Inspiration
Dev2Prod came from a very familiar feeling: thinking a system is “production ready” because the happy path works, and then learning the truth at the worst possible time.
We have both been in situations where an app looked fine in normal conditions, but once a pod restarted, traffic spiked, or the system slowed down in an unexpected way, the real gaps showed up immediately. The problem usually was not just the failure itself. It was the experience around it. The signals were scattered. The workflow was fragmented. You ended up bouncing between dashboards, logs, shell sessions, YAML, CI output, and half-remembered commands while trying to answer basic questions like:
- What actually broke?
- Is the app still usable?
- Is it recovering?
- Did the change we made help at all?
That is what pushed us toward this project.
We did not want to build just another sample app with a few DevOps features attached to it. We wanted to build a product-shaped platform around resilience and scale, something that feels relevant to the way real teams work. The URL shortener in this project is intentionally basic because it is not the point. It is the workload we use to make the platform legible. The real work went into the infrastructure, the control plane, the recovery flows, the scale lab, and the documentation around them.
Our goal was not just to satisfy the quest checklist. We wanted to build something we would genuinely want to use before shipping a workload.
What it does
Dev2Prod is a controlled chaos and scale lab for Kubernetes workloads.
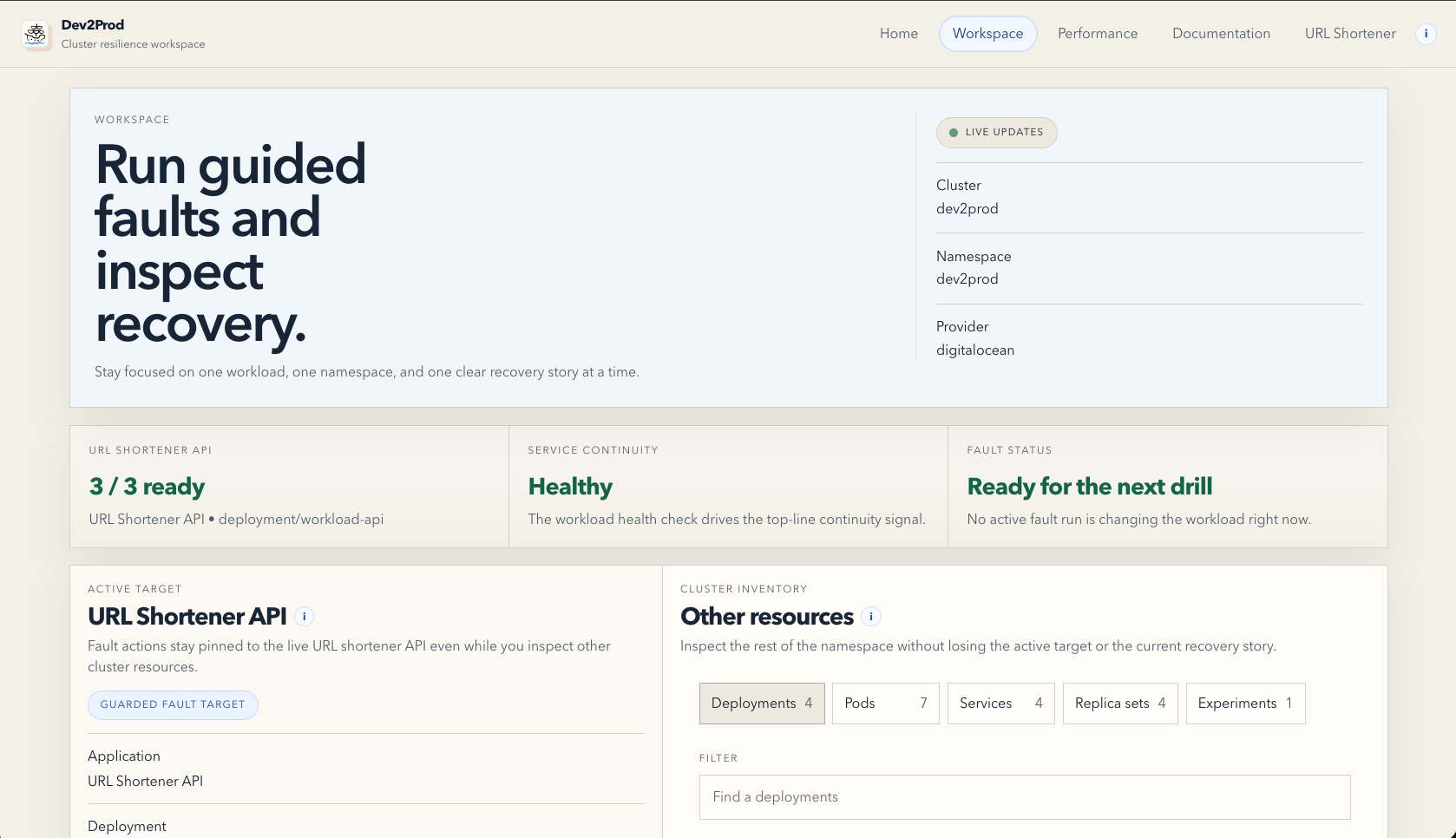
It gives the user three main surfaces:
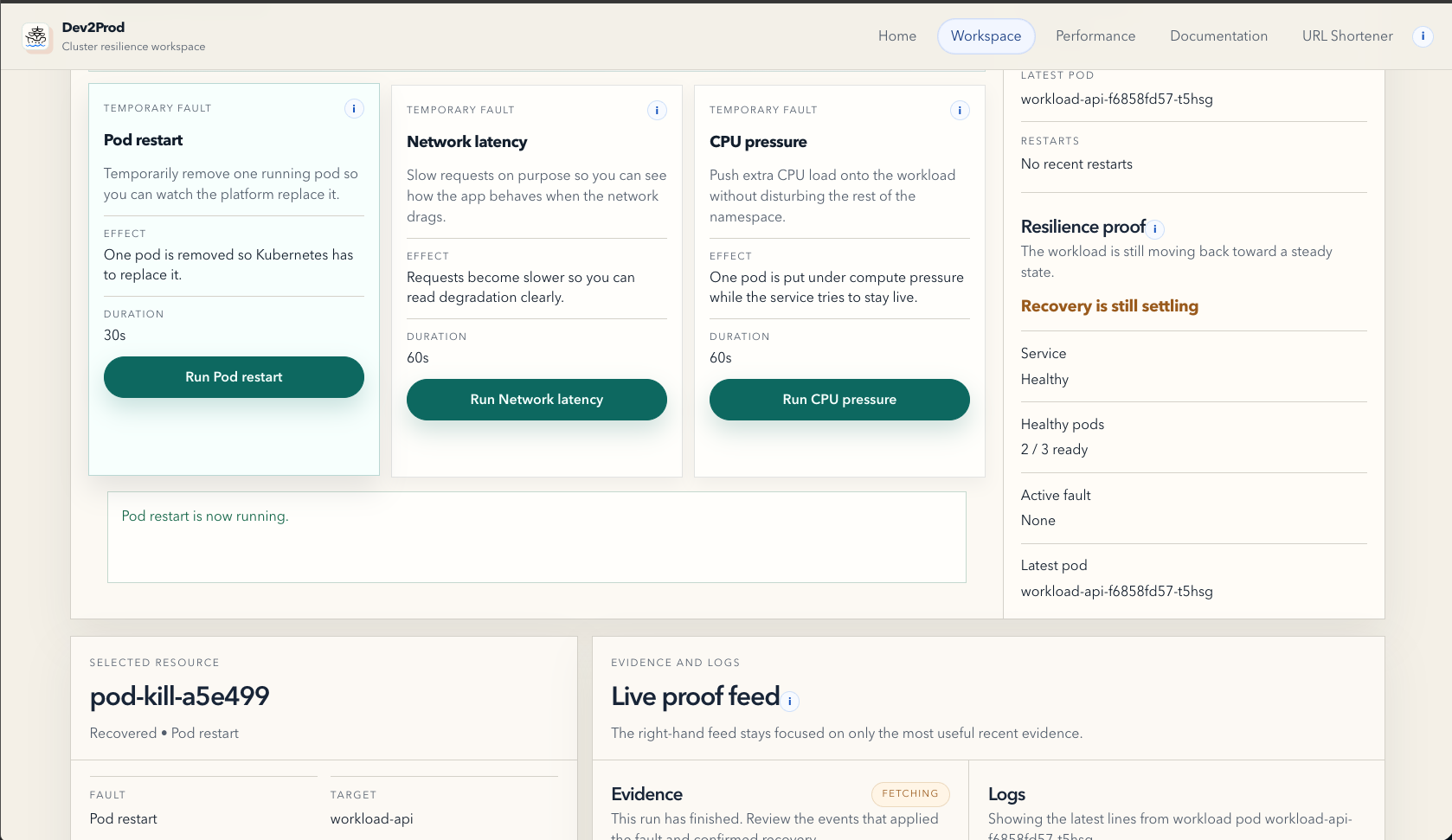
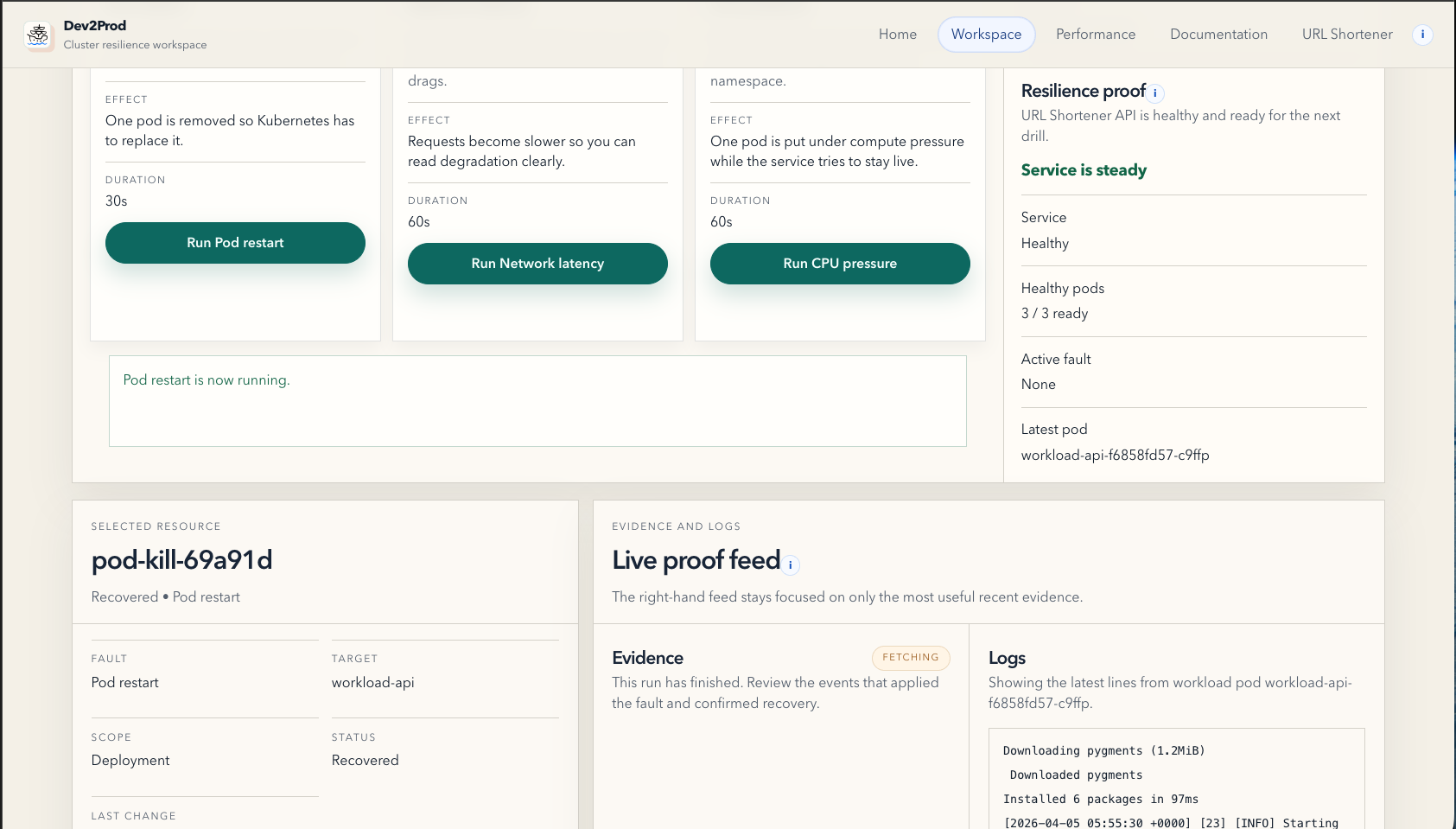
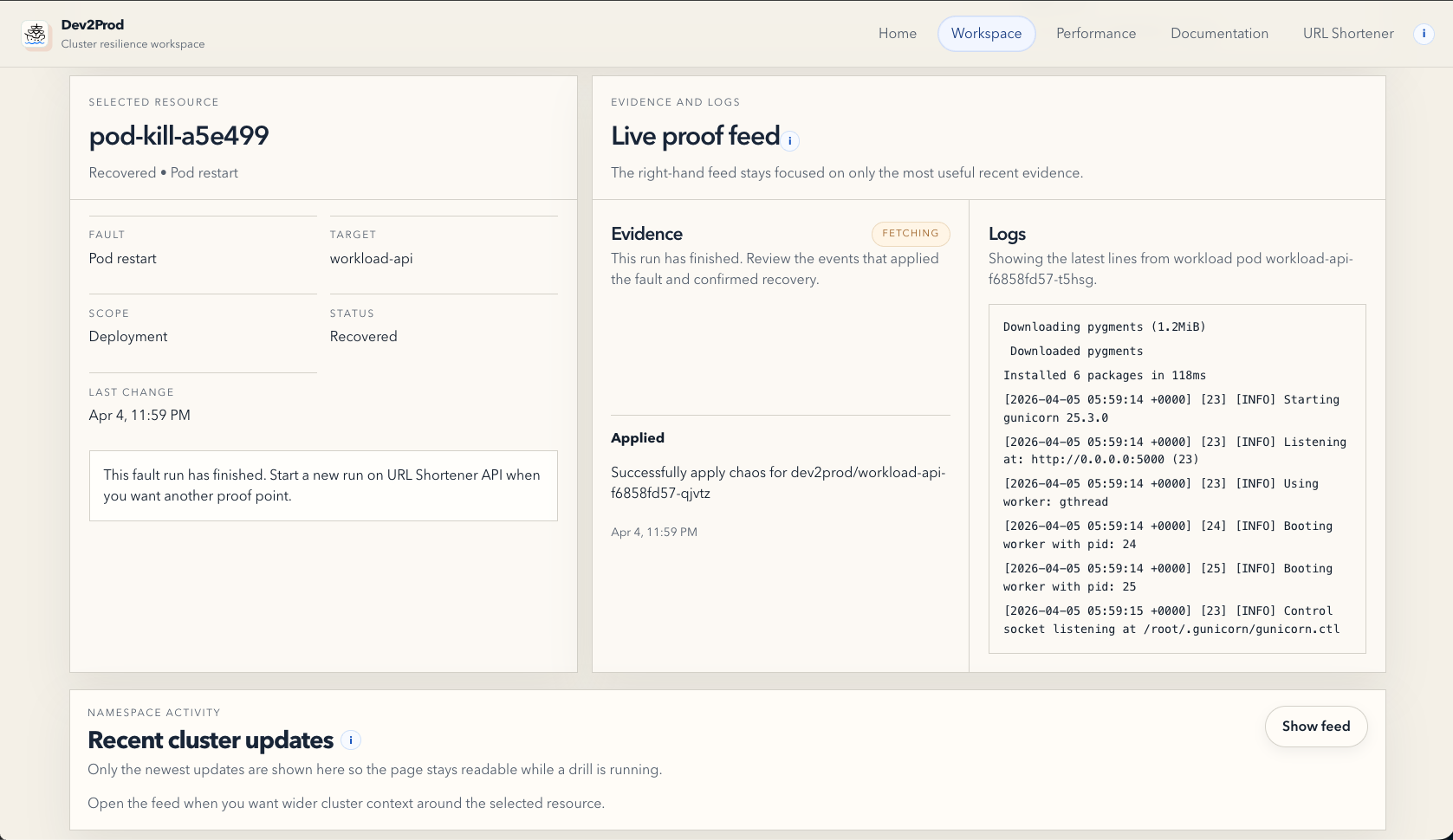
