-
-

Cover Image
-
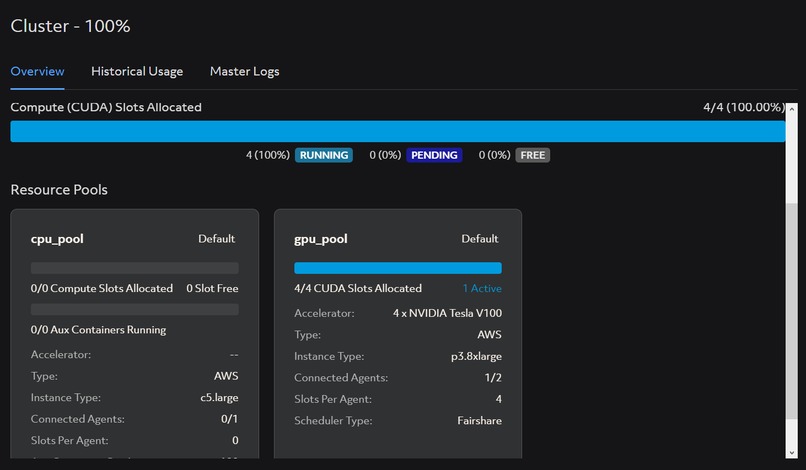
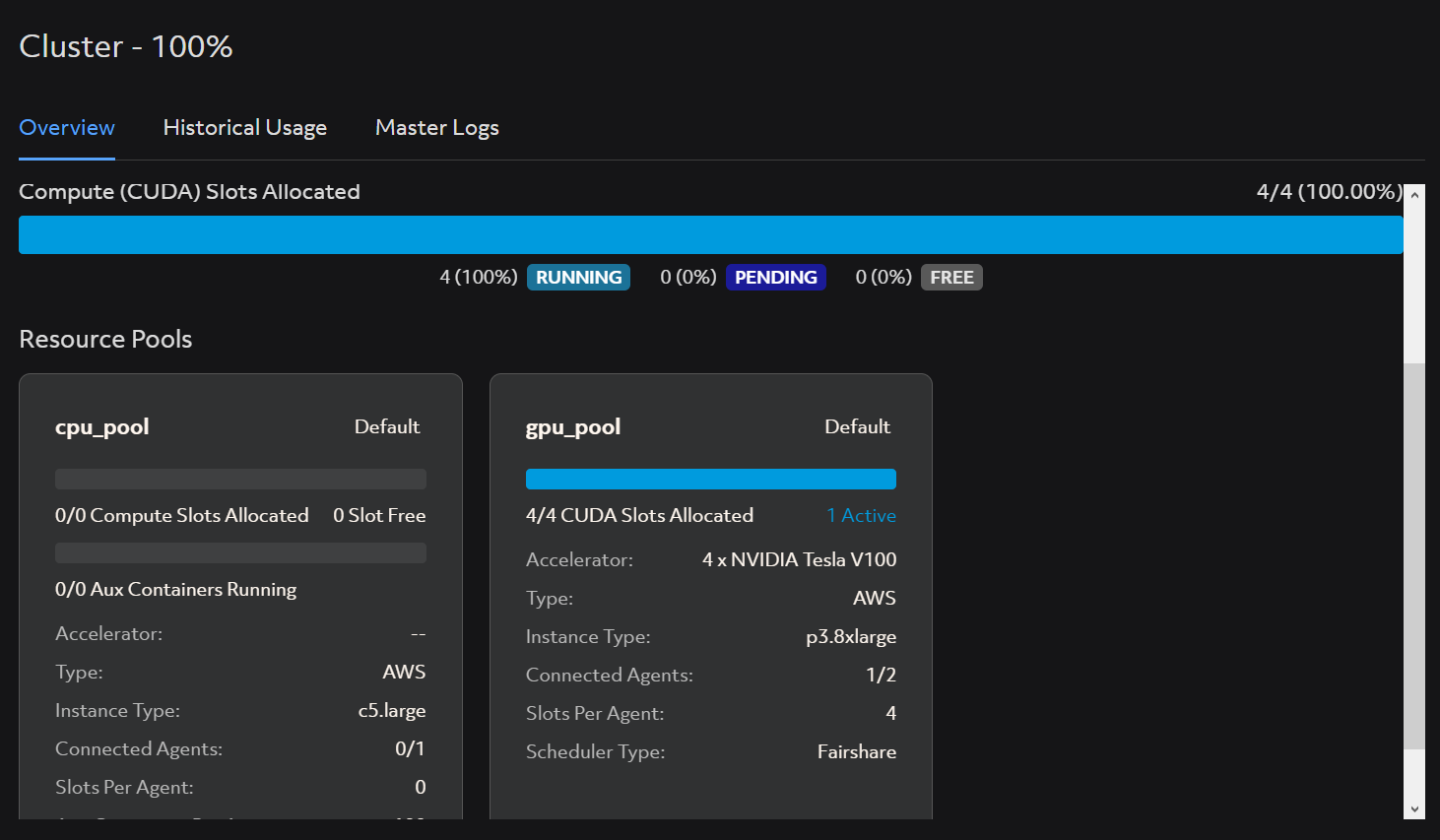
Clusters that is running in Determined AI Web GUI (2)
-
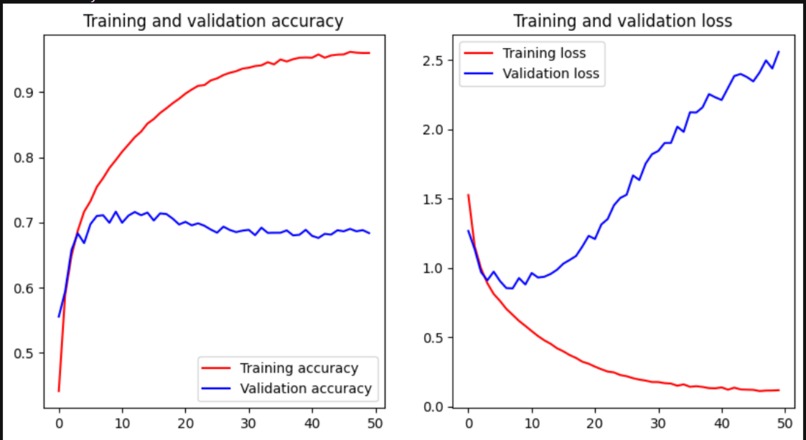
Test data and the test accuracy/loss with cifar10_cnn_keras_tensor.py
-
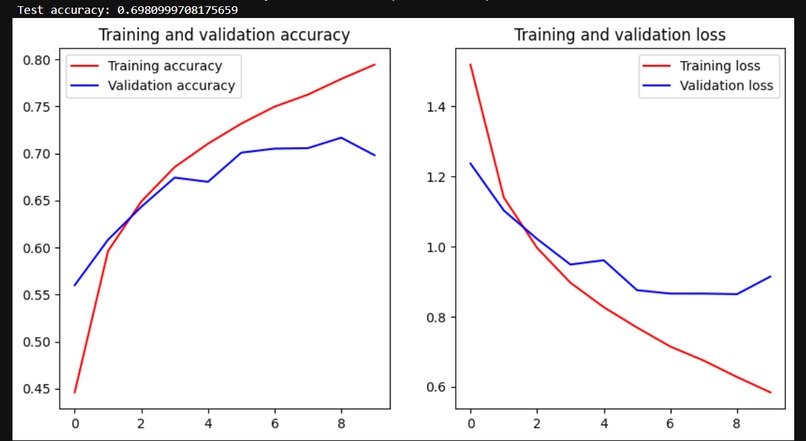
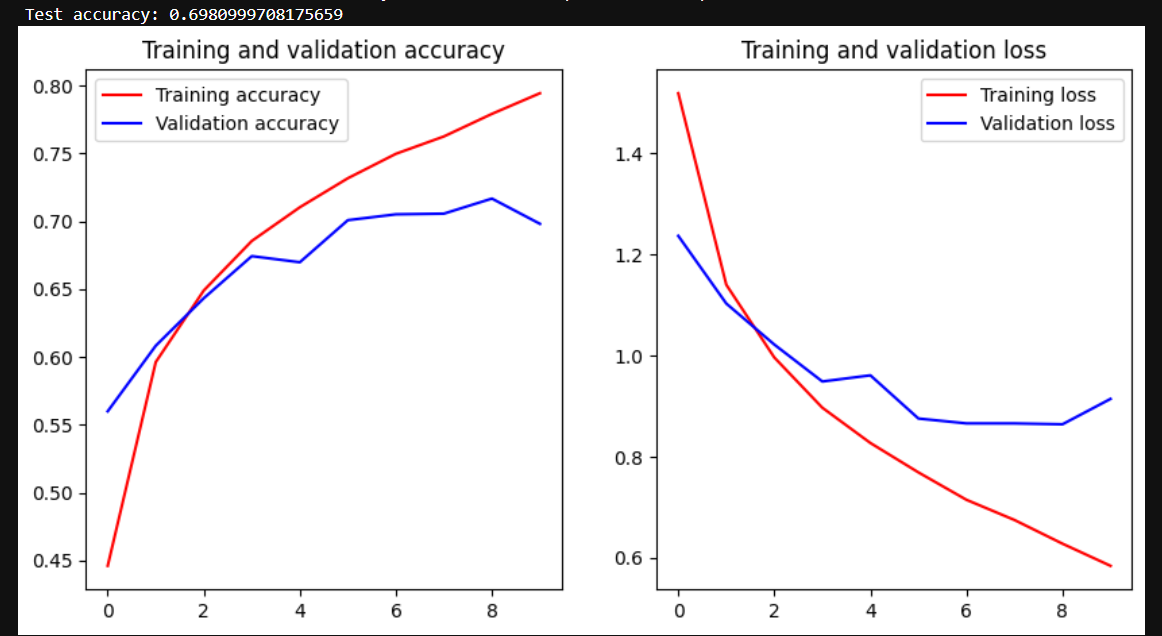
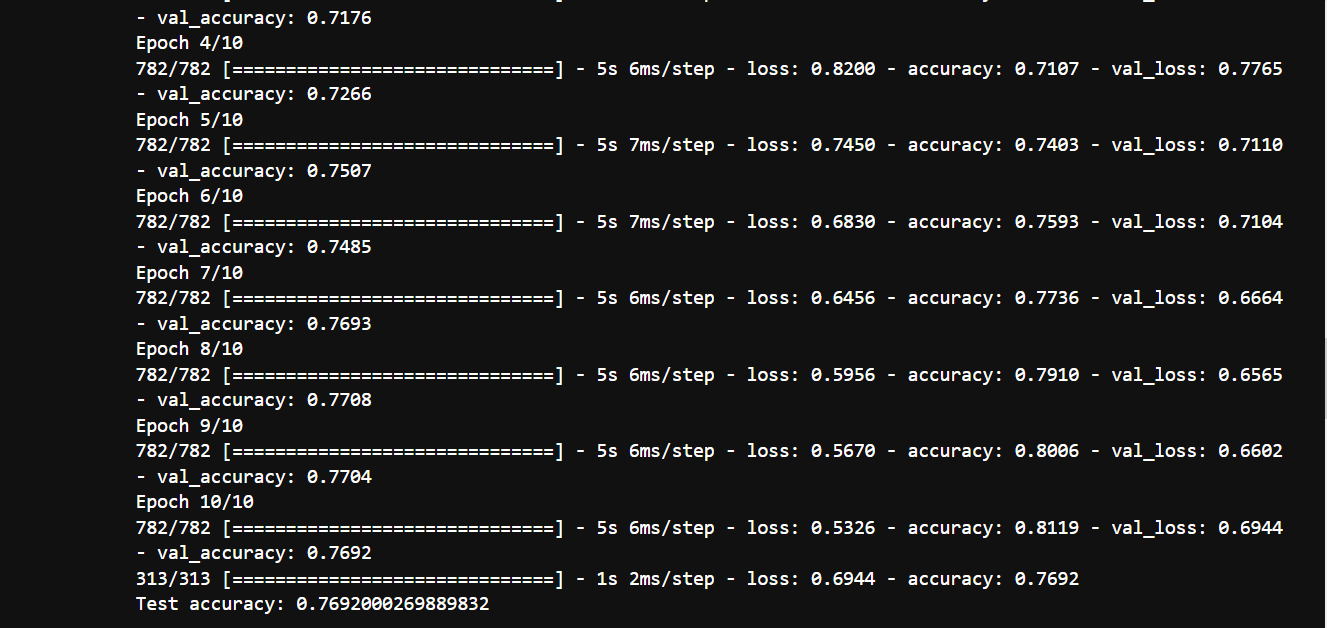
Test data and the test accuracy/loss with cifar10_cnn_keras.py
-

Downloading of Cifar_10 datasets
-
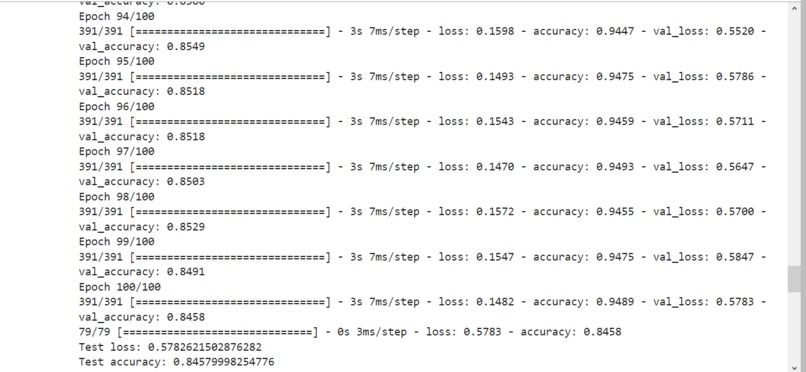
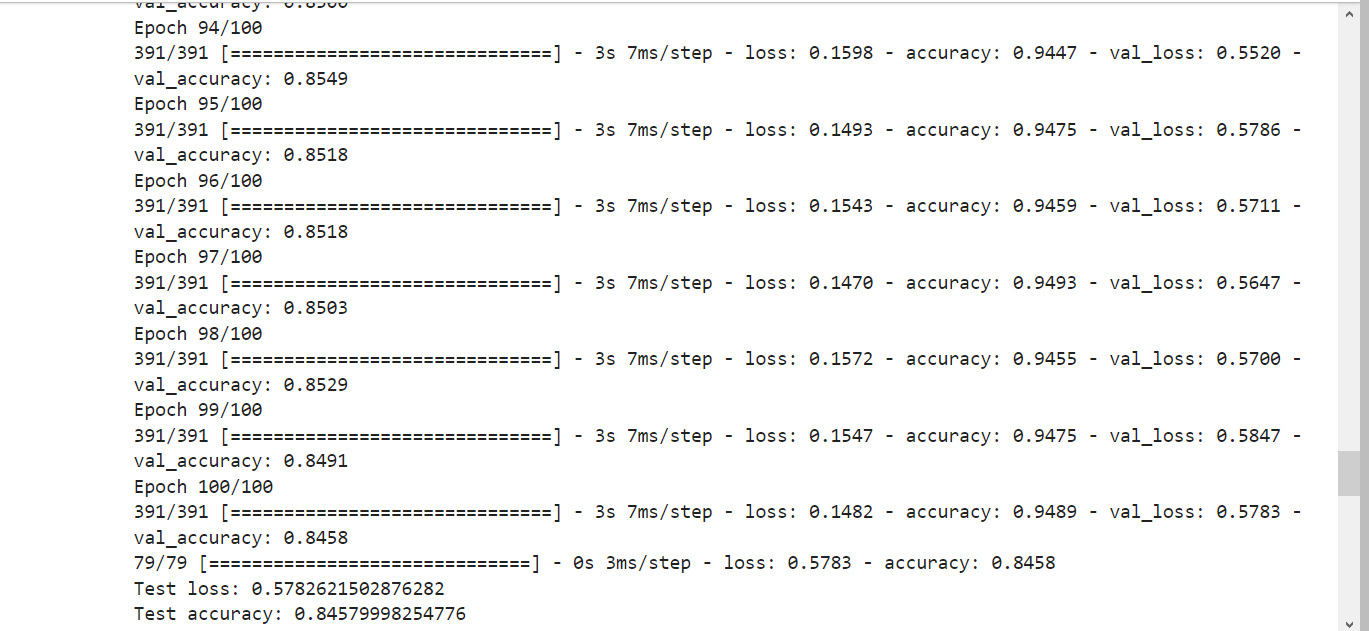
100 Epoch results from my_cnn_model.py
-
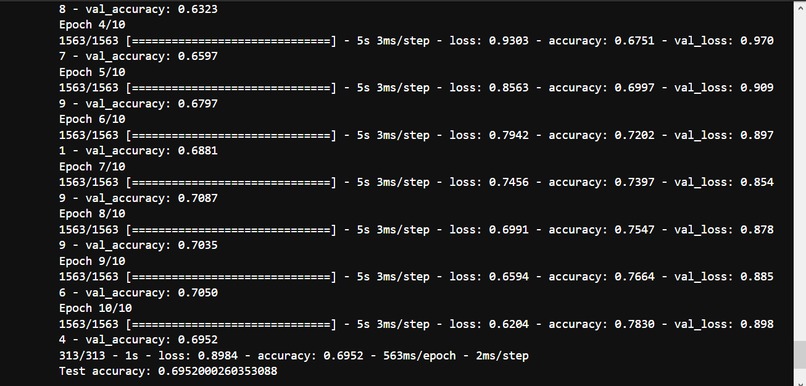
Result of accuracy and loss with cifar10_cnn_keras.py
-
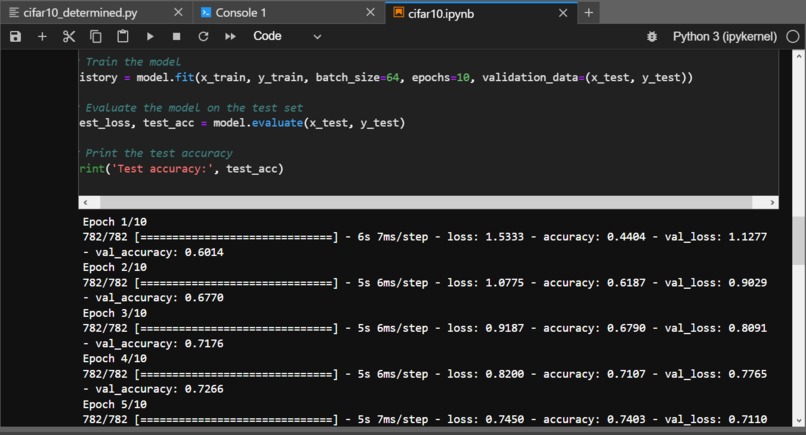
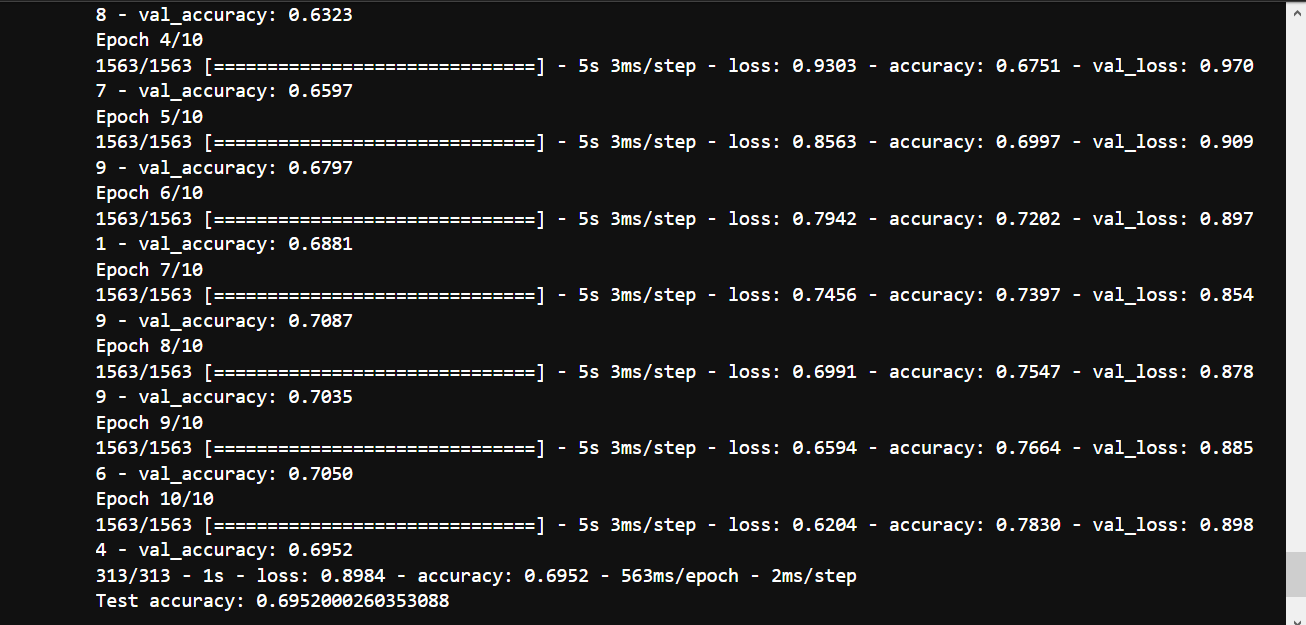
Result of Accuracy Test cifar10_cnn.py (1)
-
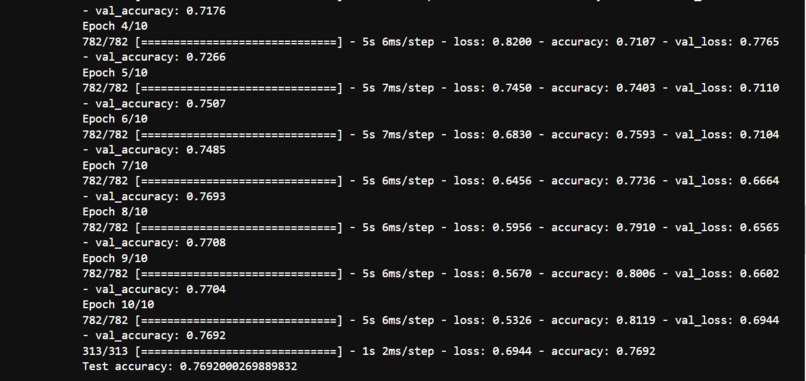
Result of Accuracy Test cifar10_cnn.py (2)
-
