
DentAI — Intelligent Clinical Decision Support for Dentistry
Inspiration
Every year, over 3.5 billion people worldwide suffer from untreated oral disease — not because dentistry doesn't exist, but because the tools dentists use haven't fundamentally changed in decades. A dentist reviewing 20 panoramic X-rays a day is doing the cognitive equivalent of reading 20 dense medical reports in a single shift. Fatigue sets in. Early-stage caries get missed. Periapical lesions are caught a year too late.
We were also struck by a stark disparity: AI has transformed radiology in oncology and cardiology, yet dental imaging — one of the most standardized, high-volume imaging domains in all of medicine — remains almost entirely manual.
The final spark came from a conversation with a practicing dentist who told us:
"I don't need AI to replace my judgment. I need something that notices what I'm about to miss at 6pm on a Friday."
That sentence became our north star. We didn't want to build a diagnostic replacement. We wanted to build the smartest possible assistant — one that gets sharper the more a doctor uses it, speaks differently to a patient than to a clinician, and never lets an urgent finding slip through the cracks unnoticed.
What It Does
DentAI is a multi-role clinical decision support platform for dental imaging. It transforms a standard X-ray upload into a fully structured, urgency-prioritized clinical workflow — for doctors, patients, and administrators.
For the Dentist
- Upload any dental X-ray — panoramic, bitewing, periapical, or intraoral photo
- The system automatically identifies the image type and routes it to the specialized AI model trained for that modality
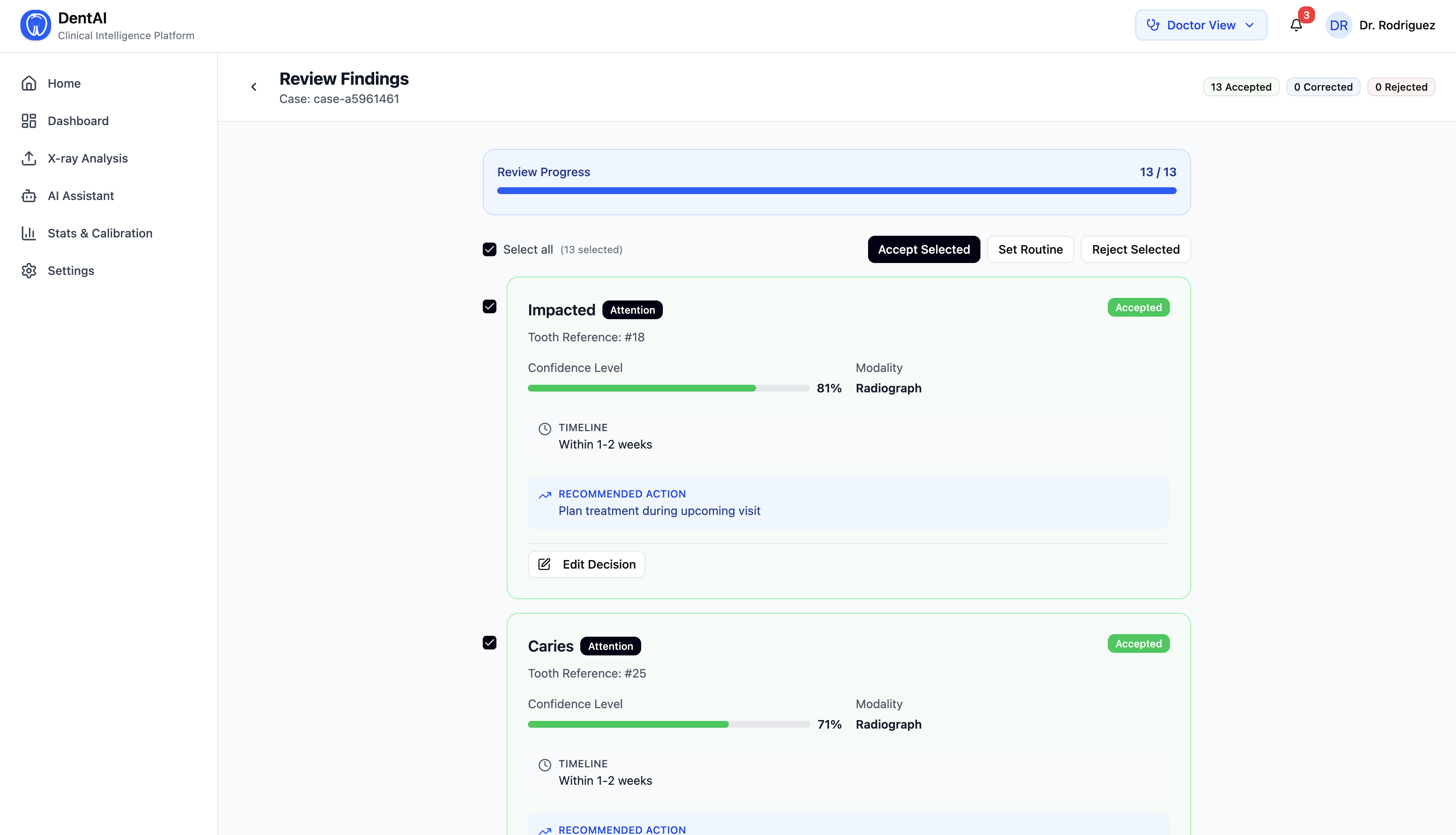
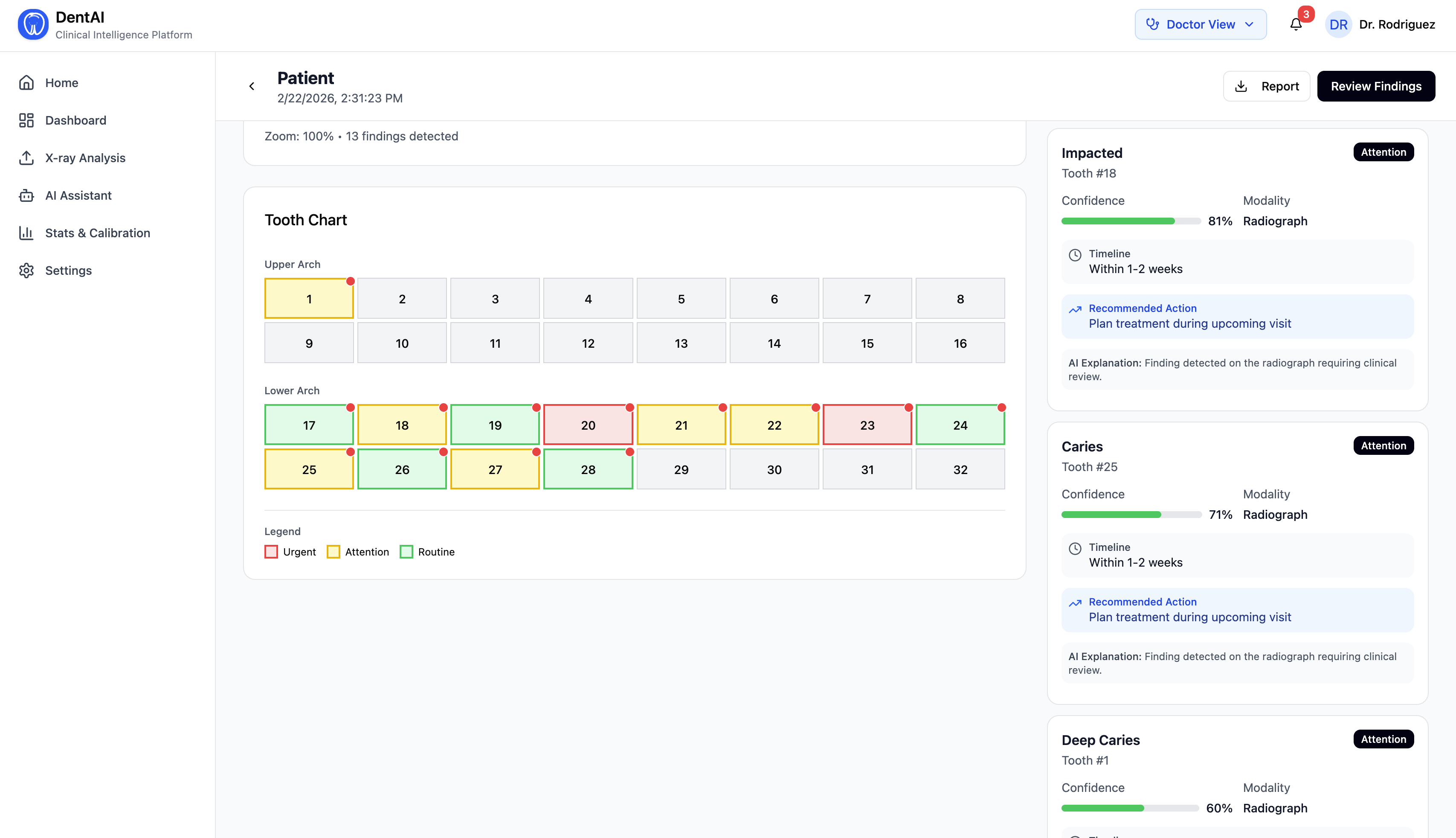
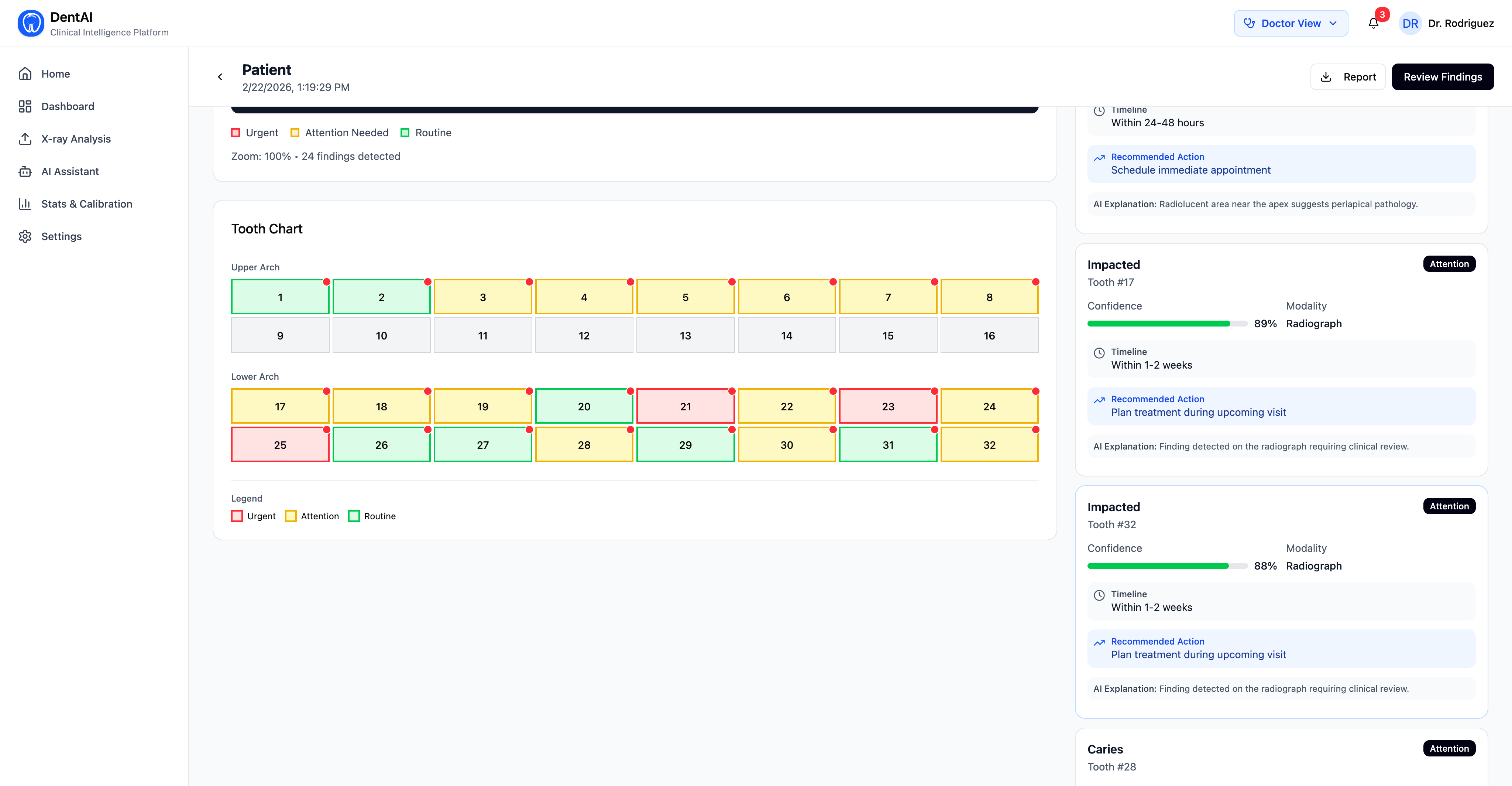
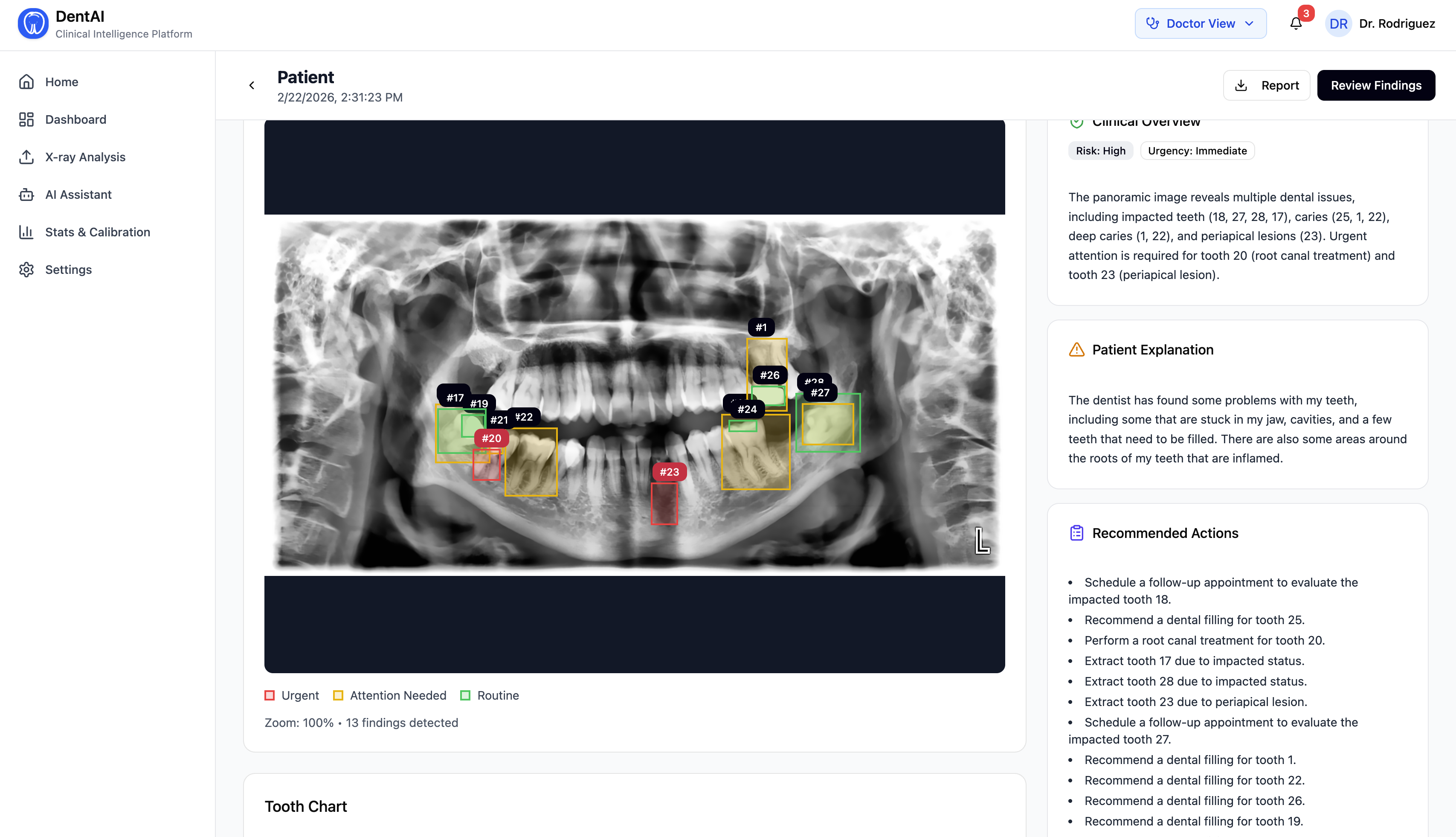
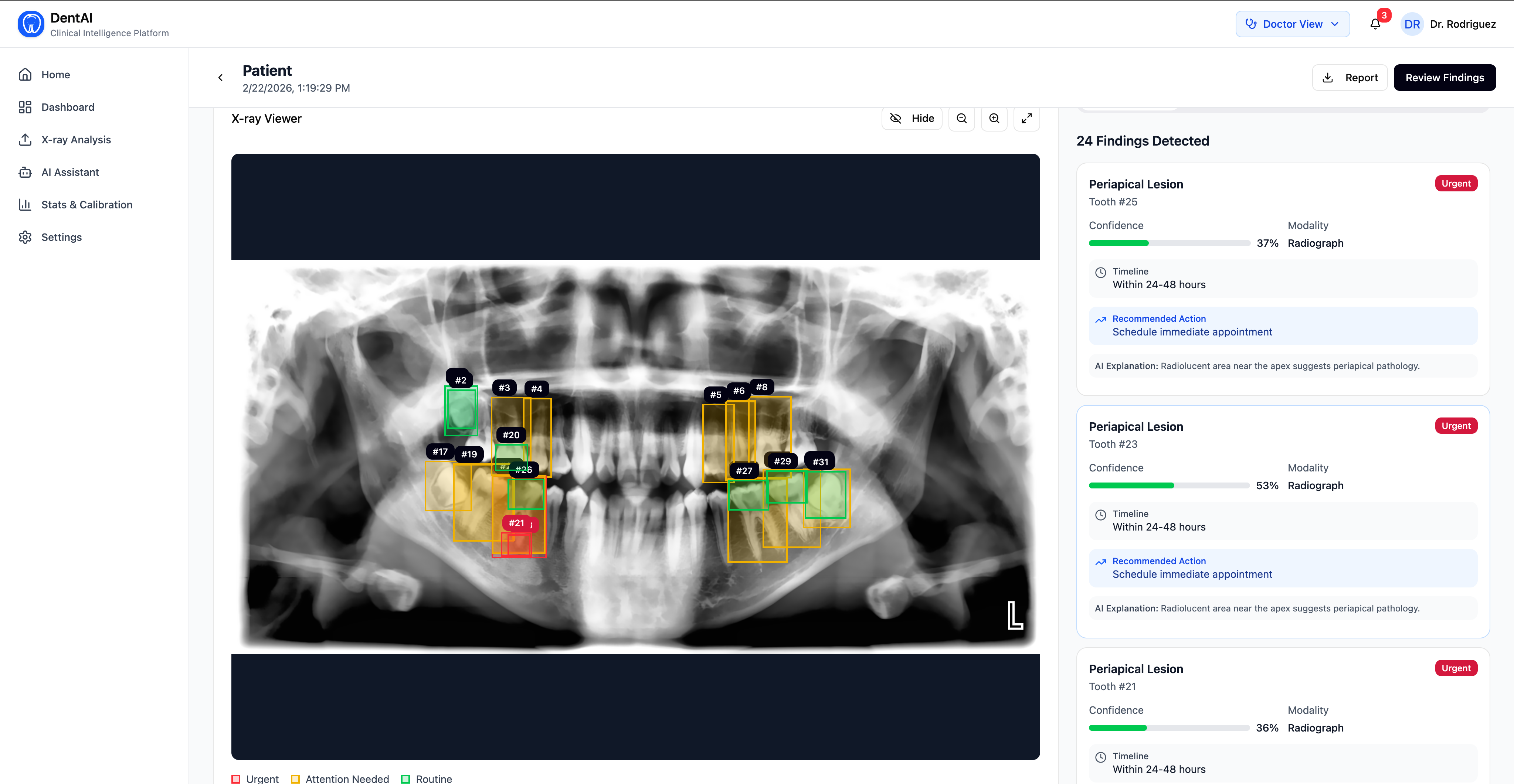
- Detections are displayed with FDI tooth numbering, disease classification, and confidence scores