- Workspace, where you can run guided fault drills like pod restarts, CPU pressure, and network latency, then watch how the system responds.
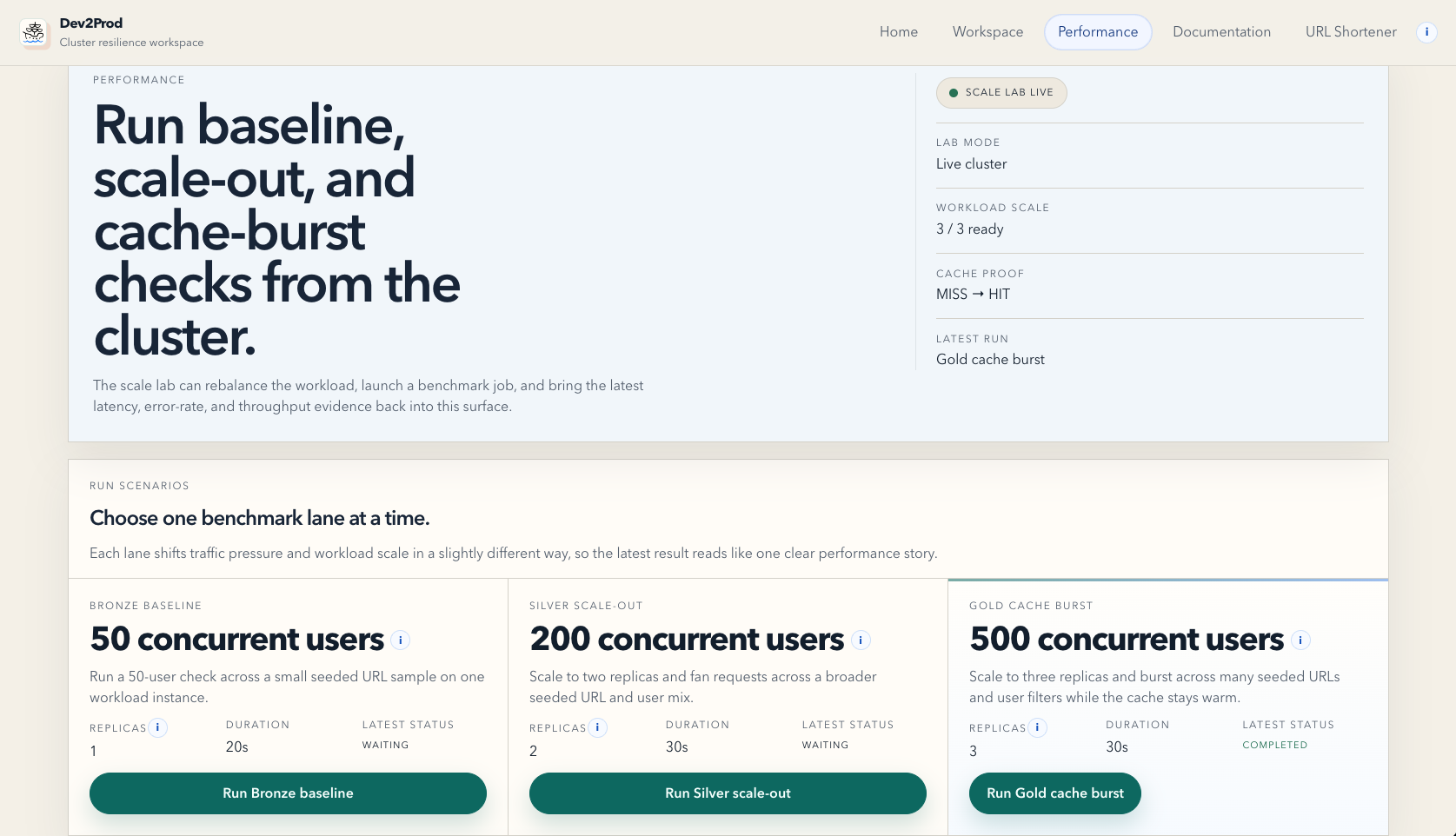
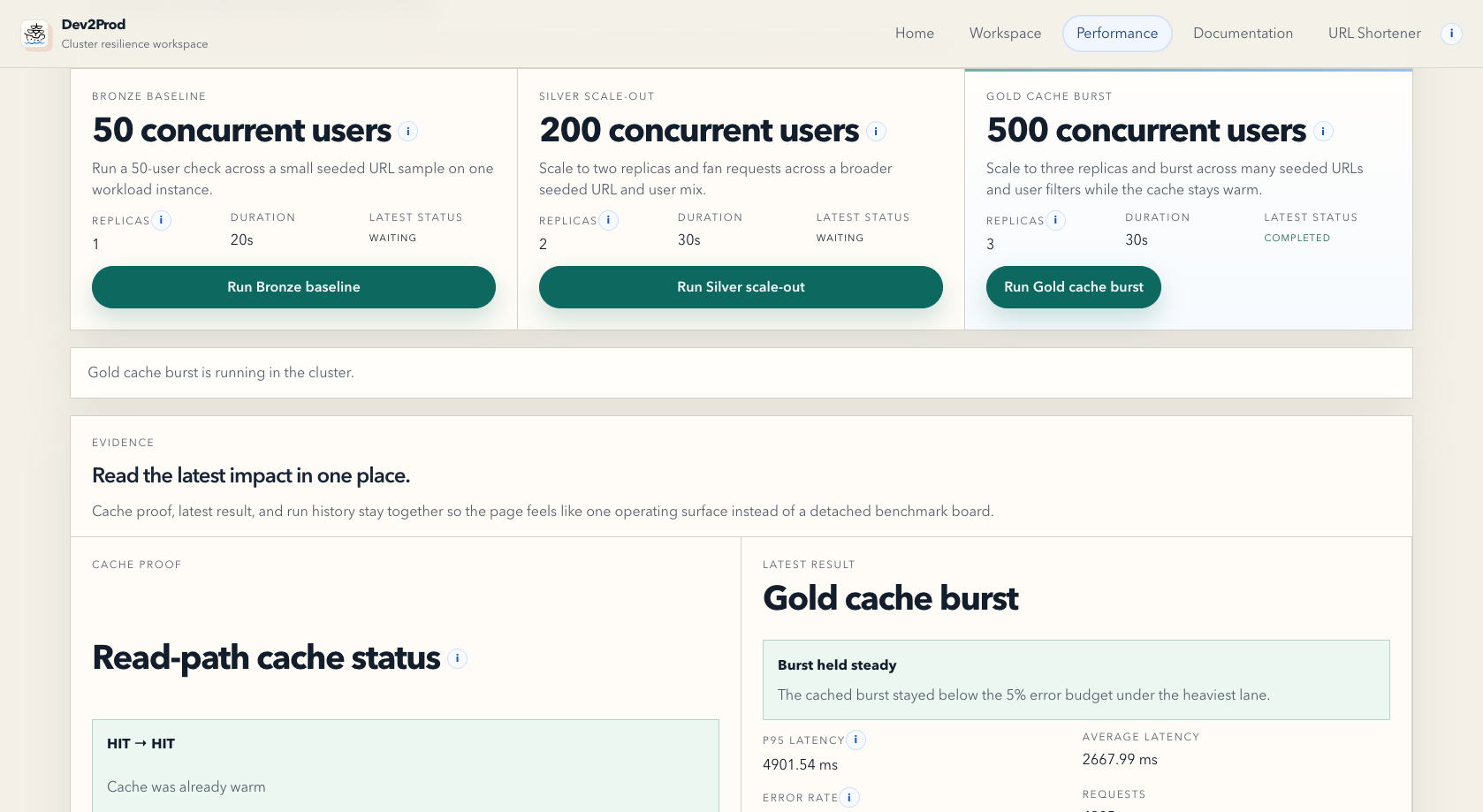
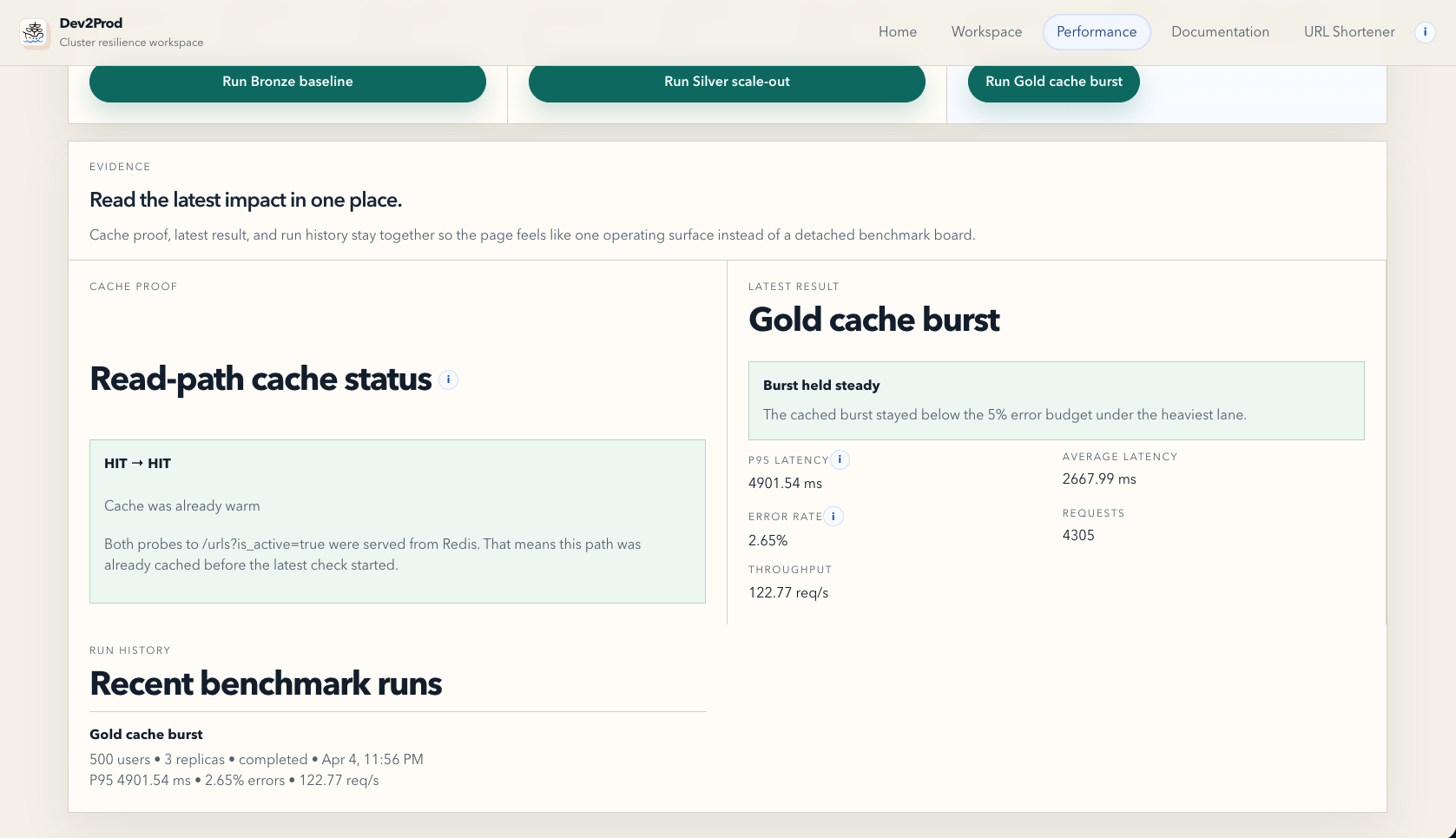
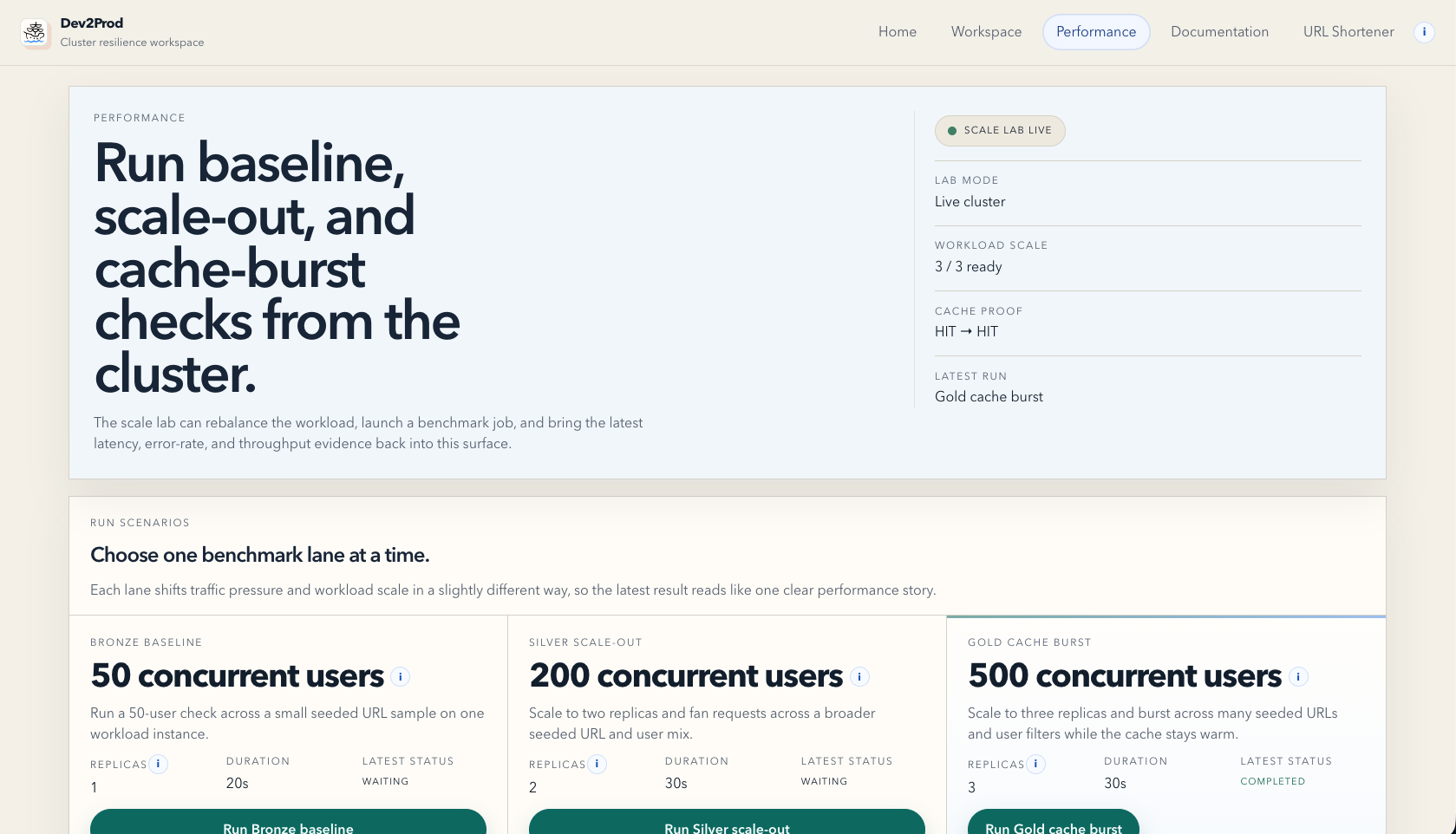
- Performance, where you can run benchmark lanes for baseline traffic, scale-out traffic, and cache-aware burst traffic.
