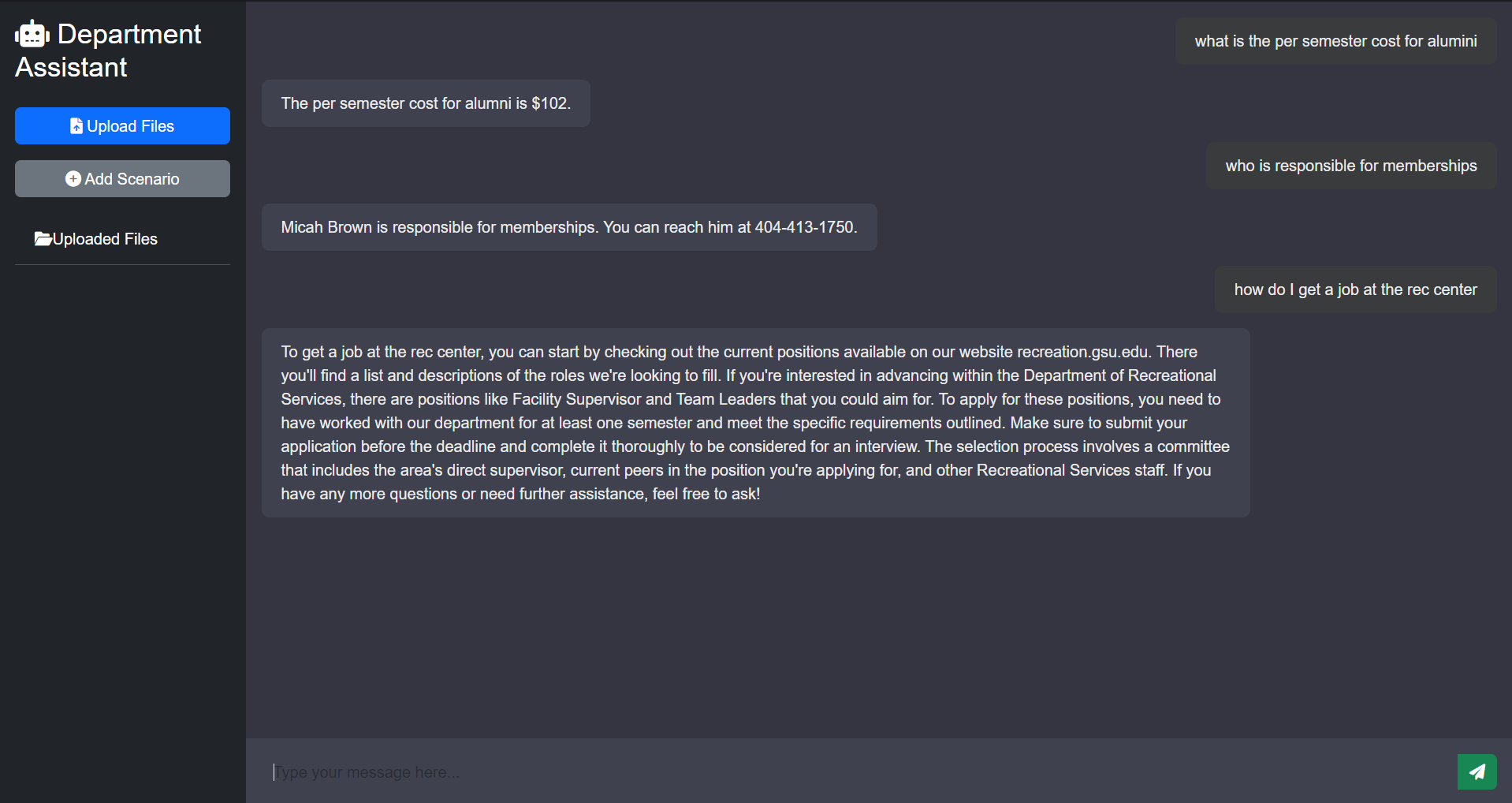
The inspiration for our project came from our hands-on experience working in customer-facing roles at Georgia State University’s Recreation Center and Housing Department. One of the major challenges we encountered was the time-consuming process of searching through massive binders to find the right information for customers. We realized that this inefficiency could be drastically improved with technology. This prompted us to create a solution that streamlines data retrieval, not only improving speed and accuracy but also reducing the chances of misinformation. Our project is designed to benefit current employees and help new hires onboard faster by giving them easy access to the right information.
What We Learned Throughout this project, we learned valuable lessons in several key areas:
Scalability: We designed our solution with scalability in mind, ensuring it can be adapted for use in various industries like education, healthcare, and corporate environments. Customizability: We focused on creating a tool that is highly customizable, allowing users to tailor it to the specific needs of their department or organization. Backend Technologies: We explored advanced data retrieval systems using technologies like HNSWlib to ensure fast and efficient data access. Integration of GPT Models: By leveraging OpenAI’s GPT large language model, we learned how to integrate powerful language models into real-world applications to handle natural language queries.
How We Built Our Project Our project is built as a Flask web application with a focus on ease of use and flexibility. Here’s the technical breakdown:
Frontend: We used HTML, CSS, and JavaScript to create a simple and intuitive user interface that allows users to upload department-specific data and interact with the assistant through a chat interface.
Backend:
We implemented LangChain and a Retrieval-Augmented Generation (RAG) system to handle complex queries and provide accurate results based on the available data.
HNSWlib is utilized on the backend for fast retrieval of relevant information from large datasets. Integration with GPT: For the demo, we powered the assistant using OpenAI’s GPT model, but our architecture allows flexibility in using other models based on the user's requirements.
Data Compatibility: The system supports a wide variety of file formats, such as PDFs, Excel files, Word documents, and text files, by leveraging Python libraries to parse and retrieve information from these formats.
Challenges We Faced Throughout the project, we encountered several challenges, including:
Data Parsing: Ensuring compatibility with various file formats (PDF, DOCX, Excel, etc.) required overcoming multiple parsing challenges. We had to make sure the assistant could accurately extract and process data from these diverse formats.
Accuracy of Information: Maintaining the accuracy of the information retrieved, especially with vague or complex queries, was an ongoing challenge. We addressed this by allowing users to update the database with new scenarios easily, ensuring the assistant evolves over time.
Scalability: We needed to make sure that our solution could handle large volumes of data while remaining responsive. Implementing HNSWlib helped us solve this challenge, allowing us to retrieve information quickly even with large datasets.
Conclusion This project has been an exciting journey where we combined our technical knowledge and real-world experiences to build a tool that addresses an everyday challenge. We believe our solution can be widely used across multiple sectors, improving both employee efficiency and customer satisfaction.
Built With
- css
- flask
- gpt
- hnswlib
- html
- javascript
- langchain
- python
- rag

Log in or sign up for Devpost to join the conversation.