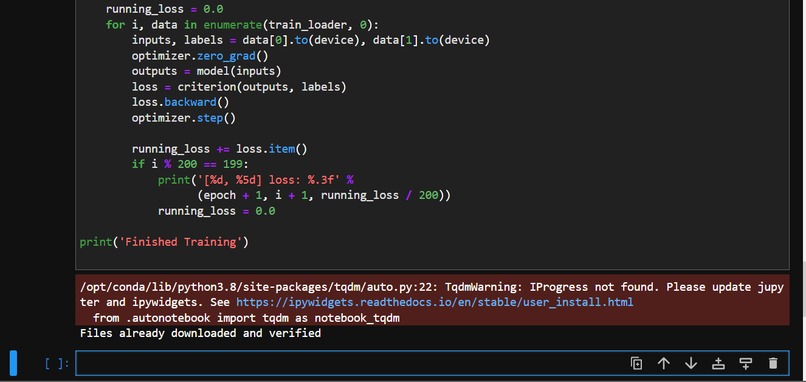
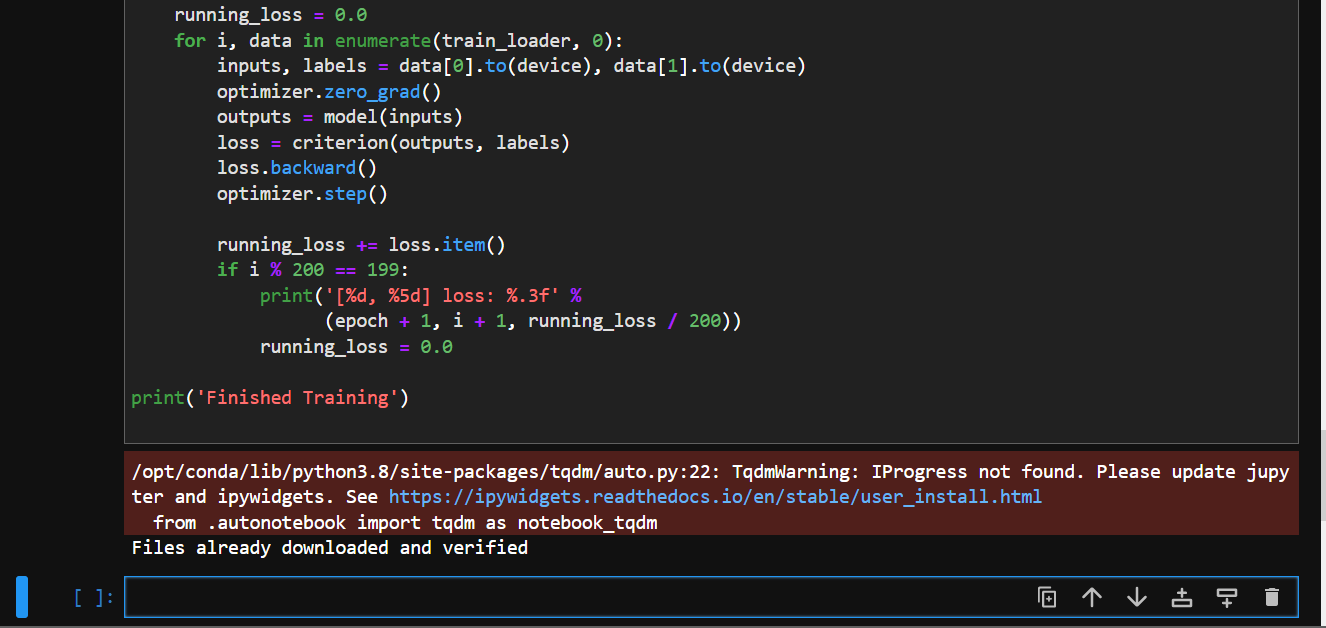
Files downloaded and verified with cifar10_train.py
-
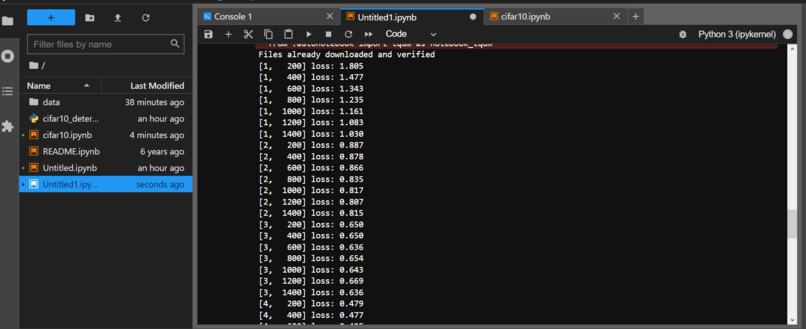
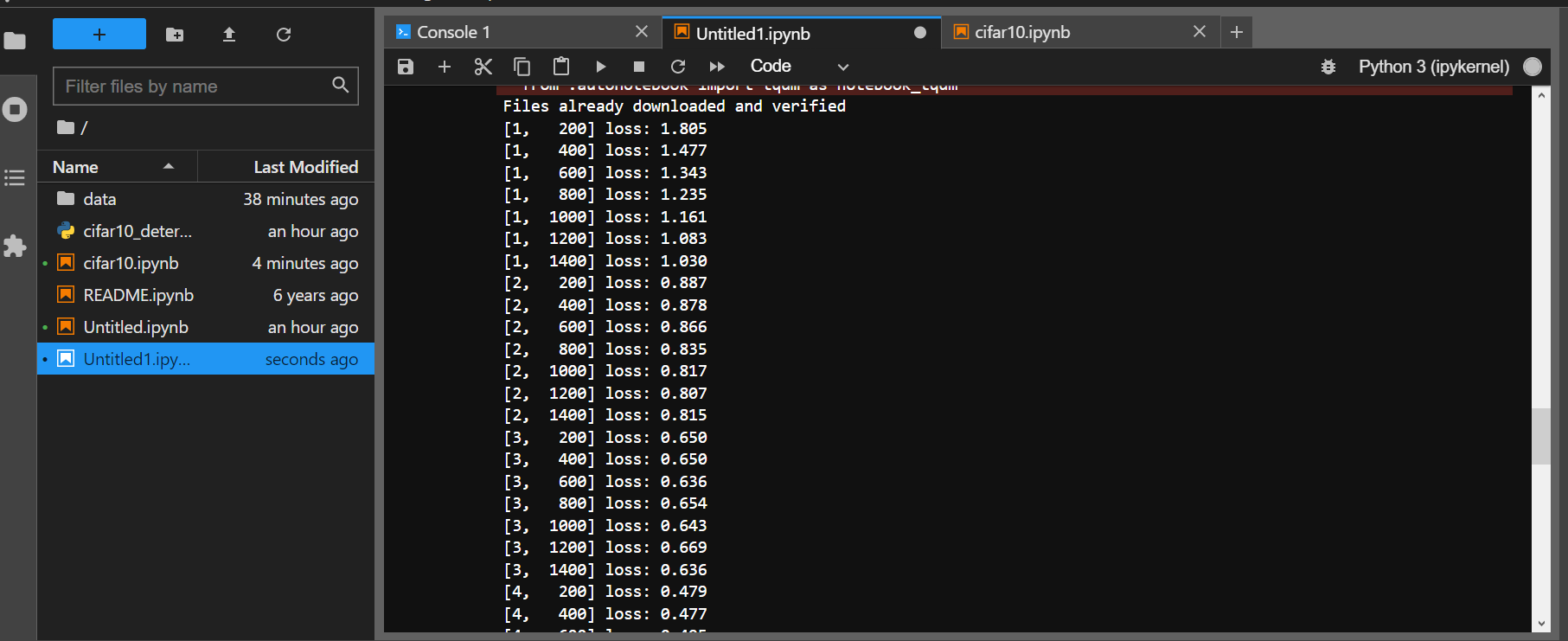
Result of Training with cifar10_train.py (1)
-
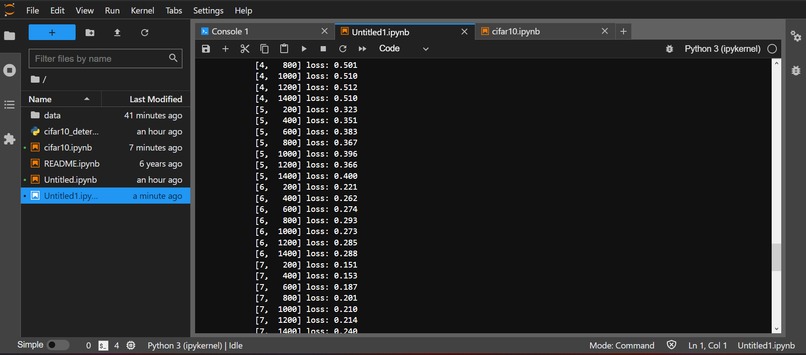
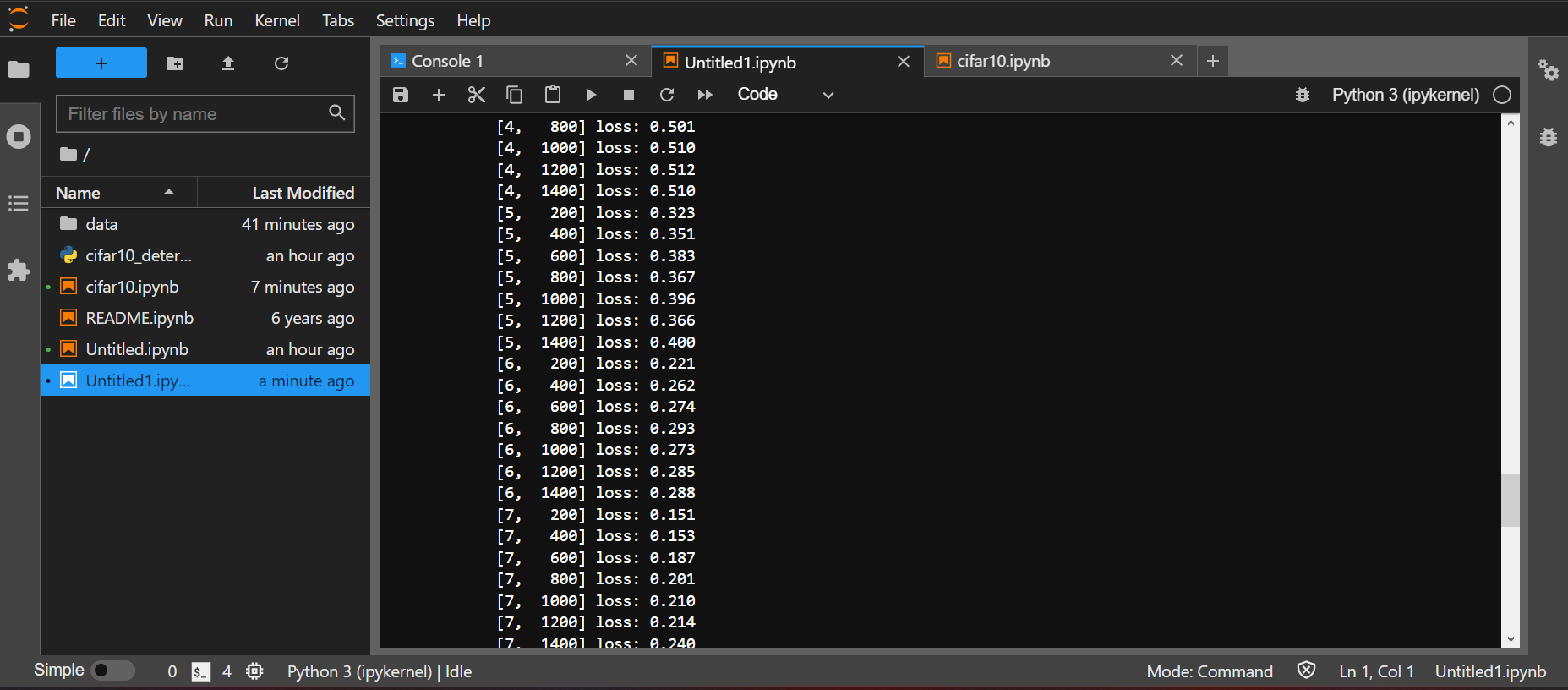
Result of Training with cifar10_train.py (2)
-
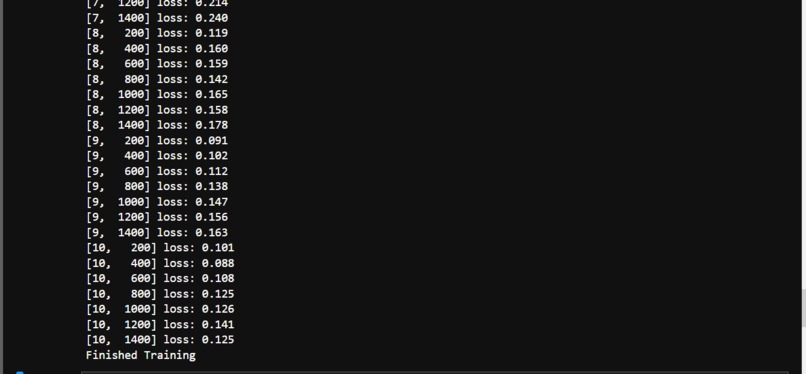
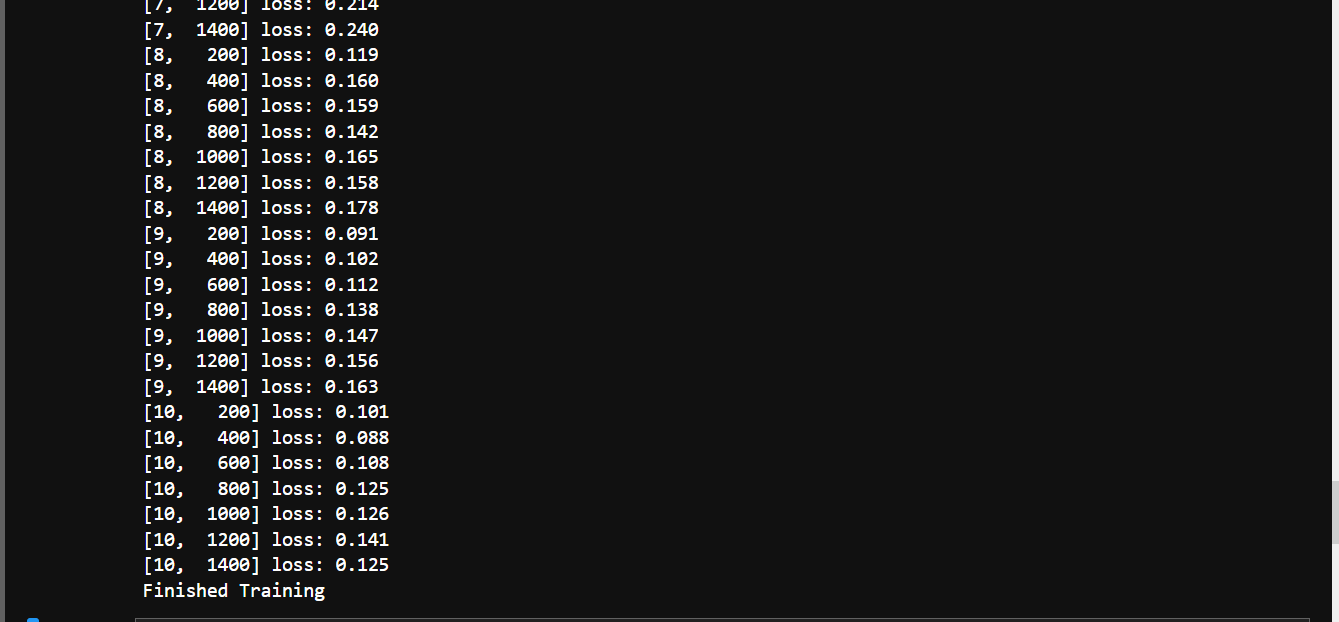
Result of Training and Finished Training with cifar10_train.py (3)
-
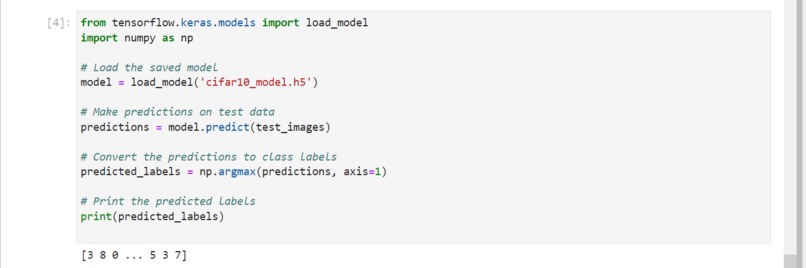
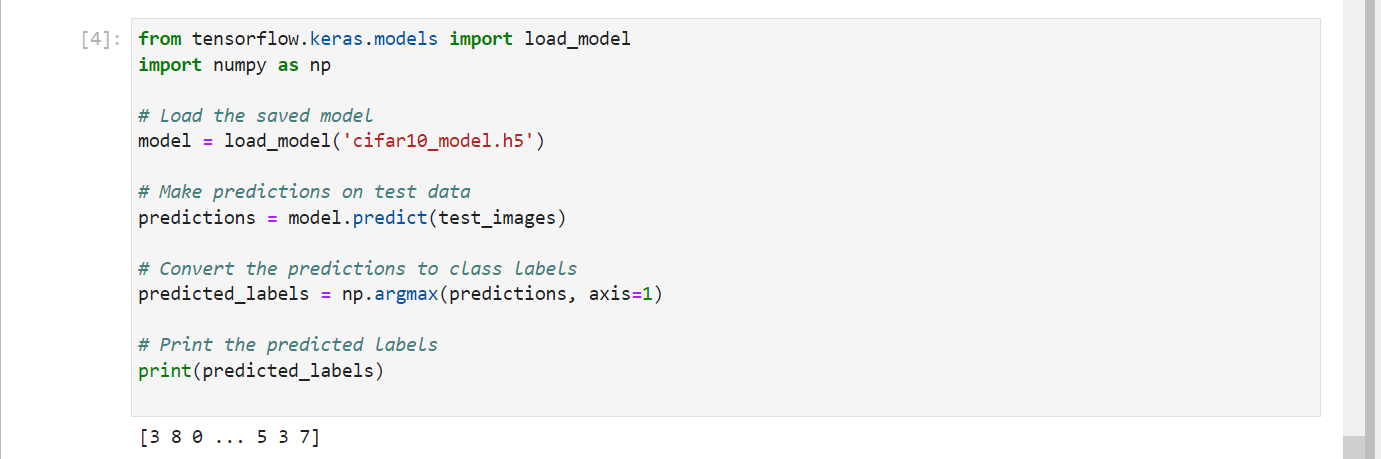
Testing out the cifar10_model.h5
-
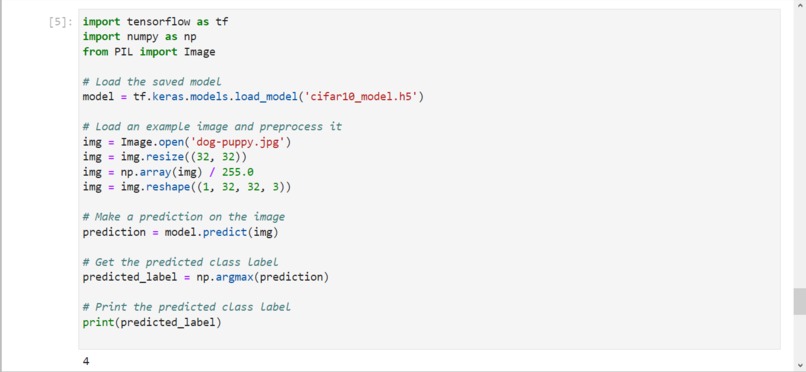
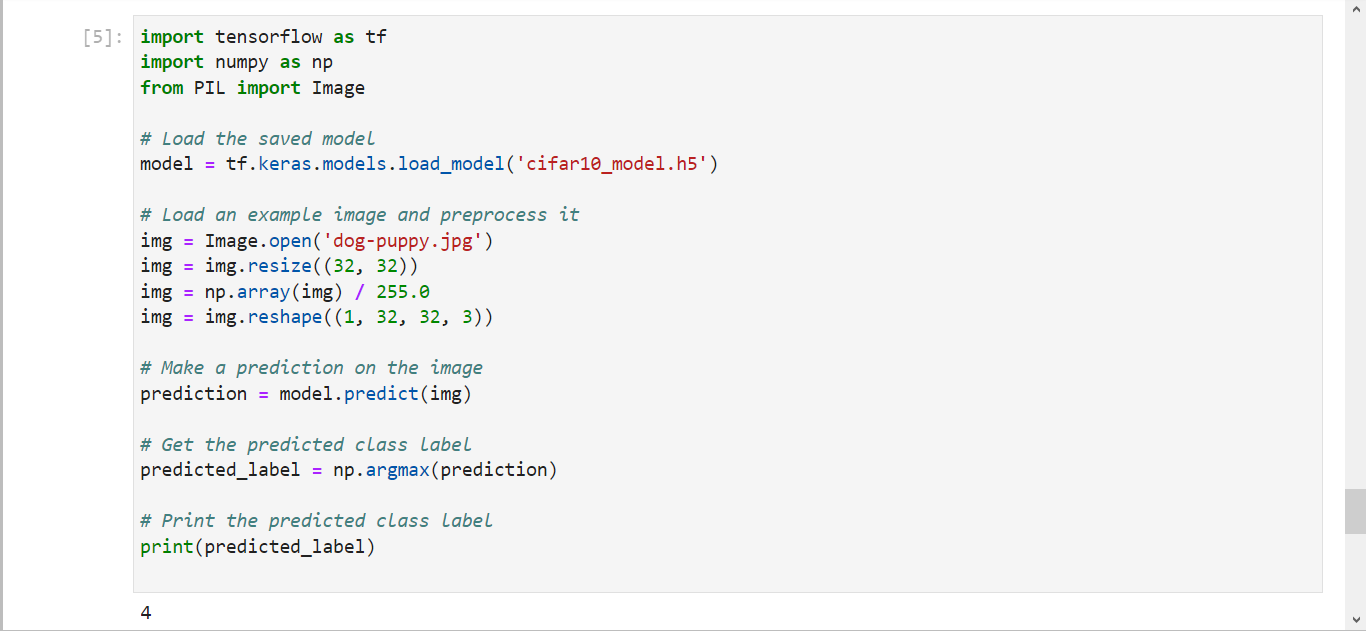
Testing out the cifar10_model.h5 (2)
-
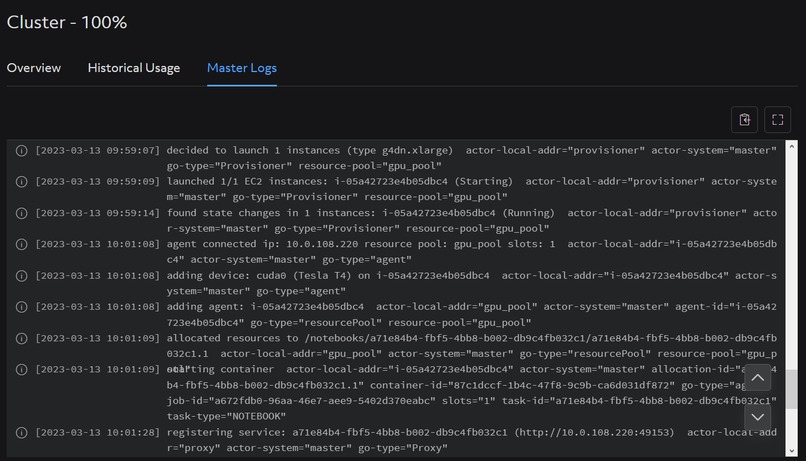
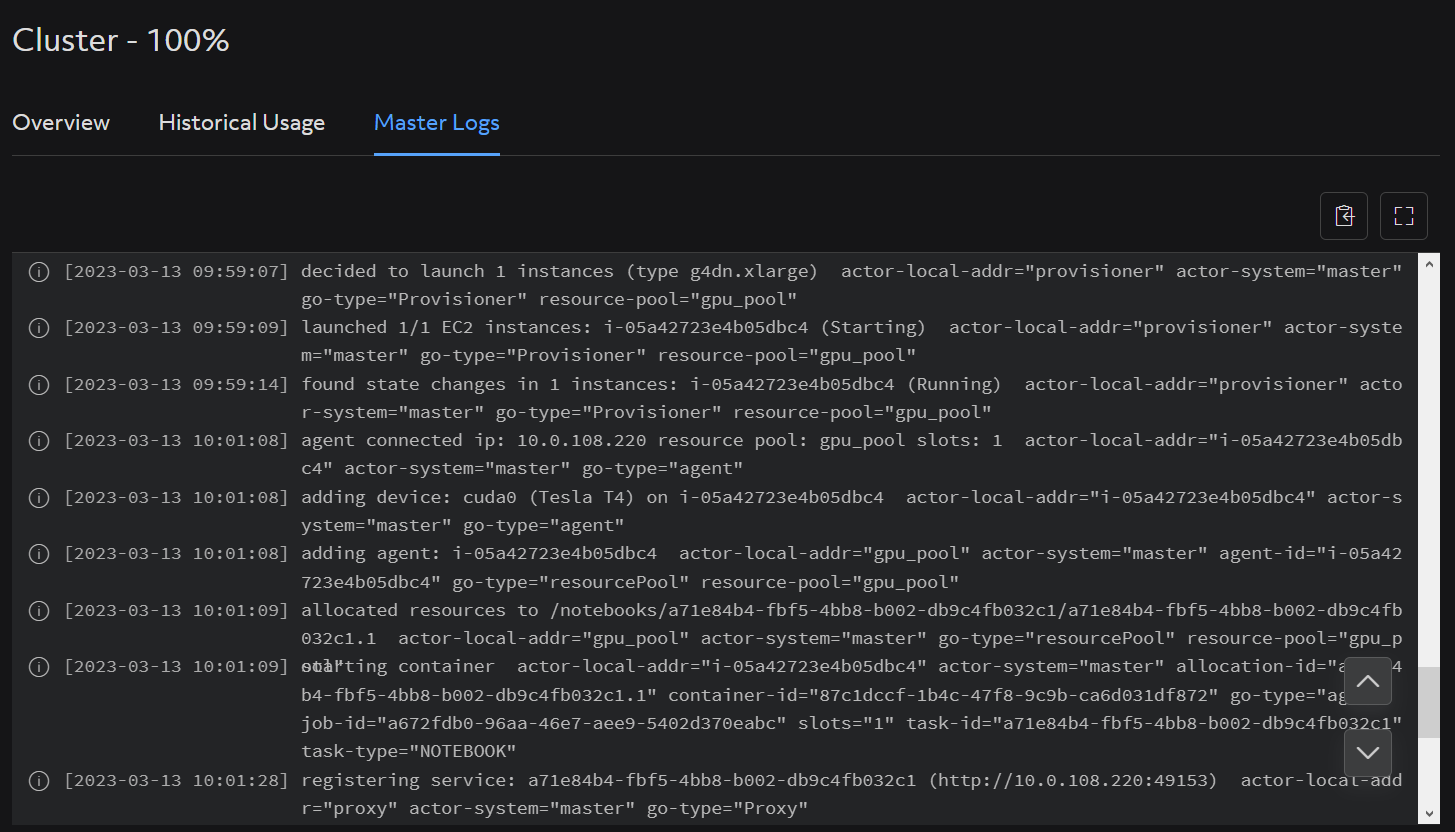
Cluster Master Logs
-
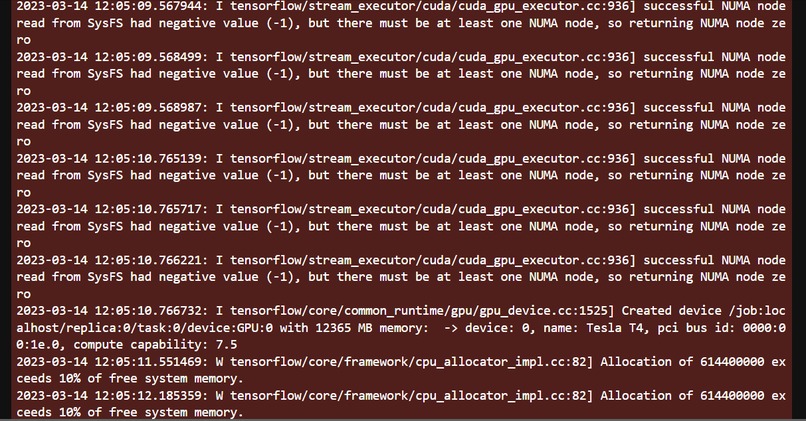