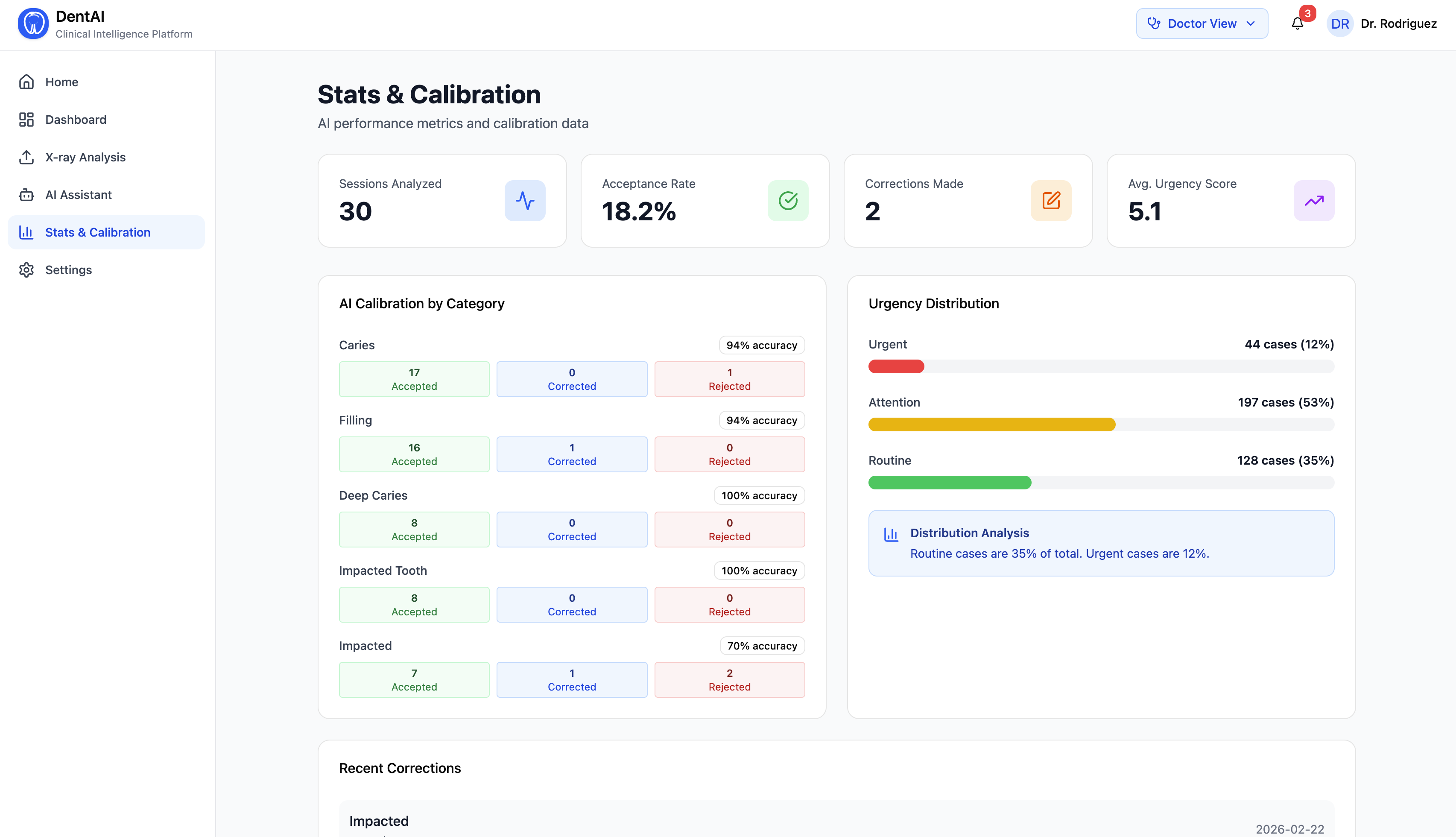
- Every finding is scored on a 1–5 urgency scale (Routine → Critical), with clinical timelines and recommended actions
- A confidence bias layer silently recalibrates over time based on the doctor's accept/reject patterns — the system learns each doctor's diagnostic tendencies
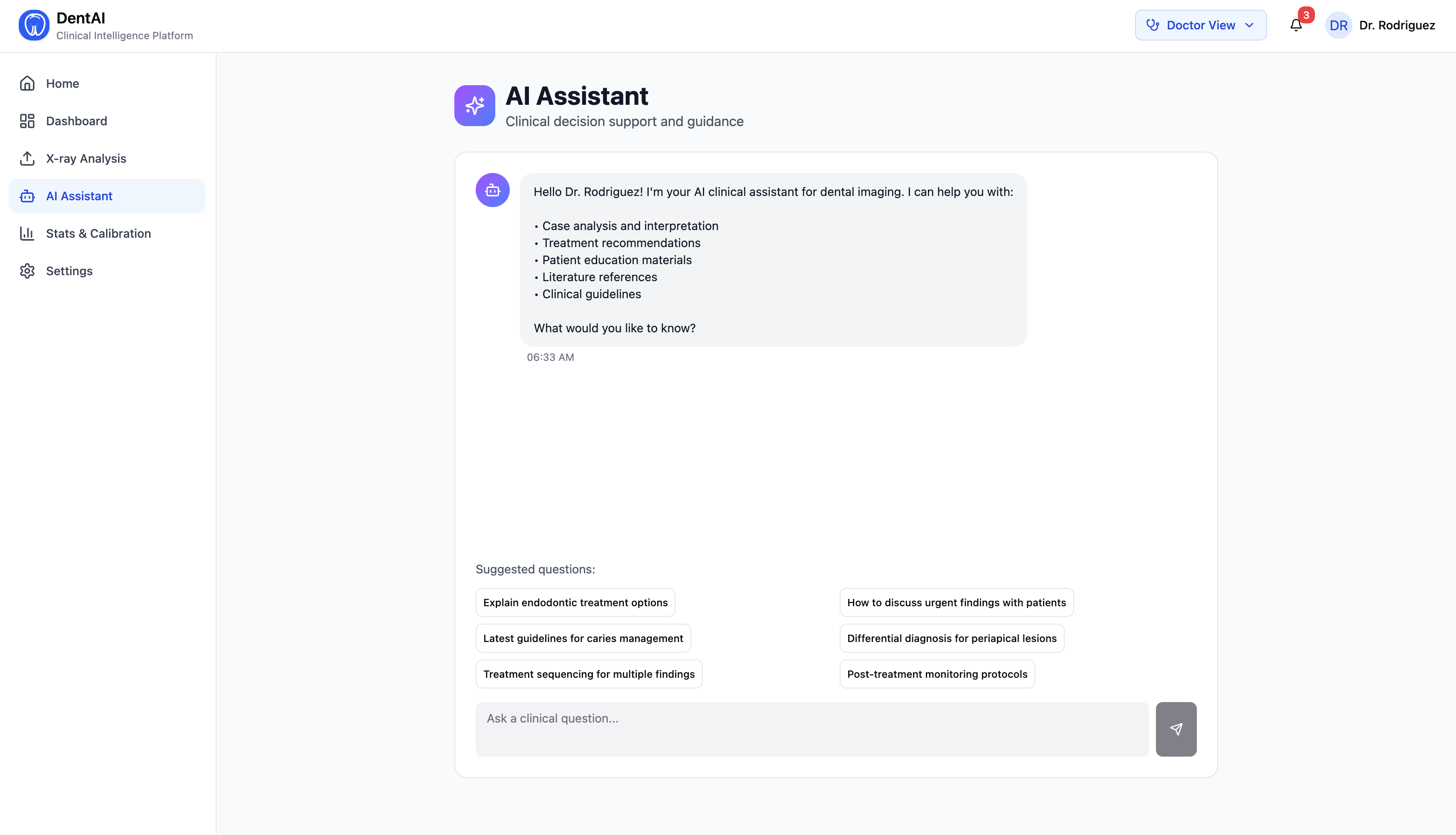
- An AI agent (powered by LangChain + Claude) answers clinical questions in real time, calls tools like similar case retrieval and treatment planning, and proactively surfaces critical findings
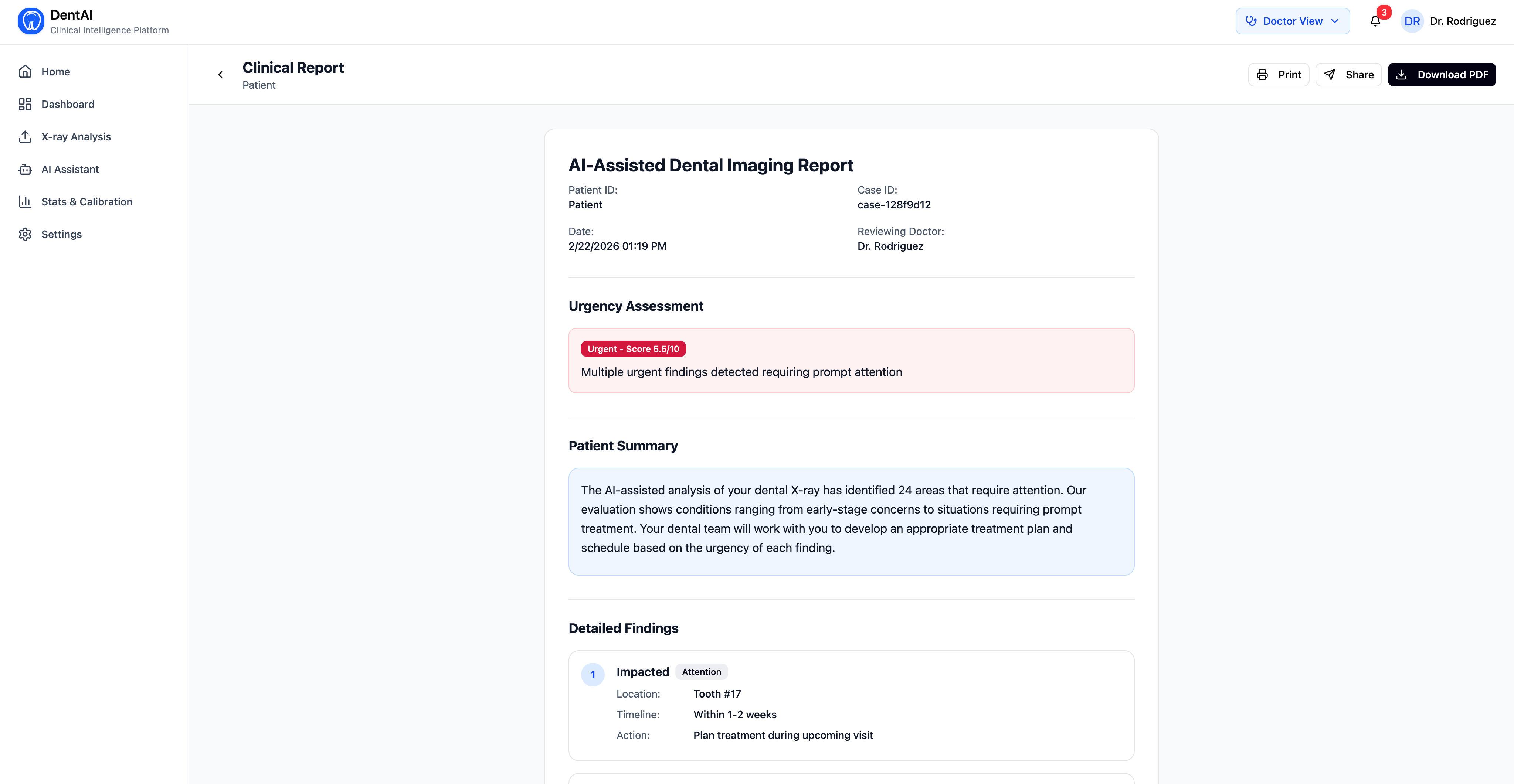
- After reviewing findings, the dentist clicks "Generate Clinical Summary" — a local open-source LLM (Phi-3 Mini via Ollama) synthesizes a structured clinical report with overview, treatment priorities, and follow-up timeline
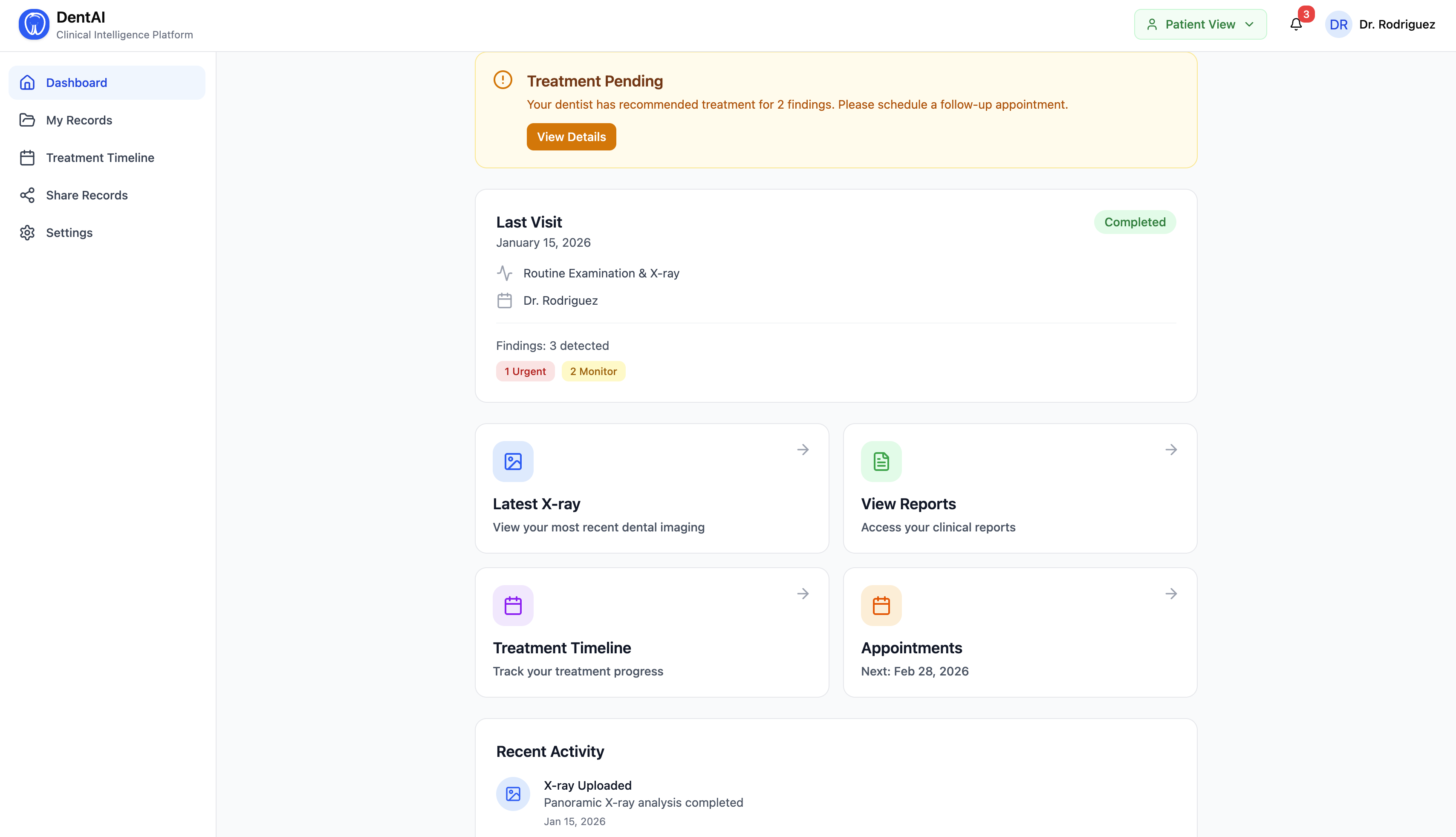
For the Patient
- A simplified patient portal shows their scan history, treatment timeline, and urgency alerts
- Reports use plain English — "tooth decay" not "caries", "root infection" not "periapical lesion"
