-
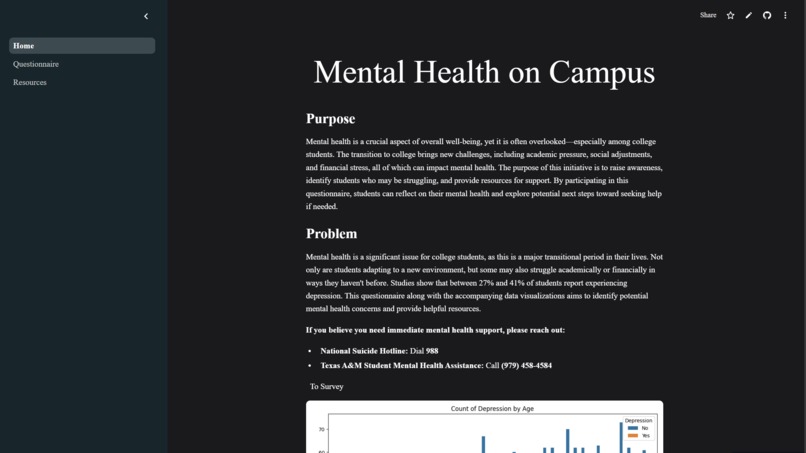
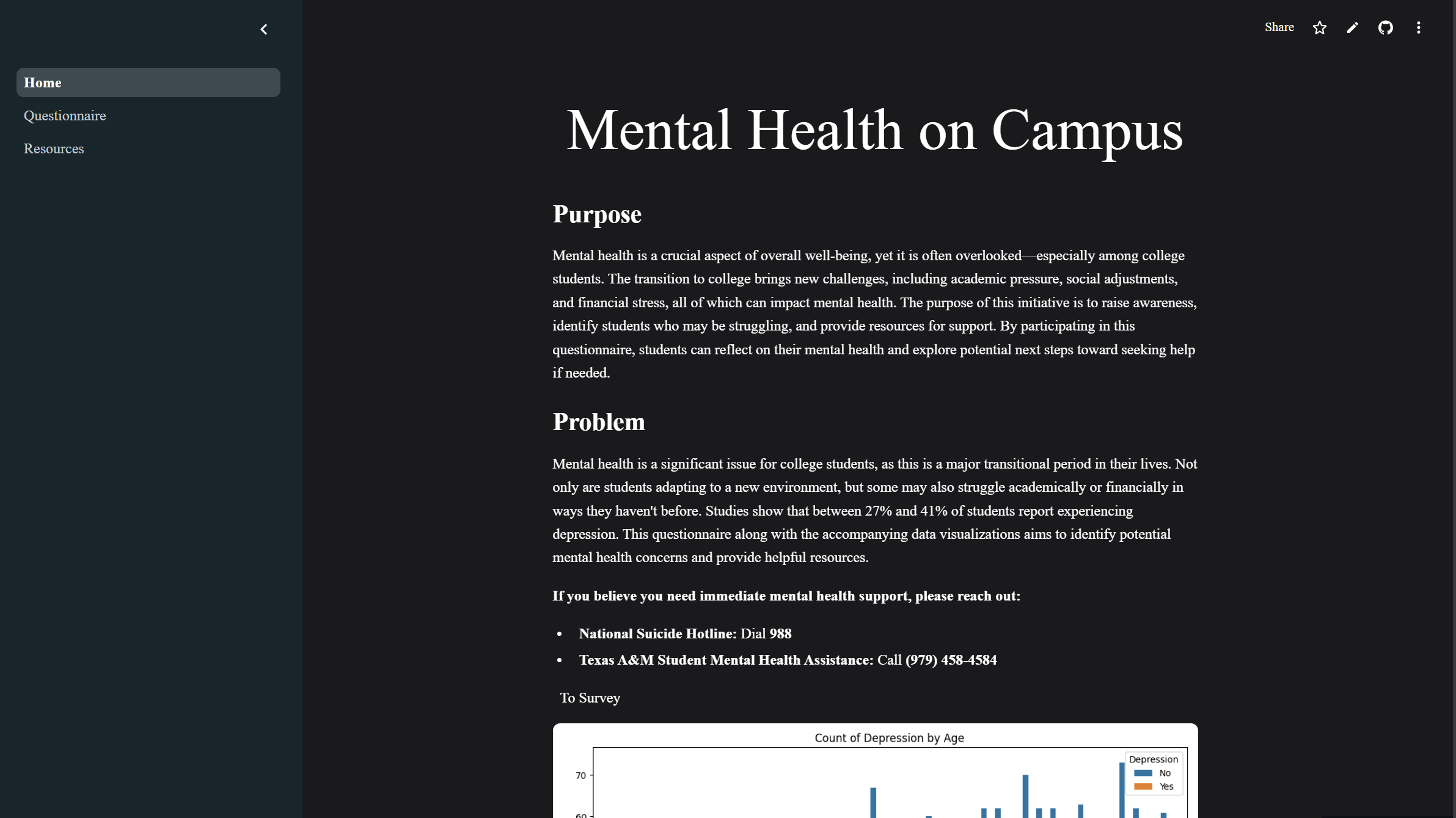
Homepage of urphren
Inspiration
We were inspired by 4 main things: intervention, accessibility, reducing stigma, and scalability.
What it does
Our app provides a survey that the user can fill out. These answers are then fed through a machine learning model to determine whether they are at risk of depression. We then provide resources and visualizations of trends in mental health relating to the survey.
How we built it
The machine learning was trained using a publicly available dataset. Unimportant variables such as name and location were dropped. This data was then used to train a random forest model to predict whether or not the person is at risk of depression. We then dropped insignificant features from the model to lower the complexity and make the survey more convenient to the applicant.
Challenges we ran into
We had issues with our dataset being synthetic, resulting in unrealistically high rates of depression in the model. As a result, we had to search for a new dataset representative of a general population.
Accomplishments that we're proud of
The model we trained had a high degree of accuracy and the application we created is easily accessible and user friendly.
What we learned
We learned how to create a visually appealing front-end using NextJS and eventually Streamlit. Additionally, we gained experience training various machine learning models to fit a dataset.
What's next for Depression Awareness Project
In the future, we'd like to compile larger datasets to better ensure our model is accurate for all people.
Built With
- google-cloud
- jupyter
- python

Log in or sign up for Devpost to join the conversation.