Encountered code with the GPU Nvidia Cuda



- Video audio quality is very low use earphones or headphones
Inspiration
"Efficient Distributed Training with Determined AI" - This code showcases how the Determined AI platform can distribute the training process across multiple GPUs, allowing for faster and more efficient training of deep neural networks on large datasets such as CIFAR-10.
Inspiration in building the application includes:
Data preprocessing: The CIFAR-10 dataset consists of 50,000 training images and 10,000 test images, each of size 32x32 pixels with RGB color channels. You can preprocess the data by normalizing the pixel values to be between 0 and 1, and one-hot encoding the class labels.
Model creation: You can create a CNN model using Keras by stacking convolutional, pooling, and dense layers. You can experiment with different architectures by varying the number and size of the layers, the activation functions used, and the regularization techniques applied (e.g., dropout).
Training: You can train the CNN model using stochastic gradient descent (SGD) or other optimizers available in Keras. You can experiment with different batch sizes, learning rates, and number of epochs to find the optimal hyperparameters for your model.
What it does
The code demonstrates how to use Determined AI to train a deep neural network on the CIFAR-10 dataset using distributed training. This project uses the CIFAR-10 dataset, a common benchmark dataset for image classification. The model architecture is a convolutional neural network that consists of two convolutional layers, max-pooling layers, and two fully connected layers. The data loader function preprocesses the data and creates TensorFlow Datasets for training and validation. The training function uses the Determined AI library to distribute the training across multiple GPUs using the TensorFlow backend.