- Patients only see a report after the dentist explicitly shares it, mirroring real clinical workflow
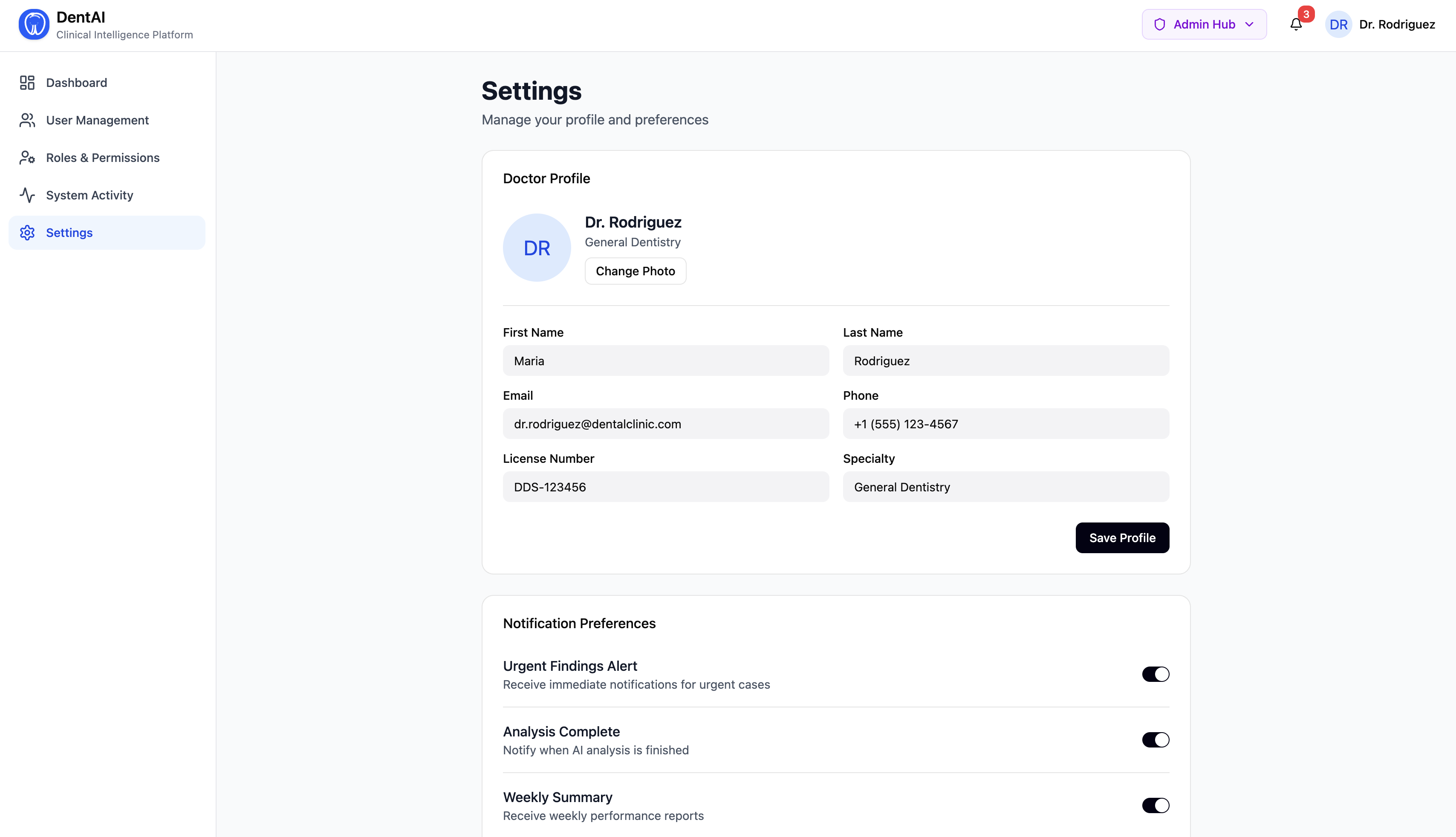
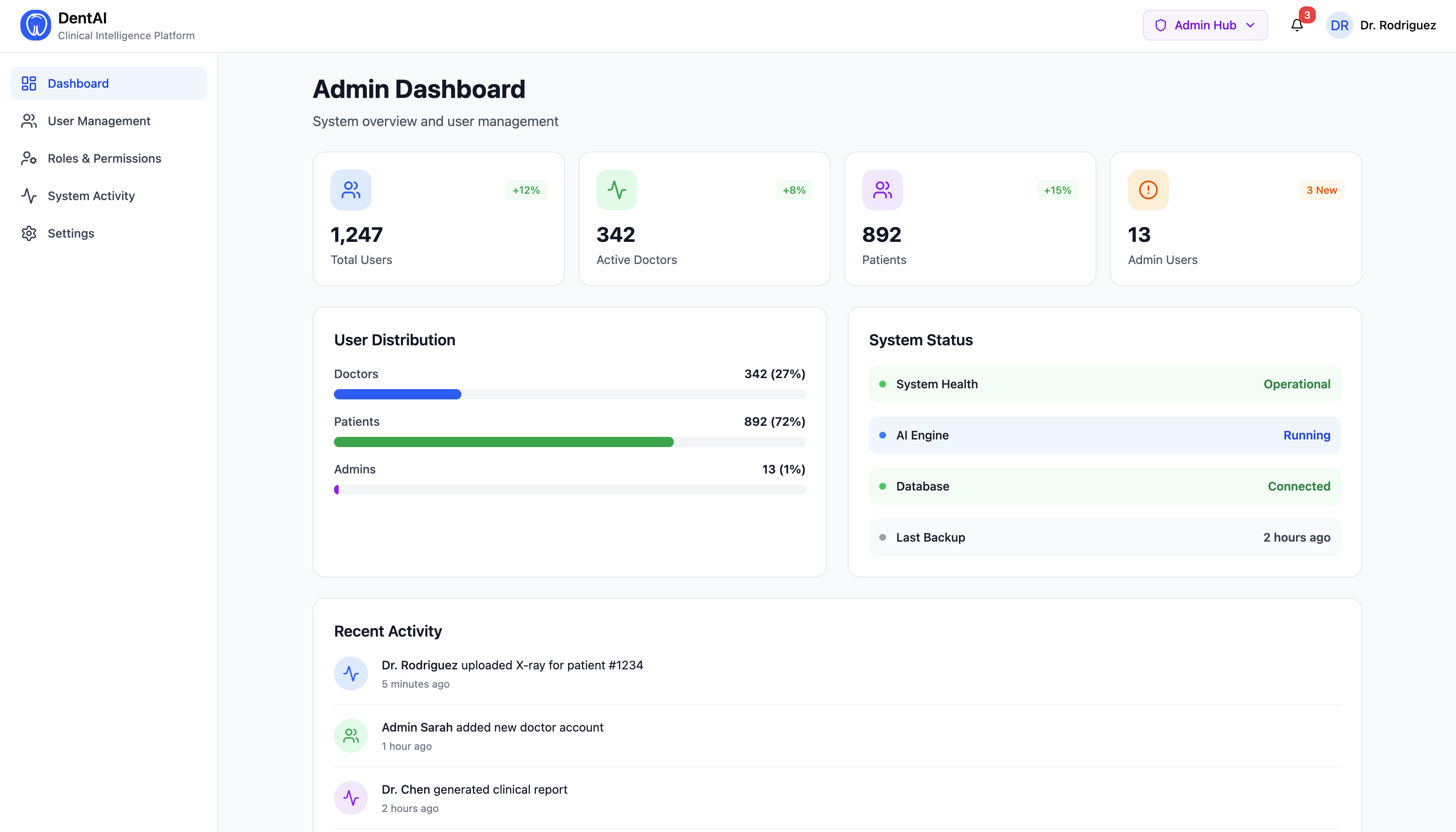
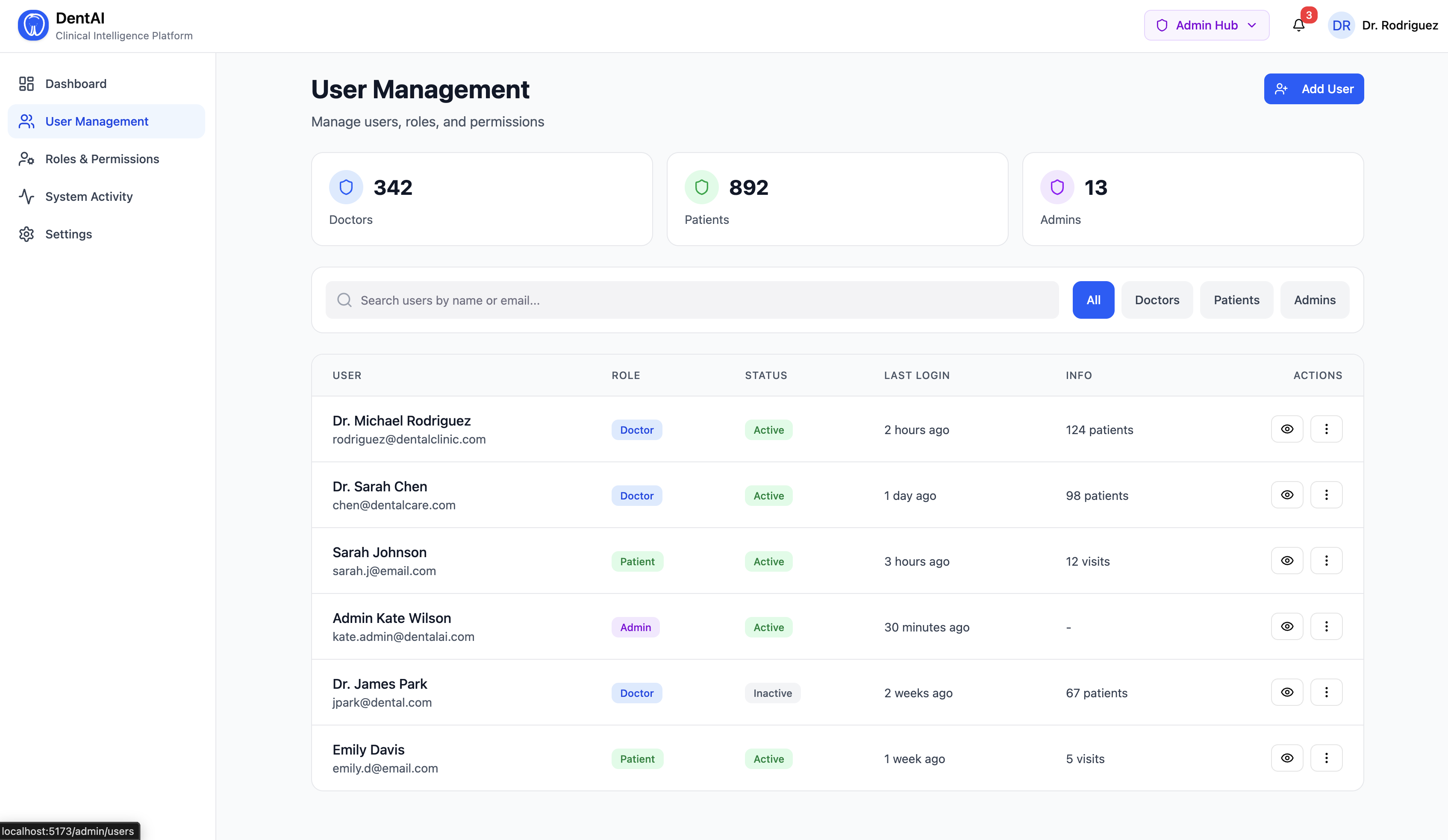
For the Clinic Administrator
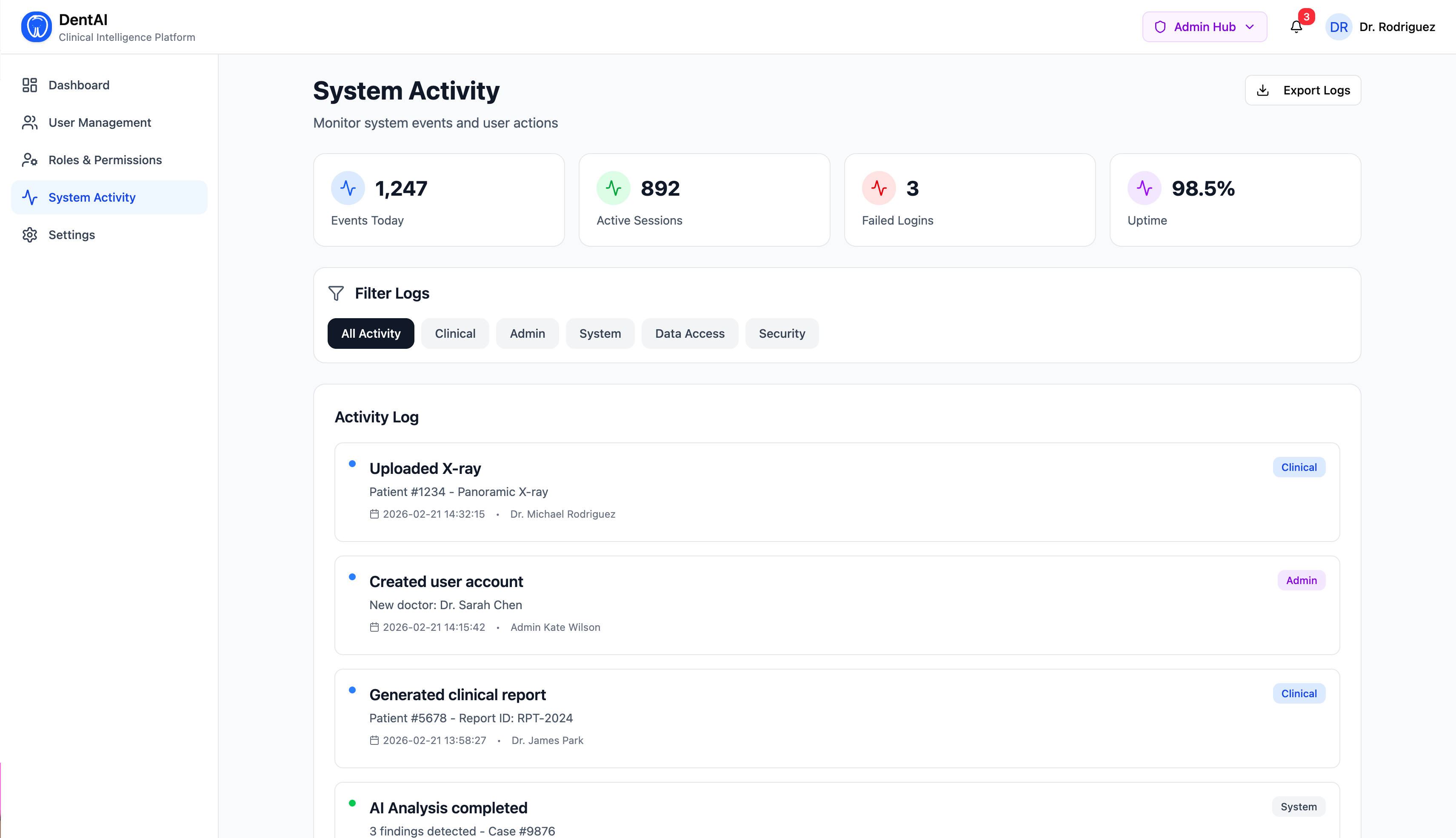
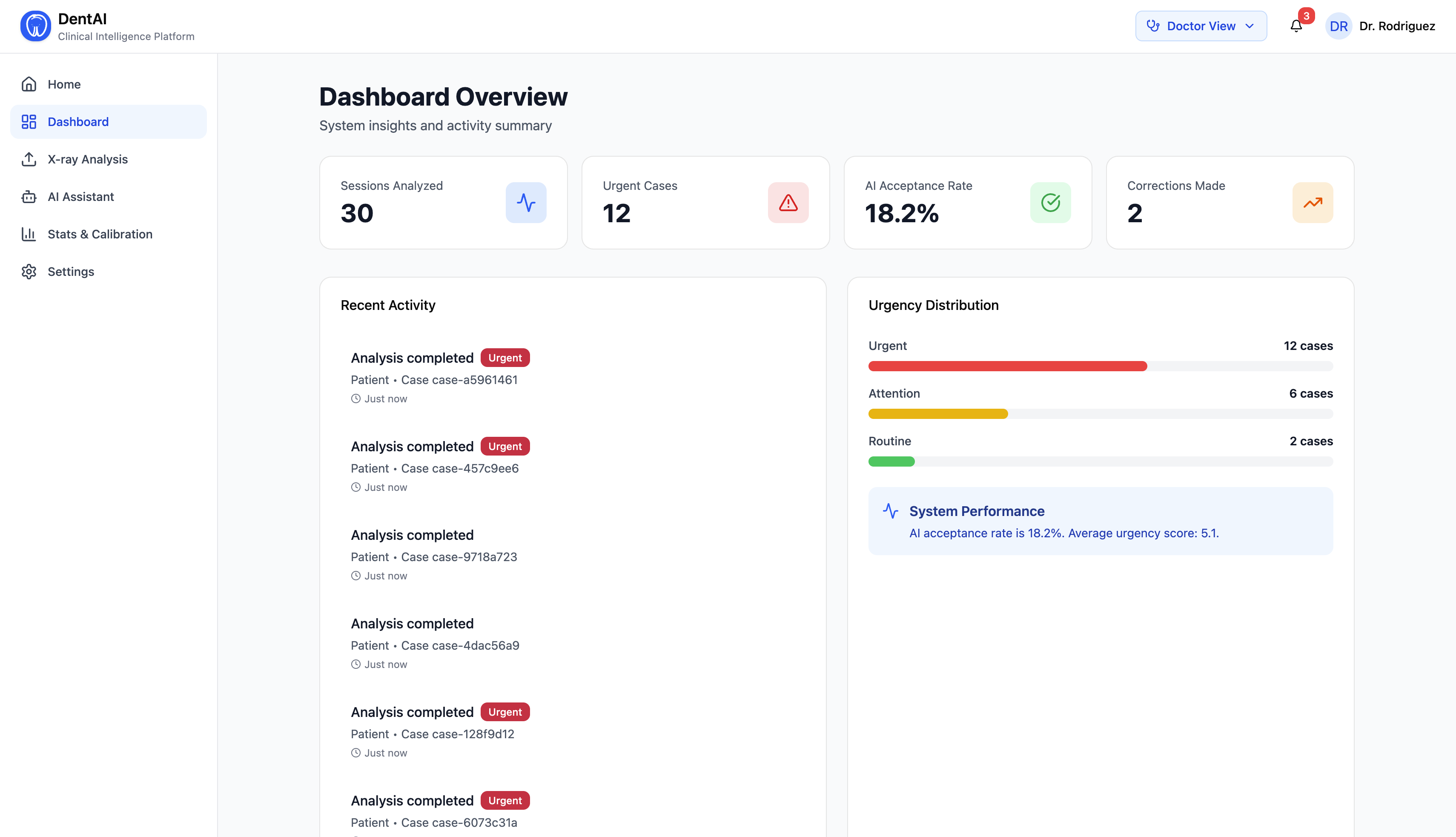
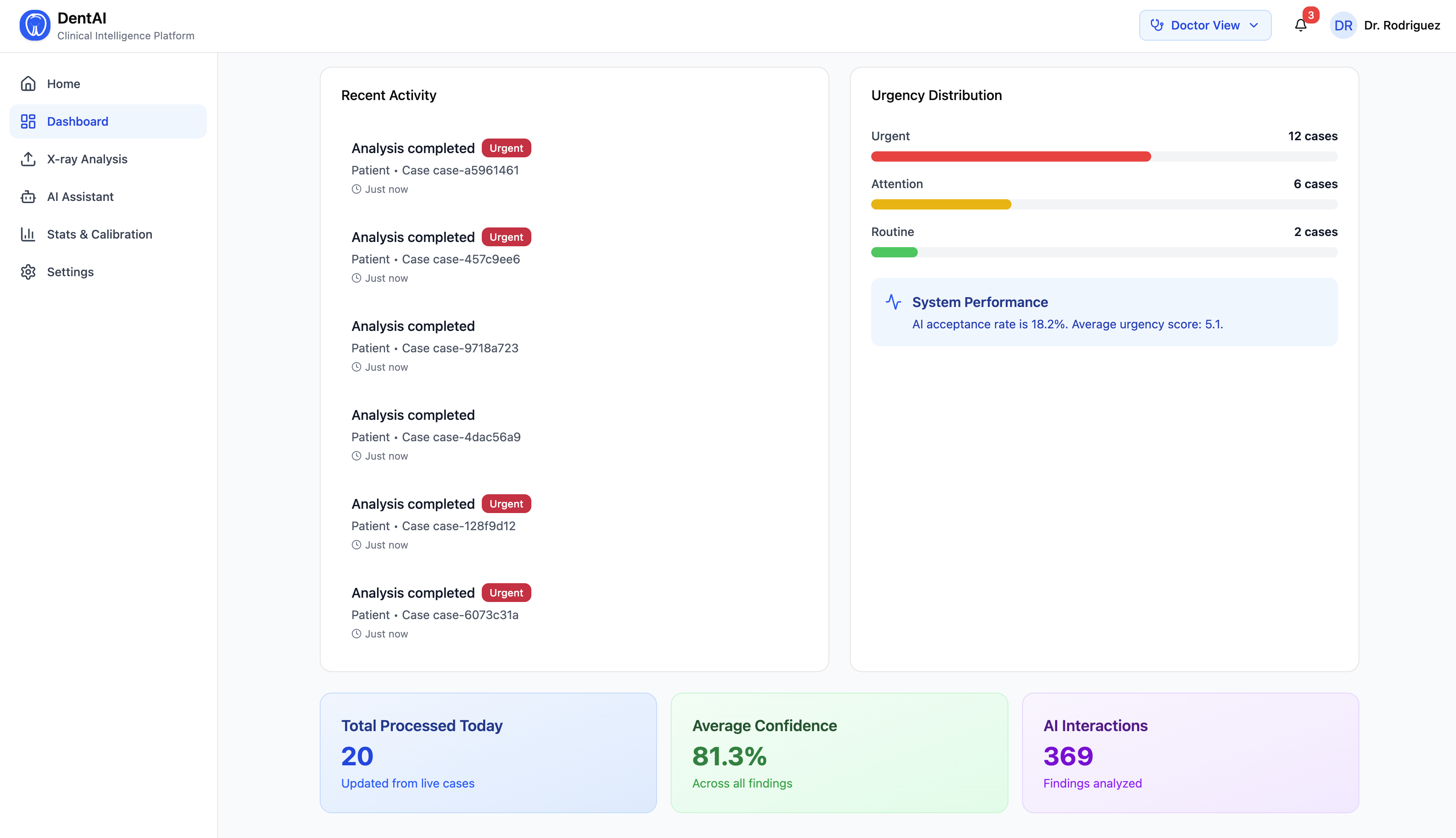
- A full admin hub with user management, role assignment, analytics, and audit logs
- Real-time metrics: total scans, urgent case counts, model acceptance rate, image type distribution
- Export doctor correction data for future model retraining
How We Built It
The architecture has five distinct intelligence layers, each doing one job exceptionally well.
Layer 1 — Multi-Model Vision Router
Rather than using a single model for all dental images, we built an image classifier that detects the modality first, then routes to the best specialized model:
