Intro to the Solution 💡
The objective of this solution is to detect hate speech from input sentences, classifying them into one of three categories: hateful, offensive, or normal. This classification is crucial for moderating online platforms, ensuring they remain safe and inclusive. The aim is to develop a robust model that can accurately interpret and categorize statements, thereby helping to reduce the prevalence of harmful content on social media.
Dataset Description and Data Processing 📊
The data contains each instance tagged by 2 or 3 annotators The dataset contains 20,148 samples, where the distribution is given as follows -

Note: The ‘Undecided’ category is decided on the basis when the label among Hateful, Offensive and Normal has a frequency of less than 50%. The same threshold of 50% is applied while considering the final Target and Rationale.
As per the table only 19,229 instances were considered for the modeling purpose to avoid misjudgement.
Data cleaning involves the points given below - Removing the parts enclosed between < > tags. Demojize the emojis present in the text to make meaning out of it.
For the part of Target community, only the top ones having more frequency are considered and they are given as follows - African, Islam, Jewish, Homosexual, Women, Refugee, Arab, Caucasian, Hispanic and Asian.

The major target communities are on the basis of Race, Religion, Gender, Sexual Orientation and Miscellaneous.
Overall Flow 🔀

Training Methodology ⚙️
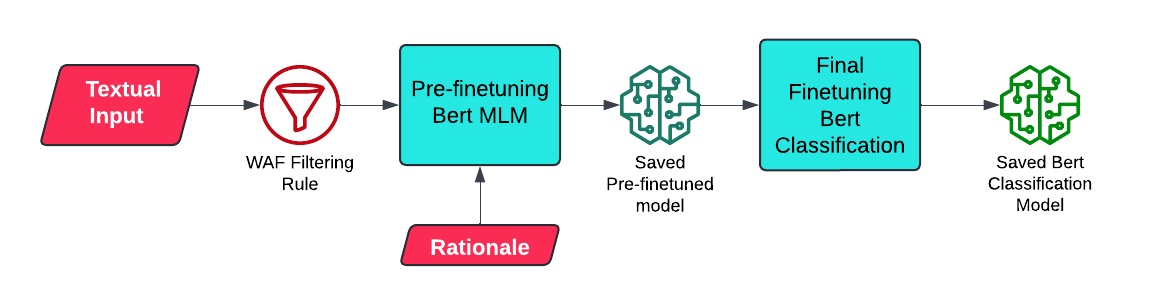
For training and test the split of 80:20 was considered, so the data is trained on the 80% data. Now training happens in 2 phases. The first phase is regarding the part where the model is pre-finetuned along with the text and the rationale using the BERT MLM, where we make the model learn to predict the part where rationale is ‘1’ by randomly masking it specifying a certain percentage. This is done to make the model learn the domain specific data and how the tokens where rationale is ‘1’ can appear. In the second phase, the pre-finetuned model is used and loaded for the sequence classification with bert-base-uncased model, so that the model having the domain knowledge would learn about how to do the multi-class classification over 3 categories.
Below is the diagram that shows the process -

Results and Analysis 📋
Multiple models were tried out during the process for experimentation for the multi-class classification purpose. The below table depicts the Efficiency based metrics and methods for each method.


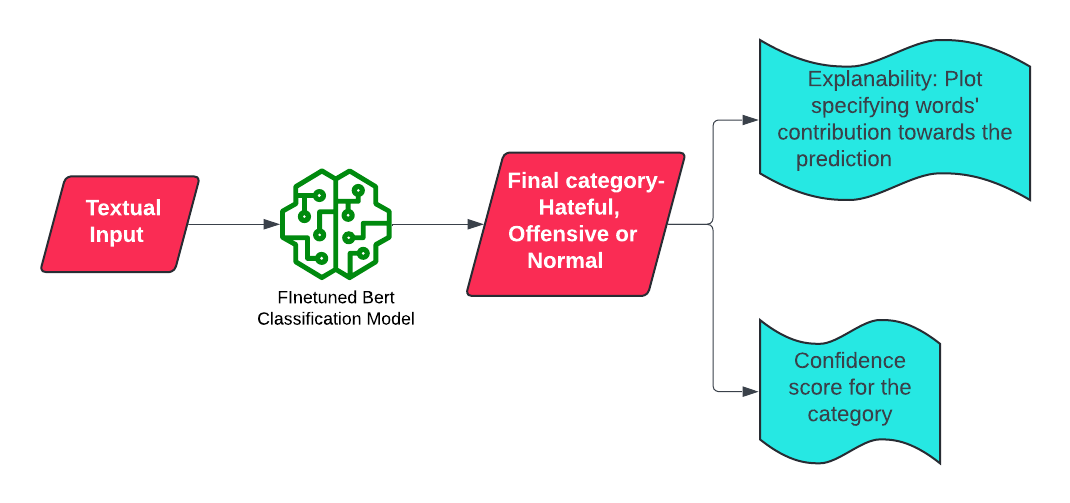
Explainability is added via LIME and Confidence Score 💯


Accomplishments to be proud of 🏆
It beats State-of-the-art Algorithm! of the the HateXplain paper.
Tech Stack Used 🌐
Streamlit, Streamlit Community Cloud, Python, Google Cloud, Docker
Libraries Used 📖
transformers, pytorch, streamlit, pillow, plotly, lime
UI of the deployed Web App

Challenges I Ran Into 🧗🏿♂️
Getting the Explainability metrics using the ERASER Benchmark. Less powerful resource to train the models or use the heavier models. Beautification of UI.
Future Expansion Thoughts 🚀
As the data contains mislabelling to some extent, this can be improved using the GPT based verification method to improve labels. Can be adapted to the multilingual text, video, audio and image forms. A user feedback loop should be added in a way to make the model learn better in future based on the incoming text and model’s categorization. Quantizing the output models to increase the scalability.
Built With
- docker
- google-cloud
- huggingface
- machine-learning
- python
- streamlit











Log in or sign up for Devpost to join the conversation.