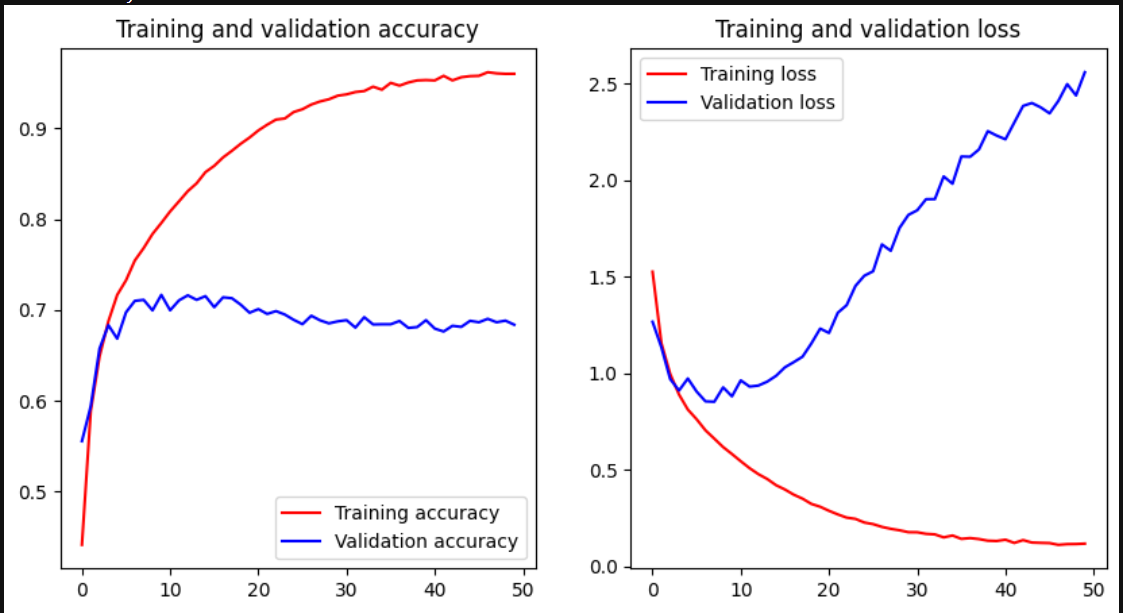
cifar10_cnn_keras_tensor.py This code uses TensorFlow to load the CIFAR-10 dataset, normalize the pixel values, define a CNN model, compile the model with an optimizer and loss function, train the model on the training data, evaluate the model on the test data, and plot the accuracy and loss curves for both the training and validation data. The model architecture consists of three convolutional layers followed by max pooling, a flatten layer, and two dense layers. The model is trained for up to 50 epochs or until a validation accuracy of 90% is achieved, whichever comes first. After training, the model is evaluated on the test data and the test accuracy is printed. Note that this code assumes that TensorFlow and Keras are already installed in your JupyterLab environment.
How we built it
