-
-
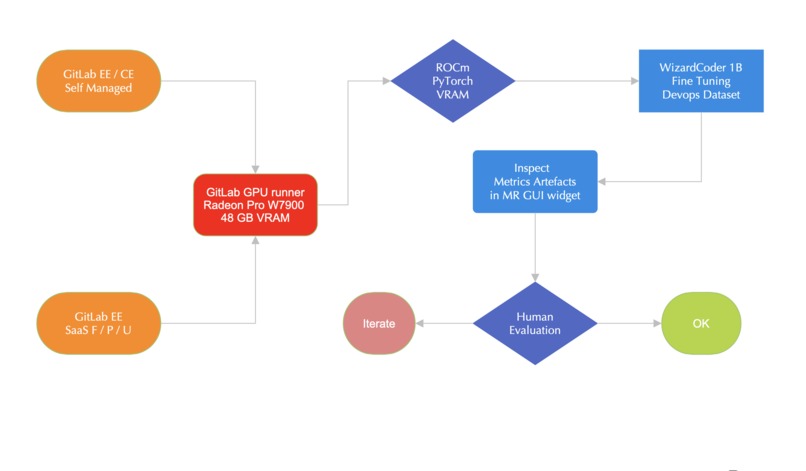
Code LLM fine-tuning within gitlab GPU runner: (pseudo-)logic diagram of infrastructure components and CI pipeline stages and training jobs.
Inspiration
For any new Gitlab community member (including ourselves) the experience of migrating a repository is inspiring. In contrast to migrating the code, migrating the CI/CD part of a repository can often feel fragmented. How do you translate a GithubActions file into a GitlabCI yaml pipeline file? As projects grow and reach maturity translating between various CI/CD contexts also becomes a common need: How do you translate a CI/CD template file for PHP into one for Python or Node? How do you translate a CI/CD template targeting AWS deployment into one for GCP, or self-hosting? Such questions, and many similar ones, are relevant for many Gitlab users at some stage of their DevOps journey. In 2023, most developers have tried at least once to use AI for such a task. Certanily Gitlab Duo, Copilot, ChatGPT or Gemini, etc. can help with both code generation and translation, why not also with CI-template translation? A natural next question is: How good are the existing code-specialized LLMs at translating DevOps template files? It is not trivial to answer such a question in a systematic way (in the spinoff twin project we consider a POC for such an LLM graded evaluation pipeline), but a few quick prompts will probably convince you that they can be improved. Imagining a world in which Gitlab Duo provides a (very) high quality translation between any pair of devops templates, contexts, or infrastructures, is the main inspiration driving this project.
What it does
This POC starts from the assumption that the (quality of) CI-template translation ML task can be improved and will show how to do this with a Gitlab pipeline connected to a Gitlab GPU runner. We first adapt a very basic model training pipeline for our particular use-case. Starting from a large language model (henceforth, LLM) already pre-trained and fine-tuned for code, the POC integrates an LLM fine-tuning script with a minimalistic dataset of Devops template files describing CI/CD setups in different contexts across equivalent devops solutions, infrastructures or targets. The training runs for a minimalistinc number of epochs and with a minimalistic number of examples. While aiming to provide the next state of the art LLM specialised for Devops is too ambitious a goal for the given timeline, it is realistic to hope that the POC could become a starting point towards further engaging the wider opensource Gitlab and ML/LLM-ops communities to contribute towards building the dataset and workflow to make such a model possible. We show that all this can be done using the very same tools that will, hopefully, benefit from, and be improved by it: Gitlab pipelines, components, and Gitlab (GPU) runners.
How we built it
We start from setting up a local gitlab runner equipped with a GPU with 48GB of VRAM. We then focus on implementing a pipeline that can fine-tune a small LLM model pretrained for code instruction tasks. Because our bottleneck is the amount of VRAM available to the runner, we settle for a "merely" 1 Billion parameters model. We adapt the training script to use a (minimalistic) instruction dataset with a few CI-template translation examples. Then we integrate the script into a larger ML workflow triggered by updates to the repository for both code and data used for training. More details about the build are available in the attached code repository and presented in the linked video.
Challenges we ran into
The main challenge was finding a way to meet the resources requirements needed to run an LLM training (i.e. fine-tuning) job within the confines of one Gitlab GPU runner with limited amount of consumer level VRAM. Setting up the runner virtual environment and orchestrating the pipeline stages in a way that does not exceed the amount of available GPU memory while running the code LLM training/fine-tuning steps was also a challenge, especially because for this project we have integrated a GPU empowered by the ROCm opensource library and several software components of the usual training pipeline needed to use HIPified versions. Other challenges that were faced during the project included integrating the trained model with a native model registry, and alignment with the standard Gitlab runner Docker image.
Accomplishments that we're proud of
Probably the main accomplishment is the fact that we have managed to achieve all these using only one consumer level grade GPU and open source software libraries, including the acceleration library for the GPU (ROCm and HIP). This shows that, with the coordinated effort and support of the wider MLops and LLMops communities, useful AI applications are possible even on a personal workstation, or single board computer infrastructure, and low resources consumer level GPUs can support this journey a long way before larger datacenter-grade infrastructure becomes necessary.
What we learned
We learned many new details about various Gitlab components, especially the Gitlab runner and how to use a GPU inside a CI pipeline. We also learned about using MR widgets and metrics artifacts inside CI components and the Gitlab components catalog. Also we learned a lot about the tradeoffs needed in order to shift left an end to end LLM training workflow, especially when local infrastructure is employed. Also we learned many prerequisites that will be useful in the future to furhter align local and cloud based configurations for runners using a Docker executor. We also learned a lot about the Gitlab model registry and how it can help with versioning and publishing models.
What's next for Fine-tunning code-LLMs for CI/CD yaml templates translations
Working on this POC only scratches the surface of what a complete training workflow with Gitlab can achieve, and several next extensions are possible. To only mention the most important ones: scaling the infrastructure to handle larger code LLMs; with 48GB we are already at the high end of the spectrum for consumer grade GPUs. Using quantization can briefly alleviate vertical scaling, beyond this, the pipeline can also accommodate various data-center level GPUs. The workflow can also be scale horizontally by using runners with multiple GPUs and leverage data, model and pipeline parallelism techniques. For example, with two 48GB GPUs we could fine tune some SOTA open source code LLMs. Further extending (in both size and quality) the training dataset is necessary in the future, this is also a task that can benefit the most from deeper engagement with the Gitlab team expertise and the wider community, as it will require a larger effort and crowdsourcing contributions from successful migrations and coordinating examples of working templates to translate between. We also plan to integrate the training with evaluation of quality for the resulting fine-tunned model (see the spinoff twin project for an early illustration). Integrating the features of the model registry to version and publish the artifacts of the training pipeline is another important future improvement. Finally, alignment with SaaS container runners setups and developing a component to display the training metrics in the merge request GUI would also be useful additions.
Built With
- datasets
- gitlab-ce
- gitlab-ee
- gitlab-runner
- metrics-widget
- pytoch
- rocm
- transformers
- wizard-coder




Log in or sign up for Devpost to join the conversation.