- Reference workload, which is the live URL shortener app that gives the cluster story something real to protect and test against.
The important part is that Dev2Prod does not just trigger faults or dump benchmark numbers. It tries to turn resilience and scalability into a readable story.
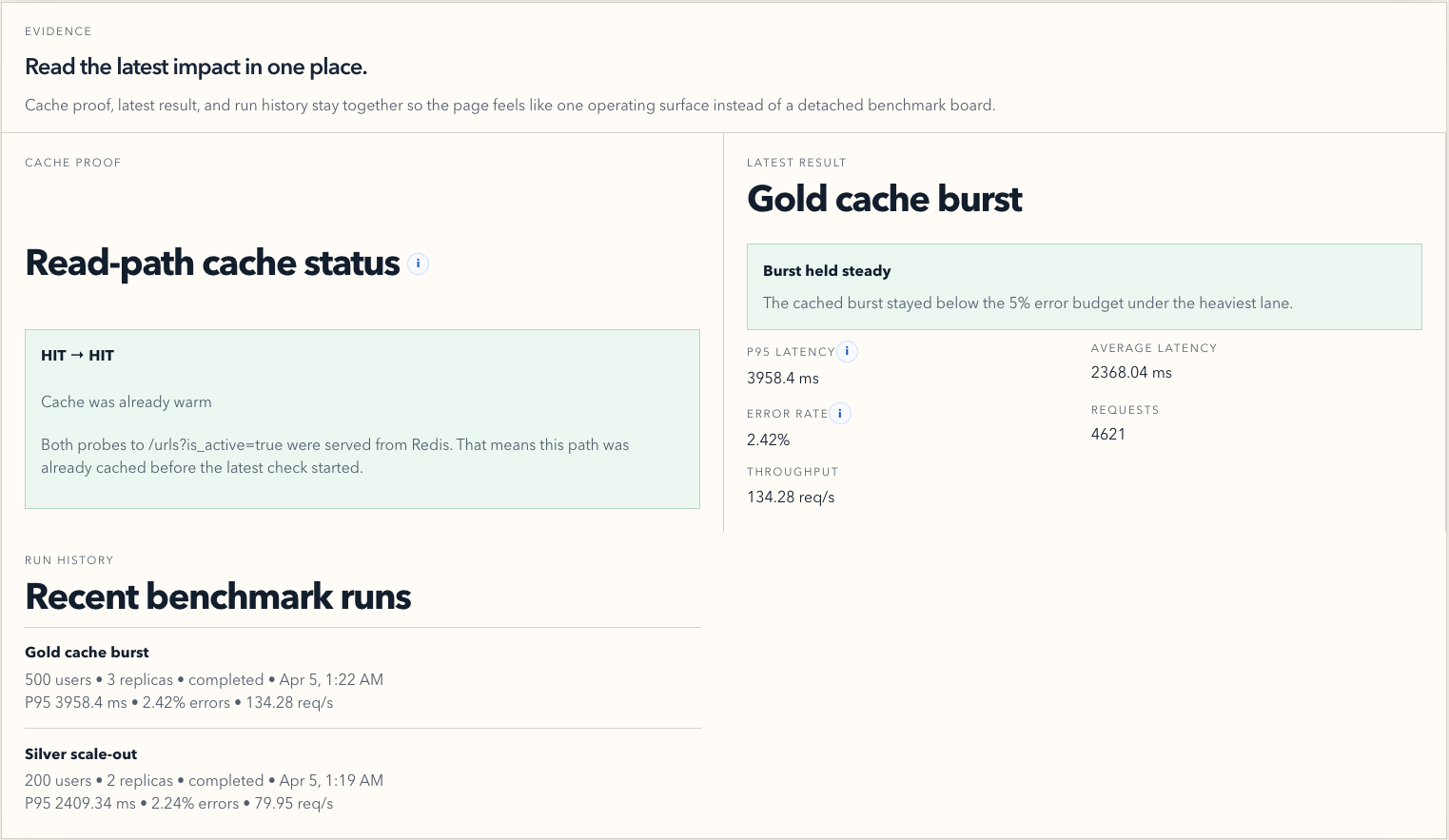
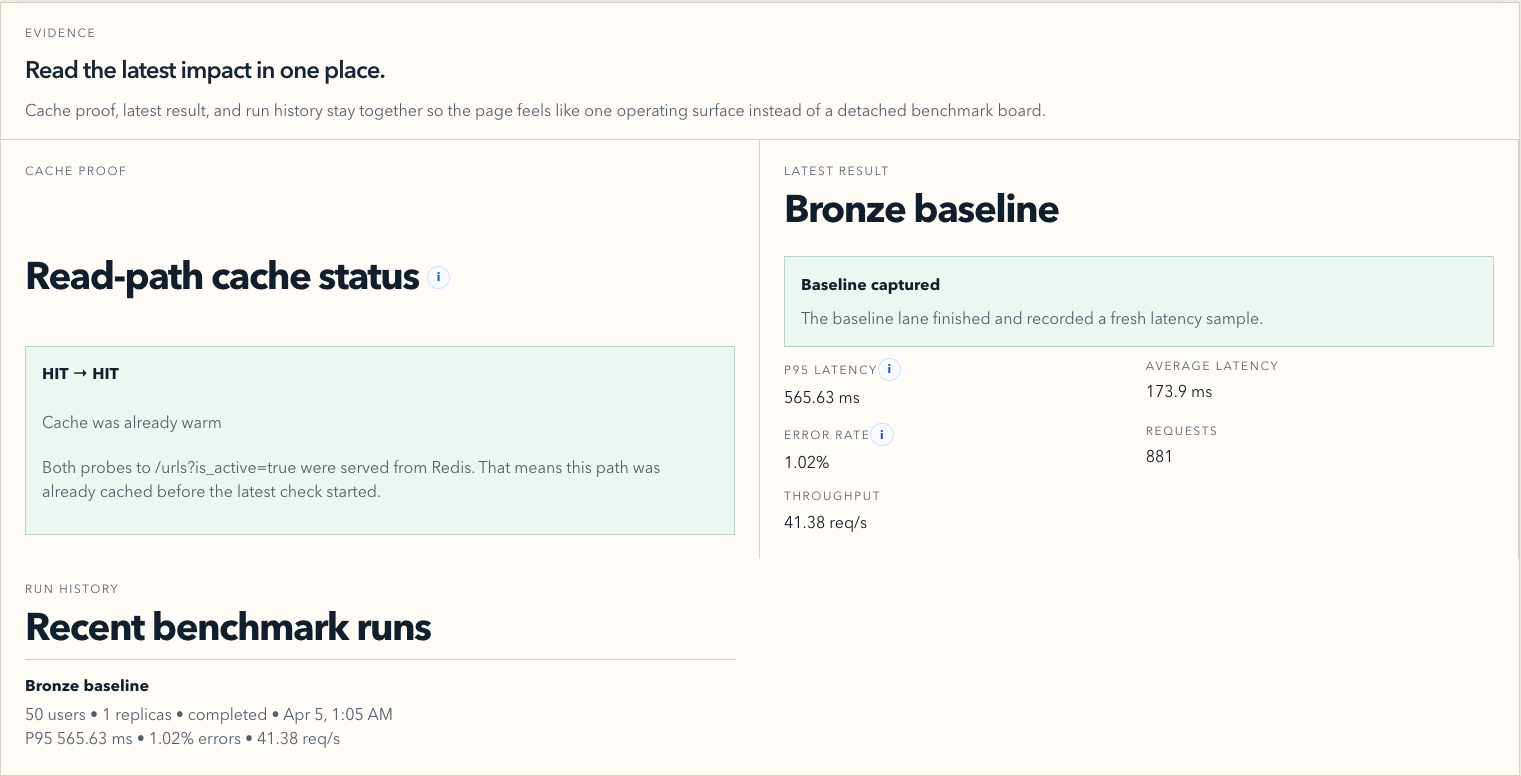
In the reliability flow, the platform keeps the active target clear, shows recovery signals, and keeps the evidence attached to the drill. In the scalability flow, it shows the impact of baseline