We built the code using Python and the Determined AI platform. The model architecture is a convolutional neural network, and the code uses TensorFlow as the backend for distributed training. The hyperparameters are defined in the experiment configuration, and the Determined AI library is used to manage the training process and optimize the hyperparameters using automated hyperparameter tuning.
Here are the methods used:
Fine-tune hyperparameters: Try adjusting the number of epochs, batch size, learning rate, or other hyperparameters to see how they affect the model's accuracy and training time.
Visualize the CNN filters: The CNN filters are learned weights that represent the patterns and features that the model has learned to detect in the input images. You can visualize these filters to get an insight into what the model is "seeing" in the images.
Evaluate the model on individual classes: The CIFAR-10 dataset consists of 10 different classes of images. You can evaluate the model's accuracy on each individual class to see if there are any classes that the model struggles with.
Implement transfer learning: Transfer learning is a technique that involves using a pre-trained CNN model as a starting point and fine-tuning it on a new dataset. You can try using a pre-trained model like VGG16 or ResNet50 as a starting point and fine-tuning it on the CIFAR-10 dataset.
Challenges we ran into
One of the challenges we faced was configuring the distributed training to work with multiple GPUs, which required careful management of the resources and coordination between the workers. Another challenge was optimizing the hyperparameters for the model, which involved selecting the right search strategy and setting appropriate ranges for the hyperparameters. Finally, we needed to ensure that the code was scalable and efficient, particularly for large datasets like CIFAR-10, which required careful management of memory and computation.
