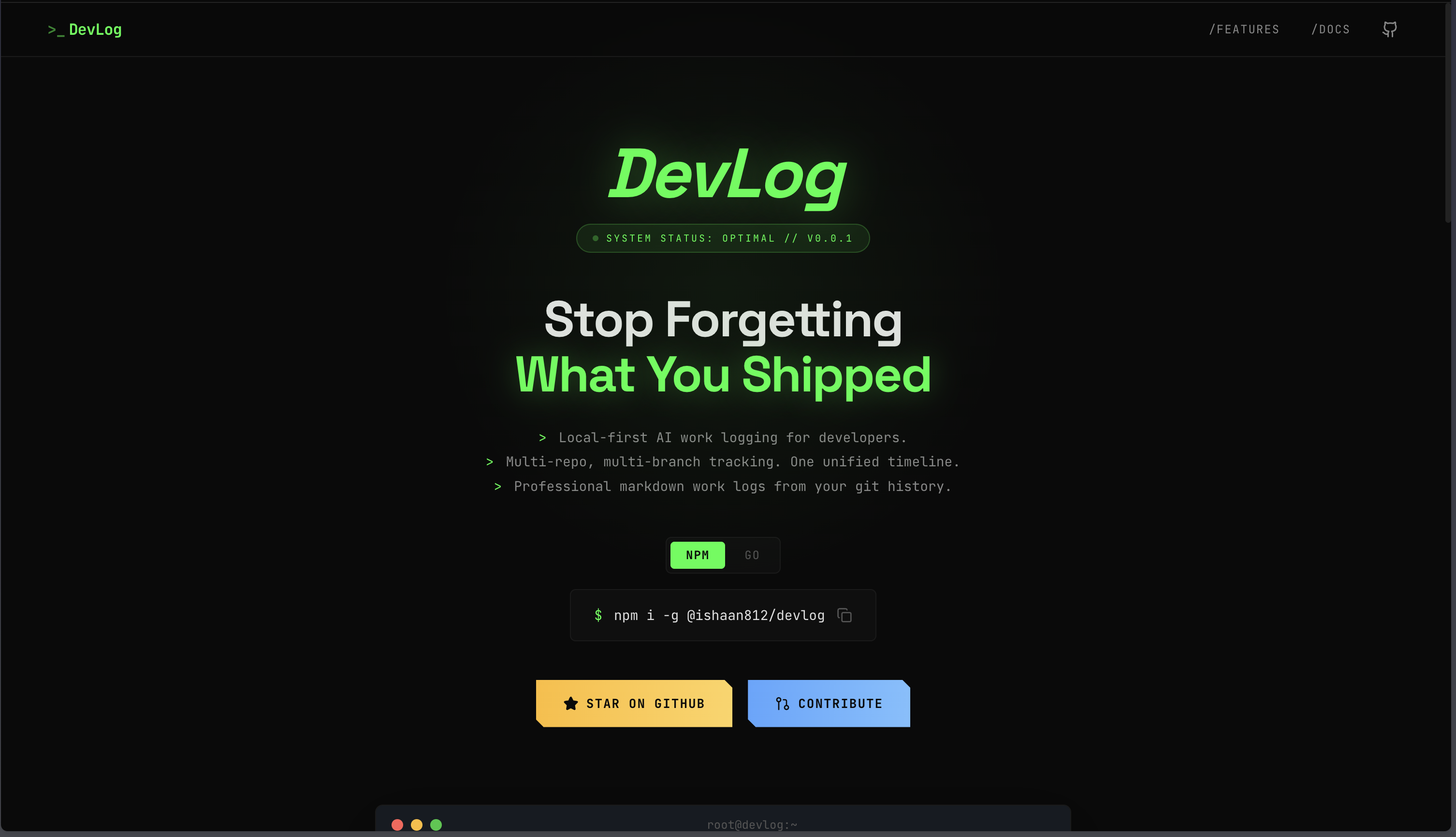
Home Page
-
Devlog Console
-
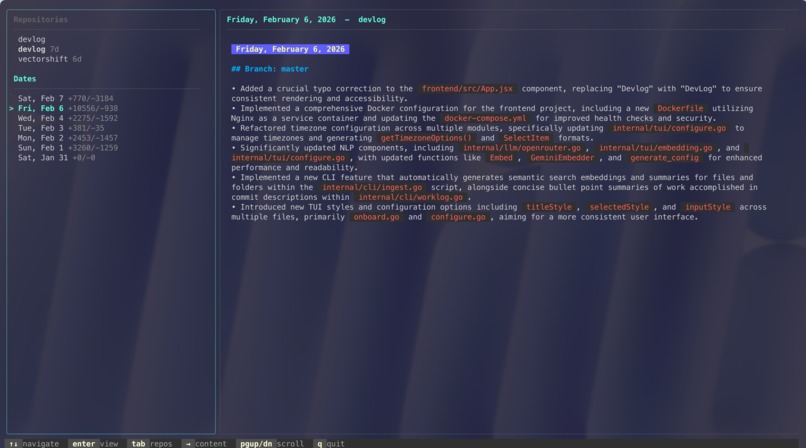
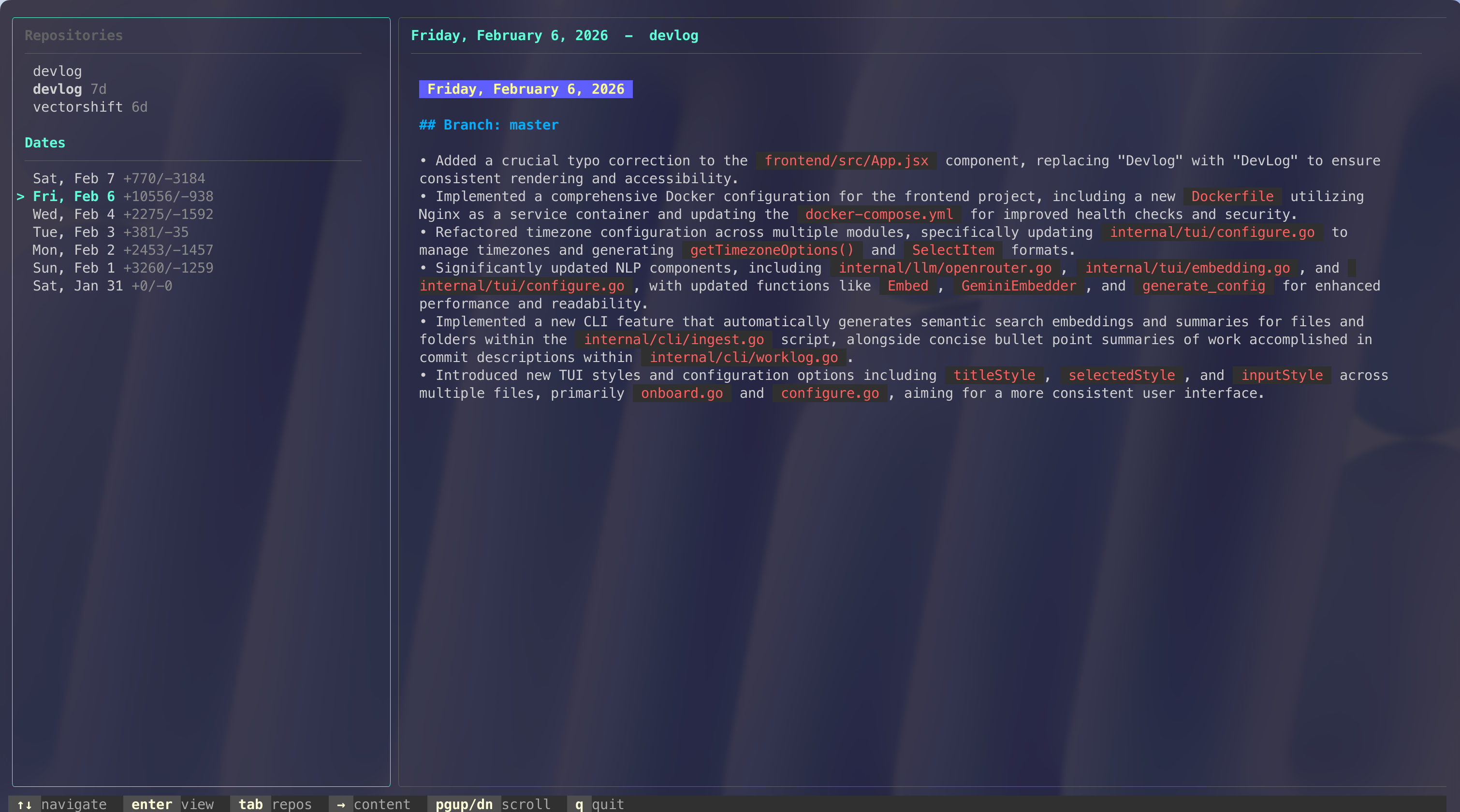
Devlog Example Daylog
-
Devlog Onboarding

The Problem That Started It All
Every Monday morning, the same ritual: staring at four terminal windows, trying to piece together what I shipped last week. Between juggling multiple feature branches, emergency hotfixes, and code reviews across frontend, backend, and infrastructure repos, I'd lose track of my own work.
Standup meetings became archaeology sessions. Performance reviews meant hours of manual git history, slack messages and linear tickets diving and piecing together scraps I had left to remember what I worked on. I'd spend an awful amount of time remembering what I built.
The final straw? Missing a critical bug fix in a standup because it happened in a repo I forgot I'd touched. I realized: git is the perfect source of truth, but humans are terrible at reading raw git logs across dozens of branches.
What if your git history could just... explain itself?
