DevBrain — Persistent Engineering Memory for AI Coding Agents
A shared, long-term memory layer that lets AI agents query a team's past fixes, decisions, and patterns over the Model Context Protocol built on Gemini (Vertex AI), Google Cloud Run, and MongoDB Atlas Vector Search.
Inspiration
AI coding agents forget everything between sessions, and the knowledge stays trapped in one repo. When a developer spends hours fixing a race condition, a mobile safe-area overlap, or a subtle DB connection issue, that hard-won fix vanishes when the terminal closes and the next teammate (or their agent) on a sibling project re-derives it from scratch. We wanted a memory that survives the session and crosses repository boundaries.
What it does
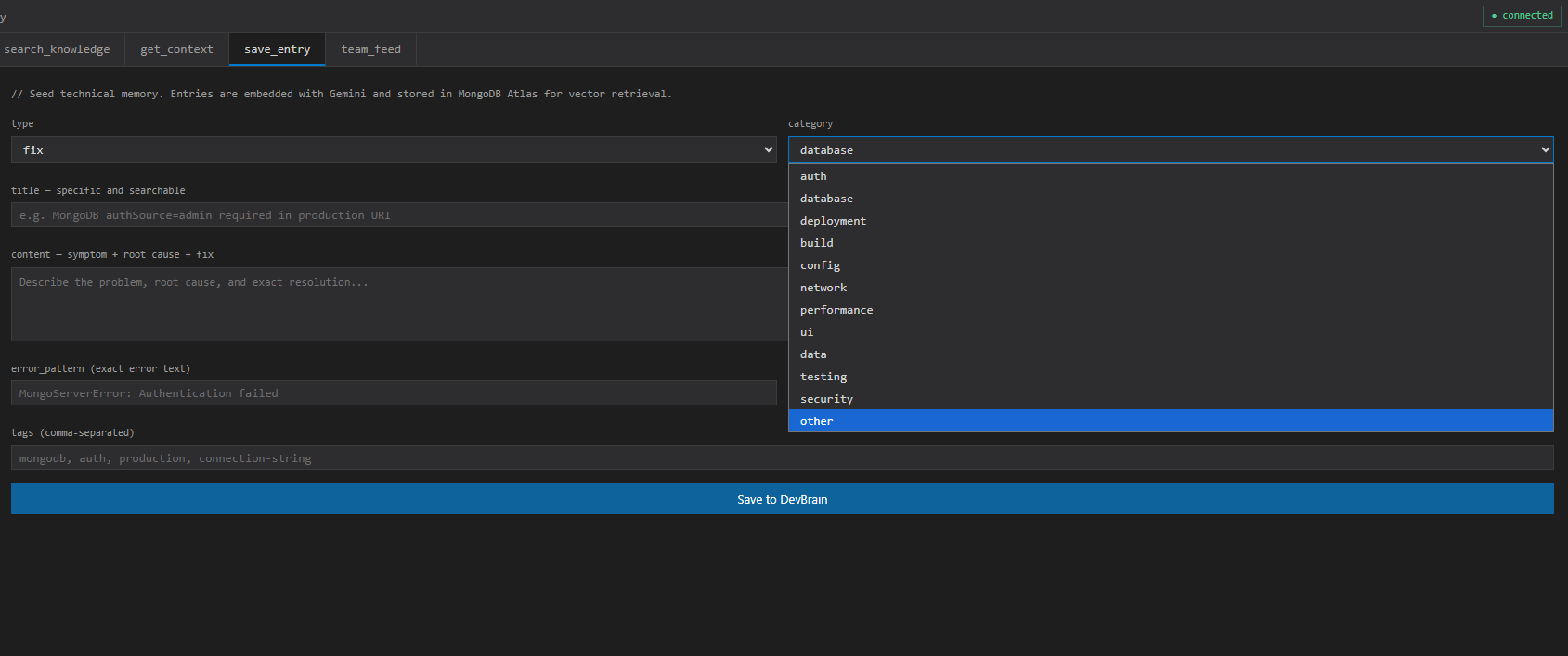
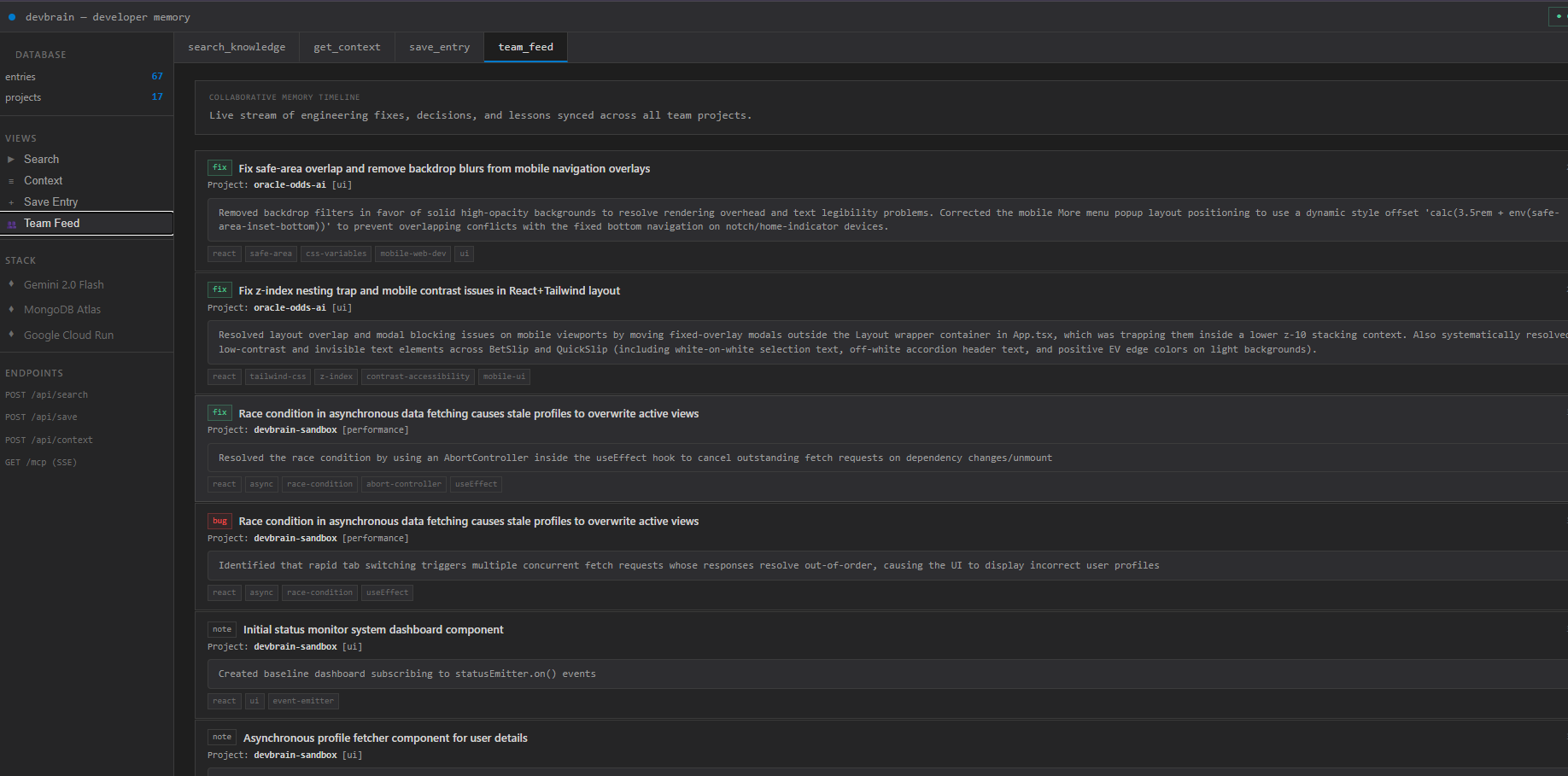
DevBrain gives agents a persistent, shared knowledge base they can read and write through an open protocol: Autonomous capture from commits. A post-commit Git hook sends each diff to Gemini, which extracts the problem, the fix, tags, the category, the exact error pattern, and a transferable cause archetype then stores it as a structured entry. No manual docs. Hybrid two-pass retrieval. When an agent hits an error, DevBrain first does exact/fuzzy matching on stored error text, then falls