Accomplishments that we're proud of
We are proud to have successfully trained a deep neural network on the CIFAR-10 dataset using distributed training with Determined AI. The code achieved high accuracy on the validation set and demonstrated the effectiveness of the Determined AI platform for optimizing hyperparameters and managing the training process. We are also proud of the scalability and efficiency of the code, which can be applied to other datasets and models with minimal modification. Determined AI Cloud is blazingly fast, testing on my PC takes hours while using Determined AI Cloud takes me seconds to minutes~!
What we learned
Through building this code, we learned the importance of efficient distributed training for large-scale machine learning tasks. We also gained experience using the Determined AI platform and its tools for managing experiments, optimizing hyperparameters, and monitoring training progress. We learned how to work with TensorFlow as a backend for distributed training, and how to balance memory and computation requirements when working with large datasets like CIFAR-10. Overall, we gained valuable insights into the challenges and opportunities of deep learning at scale.
What's next for Determined AI to train a deep neural network on the CIFAR-10
Next steps for Determined AI to train a deep neural network on CIFAR-10 might include exploring other model architectures and hyperparameter search strategies to improve performance, as well as experimenting with other datasets and use cases. Additionally, the platform could be further optimized for distributed training on larger clusters, and new features could be added to support more advanced model development and deployment workflows. Overall, there are many opportunities for further innovation and growth with Determined AI in the field of deep learning.
cifar10_cnn_keras_tensor.py Training accuracy and loss results with 50 Epoch test.
Epoch 1/50
1563/1563 [==============================] - 6s 4ms/step - loss: 1.5267 - accuracy: 0.4410 - val_loss: 1.2673 - val_accuracy: 0.5553
Epoch 2/50
1563/1563 [==============================] - 5s 3ms/step - loss: 1.1565 - accuracy: 0.5886 - val_loss: 1.1354 - val_accuracy: 0.5938
Epoch 3/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.9967 - accuracy: 0.6488 - val_loss: 0.9706 - val_accuracy: 0.6573
Epoch 4/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.8902 - accuracy: 0.6874 - val_loss: 0.9111 - val_accuracy: 0.6831
Epoch 5/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.8124 - accuracy: 0.7165 - val_loss: 0.9734 - val_accuracy: 0.6682
Epoch 6/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.7620 - accuracy: 0.7326 - val_loss: 0.9055 - val_accuracy: 0.6973
Epoch 7/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.7047 - accuracy: 0.7544 - val_loss: 0.8550 - val_accuracy: 0.7099
Epoch 8/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.6617 - accuracy: 0.7681 - val_loss: 0.8529 - val_accuracy: 0.7110
Epoch 9/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.6181 - accuracy: 0.7836 - val_loss: 0.9276 - val_accuracy: 0.6994
Epoch 10/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.5820 - accuracy: 0.7957 - val_loss: 0.8808 - val_accuracy: 0.7165
Epoch 11/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.5446 - accuracy: 0.8085 - val_loss: 0.9637 - val_accuracy: 0.6995
Epoch 12/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.5086 - accuracy: 0.8195 - val_loss: 0.9314 - val_accuracy: 0.7104
Epoch 13/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.4776 - accuracy: 0.8308 - val_loss: 0.9368 - val_accuracy: 0.7160
Epoch 14/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.4525 - accuracy: 0.8394 - val_loss: 0.9572 - val_accuracy: 0.7110
Epoch 15/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.4205 - accuracy: 0.8517 - val_loss: 0.9872 - val_accuracy: 0.7151
Epoch 16/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.3982 - accuracy: 0.8587 - val_loss: 1.0313 - val_accuracy: 0.7029
Epoch 17/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.3715 - accuracy: 0.8680 - val_loss: 1.0580 - val_accuracy: 0.7138
Epoch 18/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.3507 - accuracy: 0.8753 - val_loss: 1.0865 - val_accuracy: 0.7128
Epoch 19/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.3235 - accuracy: 0.8830 - val_loss: 1.1550 - val_accuracy: 0.7057
Epoch 20/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.3088 - accuracy: 0.8899 - val_loss: 1.2320 - val_accuracy: 0.6968
Epoch 21/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.2878 - accuracy: 0.8977 - val_loss: 1.2095 - val_accuracy: 0.7008
Epoch 22/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.2691 - accuracy: 0.9040 - val_loss: 1.3143 - val_accuracy: 0.6955
Epoch 23/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.2525 - accuracy: 0.9097 - val_loss: 1.3534 - val_accuracy: 0.6986
Epoch 24/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.2459 - accuracy: 0.9109 - val_loss: 1.4532 - val_accuracy: 0.6948
Epoch 25/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.2271 - accuracy: 0.9180 - val_loss: 1.5059 - val_accuracy: 0.6890
Epoch 26/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.2188 - accuracy: 0.9211 - val_loss: 1.5292 - val_accuracy: 0.6842
Epoch 27/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.2044 - accuracy: 0.9262 - val_loss: 1.6683 - val_accuracy: 0.6935
Epoch 28/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1945 - accuracy: 0.9297 - val_loss: 1.6351 - val_accuracy: 0.6884
Epoch 29/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1868 - accuracy: 0.9321 - val_loss: 1.7541 - val_accuracy: 0.6851
Epoch 30/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1770 - accuracy: 0.9360 - val_loss: 1.8213 - val_accuracy: 0.6873
Epoch 31/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1765 - accuracy: 0.9375 - val_loss: 1.8452 - val_accuracy: 0.6886
Epoch 32/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1684 - accuracy: 0.9400 - val_loss: 1.9026 - val_accuracy: 0.6804
Epoch 33/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1655 - accuracy: 0.9411 - val_loss: 1.9030 - val_accuracy: 0.6919
Epoch 34/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1500 - accuracy: 0.9459 - val_loss: 2.0205 - val_accuracy: 0.6839
Epoch 35/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1598 - accuracy: 0.9426 - val_loss: 1.9828 - val_accuracy: 0.6841
Epoch 36/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1424 - accuracy: 0.9501 - val_loss: 2.1237 - val_accuracy: 0.6841
Epoch 37/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1464 - accuracy: 0.9471 - val_loss: 2.1224 - val_accuracy: 0.6877
Epoch 38/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1413 - accuracy: 0.9506 - val_loss: 2.1604 - val_accuracy: 0.6801
Epoch 39/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1328 - accuracy: 0.9528 - val_loss: 2.2553 - val_accuracy: 0.6810
Epoch 40/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1313 - accuracy: 0.9532 - val_loss: 2.2323 - val_accuracy: 0.6886
Epoch 41/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1380 - accuracy: 0.9528 - val_loss: 2.2130 - val_accuracy: 0.6793
Epoch 42/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1213 - accuracy: 0.9579 - val_loss: 2.2997 - val_accuracy: 0.6761
Epoch 43/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1359 - accuracy: 0.9529 - val_loss: 2.3860 - val_accuracy: 0.6824
Epoch 44/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1233 - accuracy: 0.9563 - val_loss: 2.4010 - val_accuracy: 0.6812
Epoch 45/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1217 - accuracy: 0.9576 - val_loss: 2.3783 - val_accuracy: 0.6879
Epoch 46/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1205 - accuracy: 0.9579 - val_loss: 2.3475 - val_accuracy: 0.6863
Epoch 47/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1115 - accuracy: 0.9619 - val_loss: 2.4121 - val_accuracy: 0.6901
Epoch 48/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1151 - accuracy: 0.9606 - val_loss: 2.4989 - val_accuracy: 0.6863
Epoch 49/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1156 - accuracy: 0.9601 - val_loss: 2.4402 - val_accuracy: 0.6881
Epoch 50/50
1563/1563 [==============================] - 5s 3ms/step - loss: 0.1177 - accuracy: 0.9601 - val_loss: 2.5606 - val_accuracy: 0.6836
313/313 - 1s - loss: 2.5606 - accuracy: 0.6836 - 574ms/epoch - 2ms/step
Test accuracy: 0.6836000084877014
Built With
- ai
- artificial-intelligence
- artificialintelligence
- derterminedai
- determined
- github
- keras
- machine-learning
- python
- tensor-flow
- torch
- visual-studio
- wbp-systems-torch










Log in or sign up for Devpost to join the conversation.