traffic, horizontal scale-out, and caching in one place, with metrics like p95 latency, error rate, throughput, and cache proof.
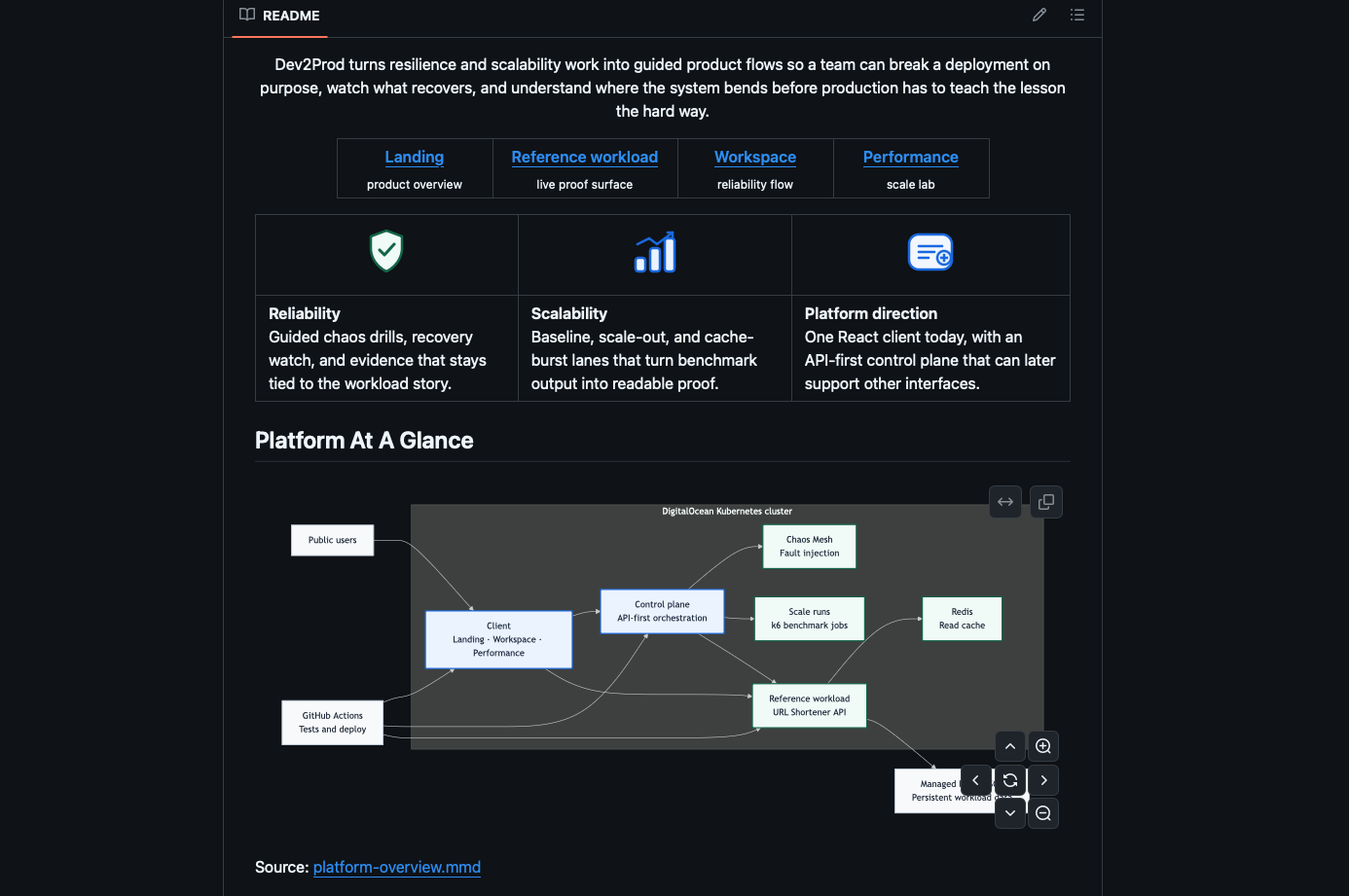
The product direction is bigger than the current demo. We designed the control plane to be API-first because the long-term idea is a headless platform that could support a web client, a CLI, and eventually bring-your-own workload onboarding. Right now the cluster is intentionally locked down to one reference workload so the story stays safe and predictable, but the shape is there for something broader.