back to semantic cosine similarity over 3072-dimension embeddings in MongoDB Atlas Vector Search so pasting an exact error finds the specific past fix, not just something vaguely related. Memory that compounds. Entries retrieved repeatedly get promoted observation → corroborated → confirmed, and entries seen across multiple projects are flagged as cross-project patterns that surface in every future context load. Shared knowledge across codebases. Every project writes to one shared Atlas database, so a team pointing at the same connection string builds collective memory. The web dashboard shows a shared activity timeline across all registered codebases, and the CLI surfaces recent entries from your other projects during context loads so a layout fix saved in a mobile repo reaches the web frontend developer instead of being resolved again. Agent integration (the core) DevBrain exposes its memory as an MCP server (get_context, search_knowledge, save_entry, query_entries, get_project_summary). Any MCP-compliant agent Claude, Gemini, Cursor, or Agent Builder connects and receives the team's historical lessons before starting a task, grounding the agent in past decisions to reduce hallucinations and keep it consistent with what the team already settled. Our own Gemini agent, built on Google's ADK (@google/adk), consumes that server over Streamable HTTP and also reads the official MongoDB MCP server for live database queries.
How we built it
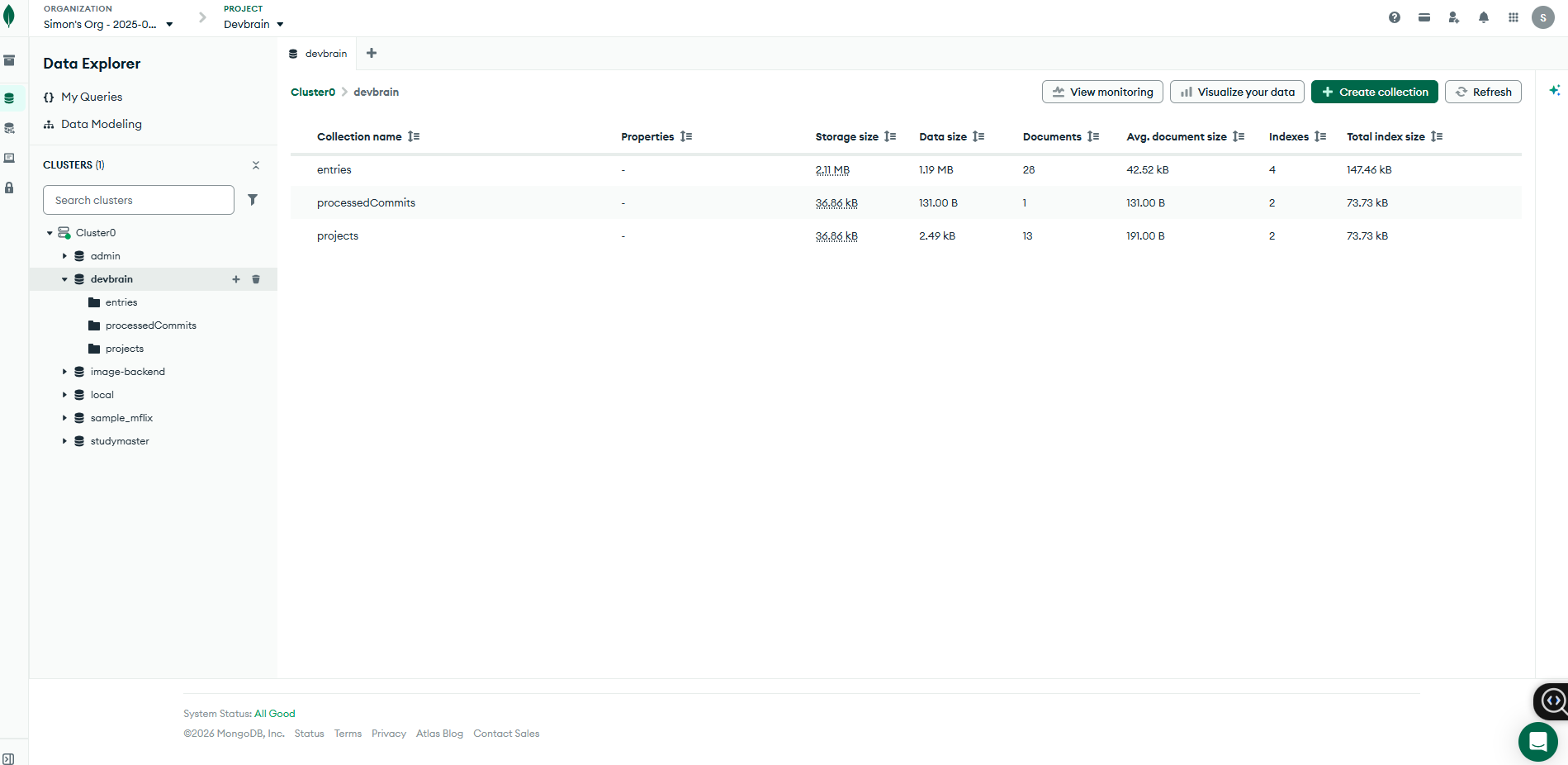
Reasoning: Gemini 2.5 Flash on Vertex AI powers knowledge extraction, query classification, section synthesis, and session recap. Embeddings: gemini-embedding-001 on Vertex AI, 3072-dim, authenticated via Application Default Credentials (no API keys in production). Vector store: MongoDB Atlas Vector Search ($vectorSearch, cosine) with hybrid pattern match + semantic re-ranking (semantic, recency, same-project, same-stack, usage, confidence, category, cross-project). Partner MCP: integrates the official @mongodb-js/mongodb-mcp-server over stdio for agent-driven DB access. Deployment: stateless container on Google Cloud Run, MCP served over SSE/Streamable HTTP, a fresh transport spun up per connection to avoid session cross-talk. Surfaces: a TypeScript CLI with an interactive REPL, and a dark-mode web dashboard (search, context, and the team feed). Challenges we ran into Getting onto Google Cloud AI properly. We started on the Gemini Developer API and migrated the entire reasoning + embedding pipeline (and the ADK agent) to Vertex AI behind a single env switch, so the same model IDs and 3072-dim schema work in cloud (ADC) and local dev without touching the Atlas index. Exact-error recall. Pure semantic search missed cases where an identical error was saved with different surrounding words, which is why we added the high-precision errorPattern pass before vector search. Stateless SSE on Cloud Run. Concurrent agents sharing one MCP server caused state pollution; isolating a fresh Server/transport per request fixed it. Accomplishments A working end-to-end loop: commit → Gemini extraction on Vertex → Atlas vector store → agent retrieval over MCP, with cross-project surfacing that actually shares fixes between repos.
What we learned
Retrieval quality for engineering knowledge depends more on hybrid matching and confidence promotion than on raw embedding similarity, and an open protocol (MCP) is what makes the memory portable across every agent a team already uses.
What's next Evolve DevBrain from retrieval into a preventative guardrail: a CI/CD check on pull requests that flags when a developer or agent is about to reintroduce a bug or anti-pattern someone already solved and recorded in another repo catching it before merge.
Built With
- gemini
- gemini2.5flash
- googlecloud-run
- mcp
- mongodb-atlas
- mongodb-mcp
- node.js
- typescript
- vertexai


Log in or sign up for Devpost to join the conversation.