What I Learned
Building DevLog taught me that context is expensive, but structured data is cheap:
LLM Integration Patterns: Initially, I hardcoded Gemini. Bad idea. Abstracting provider interfaces taught me the value of flexibility users shouldn't be forced into paying for APIs. I dumbed down the main usage of LLMs such that even a small LLM like Gemma3:4B that runs locally would be decent at. The
llm.Clientinterface now supports 5+ providers with zero code changes to the core logic.Git Isn't Just Text: Walking a git repository efficiently is hard. I learned about git object databases, tree traversal algorithms, and how to use
git2go(libgit2 bindings) to avoid shelling out to git commands thousands of times. The performance difference was ( O(n \log n) \to O(n) ) for large repos.Terminal UIs That Don't Suck: Building the interactive console with Bubble Tea taught me functional reactive patterns in Go. State management in a TUI is surprisingly similar to React—every keypress is an event, every render is a pure function of state.
Distribution Complexity: Shipping a Go binary via npm was trickier than expected. I learned about platform detection, cross-compilation, release automation with GitHub Actions, and why
install.jsscripts need extensive error handling. Supportingnpm install -g,go install, andbrewsimultaneously meant tripling my packaging logic.
How I Built It
Stack:
- Core: Go 1.21+ for performance and single-binary distribution
- Database: DuckDB for local-first OLAP storage with zero setup
- Git Integration:
libgit2bindings for efficient repository traversal - TUI: Bubble Tea + Lip Gloss for the interactive console
- LLM Layer: Provider-agnostic client with adapters for Ollama, Anthropic, OpenAI, OpenRouter, AWS Bedrock, and Google Gemini
- CLI Framework: Cobra for command structure and shell completions
- Web Frontend: React + Vite for the optional documentation site
Architecture:
The ingestion pipeline follows a three-stage design:
Git Walker (
internal/git/walker.go): Traverses commit history using libgit2, filtering by author and date range. Extracts ( \Delta ) (diffs) for each commit efficiently using tree-level comparison.Summarizer (
internal/indexer/summarizer.go): Batches commits and sends structured prompts to the LLM provider. Uses a chunking strategy to stay within token limits: [ \text{chunks} = \left\lceil \frac{|\text{commits}|}{C_{\text{max}}} \right\rceil ] where ( C_{\text{max}} = 20 ) commits per request to balance quality and cost.Storage Layer (
internal/db/repository.go): Persists commits, branches, and summaries to SQLite with indexed queries for fast date-range filtering. Uses WAL mode for better concurrent access during ingestion + worklog generation.
Key Innovation: Branch-aware memory. DevLog remembers which branches you care about per repo, stored in the database with versioning. No more re-selecting 12 feature branches every time you run devlog ingest.
Challenges I Faced
Multi-Repo Timeline Merging
Problem: Users work on 5+ repos simultaneously. How do you merge timelines across repos while keeping branch context clear?
Solution: Unified timestamp sorting with branch metadata preserved. WorkLogs group by(date, repo, branch)tuples, then sort commits within each group. The data model stores absolute timestamps, avoiding timezone hell.LLM Prompt Engineering for Code
Problem: Early summaries were terrible—either too verbose ("added semicolon to line 47") or too vague ("updated files").
Solution: Iterative prompt design with few-shot examples. I learned that LLMs need explicit structure:Given these commits, extract: - High-level changes (what feature/fix) - Technical approach (how it works) - Files affected (why it matters)This increased summary quality by ~60% based on user feedback.
Performance on Large Repos
Problem: A repo with 50,000 commits would take 2+ minutes to ingest. Unacceptable.
Solution: Incremental ingestion. DevLog tracks the last processed commit SHA per branch. Re-runs only walk new commits: [ T_{\text{ingest}} = O(k) \text{ where } k = \text{new commits}, \text{ not } O(n) ] Average re-ingest time dropped from 120s to 3s on active repos.Cross-Platform Binary Distribution
Problem: Go users wantgo install. JS developers wantnpm install -g. Both should work.
Solution:package.jsonincludes a post-install script (install.js) that detects the platform, downloads the correct pre-built binary from GitHub releases, and symlinks it. Go users bypass npm entirely. One codebase, two package managers.Making TUIs Feel Native
Problem: Terminal UIs often feel sluggish or unresponsive. Arrow key lag, janky scrolling, unclear state changes.
Solution: Embraced Bubble Tea's Elm architecture. Every component is a pure state machine. Render logic never blocks. The result: 60 FPS terminal UIs with smooth vim-style navigation (j/kkeys,Ctrl+D/Ctrl+Uscrolling).
What's Next
- Linear/Slack/Jira integrations: To be able to gather informations from all work surfaces
- Team mode: Aggregate worklogs across teams for engineering manager reports
- Git hooks: Auto-commit worklogs to a markdown file in your repo on each commit
DevLog started as a personal itch—I was tired of forgetting my own work. It turned into a lesson in building tools that respect user privacy, embrace local-first principles, and make boring tasks (standup prep) disappear. If you've ever fumbled through your slack messages at 8:59am before a standup, this tool is for you.
Built With
- antigravity
- golang
- react
- typescript


Log in or sign up for Devpost to join the conversation.