-

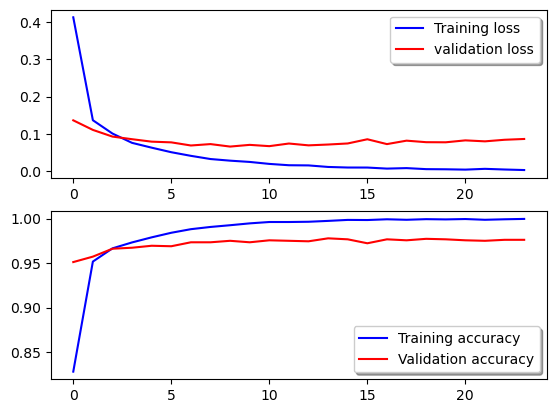
Model is trained over train and validation set
-
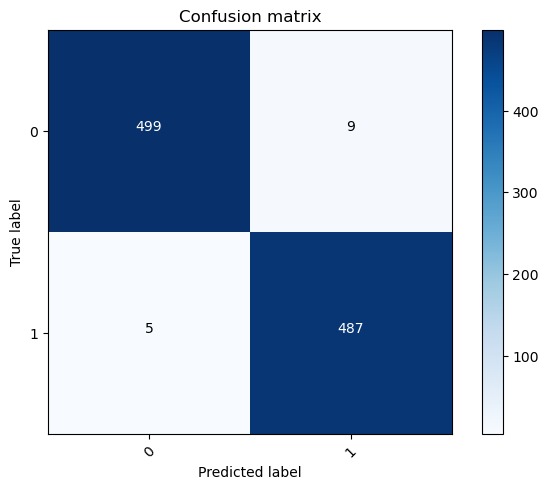
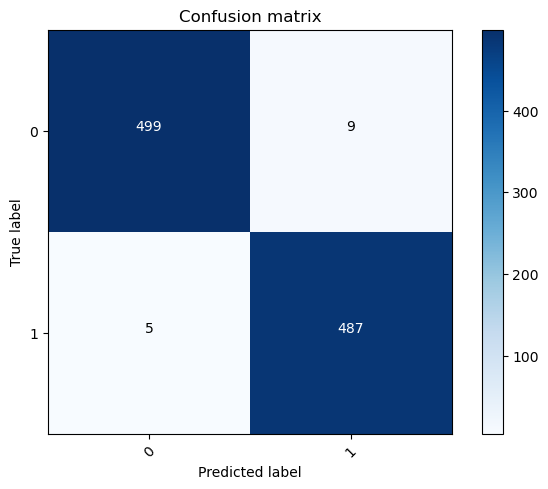
COnfusuion Matrix for test set
-
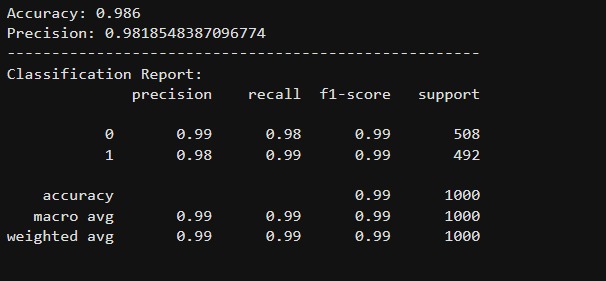
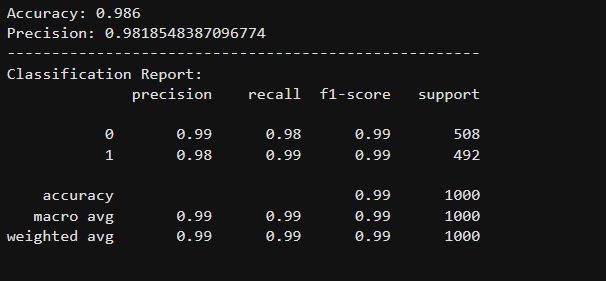
98 % accuracy reached while testing the test set
-
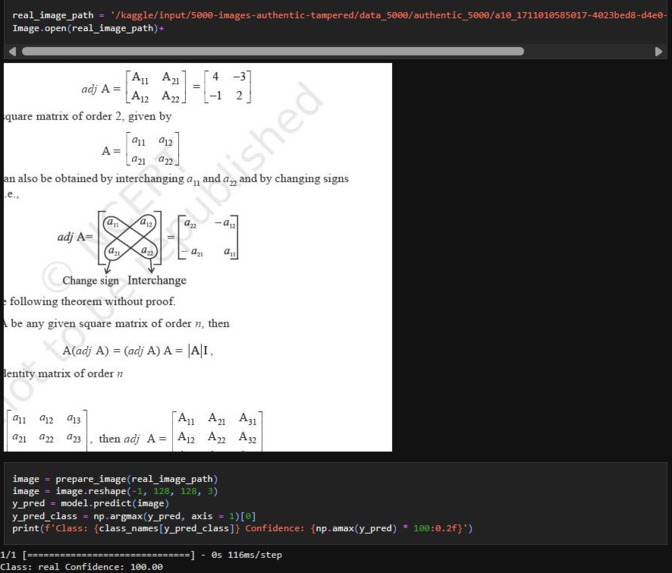
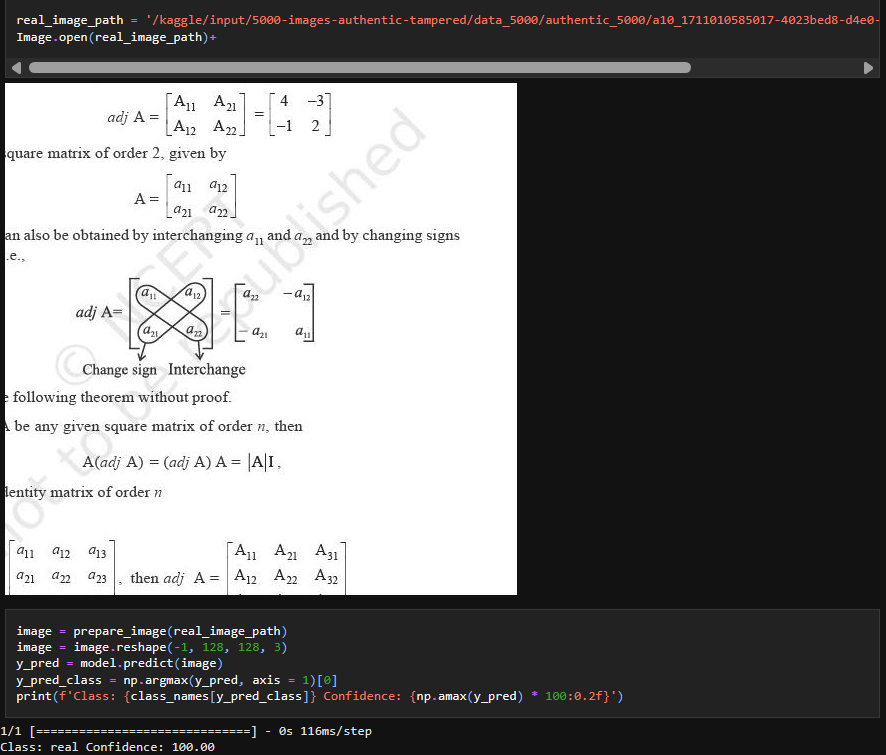
Authentic image testing
-
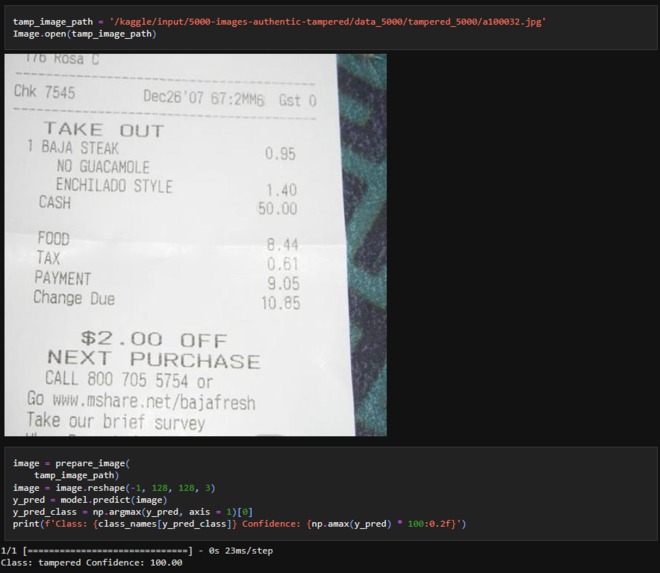
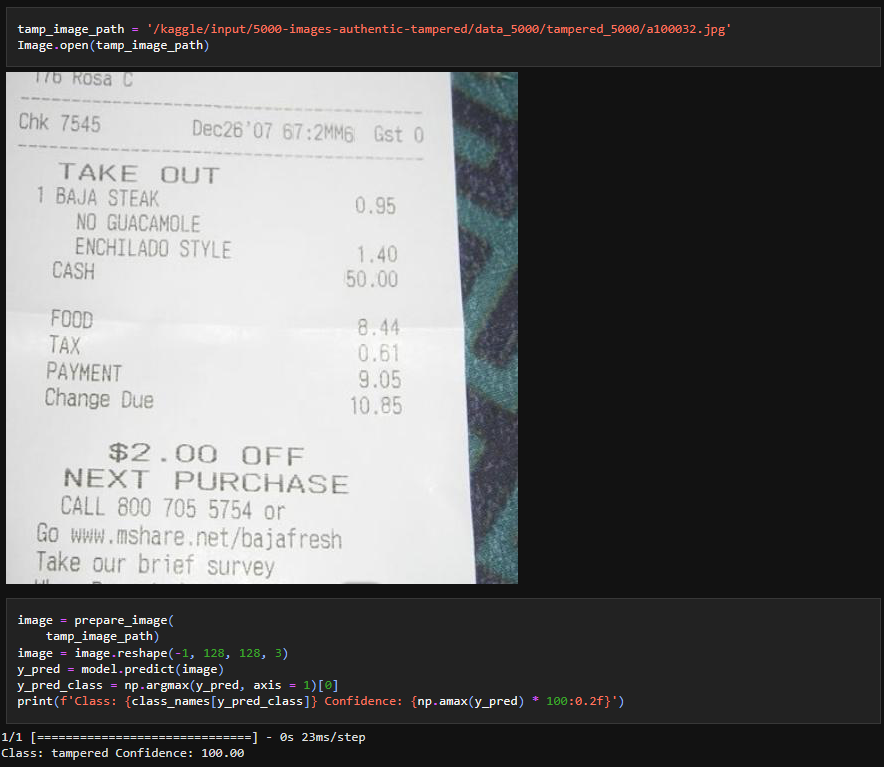
Tampered Image testing
Inspiration
The inspiration behind our project is the growing concern over the authenticity of digital Document images and the need for robust methods to detect forged text within them. With the rise of image editing tools, the ability to manipulate images has become increasingly accessible, posing a challenge to ensuring the integrity of digital documents.
What it does
Our project detects the forged text in the digital image and creates a mask over it.
How we built it
We used a CNN model to train a dataset of Text images and groundtruth masked images.
Challenges we ran into
The training of the takes a huge of amount of time. We still need to train the model on more data to make it more precise in masking.
Accomplishments that we're proud of
We're happy that our code executed successfully on a sample set of dataset we used.
What we learned
We learned a lot about machine learning, CNN, optimizers, image processing.
What's next for Detection of Forged Text in Digital Images
We are still left with training on Remaining dataset and finding the best possible performance for the model. Also, our proposed Model is ~98% accurate in predicting forgery in document images.
Built With
- cnn
- jupyter
- python

Log in or sign up for Devpost to join the conversation.