$$\text{Model}(x) = \begin{cases} \text{YOLOv8-DENTEX} & \text{if } \frac{w}{h} > 2.2 \text{ (panoramic)} \ \text{YOLOv8-Bitewing} & \text{if square, large field} \ \text{YOLOv8-Periapical} & \text{if square, small field} \ \text{YOLOv8-Intraoral} & \text{if color image} \end{cases}$$
Each model adds modality-specific fields on top of the base detection schema — periapical detections include root_involvement and estimated_lesion_size; bitewing detections include surface (mesial/distal/occlusal) and depth (enamel/dentin/pulp).
All models run on CPU only — no GPU required. Pretrained weights from the DENTEX dataset and community fine-tunes on HuggingFace.
Layer 2 — Urgency Engine
Every detection is scored $u \in {1, 2, 3, 4, 5}$ using a composite clinical scoring function:
$$u = \text{clamp}\left(u_{\text{base}} + \delta_{\text{conf}} + \delta_{\text{tooth}} + \delta_{\text{co-occur}} + \delta_{\text{depth}} + \delta_{\text{lesion}},\ 1,\ 5\right)$$
Where:
- $u_{\text{base}}$ = base urgency by disease class (e.g., deep caries = 4, caries = 2)
- $\delta_{\text{conf}} = +1$ if confidence $> 0.85$, $-1$ if $< 0.45$
- $\delta_{\text{tooth}} = +1$ if FDI tooth is clinically high-value ${11, 12, 16, 21, 22, 26, 36, 46...}$
- $\delta_{\text{co-occur}} = +1$ if 2+ severe co-occurring conditions
- $\delta_{\text{depth}}$ = bitewing-specific caries depth modifier
- $\delta_{\text{lesion}}$ = periapical lesion size modifier
The session-level urgency aggregates individual scores into an overall triage decision with a natural language narrative.
Layer 3 — Confidence Bias (Adaptive Calibration)
The system tracks each doctor's correction history and maintains a per-disease bias:
$$b_d = \text{clamp}\left(\left(\frac{A_d}{A_d + R_d + C_d} - 0.6\right) \times 0.5,\ -0.3,\ +0.3\right)$$
Where $A_d$, $R_d$, $C_d$ are accept, reject, and correct counts for disease $d$. The adjusted confidence shown to the doctor is $\hat{p} = \text{clamp}(p + b_d,\ 0.01,\ 0.99)$.
This means the system literally gets sharper for each specific doctor over time — without any retraining.
Layer 4 — Agentic AI Layer
We built a LangChain AgentExecutor with 8 real tools backed by live data:
| Tool | Does |
|---|---|
get_urgency_assessment |
Loads session urgency + priority queue |
get_current_detections |
Returns structured finding list |
search_similar_cases |
Queries ChromaDB vector store |
calculate_treatment_plan |
Groups findings by urgency into treatment tiers |
generate_differential_diagnosis |
Sub-calls Claude Haiku for ranked differentials |
get_doctor_tendencies |
Retrieves this doctor's historical correction patterns |
get_modality_context |
Returns image-type-specific clinical context |
get_feedback_stats |
Returns acceptance rate and correction patterns |
Claude (Sonnet) serves as the reasoning brain inside LangChain's orchestration loop. The agent decides which tools to call based on the doctor's natural language question — it doesn't simulate tool use, it actually calls Python functions hitting live SQLite and ChromaDB data.
