-
-

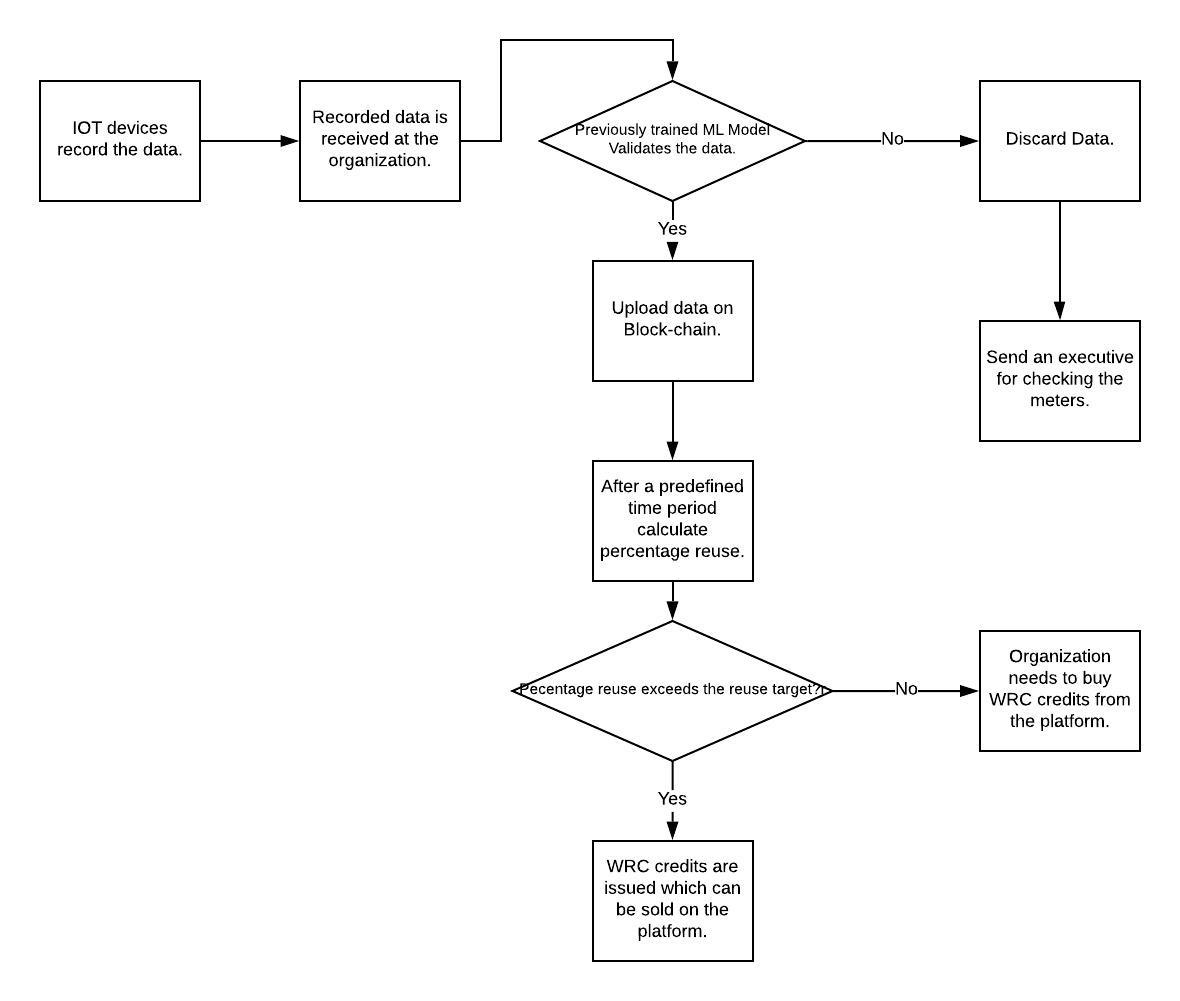
Flow-chart
Inspiration
When we downloaded the data onto our computer and began analyzing it, we found that it would be possible to generate an unsupervised learning model for predicting the fabricated readings that were being sent from some tampered IOT meters. This model would test on the data given and based on this training set it would predict the future readings whether they are fabricated or not. We have also calculated percentage reuse for all the values from the datasets provided on the website.
What it does
We have filtered the data in such a form that we can apply an unsupervised machine learning algorithm on the data for training purpose after that it would perform the task of prediction. We have also calculated the percentage reuse for the values in the given dataset.
How we built it
We have used python for everything. Python modules like pandas, numpy, matplotlib, sklearn, etc were used.
Challenges we ran into
We couldn't decide on which unsupervised learning algorithm to use for the training of the model. During the calculation of percentage reuse, the readings initially were very less, but later, in consultation with the mentors, we were able to calculate them accurately.
Accomplishments that we're proud of
We have successfully calculated the percentage reuse for the first 3 DataSets (i.e Large Industries & Industrial Parks Sample Data, Urban Local Bodies and Municipal Councils Sample Data, Housing Complexes & Gated Communities Sample Data). Also, these calculations have been used for deciding the WRC Certificates for various organizations.
What we learned
A lot about the current water crisis and the importance of water conservation.
What's next for Detecting Anomalies in Data & Calculation of % Reuse
As soon as the model for machine learning is trained we could start with the predictions for future readings.

Log in or sign up for Devpost to join the conversation.