How we built it
We built Dev2Prod as a full-stack platform, not just a frontend or backend exercise.
The workload API and the control plane are both built in Python with Flask. The public client is built with React, TypeScript, and Vite. The live environment runs on DigitalOcean Kubernetes, with GitHub Actions handling test gating and deployment. For resilience testing we integrated Chaos Mesh, and for scalability work we used k6, Nginx, and Redis. The primary database is managed PostgreSQL, and Redis is used as a read cache in the Gold scalability path.
A lot of the project was about making these pieces work together coherently:
- the control plane has to understand cluster state
- the client has to present that state clearly
- the workload has to expose enough signal to make the platform believable
- the deploy path has to be stable enough that the platform itself is not the weak point
We also spent a lot of time on documentation because we wanted the repo to feel like a real product manual, not an afterthought. The README, quest docs, deploy guide, troubleshooting notes, decision log, and capacity plan are all part of the product story.
We also used Codex as an engineering copilot throughout the project. That helped us move faster across architecture planning, infrastructure debugging, implementation, and documentation, but we were careful not to use it as a substitute for validation. We treated the output the same way we would treat any engineering contribution: it had to be tested, reviewed, and grounded in the actual runtime behavior of the system.
Challenges we ran into
There were a lot of them.
One of the biggest challenges was making resilience visible, not just technically present. It is easy to kill a pod. It is harder to make the system explain, in a clean and believable way, what changed, what recovered, and whether the app is still usable. A lot of the Workspace work was really about narration and operator clarity.
Another big challenge was the scalability story. Redis alone did not magically make the system healthy under load. We hit real database connection pressure during the heavy burst lane, and that forced us to fix the actual bottleneck instead of just talking about caching. We had to move toward pooled PostgreSQL connections and remove unnecessary database touches from cached paths. That was one of the most useful moments in the project because it turned the scale lab into a real engineering tool rather than a cosmetic benchmark screen.
The deployment path also had its own surprises. One example was the seed job in Kubernetes. Since Job pod templates are immutable, our first deployment flow around the seed job was not robust enough, and we had to explicitly recreate it during deploy. That is the kind of issue that sounds small until it blocks the release path.
We also ran into hidden evaluator edge cases around invalid input, uniqueness, inactive resources, and output expectations. Fixing those forced us to harden the APIs in ways that actually improved the product.
And finally, there was the product challenge: keeping the scope disciplined. There were many moments where the easiest path would have been to add more features to the shortener itself. We had to keep reminding ourselves that the product was Dev2Prod, not the demo workload.
Accomplishments that we're proud of
We are proud that this feels like a platform, not a stitched-together hackathon demo.
The biggest accomplishment is the overall shape of the product:
- a guided reliability surface instead of raw chaos controls
- a guided scalability surface instead of raw load-test output
- a live workload that makes the system behavior easy to understand
- documentation that explains the architecture, tradeoffs, and measured limits clearly
We are also proud that the project stayed technically honest. The scale story includes real bottlenecks and real fixes. The reliability story includes real recovery behavior. The docs do not pretend the platform is more general than it currently is. That honesty matters.
Another thing we are proud of is that we resisted the temptation to overbuild the wrong thing. Keeping the sample workload simple gave us room to invest in the control plane, the cluster flows, the scale lab, the docs, and the operator experience. That tradeoff was the right one.
What we learned
The biggest lesson was that infrastructure features are not enough on their own. A pod restart, a cache layer, or a benchmark script only becomes useful when the person using the system can understand what it means.
We also learned that product design matters just as much in DevOps-style tools as it does in user-facing apps. If the interface is confusing, if the evidence is fragmented, or if the flow is too technical, the value gets lost even when the backend is doing the right thing.
On the technical side, we learned a lot about:
- making Chaos Mesh behavior readable in a product surface
- turning cluster state into something understandable in real time
- handling benchmark orchestration from a control plane
- the practical difference between “caching exists” and “caching actually changes the bottleneck”
- how much deployment reliability and documentation quality affect the credibility of the whole system
We also learned that building something meaningful sometimes means ignoring the obvious shortcut. We did not strictly follow the most expected stack or the easiest feature path. We made choices based on the product we wanted this to become.
What's next for Dev2Prod
The current version is intentionally scoped, but the direction is much broader.
The next major step is making the control plane truly headless, so Dev2Prod can support more than one client cleanly. We want the current React client to be one interface over the platform, not the final shape of it.
After that, the most important expansion is bring-your-own workload support. Instead of staying locked to the reference workload, the platform should be able to take in another deployment safely, understand its shape, and guide the user through testing it without forcing them through raw cluster commands.
We also want to expand:
- supported Chaos Mesh fault types
- cluster-level visibility and runtime signals
- clearer operational workflows
- CLI-based usage
- better onboarding for people who are not deep Kubernetes experts
The long-term idea is simple: make DevOps and resilience work more accessible without making it superficial. If a team can test their deployment before production, understand the result, and sleep better because they already broke it in a controlled way, then Dev2Prod is doing the job we built it for.
Built With
- chaos-mesh
- codex
- digitalocean-container-registry
- digitalocean-kubernetes
- digitalocean-managed-postgresql
- docker
- docker-compose
- flask
- github-actions
- gunicorn
- k6
- kubernetes
- nginx
- peewee
- postgresql
- python
- react
- redis
- typescript
- uv
- vite






Log in or sign up for Devpost to join the conversation.