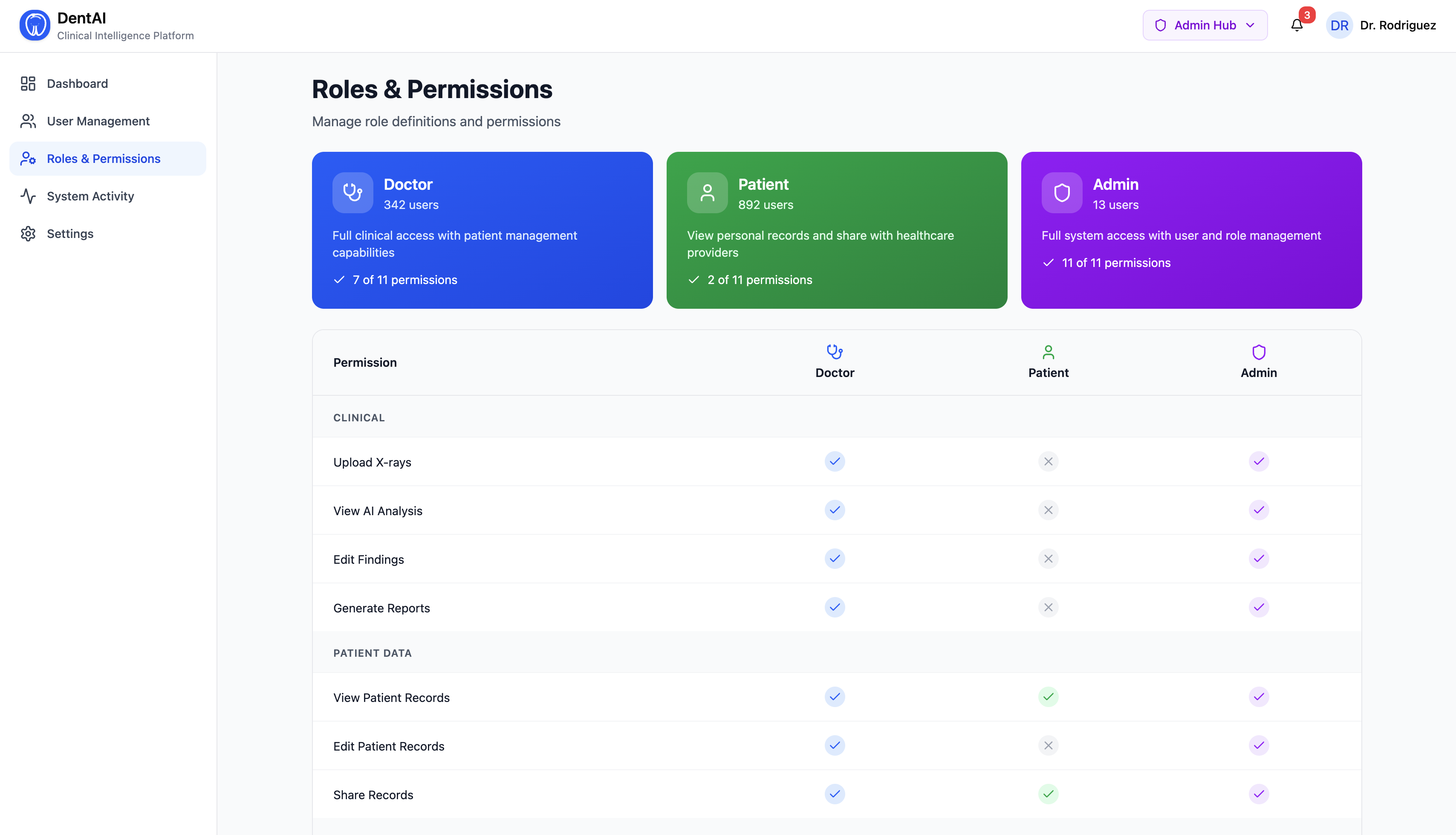
Layer 5 — Role-Based Access Control (RBAC)
Three roles — Doctor, Patient, Admin — with permission enforcement on every endpoint via request headers. Patients only see reports after explicit doctor sharing. Agents respond differently by role: clinical terminology for doctors, plain English for patients.
Clinical Summary (LLM Pipeline)
After finding approval, the summarization pipeline is:
Approved Findings (JSON)
↓
Build Clinical Prompt
↓
Try Ollama/phi3:mini → HuggingFace/Phi-3-mini → Rule-based fallback
↓
Parse LLM Response → Structured Sections
↓
{overview, key_findings, treatment_priorities, next_steps, follow_up}
Tech Stack
| Layer | Technology |
|---|---|
| Vision Models | YOLOv8 (Ultralytics) — DENTEX pretrained weights |
| Backend | FastAPI + Python |
| Agent Orchestration | LangChain + Claude API (Anthropic) |
| Clinical Summary LLM | Ollama / phi3:mini (local, CPU) |
| Vector Database | ChromaDB (similar case retrieval) |
| Persistent Storage | SQLite |
| Frontend | React + TypeScript + Tailwind CSS (Figma-generated) |
| Build Tool | Vite |
Challenges We Ran Into
1. One model can't do everything. Our biggest early mistake was assuming a single YOLOv8 model could handle all four dental image types. A panoramic X-ray and a periapical X-ray look nothing alike to a neural network. The panoramic model was producing garbage on periapical images because it had never seen a close-up of a single root apex. Building the classifier + router system and getting all four models to produce a unified output schema took significant iteration.
2. FDI tooth numbering from pixel coordinates. Assigning the correct FDI tooth number from a bounding box center required understanding the spatial layout of panoramic radiology — upper arch runs $18 \rightarrow 28$ left to right, lower arch runs $48 \rightarrow 38$ left to right, with the midline at image center. Getting the heuristic mapping accurate enough to be clinically meaningful (not just directionally correct) was harder than expected.
3. LangChain tool calling reliability.
Early versions of the agent would sometimes decide not to call tools and just reason from memory — giving confident but fabricated clinical answers. We solved this by being extremely explicit in the system prompt about when tools are mandatory, and by adding handle_parsing_errors=True to catch and retry malformed tool calls.
4. Running everything on CPU. We had no GPU budget. Every model — YOLOv8, the LLM summarizer, the HuggingFace fallback — had to work on CPU in reasonable time. Phi-3 Mini via Ollama turned out to be the key discovery here: it runs comfortably on a MacBook CPU, produces genuinely useful clinical text, and takes ~20 seconds per summary — acceptable for a real clinical workflow.
5. Role-aware agent responses.
Making the same agent produce meaningfully different responses for a doctor vs. a patient required careful prompt engineering. Early attempts produced responses that were either too clinical for patients or too dumbed-down for doctors. The breakthrough was treating it as a context-injection problem: the user_role field is passed in every chat call and the system prompt gives explicit behavioral rules per role.
6. Patient data privacy in the UI. Ensuring patients couldn't access unshared reports required permission checks not just on the backend but also graceful handling in the frontend — showing "Report not yet shared by your dentist" rather than a generic 403 error. Getting that UX right while keeping the backend clean took multiple iterations.
Accomplishments That We're Proud Of
Multi-model routing that actually works — uploading a periapical X-ray and seeing the system correctly classify it, run the right model, and return root involvement depth and lesion size estimates feels genuinely useful.
The confidence bias layer — watching a model's displayed confidence for caries drop in real time after a doctor rejects three consecutive caries predictions is the clearest demonstration of adaptive AI we've built.
Agent tool transparency — when the agent calls
search_similar_casesandcalculate_treatment_planand the frontend shows those tool pills next to the response, you understand exactly how the answer was constructed. No black box.Three completely different experiences from one codebase — switching from Doctor to Patient role and watching the exact same X-ray produce clinical FDI-numbered findings in one view and "tooth decay on your back lower molar" in another is something we're genuinely proud of.
Zero-GPU, zero-internet summarization — the clinical summary runs entirely locally, on CPU, with no API key and no internet connection required. A clinic in a rural area with no cloud access can still use the summary feature.
The full RBAC + share flow — doctor reviews findings, clicks Share, switches to patient view, sees the report appear. That's a real clinical workflow, not a demo shortcut.
What We Learned
AI in healthcare is a UX problem as much as an ML problem. The hardest part wasn't building the models — it was making sure the output was presented in a way that augments clinical judgment rather than replacing it. A 94% confidence score means nothing to a dentist unless it's accompanied by the reasoning behind it. The explainability layer (tool calls visible in the UI, modality context in the agent) matters as much as the accuracy.
Small models are underrated. Phi-3 Mini at 3.8B parameters, running locally on CPU, produces clinical summaries that are genuinely useful. The field is obsessed with larger models, but for a specific, well-constrained task like "summarize these 4 dental findings into a structured report," a small specialized model is often better than a giant general one — and dramatically more deployable.
Active learning is a product feature, not just an ML technique. The confidence bias layer isn't just technically interesting — it's a selling point. Telling a dentist "this system will adjust to your diagnostic style over time" changes their relationship with the tool from skepticism to investment. They become stakeholders in its improvement.
Agentic AI needs guardrails, not just tools. Giving an agent 8 tools and telling it to "figure it out" produces unpredictable behavior. The breakthrough was being explicit: tell the agent exactly when each tool is mandatory, what to do first when urgency is critical, and how to behave differently by role. The system prompt is as important as the tools themselves.
Role-based design forces you to deeply understand your users. Building three separate role experiences forced us to ask: what does a patient actually need to know? What is clinically important vs. what is just noise? Those questions made every feature better — not just the patient portal.
What's Next for DentAI
Longitudinal patient tracking — comparing findings across multiple visits for the same patient to detect disease progression. A caries detected at Moderate urgency in November that becomes Severe by February is a fundamentally different clinical signal than a new finding.
GradCAM explainability — adding heatmap overlays so dentists can see exactly which pixels drove each detection. The single most requested feature in clinical AI adoption research is "show me why."
Real fine-tuning pipeline — the feedback database is already collecting every doctor correction. The next step is a scheduled LoRA fine-tuning job that runs offline on collected corrections and updates the deployed model weights. The active learning loop is architecturally complete — it just needs the training compute step.
Voice-first interaction — a dentist's hands are busy during examination. Web Speech API integration would let them say "reject tooth 36, that's a restoration artifact" and have the system update accordingly.
DICOM support — real clinical environments use DICOM format, not JPEG. Adding a DICOM parser would make the platform deployable in actual clinic PACS systems.
Multi-language patient reports — the patient portal's plain-language summaries are one translation step away from serving non-English-speaking patients. A significant equity opportunity.
Federated learning — allow multiple clinics to contribute correction data to model improvement without sharing patient images. Privacy-preserving improvement at scale.
Built With
- ai
- api
- asgi
- assistant
- charts.
- css
- deep
- deployment
- detection.
- dicom
- docker
- fastapi
- figma
- frontend
- groq
- handling.
- httpx
- icons/material
- image
- learning
- lucide
- machine-learning
- models.
- mui
- nnunet
- numpy
- opencv
- processing.
- pydantic
- pydicom
- pylibjpeg
- python
- python?dotenv
- python?multipart
- pytorch
- radix
- react
- recharts
- request/response
- rest-api
- schemas.
- scikit?image
- segmentation.
- server.
- service.
- styling.
- tailwind
- timm
- torchvision
- ui
- ultralytics
- uvicorn
- v2




Log in or sign up for Devpost to join the conversation.